What's In My Human Feedback? Learning Interpretable Descriptions of Preference Data
Pith reviewed 2026-05-18 03:36 UTC · model grok-4.3
The pith
Sparse autoencoders extract a small number of interpretable features that capture most of the preference signal in human feedback data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
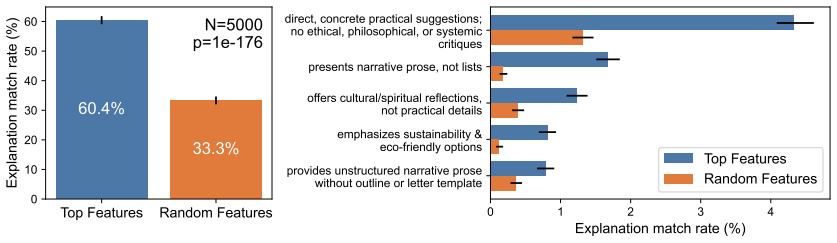
WIMHF is a method to explain feedback data using sparse autoencoders. It characterizes both the preferences a dataset is capable of measuring and the preferences that the annotators actually express. Across 7 datasets, WIMHF identifies a small number of human-interpretable features that account for the majority of the preference prediction signal achieved by black-box models.
What carries the argument
Sparse autoencoders trained on preference data to recover a small set of sparse, human-interpretable features that represent what the data encodes.
If this is right
- Features reveal wide diversity in preferences, such as Reddit users favoring informality and jokes while HH-RLHF and PRISM annotators disfavor them.
- The method surfaces unsafe preferences, including LMArena users voting against refusals often in favor of toxic content.
- Re-labeling harmful examples identified by the features produces large safety gains of 37 percent with no reduction in general performance.
- Learning annotator-specific weights over the subjective features improves preference prediction on datasets like Community Alignment.
Where Pith is reading between the lines
- The same decomposition could be applied to ongoing data collection to monitor whether preferences shift as models improve or new annotator pools are added.
- Reward models built from these features might enable more precise control over alignment objectives than current scalar reward approaches.
- Testing the method on preference data from non-text domains or multimodal models would check whether the low-dimensional structure generalizes.
Load-bearing premise
The sparse autoencoder features learned from the preference data are faithful representations of the underlying human preferences rather than artifacts of the autoencoder training process or the specific model used to embed the data.
What would settle it
Retraining the sparse autoencoders on the same datasets with different random seeds or embedding models and observing that the extracted features no longer predict held-out preferences or yield safety gains when used for re-labeling would falsify the central claim.
Figures








read the original abstract
Human feedback can alter language models in unpredictable and undesirable ways, as practitioners lack a clear understanding of what feedback data encodes. While prior work studies preferences over certain attributes (e.g., length or sycophancy), automatically extracting relevant features without pre-specifying hypotheses remains challenging. We introduce What's In My Human Feedback? (WIMHF), a method to explain feedback data using sparse autoencoders. WIMHF characterizes both (1) the preferences a dataset is capable of measuring and (2) the preferences that the annotators actually express. Across 7 datasets, WIMHF identifies a small number of human-interpretable features that account for the majority of the preference prediction signal achieved by black-box models. These features reveal a wide diversity in what humans prefer, and the role of dataset-level context: for example, users on Reddit prefer informality and jokes, while annotators in HH-RLHF and PRISM disprefer them. WIMHF also surfaces potentially unsafe preferences, such as that LMArena users tend to vote against refusals, often in favor of toxic content. The learned features enable effective data curation: re-labeling the harmful examples in Arena yields large safety gains (+37%) with no cost to general performance. They also allow fine-grained personalization: on the Community Alignment dataset, we learn annotator-specific weights over subjective features that improve preference prediction. WIMHF provides a human-centered analysis method for practitioners to better understand and use preference data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WIMHF, a method applying sparse autoencoders to human preference datasets to extract small sets of human-interpretable features. Across seven datasets it claims these features capture the majority of the predictive signal achieved by black-box preference models, surface diverse and sometimes unsafe preferences (e.g., Reddit favoring informality while HH-RLHF disfavors it; Arena users voting against refusals), and enable downstream uses such as safety-oriented data curation (+37% safety gains) and annotator-specific personalization on the Community Alignment dataset.
Significance. If the empirical claims are robust, WIMHF supplies a practical post-hoc interpretability technique for preference data that could help practitioners diagnose hidden biases, improve curation, and support personalized alignment. The approach extends SAE-based dictionary learning to the preference-modeling setting and the reported curation and personalization results indicate concrete utility beyond pure analysis.
major comments (2)
- §4 (Experiments) and associated tables: the central claim that a small number of interpretable SAE features recover the majority of black-box preference prediction performance requires a direct head-to-head comparison (black-box model vs. full SAE vs. top-k interpretable features) on held-out preference labels with quantitative metrics such as accuracy or log-likelihood. No such comparison is reported, leaving open whether the selected features truly account for most of the signal or whether performance drops substantially once only the human-interpretable subset is retained.
- §3.2 (Method) and §4.1: the manuscript does not present ablations on SAE hyperparameters (dictionary size, L1 sparsity coefficient) or on the choice of embedding model. Because the strongest claim depends on the SAE decomposition being both faithful and sufficiently sparse, sensitivity to these choices is load-bearing; without them the robustness of the “small number of features” result across the seven datasets cannot be assessed.
minor comments (3)
- Notation for the autoencoder loss (reconstruction + sparsity) should be introduced with explicit symbols in §3 rather than left implicit.
- Figure captions for feature activation visualizations would benefit from example preference pairs that activate each feature, to aid reader interpretation.
- A short related-work paragraph contrasting WIMHF with prior attribute-specific analyses (length, sycophancy, etc.) would help situate the contribution.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We agree that additional quantitative comparisons and robustness checks will strengthen the empirical support for our central claims. We address each major comment below and will incorporate the suggested revisions in the next version of the manuscript.
read point-by-point responses
-
Referee: §4 (Experiments) and associated tables: the central claim that a small number of interpretable SAE features recover the majority of black-box preference prediction performance requires a direct head-to-head comparison (black-box model vs. full SAE vs. top-k interpretable features) on held-out preference labels with quantitative metrics such as accuracy or log-likelihood. No such comparison is reported, leaving open whether the selected features truly account for most of the signal or whether performance drops substantially once only the human-interpretable subset is retained.
Authors: We agree that a direct head-to-head comparison on held-out data is necessary to rigorously support the claim. In the revised manuscript we will add results comparing the black-box preference model, the full SAE reconstruction, and a linear model using only the top-k human-interpretable features, evaluated with accuracy and log-likelihood on held-out preference pairs. This will quantify the fraction of predictive signal retained by the interpretable subset across the seven datasets. revision: yes
-
Referee: §3.2 (Method) and §4.1: the manuscript does not present ablations on SAE hyperparameters (dictionary size, L1 sparsity coefficient) or on the choice of embedding model. Because the strongest claim depends on the SAE decomposition being both faithful and sufficiently sparse, sensitivity to these choices is load-bearing; without them the robustness of the “small number of features” result across the seven datasets cannot be assessed.
Authors: We acknowledge that sensitivity analyses are important for establishing robustness. We will add ablations in the revised manuscript that vary dictionary size and the L1 coefficient, and we will report results using at least one alternative embedding model. These experiments will confirm that the finding of a small number of interpretable features capturing most of the signal is stable across reasonable hyperparameter regimes. revision: yes
Circularity Check
No significant circularity; claims rest on held-out evaluations and independent experiments
full rationale
The paper trains sparse autoencoders on preference data to extract features and then evaluates how well a small number of interpretable features recover the predictive performance of black-box models. This evaluation is described as occurring across 7 datasets with applications to curation and personalization, implying standard held-out testing rather than direct equivalence to fitted parameters. No equations or steps reduce the central claim to a self-definition, a renamed fit, or a load-bearing self-citation chain. The derivation remains self-contained against external benchmarks such as black-box performance and downstream task gains.
Axiom & Free-Parameter Ledger
free parameters (1)
- sparsity level / L1 coefficient
axioms (1)
- domain assumption Sparse autoencoders can decompose preference signals into human-interpretable features without supervision on those features.
Forward citations
Cited by 2 Pith papers
-
Understanding Annotator Safety Policy with Interpretability
Annotator Policy Models learn safety policies from labeling behavior alone, accurately predicting responses and revealing sources of disagreement like policy ambiguity and value pluralism.
-
Compared to What? Baselines and Metrics for Counterfactual Prompting
Counterfactual prompting effects on LLMs are often indistinguishable from those caused by meaning-preserving paraphrases, causing most previously reported demographic sensitivities to disappear under proper statistica...
Reference graph
Works this paper leans on
-
[1]
doi: 10.1002/jrsm.1255. B. Bussmann, P. Leask, and N. Nanda. BatchTopK Sparse Autoencoders, Dec. 2024. B. Bussmann, N. Nabeshima, A. Karvonen, and N. Nanda. Learning Multi-Level Features with Matryoshka Sparse Autoencoders, Mar. 2025. W. Chi, V. Chen, A. N. Angelopoulos, W.-L. Chiang, A. Mittal, N. Jain, T. Zhang, I. Stoica, C. Donahue, and A. Talwalkar. ...
-
[2]
URLhttps://arxiv.org/abs/2310.11523. 15 Y. Zhao, K. Zhang, T. Hu, S. Wu, R. L. Bras, T. Anderson, J. Bragg, J. C. Chang, J. Dodge, M. Latzke, Y. Liu, C. McGrady , X. Tang, Z. Wang, C. Zhao, H. Hajishirzi, D. Downey , and A. Cohan. SciArena: An Open Evaluation Platform for Foundation Models in Scientific Literature Tasks, July 2025. K. Zhou, J. D. Hwang, X...
-
[3]
Remove rows with empty prompts or responses
-
[4]
Remove non-English prompts as annotated by the original dataset creators, or otherwise with fastText language ID5
-
[5]
Remove very long conversations with over 2048 tokens (this is<1% of all data)
work page 2048
-
[6]
Randomly swap response A and response B to avoid any position bias
-
[7]
addresses the user’s request with creativity and clarity
Remove any rows where both response A and response B are marked as subjective by gpt-4.1-mini, using the same prompt as in Huang et al. [2025]. 6.Reddit : To preprocess the Stanford Human Preferences data, in addition to the above steps, we include only the pairs of comments where the preferred comment has at least 10 upvotes and at least twice as many up...
work page 2025
-
[8]
Helpful: Does this concept help you understand what humans prefer? If you were studying this dataset, and your goal was to understand what humans prefer, is this a concept you would explore further? Rate 1 if yes, 0 if no or only a little
-
[9]
Interpretable: When you read the concept, is it clear what it means? If you saw a prompt and a response, could you easily decide whether that response contains that concept? Rate 1 if yes, 0 if no / would often be subjective. 6The ICAI default is 𝑃= 5, and we show that trends hold with this in App. C. We use 𝑃= 10 to more clearly establish differences bet...
work page 2017
-
[10]
The task is to assess whether the automated response attributes are closely related to the attributes mentioned by the annotator. For example, if the feature is “does not discuss AI”, and the annotator says “I didn’t like the discussion about AI”, then the feature IS present. On the other hand, if the annotator says “I liked the suggestion of a surprise p...
-
[11]
Directionality does not matter, only relevance. For example, if the feature is “does not discuss AI”, and the annotator says “I really liked the discussion of AI”, then the feature IS considered present, since AI is mentioned as relevant to the annotator’s choice
-
[12]
does not discuss the environment
Prioritize precision. If a feature is imprecise, and it only loosely matches the annotator’s explanation, then it should NOT be counted. Annotator Explanation:{annotator_explanation} Features Predicted by Automated Explanation:{automated_explanation} If No, output an empty list: [] If Yes, output a list of indices of the features that are present in the a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.