MTraining: Distributed Dynamic Sparse Attention for Efficient Ultra-Long Context Training
Pith reviewed 2026-05-21 19:38 UTC · model grok-4.3
The pith
MTraining uses dynamic sparse attention with balanced ring mechanisms to train LLMs on 512K token contexts at up to 6x higher throughput while holding accuracy steady.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MTraining integrates a dynamic sparse training pattern, balanced sparse ring attention, and hierarchical sparse ring attention to resolve worker-level and step-level imbalance plus communication overhead when dynamic sparse attention is used for ultra-long contexts. The combined system trains Qwen2.5-3B from 32K to 512K tokens on a 32-GPU A100 cluster, delivering up to 6x higher throughput while producing models that match full-attention baselines on RULER, PG-19, InfiniteBench, and Needle-In-A-Haystack evaluations.
What carries the argument
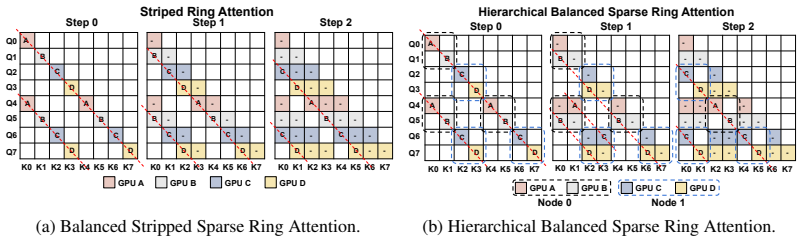
balanced sparse ring attention and hierarchical sparse ring attention, which redistribute uneven computation and communication loads created by dynamic sparsity across workers and training steps
If this is right
- Context windows can be expanded from 32K to 512K tokens on a fixed 32-GPU cluster without a proportional increase in training time.
- Dynamic sparse attention becomes practical for distributed training rather than remaining limited to inference.
- Downstream long-context benchmarks remain at parity with dense-attention training under the reported conditions.
- The same balancing techniques can be applied to other base models that currently use ring attention.
Where Pith is reading between the lines
- The method could be combined with existing sequence parallelism or activation checkpointing to push context lengths beyond 512K on the same hardware budget.
- Energy and carbon costs of long-context pretraining would drop roughly in proportion to the reported throughput gain.
- Similar imbalance-correction logic might transfer to other sparse or mixture-of-experts training regimes that also produce uneven per-token work.
Load-bearing premise
The specific sparse attention patterns chosen dynamically during training do not create systematic gaps that prevent the model from learning important long-range dependencies.
What would settle it
Retraining the same model with full attention on 512K contexts and measuring whether it scores higher than the MTraining version on the longest-distance items in Needle-In-A-Haystack or InfiniteBench.
Figures











read the original abstract
The adoption of long context windows has become a standard feature in Large Language Models (LLMs), as extended contexts significantly enhance their capacity for complex reasoning and broaden their applicability across diverse scenarios. Dynamic sparse attention is a promising approach for reducing the computational cost of long-context. However, efficiently training LLMs with dynamic sparse attention on ultra-long contexts-especially in distributed settings-remains a significant challenge, due in large part to worker- and step-level imbalance. This paper introduces MTraining, a novel distributed methodology leveraging dynamic sparse attention to enable efficient training for LLMs with ultra-long contexts. Specifically, MTraining integrates three key components: a dynamic sparse training pattern, balanced sparse ring attention, and hierarchical sparse ring attention. These components are designed to synergistically address the computational imbalance and communication overheads inherent in dynamic sparse attention mechanisms during the training of models with extensive context lengths. We demonstrate the efficacy of MTraining by training Qwen2.5-3B, successfully expanding its context window from 32K to 512K tokens on a cluster of 32 A100 GPUs. Our evaluations on a comprehensive suite of downstream tasks, including RULER, PG-19, InfiniteBench, and Needle In A Haystack, reveal that MTraining achieves up to a 6x higher training throughput while preserving model accuracy. Our code is available at https://github.com/microsoft/MInference/tree/main/MTraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MTraining, a distributed training framework for LLMs with ultra-long contexts that integrates dynamic sparse attention, balanced sparse ring attention, and hierarchical sparse ring attention to reduce computational imbalance and communication overhead. The authors train Qwen2.5-3B, extending its context window from 32K to 512K tokens on a 32-GPU A100 cluster, and report up to 6x higher training throughput while preserving accuracy on RULER, PG-19, InfiniteBench, and Needle-In-A-Haystack evaluations.
Significance. If the results hold, the work would be significant for practical long-context LLM training by demonstrating concrete wall-clock throughput gains on real hardware and models without apparent accuracy loss. The use of multiple long-context benchmarks and the release of code at the cited GitHub repository strengthen the practical contribution.
major comments (3)
- [Evaluation / Experiments] The central claim that accuracy is preserved on RULER, PG-19, InfiniteBench, and Needle-In-A-Haystack rests on the assumption that the dynamic sparse pattern supplies sufficient gradient signal for long-range dependencies. No ablation is reported that freezes the sparsity mask versus allowing it to evolve dynamically, nor is the fraction of long-range (>32k) tokens receiving zero gradient measured across training steps.
- [Methods] The dynamic sparse training pattern is introduced as one of the three key components, but the exact selection criterion (attention scores, proxy, or otherwise) and its per-step evolution are not specified in sufficient detail to assess whether low-attention long-range tokens are systematically under-sampled, which would create a training-time distribution shift undetectable by the downstream evals.
- [Results / Implementation] The 6x throughput result on the 32-GPU cluster is load-bearing for the efficiency claim, yet it is unclear whether the load-balancing rules in balanced sparse ring attention and hierarchical sparse ring attention were tuned post-hoc to the reported runs or derived parameter-free from the sparsity pattern.
minor comments (2)
- [Abstract] The benchmark is referred to as 'Needle In A Haystack' in the abstract; standardize to 'Needle-In-A-Haystack' for consistency with common usage.
- [Abstract / Appendix] The code link is provided, but the manuscript does not include a reproducibility checklist or details on random seeds, hyperparameter search ranges, or exact sparsity thresholds used in the reported experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below with clarifications and indicate where revisions will be made to strengthen the paper.
read point-by-point responses
-
Referee: [Evaluation / Experiments] The central claim that accuracy is preserved on RULER, PG-19, InfiniteBench, and Needle-In-A-Haystack rests on the assumption that the dynamic sparse pattern supplies sufficient gradient signal for long-range dependencies. No ablation is reported that freezes the sparsity mask versus allowing it to evolve dynamically, nor is the fraction of long-range (>32k) tokens receiving zero gradient measured across training steps.
Authors: We agree that an ablation study contrasting a frozen sparsity mask against the dynamic version would provide stronger support for the role of dynamic evolution in preserving long-range gradient signals. In the revised manuscript we will add this ablation on the Qwen2.5-3B model, showing that the dynamic pattern yields measurably better downstream performance on long-context benchmarks. We will also report the measured fraction of long-range (>32k) tokens that receive zero gradient at multiple training checkpoints; our internal analysis indicates this fraction is kept low by the hierarchical component, and we will include the corresponding statistics and plots. revision: yes
-
Referee: [Methods] The dynamic sparse training pattern is introduced as one of the three key components, but the exact selection criterion (attention scores, proxy, or otherwise) and its per-step evolution are not specified in sufficient detail to assess whether low-attention long-range tokens are systematically under-sampled, which would create a training-time distribution shift undetectable by the downstream evals.
Authors: We thank the referee for highlighting the need for greater methodological transparency. The dynamic sparse training pattern selects tokens using a hybrid criterion that combines attention scores computed via a lightweight proxy model with positional priors designed to guarantee coverage of distant positions. The mask is recomputed at every training step from the current model activations. We will expand Section 3.1 with precise pseudocode, the exact proxy formulation, and an explicit discussion of how the selection rule prevents systematic under-sampling of long-range tokens, thereby allowing readers to evaluate potential distribution-shift concerns. revision: yes
-
Referee: [Results / Implementation] The 6x throughput result on the 32-GPU cluster is load-bearing for the efficiency claim, yet it is unclear whether the load-balancing rules in balanced sparse ring attention and hierarchical sparse ring attention were tuned post-hoc to the reported runs or derived parameter-free from the sparsity pattern.
Authors: The load-balancing rules in both balanced sparse ring attention and hierarchical sparse ring attention are derived directly and in a parameter-free manner from the instantaneous sparsity pattern: token-to-GPU assignments are computed from the per-token sparsity mask using a deterministic balancing procedure described in Sections 3.2 and 3.3. No post-hoc tuning specific to the reported 32-GPU runs was performed. To remove any ambiguity we will add an explicit statement in the revised Results section confirming the parameter-free derivation and will include a short algorithmic description of the balancing step. revision: partial
Circularity Check
No circularity; central claims rest on independent empirical measurements
full rationale
The paper reports measured wall-clock throughput gains (up to 6x) and downstream accuracy preservation on RULER, PG-19, InfiniteBench, and Needle-In-A-Haystack after training Qwen2.5-3B from 32K to 512K context on 32 A100 GPUs. These outcomes are obtained from direct experimental runs rather than quantities defined in terms of the same fitted parameters or self-citation chains. The described components (dynamic sparse training pattern, balanced sparse ring attention, hierarchical sparse ring attention) function as engineering choices whose efficacy is validated externally by the reported benchmarks, with no load-bearing step reducing a prediction to an input by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Dynamic sparse attention patterns chosen during training preserve sufficient gradient information for long-range dependency learning.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
dynamic sparse training pattern... Vertical-Slash locality pattern... Balanced Sparse Ring Attention... Hierarchical Sparse Ring Attention
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 3.1... expectation of the attention weights after applying RoPE depends solely on the relative position n-m
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
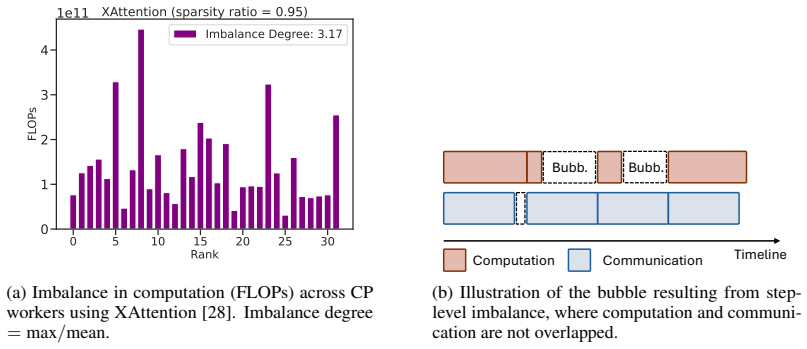
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
DashAttention: Differentiable and Adaptive Sparse Hierarchical Attention
DashAttention introduces differentiable adaptive sparse hierarchical attention via α-entmax block selection, achieving full-attention accuracy at 75% sparsity with improved Pareto performance over NSA and InfLLMv2.
Reference graph
Works this paper leans on
-
[1]
Avi Caciularu, Matthew E Peters, Jacob Goldberger, Ido Dagan, and Arman Cohan. Peek across: Improving multi-document modeling via cross-document question-answering.arXiv preprint arXiv:2305.15387, 2023
-
[2]
Yubo Ma, Yuhang Zang, Liangyu Chen, Meiqi Chen, Yizhu Jiao, Xinze Li, Xinyuan Lu, Ziyu Liu, Yan Ma, Xiaoyi Dong, et al. Mmlongbench-doc: Benchmarking long-context document understanding with visualizations.arXiv preprint arXiv:2407.01523, 2024
-
[3]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Livecodebench: Holistic and contamination free evaluation of large language models for code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[5]
OpenAI. Introducing deep research. https://openai.com/index/ introducing-deep-research/. Accessed: Feb 2, 2025
work page 2025
-
[6]
Leave it to manus.https://manus.im/
Manus. Leave it to manus.https://manus.im/. Accessed: May 15, 2025
work page 2025
-
[7]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
An Yang, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoyan Huang, Jiandong Jiang, Jianhong Tu, Jianwei Zhang, Jingren Zhou, et al. Qwen2. 5-1m technical report.arXiv preprint arXiv:2501.15383, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
How to train long- context language models (effectively)
Tianyu Gao, Alexander Wettig, Howard Yen, and Danqi Chen. How to train long-context language models (effectively).arXiv preprint arXiv:2410.02660, 2024
-
[13]
QUEST: Query-aware sparsity for efficient long-context LLM inference
Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, and Song Han. QUEST: Query-aware sparsity for efficient long-context LLM inference. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[14]
Huiqiang Jiang, Yucheng Li, Chengruidong Zhang, Qianhui Wu, Xufang Luo, Surin Ahn, Zhenhua Han, Amir Abdi, Dongsheng Li, Chin-Yew Lin, et al. Minference 1.0: Accelerating pre-filling for long-context llms via dynamic sparse attention.Advances in Neural Information Processing Systems, 37:52481–52515, 2024
work page 2024
-
[15]
Flexprefill: A context- aware sparse attention mechanism for efficient long-sequence inference
Xunhao Lai, Jianqiao Lu, Yao Luo, Yiyuan Ma, and Xun Zhou. Flexprefill: A context- aware sparse attention mechanism for efficient long-sequence inference. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[16]
Sparq attention: Bandwidth-efficient LLM inference
Luka Ribar, Ivan Chelombiev, Luke Hudlass-Galley, Charlie Blake, Carlo Luschi, and Douglas Orr. Sparq attention: Bandwidth-efficient LLM inference. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[17]
Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
Jingyang Yuan, Huazuo Gao, Damai Dai, Junyu Luo, Liang Zhao, Zhengyan Zhang, Zhenda Xie, YX Wei, Lean Wang, Zhiping Xiao, et al. Native sparse attention: Hardware-aligned and natively trainable sparse attention.arXiv preprint arXiv:2502.11089, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
MoBA: Mixture of Block Attention for Long-Context LLMs
Enzhe Lu, Zhejun Jiang, Jingyuan Liu, Yulun Du, Tao Jiang, Chao Hong, Shaowei Liu, Weiran He, Enming Yuan, Yuzhi Wang, et al. Moba: Mixture of block attention for long-context llms. arXiv preprint arXiv:2502.13189, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Ring attention with blockwise transformers for near-infinite context
Hao Liu, Matei Zaharia, and Pieter Abbeel. Ring attention with blockwise transformers for near-infinite context. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[20]
Striped attention: Faster ring attention for causal transformers
William Brandon, Aniruddha Nrusimha, Kevin Qian, Zachary Ankner, Tian Jin, Zhiye Song, and Jonathan Ragan-Kelley. Striped attention: Faster ring attention for causal transformers. arXiv preprint arXiv:2311.09431, 2023
-
[21]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2. 5 technical report.arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, and Boris Ginsburg. RULER: What’s the real context size of your long-context language models? InFirst Conference on Language Modeling, 2024
work page 2024
-
[23]
Needle in a haystack - pressure testing llms, 2023
Greg Kamradt. Needle in a haystack - pressure testing llms, 2023
work page 2023
-
[24]
Infinitebench: Extending long context evaluation beyond 100K tokens
Xinrong Zhang, Yingfa Chen, Shengding Hu, Zihang Xu, Junhao Chen, Moo Hao, Xu Han, Zhen Thai, Shuo Wang, Zhiyuan Liu, and Maosong Sun. Infinitebench: Extending long context evaluation beyond 100K tokens. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volum...
work page 2024
-
[25]
Compressive Transformers for Long-Range Sequence Modelling
Jack W Rae, Anna Potapenko, Siddhant M Jayakumar, and Timothy P Lillicrap. Compressive transformers for long-range sequence modelling.arXiv preprint arXiv:1911.05507, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[26]
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022. 11
work page 2022
-
[27]
[Feature request] balancing computation with zigzag blocking
Zilin Zhu. [Feature request] balancing computation with zigzag blocking. https://github. com/zhuzilin/ring-flash-attention/issues/2, February 2024. GitHub issue #2; ac- cessed 13 May 2025
work page 2024
-
[28]
Xattention: Block sparse attention with antidiagonal scoring.arXiv preprint arXiv:2503.16428,
Ruyi Xu, Guangxuan Xiao, Haofeng Huang, Junxian Guo, and Song Han. Xattention: Block sparse attention with antidiagonal scoring.arXiv preprint arXiv:2503.16428, 2025
-
[29]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
work page 2024
-
[30]
Diandian Gu, Peng Sun, Qinghao Hu, Ting Huang, Xun Chen, Yingtong Xiong, Guoteng Wang, Qiaoling Chen, Shangchun Zhao, Jiarui Fang, et al. Loongtrain: Efficient training of long-sequence llms with head-context parallelism.arXiv preprint arXiv:2406.18485, 2024
-
[31]
{nnScaler}:{Constraint-Guided} parallelization plan generation for deep learning training
Zhiqi Lin, Youshan Miao, Quanlu Zhang, Fan Yang, Yi Zhu, Cheng Li, Saeed Maleki, Xu Cao, Ning Shang, Yilei Yang, et al. {nnScaler}:{Constraint-Guided} parallelization plan generation for deep learning training. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 347–363, 2024
work page 2024
-
[32]
Zero: Memory optimiza- tions toward training trillion parameter models
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimiza- tions toward training trillion parameter models. InSC20: International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–16. IEEE, 2020
work page 2020
-
[33]
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Chen, Hy- oukJoong Lee, Jiquan Ngiam, Quoc V Le, Yonghui Wu, et al. Gpipe: Efficient training of giant neural networks using pipeline parallelism.Advances in neural information processing systems, 32, 2019
work page 2019
-
[34]
Training Deep Nets with Sublinear Memory Cost
Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. Training deep nets with sublinear memory cost.arXiv preprint arXiv:1604.06174, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[35]
Junxian Guo, Haotian Tang, Shang Yang, Zhekai Zhang, Zhijian Liu, and Song Han. Block Sparse Attention. https://github.com/mit-han-lab/Block-Sparse-Attention , 2024
work page 2024
-
[36]
Pit: Optimization of dynamic sparse deep learning models via permutation invariant transformation
Ningxin Zheng, Huiqiang Jiang, Quanlu Zhang, Zhenhua Han, Lingxiao Ma, Yuqing Yang, Fan Yang, Chengruidong Zhang, Lili Qiu, Mao Yang, et al. Pit: Optimization of dynamic sparse deep learning models via permutation invariant transformation. InProceedings of the 29th Symposium on Operating Systems Principles, pages 331–347, 2023
work page 2023
-
[37]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th Symposium on Operating Systems Principles, pages 611–626, 2023
work page 2023
-
[38]
YaRN: Efficient context window extension of large language models
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. YaRN: Efficient context window extension of large language models. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[39]
Vijay Anand Korthikanti, Jared Casper, Sangkug Lym, Lawrence McAfee, Michael Ander- sch, Mohammad Shoeybi, and Bryan Catanzaro. Reducing activation recomputation in large transformer models.Proceedings of Machine Learning and Systems, 5:341–353, 2023
work page 2023
-
[40]
System optimizations for enabling training of extreme long sequence transformer models
Sam Ade Jacobs, Masahiro Tanaka, Chengming Zhang, Minjia Zhang, Reza Yazdani Aminadabi, Shuaiwen Leon Song, Samyam Rajbhandari, and Yuxiong He. System optimizations for enabling training of extreme long sequence transformer models. InProceedings of the 43rd ACM Symposium on Principles of Distributed Computing, pages 121–130, 2024
work page 2024
-
[41]
Mini-sequence transformers: Optimizing intermediate memory for long sequences training
Cheng Luo, Jiawei Zhao, Zhuoming Chen, Beidi Chen, and Anima Anandkumar. Mini-sequence transformers: Optimizing intermediate memory for long sequences training. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[42]
Jiarui Fang and Shangchun Zhao. Usp: A unified sequence parallelism approach for long context generative ai.arXiv preprint arXiv:2405.07719, 2024. 12
-
[43]
Hao Ge, Junda Feng, Qi Huang, Fangcheng Fu, Xiaonan Nie, Lei Zuo, Haibin Lin, Bin Cui, and Xin Liu. Bytescale: Efficient scaling of llm training with a 2048k context length on more than 12,000 gpus.arXiv preprint arXiv:2502.21231, 2025
-
[44]
Zheng Wang, Anna Cai, Xinfeng Xie, Zaifeng Pan, Yue Guan, Weiwei Chu, Jie Wang, Shikai Li, Jianyu Huang, Chris Cai, et al. Wlb-llm: Workload-balanced 4d parallelism for large language model training.arXiv preprint arXiv:2503.17924, 2025
-
[45]
Flexsp: Accelerating large language model training via flexible sequence parallelism
Yujie Wang, Shiju Wang, Shenhan Zhu, Fangcheng Fu, Xinyi Liu, Xuefeng Xiao, Huixia Li, Jiashi Li, Faming Wu, and Bin Cui. Flexsp: Accelerating large language model training via flexible sequence parallelism. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, pages 421–...
work page 2025
- [46]
-
[47]
Tao Zewei and Huang Yunpeng. Magiattention: A distributed attention towards linear scalability for ultra-long context, heterogeneous mask training. https://github.com/SandAI-org/ MagiAttention/, 2025
work page 2025
-
[48]
LongroPE: Extending LLM context window beyond 2 million tokens
Yiran Ding, Li Lyna Zhang, Chengruidong Zhang, Yuanyuan Xu, Ning Shang, Jiahang Xu, Fan Yang, and Mao Yang. LongroPE: Extending LLM context window beyond 2 million tokens. In Forty-first International Conference on Machine Learning, 2024
work page 2024
-
[49]
A length-extrapolatable transformer
Yutao Sun, Li Dong, Barun Patra, Shuming Ma, Shaohan Huang, Alon Benhaim, Vishrav Chaudhary, Xia Song, and Furu Wei. A length-extrapolatable transformer. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors,Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14590–14604, Toronto...
work page 2023
-
[50]
Extending Context Window of Large Language Models via Positional Interpolation
Shouyuan Chen, Sherman Wong, Liangjian Chen, and Yuandong Tian. Extending context window of large language models via positional interpolation.arXiv preprint arXiv:2306.15595, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
Training-free long-context scaling of large language models
Chenxin An, Fei Huang, Jun Zhang, Shansan Gong, Xipeng Qiu, Chang Zhou, and Lingpeng Kong. Training-free long-context scaling of large language models. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[53]
Chenxin An, Jun Zhang, Ming Zhong, Lei Li, Shansan Gong, Yao Luo, Jingjing Xu, and Lingpeng Kong. Why does the effective context length of LLMs fall short? InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[54]
KIVI: A tuning-free asymmetric 2bit quantization for KV cache
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. KIVI: A tuning-free asymmetric 2bit quantization for KV cache. In Forty-first International Conference on Machine Learning, 2024
work page 2024
-
[55]
Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W Mahoney, Sophia Shao, Kurt Keutzer, and Amir Gholami. Kvquant: Towards 10 million context length llm inference with kv cache quantization.Advances in Neural Information Processing Systems, 37:1270–1303, 2024
work page 2024
-
[56]
Yutao Sun, Li Dong, Yi Zhu, Shaohan Huang, Wenhui Wang, Shuming Ma, Quanlu Zhang, Jianyong Wang, and Furu Wei. You only cache once: Decoder-decoder architectures for language models.Advances in Neural Information Processing Systems, 37:7339–7361, 2024
work page 2024
-
[57]
Daniel Goldstein, Fares Obeid, Eric Alcaide, Guangyu Song, and Eugene Cheah. Goldfinch: High performance rwkv/transformer hybrid with linear pre-fill and extreme kv-cache compres- sion.arXiv preprint arXiv:2407.12077, 2024. 13
-
[58]
GQA: Training generalized multi-query transformer models from multi-head checkpoints
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebron, and Sumit Sanghai. GQA: Training generalized multi-query transformer models from multi-head checkpoints. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 4895–4901, Singapor...
work page 2023
-
[59]
DHA: Learning decoupled-head attention from transformer checkpoints via adaptive heads fusion
Yilong Chen, Linhao Zhang, Junyuan Shang, Zhenyu Zhang, Tingwen Liu, Shuohuan Wang, and Yu Sun. DHA: Learning decoupled-head attention from transformer checkpoints via adaptive heads fusion. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[60]
LLM maybe longLM: Selfextend LLM context window without tuning
Hongye Jin, Xiaotian Han, Jingfeng Yang, Zhimeng Jiang, Zirui Liu, Chia-Yuan Chang, Huiyuan Chen, and Xia Hu. LLM maybe longLM: Selfextend LLM context window without tuning. In Forty-first International Conference on Machine Learning, 2024
work page 2024
-
[61]
Wonbeom Lee, Jungi Lee, Junghwan Seo, and Jaewoong Sim. {InfiniGen}: Efficient generative inference of large language models with dynamic {KV} cache management. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 155–172, 2024
work page 2024
-
[62]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[63]
Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santi- ago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, et al. Big bird: Transformers for longer sequences.Advances in neural information processing systems, 33:17283–17297, 2020
work page 2020
-
[64]
Reformer: The Efficient Transformer
Nikita Kitaev, Łukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer. arXiv preprint arXiv:2001.04451, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[65]
Abdi, Dongsheng Li, Jianfeng Gao, Yuqing Yang, and Lili Qiu
Yucheng Li, Huiqiang Jiang, Chengruidong Zhang, Qianhui Wu, Xufang Luo, Surin Ahn, Amir H. Abdi, Dongsheng Li, Jianfeng Gao, Yuqing Yang, and Lili Qiu. MMInference: Accelerating pre-filling for long-context visual language models via modality-aware permutation sparse attention. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[66]
Jintao Zhang, Chendong Xiang, Haofeng Huang, Jia Wei, Haocheng Xi, Jun Zhu, and Jianfei Chen. Spargeattn: Accurate sparse attention accelerating any model inference.arXiv preprint arXiv:2502.18137, 2025
-
[67]
MagicPIG: LSH sampling for efficient LLM generation
Zhuoming Chen, Ranajoy Sadhukhan, Zihao Ye, Yang Zhou, Jianyu Zhang, Niklas Nolte, Yuandong Tian, Matthijs Douze, Leon Bottou, Zhihao Jia, and Beidi Chen. MagicPIG: LSH sampling for efficient LLM generation. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[68]
Adam: A Method for Stochastic Optimization
Diederik P Kingma. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014. 14 A Scalability of MTraining 0 10 20 30 40 50 60 Training Iteration 1 2 4 6Training Loss Dense MTraining Figure 10: The training loss comparison of dense attention and MTrainig during continued pretraining of Llama-3.1-8B-Instruct on the ProLong dataset wi...
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[69]
XAttention [28]. XAttention score square blocks by summing every certain stride along their antidiagonals and retains only the high-score blocks, giving a plug-and-play, training-free block- sparse attention that accelerates prefill while matching dense accuracy. In our experiments, we use the following settings with granularity being 128 as the block siz...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.