DeepEye-SQL: A Software-Engineering-Inspired Text-to-SQL Framework
Pith reviewed 2026-05-18 06:05 UTC · model grok-4.3
The pith
Treating Text-to-SQL as structured software development reaches 89.8 percent accuracy on Spider with modest models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
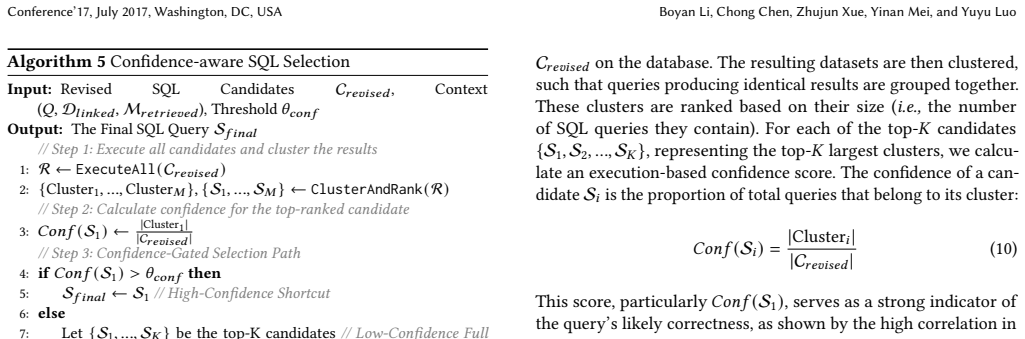
DeepEye-SQL reframes Text-to-SQL as the development of a small software program executed through a verifiable process guided by the Software Development Life Cycle. The framework integrates four synergistic stages: robust schema linking that enforces relational closure, N-version SQL generation for fault tolerance, a Syntax-Logic-Quality toolchain that intercepts errors before execution, and confidence-aware selection that resolves ambiguity through execution-guided adjudication rather than simple majority voting. Using open-source MoE LLMs without any fine-tuning, it achieves 73.5 percent execution accuracy on BIRD-Dev, 75.07 percent on the official BIRD-Test leaderboard, and 89.8 percent 0
What carries the argument
The four synergistic stages modeled on the Software Development Life Cycle that together provide intent grounding, fault tolerance, pre-execution verification, and confidence-based selection.
Where Pith is reading between the lines
- The same staged verification approach could be tested on other structured output tasks such as generating API calls or data transformation scripts.
- Applying the framework to production databases with evolving schemas would show whether the schema-linking stage remains effective outside benchmark conditions.
- If the verification rules were extended with domain-specific checks, accuracy on specialized enterprise databases might improve further.
Load-bearing premise
The Syntax-Logic-Quality toolchain reliably intercepts errors before execution and N-version generation plus confidence-aware selection together provide fault tolerance that exceeds simple majority voting.
What would settle it
An independent run on the same BIRD or Spider test sets that finds many queries passing the toolchain yet failing at execution time, or that shows confidence-aware selection performing no better than majority voting, would falsify the performance advantage.
Figures





read the original abstract
Large language models (LLMs) have advanced Text-to-SQL, yet existing solutions still fall short of system-level reliability. The limitation is not merely in individual modules -- e.g., schema linking, reasoning, and verification -- but more critically in the lack of structured orchestration that enforces correctness across the entire workflow. This gap motivates a paradigm shift: treating Text-to-SQL not as free-form language generation but as a software-engineering problem that demands structured, verifiable orchestration. We present DeepEye-SQL, a software-engineering-inspired framework that reframes Text-to-SQL as the development of a small software program, executed through a verifiable process guided by the Software Development Life Cycle (SDLC). DeepEye-SQL integrates four synergistic stages: it grounds user intent through robust schema linking, enforcing relational closure; enhances fault tolerance with N-version SQL generation; ensures deterministic verification via a ``Syntax-Logic-Quality'' tool-chain that intercepts errors pre-execution; and introduces confidence-aware selection that leverages execution-guided adjudication to resolve ambiguity beyond simple majority voting. Leveraging open-source MoE LLMs (~30B total, ~3B activated parameters) without any fine-tuning, DeepEye-SQL achieves 73.5% execution accuracy on BIRD-Dev, 75.07% on the official BIRD-Test leaderboard, and 89.8% on Spider-Test, outperforming state-of-the-art solutions that rely on larger models or extensive training. This highlights that principled orchestration, rather than LLM scaling alone, is key to achieving system-level reliability in Text-to-SQL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DeepEye-SQL, a Text-to-SQL framework that reframes the task as a software-engineering problem guided by the Software Development Life Cycle (SDLC). It consists of four synergistic stages: robust schema linking to ground user intent and enforce relational closure, N-version SQL generation to enhance fault tolerance, a Syntax-Logic-Quality toolchain for deterministic pre-execution verification, and confidence-aware selection that uses execution-guided adjudication to resolve ambiguity beyond simple majority voting. Using open-source MoE LLMs (~30B total parameters) without fine-tuning, the framework reports execution accuracies of 73.5% on BIRD-Dev, 75.07% on the official BIRD-Test leaderboard, and 89.8% on Spider-Test, outperforming prior state-of-the-art methods that rely on larger models or extensive training.
Significance. If the central claims hold, the work would demonstrate that structured orchestration and verifiable stages can deliver competitive Text-to-SQL performance with smaller open-source models, shifting emphasis from LLM scaling to system-level design. This has potential implications for building reliable, production-grade database query interfaces and could encourage similar SDLC-inspired approaches in other LLM-driven data tasks.
major comments (2)
- [Abstract and evaluation sections] Abstract and evaluation sections: the central claim that the Syntax-Logic-Quality toolchain plus confidence-aware selection deliver fault tolerance exceeding simple majority voting is load-bearing, yet no ablation study isolates the selection step while holding the N-version candidate pool fixed. Without this controlled comparison, it remains possible that reported gains derive primarily from multi-generation diversity rather than the orchestration's adjudication logic.
- [Description of the four synergistic stages] Description of the four synergistic stages: the manuscript provides no quantitative breakdown or controlled experiments showing the incremental benefit of confidence-aware selection over majority voting on identical candidates, nor details on how execution-guided adjudication resolves ambiguity in practice. This weakens the argument that principled SDLC-style stages outperform basic ensembling.
minor comments (2)
- [Abstract] The abstract states results on BIRD-Dev, BIRD-Test, and Spider-Test but provides no error bars, standard deviations across runs, or details on how post-hoc design choices in the stages affect final accuracies.
- [Abstract] Implementation details for the open-source MoE LLMs (specific model names, exact parameter counts, and prompting templates) are referenced but not fully specified, limiting reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The concerns regarding the need for controlled ablations of the confidence-aware selection component are well-taken and point to an opportunity to strengthen the empirical support for our claims. We address each major comment below and commit to revisions that directly respond to the feedback.
read point-by-point responses
-
Referee: [Abstract and evaluation sections] Abstract and evaluation sections: the central claim that the Syntax-Logic-Quality toolchain plus confidence-aware selection deliver fault tolerance exceeding simple majority voting is load-bearing, yet no ablation study isolates the selection step while holding the N-version candidate pool fixed. Without this controlled comparison, it remains possible that reported gains derive primarily from multi-generation diversity rather than the orchestration's adjudication logic.
Authors: We agree that an explicit ablation isolating the confidence-aware selection while holding the N-version candidate pool fixed would provide clearer evidence that the adjudication logic contributes beyond diversity from multi-generation alone. The manuscript reports overall framework results and comparisons to prior SOTA, but does not contain this specific controlled experiment. In the revised version we will add the requested ablation, reporting execution accuracy for majority voting versus execution-guided adjudication on identical candidate sets from the same N-version generation stage. This will be placed in the evaluation section and referenced from the abstract. revision: yes
-
Referee: [Description of the four synergistic stages] Description of the four synergistic stages: the manuscript provides no quantitative breakdown or controlled experiments showing the incremental benefit of confidence-aware selection over majority voting on identical candidates, nor details on how execution-guided adjudication resolves ambiguity in practice. This weakens the argument that principled SDLC-style stages outperform basic ensembling.
Authors: We acknowledge that the current description of the four stages would benefit from quantitative incremental analysis and concrete examples of ambiguity resolution. The manuscript explains the design of execution-guided adjudication but does not include side-by-side metrics on identical candidates or case studies. In revision we will add (1) a quantitative breakdown comparing confidence-aware selection to majority voting on fixed candidate pools and (2) practical examples illustrating cases where adjudication correctly selects the right SQL when majority voting fails. These additions will be incorporated into the section describing the synergistic stages. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents DeepEye-SQL as an engineering framework with four described stages (schema linking, N-version generation, Syntax-Logic-Quality toolchain, confidence-aware selection) and reports execution accuracies on external public benchmarks (BIRD-Dev, BIRD-Test, Spider-Test). No equations, first-principles derivations, fitted parameters, or self-referential definitions appear in the provided text. Performance results are measured against independent datasets rather than quantities defined internally by the framework itself. The central claims rest on empirical evaluation and orchestration description without any reduction of outputs to inputs by construction, self-citation load-bearing, or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Software Development Life Cycle principles can be mapped to Text-to-SQL to enforce correctness across the workflow.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DeepEye-SQL integrates four synergistic stages: ... Syntax-Logic-Quality tool-chain ... confidence-aware selection that clusters execution results
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery theorem unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
N-version Programming for SQL Generation ... three distinct generators (skeleton, ICL, divide-and-conquer)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 4 Pith papers
-
Harnessing Agentic Evolution
AEvo introduces a meta-agent that edits the evolution procedure or agent context based on accumulated state, outperforming baselines by 26% relative improvement on agentic benchmarks and achieving SOTA on open-ended tasks.
-
Data-aware candidate selection in NL2SQL translation via small separating instances
A selection technique based on separating instances and provenance outperforms baselines for choosing among 2-3 NL2SQL candidates on a BIRD-DEV subset without consistency scores.
-
FlexSQL: Flexible Exploration and Execution Make Better Text-to-SQL Agents
FlexSQL reaches 65.4% on Spider2-Snow by allowing agents to flexibly explore schemas, generate diverse plans, choose SQL or Python execution, and apply two-tiered repair.
-
DPC: Training-Free Text-to-SQL Candidate Selection via Dual-Paradigm Consistency
DPC selects correct text-to-SQL outputs by enforcing execution consistency between SQL and Python on an adversarially constructed minimal distinguishing database.
Reference graph
Works this paper leans on
-
[1]
Gemini: A Family of Highly Capable Multimodal Models
Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M. Dai, Anja Hauth, Katie Mil- lican, David Silver, Slav Petrov, Melvin Johnson, Ioannis Antonoglou, Julian Schrittwieser, Amelia Glaese, Jilin Chen, Emily Pitler, Timothy P. Lillicrap, Ange- liki Lazaridou, Orhan Firat, James Molloy, Michae...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.11805 2023
-
[2]
Jinheon Baek, Horst Samulowitz, Oktie Hassanzadeh, Dharmashankar Subrama- nian, Sola Shirai, Alfio Gliozzo, and Debarun Bhattacharjya. 2025. Knowledge Base Construction for Knowledge-Augmented Text-to-SQL. InFindings of the Association for Computational Linguistics, ACL 2025, Vienna, Austria, July 27 - August 1, 2025, Wanxiang Che, Joyce Nabende, Ekaterin...
work page 2025
-
[3]
Zhenbiao Cao, Yuanlei Zheng, Zhihao Fan, Xiaojin Zhang, Wei Chen, and Xiang Bai. 2024. RSL-SQL: Robust Schema Linking in Text-to-SQL Generation.CoRR abs/2411.00073 (2024). arXiv:2411.00073 doi:10.48550/ARXIV.2411.00073
-
[4]
Liming Chen and Algirdas Avizienis. 1978. N-version programming: A fault- tolerance approach to reliability of software operation. InProc. 8th IEEE Int. Symp. on Fault-Tolerant Computing (FTCS-8), Vol. 1. 3–9
work page 1978
-
[5]
2025.The AI-native open-source embedding database
chroma core. 2025.The AI-native open-source embedding database. https://github. com/chroma-core/chroma Accessed: 2025-10-17
work page 2025
-
[6]
Yeounoh Chung, Gaurav Tarlok Kakkar, Yu Gan, Brenton Milne, and Fatma Ozcan
-
[7]
VLDB Endow.18, 8 (2025), 2735–2747
Is Long Context All You Need? Leveraging LLM’s Extended Context for NL2SQL.Proc. VLDB Endow.18, 8 (2025), 2735–2747
work page 2025
- [8]
-
[9]
Hierons, Kirill Bogdanov, Jonathan P
Robert M. Hierons, Kirill Bogdanov, Jonathan P. Bowen, Rance Cleaveland, John Derrick, Jeremy Dick, Marian Gheorghe, Mark Harman, Kalpesh Kapoor, Paul J. Krause, Gerald Lüttgen, Anthony J. H. Simons, Sergiy A. Vilkomir, Martin R. Woodward, and Hussein Zedan. 2009. Using formal specifications to support testing.ACM Comput. Surv.41, 2 (2009), 9:1–9:76. doi:...
-
[10]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Kai Dang, An Yang, Rui Men, Fei Huang, Xingzhang Ren, Xuancheng Ren, Jingren Zhou, and Junyang Lin. 2024. Qwen2.5-Coder Technical Report.CoRRabs/2409.12186 (2024). arXiv:2409.12186 doi:10.48550/ ARXIV.2409.12186
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, Aleksander Madry, Alex Baker-Whitcomb, Alex Beutel, Alex Borzunov, Alex Carney, Alex Chow, Alex Kirillov, Alex Nichol, Alex Paino, Alex Renzin, Alex Tachard Passos, Alexander Kirillov, Alexi Christakis, Alexis Conneau,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2024
-
[12]
Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean-Bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, Gaël Liu, Francesco Visin, Kathleen Kenealy, Lucas Beyer, Xiaohai ...
-
[13]
Gemma 3 Technical Report.CoRRabs/2503.19786 (2025). arXiv:2503.19786 doi:10.48550/ARXIV.2503.19786
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.19786 2025
- [14]
-
[15]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient Memory Management for Large Language Model Serving with PagedAtten- tion. InProceedings of the 29th Symposium on Operating Systems Principles, SOSP 2023, Koblenz, Germany, October 23-26, 2023, Jason Flinn, Margo I. Se...
-
[16]
Boyan Li, Yuyu Luo, Chengliang Chai, Guoliang Li, and Nan Tang. 2024. The Dawn of Natural Language to SQL: Are We Fully Ready? [Experiment, Analysis & Benchmark ].Proc. VLDB Endow.17, 11 (2024), 3318–3331. doi:10.14778/3681954. 3682003
-
[17]
Boyan Li, Jiayi Zhang, Ju Fan, Yanwei Xu, Chong Chen, Nan Tang, and Yuyu Luo. 2025. Alpha-SQL: Zero-Shot Text-to-SQL using Monte Carlo Tree Search. InForty-second International Conference on Machine Learning. OpenReview.net. https://openreview.net/forum?id=kGg1ndttmI
work page 2025
-
[18]
Haoyang Li, Shang Wu, Xiaokang Zhang, Xinmei Huang, Jing Zhang, Fuxin Jiang, Shuai Wang, Tieying Zhang, Jianjun Chen, Rui Shi, Hong Chen, and Cuiping Li
-
[19]
VLDB Endow.18, 11 (2025), 4695–4709
OmniSQL: Synthesizing High-quality Text-to-SQL Data at Scale.Proc. VLDB Endow.18, 11 (2025), 4695–4709. https://www.vldb.org/pvldb/vol18/p4695-li.pdf
work page 2025
-
[20]
Haoyang Li, Jing Zhang, Hanbing Liu, Ju Fan, Xiaokang Zhang, Jun Zhu, Renjie Wei, Hongyan Pan, Cuiping Li, and Hong Chen. 2024. CodeS: Towards Building Open-source Language Models for Text-to-SQL.Proc. ACM Manag. Data2, 3 (2024), 127. doi:10.1145/3654930
-
[21]
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, et al . 2024. Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls. Advances in Neural Information Processing Systems36 (2024)
work page 2024
-
[22]
Xinyu Liu, Shuyu Shen, Boyan Li, Peixian Ma, Runzhi Jiang, Yuxin Zhang, Ju Fan, Guoliang Li, Nan Tang, and Yuyu Luo. 2025. A Survey of Text-to-SQL in the Era of LLMs: Where Are We, and Where Are We Going?IEEE Trans. Knowl. Data Eng.37, 10 (2025), 5735–5754
work page 2025
-
[23]
Xinyu Liu, Shuyu Shen, Boyan Li, Nan Tang, and Yuyu Luo. 2025. NL2SQL- BUGs: A Benchmark for Detecting Semantic Errors in NL2SQL Translation.CoRR abs/2503.11984 (2025). arXiv:2503.11984 doi:10.48550/ARXIV.2503.11984
-
[24]
Yifu Liu, Yin Zhu, Yingqi Gao, Zhiling Luo, Xiaoxia Li, Xiaorong Shi, Yuntao Hong, Jinyang Gao, Yu Li, Bolin Ding, and Jingren Zhou. 2025. XiYan-SQL: A Novel Multi-Generator Framework For Text-to-SQL.CoRRabs/2507.04701 (2025). arXiv:2507.04701 doi:10.48550/ARXIV.2507.04701
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.04701 2025
-
[25]
Tianqi Luo, Chuhan Huang, Leixian Shen, Boyan Li, Shuyu Shen, Wei Zeng, Nan Tang, and Yuyu Luo. 2025. nvBench 2.0: Resolving Ambiguity in Text- to-Visualization through Stepwise Reasoning.arXiv preprint arXiv:2503.12880 (2025). DeepEye-SQL: A Software-Engineering-Inspired Text-to-SQL Framework Conference’17, July 2017, Washington, DC, USA
-
[26]
Yuyu Luo, Guoliang Li, Ju Fan, Chengliang Chai, and Nan Tang. 2025. Natural Language to SQL: State of the Art and Open Problems.Proc. VLDB Endow.18, 12 (2025), 5466–5471
work page 2025
-
[27]
Yuyu Luo, Xuedi Qin, Nan Tang, and Guoliang Li. 2018. DeepEye: Towards Automatic Data Visualization. In34th IEEE International Conference on Data Engineering, ICDE 2018, Paris, France, April 16-19, 2018. IEEE Computer Society, 101–112. doi:10.1109/ICDE.2018.00019
-
[28]
Yuyu Luo, Nan Tang, Guoliang Li, Chengliang Chai, Wenbo Li, and Xuedi Qin
-
[29]
Synthesizing Natural Language to Visualization (NL2VIS) Benchmarks from NL2SQL Benchmarks. InSIGMOD ’21: International Conference on Management of Data, Virtual Event, China, June 20-25, 2021, Guoliang Li, Zhanhuai Li, Stratos Idreos, and Divesh Srivastava (Eds.). ACM, 1235–1247. doi:10.1145/3448016. 3457261
-
[30]
Yuyu Luo, Nan Tang, Guoliang Li, Jiawei Tang, Chengliang Chai, and Xuedi Qin
-
[31]
Natural Language to Visualization by Neural Machine Translation.IEEE Trans. Vis. Comput. Graph.28, 1 (2022), 217–226. doi:10.1109/TVCG.2021.3114848
-
[32]
Peixian Ma, Boyan Li, Runzhi Jiang, Ju Fan, Nan Tang, and Yuyu Luo. 2024. A Plug-and-Play Natural Language Rewriter for Natural Language to SQL.CoRR abs/2412.17068 (2024). arXiv:2412.17068 doi:10.48550/ARXIV.2412.17068
-
[33]
Karime Maamari, Fadhil Abubaker, Daniel Jaroslawicz, and Amine Mhedhbi
-
[34]
The death of schema linking? text-to-sql in the age of well-reasoned language models,
The Death of Schema Linking? Text-to-SQL in the Age of Well-Reasoned Language Models.CoRRabs/2408.07702 (2024). arXiv:2408.07702 doi:10.48550/ ARXIV.2408.07702
-
[35]
Yury A. Malkov and Dmitry A. Yashunin. 2020. Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs.IEEE Trans. Pattern Anal. Mach. Intell.42, 4 (2020), 824–836. doi:10.1109/TPAMI.2018. 2889473
-
[36]
Joel Ossher, Sushil Krishna Bajracharya, and Cristina Videira Lopes. 2010. Au- tomated dependency resolution for open source software. InProceedings of the 7th International Working Conference on Mining Software Repositories, MSR 2010 (Co-located with ICSE), Cape Town, South Africa, May 2-3, 2010, Proceedings, Jim Whitehead and Thomas Zimmermann (Eds.). I...
-
[37]
Mohammadreza Pourreza, Hailong Li, Ruoxi Sun, Yeounoh Chung, Shayan Talaei, Gaurav Tarlok Kakkar, Yu Gan, Amin Saberi, Fatma Ozcan, and Sercan Ö. Arik
-
[38]
CHASE-SQL: Multi-Path Reasoning and Preference Optimized Candidate Selection in Text-to-SQL. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net. https: //openreview.net/forum?id=CvGqMD5OtX
work page 2025
-
[39]
Mohammadreza Pourreza and Davood Rafiei. 2023. DIN-SQL: Decomposed In- Context Learning of Text-to-SQL with Self-Correction. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, Alice Oh, Tristan Naumann, Amir Globerson, Kate Sae...
work page 2023
-
[40]
Ge Qu, Jinyang Li, Bowen Qin, Xiaolong Li, Nan Huo, Chenhao Ma, and Reynold Cheng. 2025. SHARE: An SLM-based Hierarchical Action CorREction Assistant for Text-to-SQL. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, Austria, July 27 - August 1, 2025, Wanxiang Che, Joyce Na...
work page 2025
-
[41]
M. G. Rekoff. 1985. On reverse engineering.IEEE Trans. Syst. Man Cybern.15, 2 (1985), 244–252. doi:10.1109/TSMC.1985.6313354
-
[42]
Per Runeson. 2006. A Survey of Unit Testing Practices.IEEE Softw.23, 4 (2006), 22–29. doi:10.1109/MS.2006.91
- [43]
-
[44]
Joscha Schnell and Gunther Reinhart. 2016. Quality management for battery production: a quality gate concept.Procedia CIRP57 (2016), 568–573
work page 2016
-
[45]
Philip Sedgwick. 2012. Pearson’s correlation coefficient.Bmj345 (2012)
work page 2012
-
[46]
Lei Sheng and Shuai-Shuai Xu. 2025. CSC-SQL: Corrective Self-Consistency in Text-to-SQL via Reinforcement Learning.CoRRabs/2505.13271 (2025). arXiv:2505.13271 doi:10.48550/ARXIV.2505.13271
-
[47]
Lei Sheng, Shuai-Shuai Xu, and Wei Xie. 2025. BASE-SQL: A powerful open source Text-To-SQL baseline approach.CoRRabs/2502.10739 (2025). arXiv:2502.10739 doi:10.48550/ARXIV.2502.10739
-
[48]
Vladislav Shkapenyuk, Divesh Srivastava, Theodore Johnson, and Parisa Ghane
-
[49]
arXiv:2505.19988 doi:10.48550/ARXIV.2505.19988
Automatic Metadata Extraction for Text-to-SQL.CoRRabs/2505.19988 (2025). arXiv:2505.19988 doi:10.48550/ARXIV.2505.19988
-
[50]
Zhihao Shuai, Boyan Li, Siyu Yan, Yuyu Luo, and Weikai Yang. 2025. DeepVIS: Bridging Natural Language and Data Visualization Through Step-wise Reasoning. CoRRabs/2508.01700 (2025). arXiv:2508.01700 doi:10.48550/ARXIV.2508.01700
-
[51]
Shayan Talaei, Mohammadreza Pourreza, Yu-Chen Chang, Azalia Mirhoseini, and Amin Saberi. 2024. CHESS: Contextual Harnessing for Efficient SQL Synthesis. CoRRabs/2405.16755 (2024). arXiv:2405.16755 doi:10.48550/ARXIV.2405.16755
work page internal anchor Pith review doi:10.48550/arxiv.2405.16755 2024
-
[52]
Martyn Thomas and Frank E. McGarry. 1994. Top-Down vs. Bottom-Up Process Improvement.IEEE Softw.11, 4 (1994), 12–13. doi:10.1109/52.300121
-
[53]
Peter Ulbrich, Martin Hoffmann, Rüdiger Kapitza, Daniel Lohmann, Wolfgang Schroder-Preikschat, and Reiner Schmid. 2012. Eliminating single points of failure in software-based redundancy. In2012 Ninth European Dependable Computing Conference. IEEE, 49–60
work page 2012
-
[54]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V. Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. Self-Consistency Improves Chain of Thought Reasoning in Language Models. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net. https://openreview.net/forum?id=1PL1NIMMrw
work page 2023
- [55]
-
[56]
Xiangjin Xie, Guangwei Xu, Lingyan Zhao, and Ruijie Guo. 2025. OpenSearch- SQL: Enhancing Text-to-SQL with Dynamic Few-shot and Consistency Align- ment.Proc. ACM Manag. Data3, 3 (2025), 194:1–194:24. doi:10.1145/3725331
-
[57]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jian Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, Le Yu, Liangha...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[58]
Jiaxi Yang, Binyuan Hui, Min Yang, Jian Yang, Junyang Lin, and Chang Zhou. 2024. Synthesizing Text-to-SQL Data from Weak and Strong LLMs. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). A...
-
[59]
Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, Zilin Zhang, and Dragomir R. Radev
-
[60]
Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross- Domain Semantic Parsing and Text-to-SQL Task. InEMNLP. Association for Computational Linguistics, 3911–3921
-
[61]
Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, Xionghui Chen, Jiaqi Chen, Mingchen Zhuge, Xin Cheng, Sirui Hong, Jinlin Wang, Bingnan Zheng, Bang Liu, Yuyu Luo, and Chenglin Wu. 2025. AFlow: Automating Agentic Workflow Generation. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenRevi...
work page 2025
-
[62]
Qingjie Zhang, Di Wang, Haoting Qian, Yiming Li, Tianwei Zhang, Minlie Huang, Ke Xu, Hewu Li, Liu Yan, and Han Qiu. 2025. Understanding the Dark Side of LLMs’ Intrinsic Self-Correction. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, Austria, July 27 - August 1, 2025, Wan...
work page 2025
- [63]
-
[64]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. 2025. Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models.CoRRabs/2506.05176 (2025). arXiv:2506.05176 doi:10.48550/ARXIV.2506.05176
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.05176 2025
-
[65]
Yizhang Zhu, Shiyin Du, Boyan Li, Yuyu Luo, and Nan Tang. 2024. Are Large Language Models Good Statisticians?. InNeurIPS
work page 2024
- [66]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.