Cortex AISQL: A Production SQL Engine for Unstructured Data
Pith reviewed 2026-05-17 23:22 UTC · model grok-4.3
The pith
Cortex AISQL integrates semantic operations into SQL with cost-aware planning, model cascades, and join rewriting to deliver major speedups on unstructured data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AISQL addresses the efficiency barriers of semantic operations by treating LLM inference cost as a first-class objective in query planning, by routing the bulk of rows through fast proxy models and escalating only uncertain cases to a stronger oracle model, and by reformulating semantic joins as multi-label classification tasks. The first technique yields 2-8× speedups, the second 2-6× speedups at 90-95 percent of oracle quality, and the third 15-70× speedups with often higher prediction quality. The resulting engine is deployed in production at Snowflake and supports customer workloads in analytics, search, and content understanding.
What carries the argument
Three cooperating techniques: AI-aware query optimization that reasons directly about LLM costs, adaptive model cascades that combine a fast proxy with an oracle model, and semantic join query rewriting that converts quadratic joins into linear multi-label classification.
If this is right
- Query planners can now treat model inference cost as an explicit, quantifiable objective alongside traditional metrics such as cardinality.
- Most rows in a semantic pipeline can be handled by cheap proxy models while quality remains close to that of the full oracle model.
- Semantic joins no longer scale quadratically because the problem is recast as a linear-time classification task.
- Production SQL engines can support mixed structured-unstructured workloads without requiring users to write custom glue code.
Where Pith is reading between the lines
- The same cost-modeling and cascade ideas could be adapted to other database systems that embed large language models for data cleaning or enrichment.
- Collecting telemetry from live deployments appears to be a practical way to calibrate cost and selectivity estimates for semantic operators.
- Extending the classification reformulation to other set-oriented semantic operations might further reduce the gap between relational and AI-driven query performance.
Load-bearing premise
The three techniques, tuned on Snowflake customer workloads and chosen models, will continue to deliver comparable speedups and quality when applied to different workloads or different underlying language models.
What would settle it
Run the same semantic SQL queries on a fresh set of customer data and models never seen during the original development and measure whether the reported speedups and quality retention still hold.
Figures


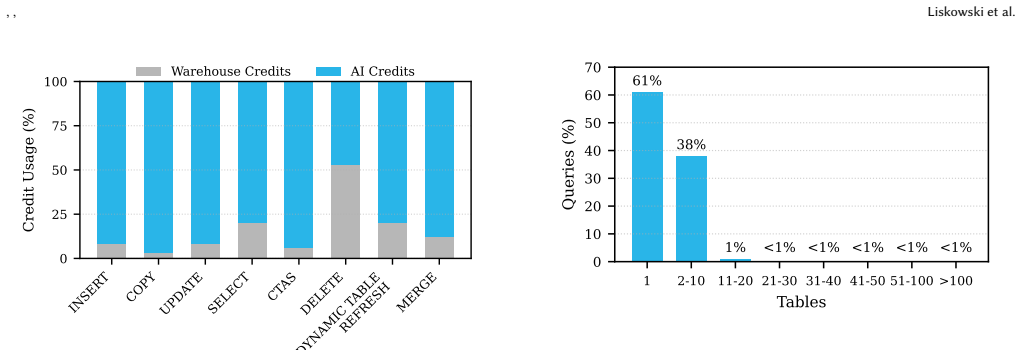



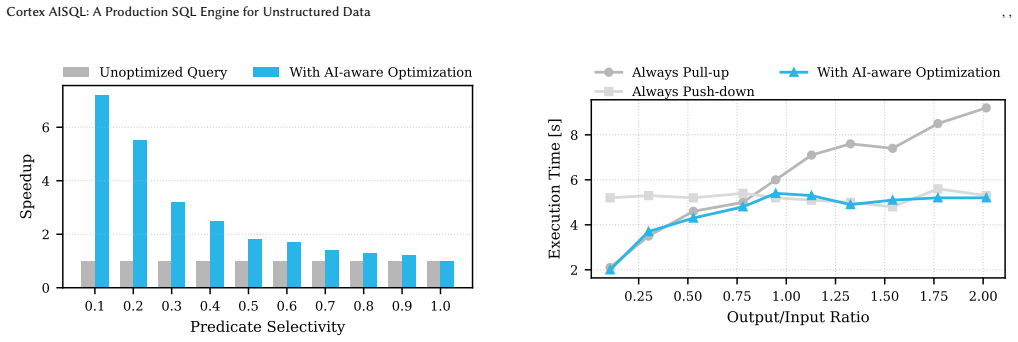


read the original abstract
Snowflake's Cortex AISQL is a production SQL engine that integrates native semantic operations directly into SQL. This integration allows users to write declarative queries that combine relational operations with semantic reasoning, enabling them to query both structured and unstructured data effortlessly. However, making semantic operations efficient at production scale poses fundamental challenges. Semantic operations are more expensive than traditional SQL operations, possess distinct latency and throughput characteristics, and their cost and selectivity are unknown during query compilation. Furthermore, existing query engines are not designed to optimize semantic operations. The AISQL query execution engine addresses these challenges through three novel techniques informed by production deployment data from Snowflake customers. First, AI-aware query optimization treats AI inference cost as a first-class optimization objective, reasoning about large language model (LLM) cost directly during query planning to achieve 2-8$\times$ speedups. Second, adaptive model cascades reduce inference costs by routing most rows through a fast proxy model while escalating uncertain cases to a powerful oracle model, achieving 2-6$\times$ speedups while maintaining 90-95% of oracle model quality. Third, semantic join query rewriting lowers the quadratic time complexity of join operations to linear through reformulation as multi-label classification tasks, achieving 15-70$\times$ speedups with often improved prediction quality. AISQL is deployed in production at Snowflake, where it powers diverse customer workloads across analytics, search, and content understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Cortex AISQL, a production SQL engine integrating native semantic operations into SQL for querying structured and unstructured data. It introduces three techniques informed by Snowflake customer data: AI-aware query optimization (treating LLM costs as first-class, 2-8× speedups), adaptive model cascades (routing via proxy models with escalation to oracle models, 2-6× speedups at 90-95% quality), and semantic join query rewriting (reformulating joins as multi-label classification to reduce quadratic to linear complexity, 15-70× speedups), with the system deployed in production at Snowflake for analytics, search, and content workloads.
Significance. If the empirical claims hold under broader validation, the work could meaningfully advance database systems by making semantic/AI operations first-class citizens in query optimization and execution, potentially enabling scalable hybrid queries over unstructured data and informing cost models for LLM integration in production engines.
major comments (2)
- [Abstract] Abstract: The central claims of 2-8×, 2-6×, and 15-70× speedups with quality retention are stated without reference to any tables, figures, workload characterizations (e.g., selectivity or cardinality distributions), error bars, or ablation studies, leaving the load-bearing performance assertions unsupported by visible evidence.
- [Deployment section] Deployment section: The techniques are described as informed by and validated on Snowflake customer data, yet no quantitative details are supplied on LLM latency variance, model pair choices, or join cardinalities; this makes it impossible to assess whether the cost models, routing thresholds, and classification reformulations transfer beyond the specific observed distributions.
minor comments (1)
- [Abstract] Abstract: Consider adding one sentence clarifying the exact semantic primitives exposed (e.g., semantic similarity, classification, or join predicates) to help readers map the techniques to concrete SQL extensions.
Simulated Author's Rebuttal
We thank the referee for the constructive review and positive assessment of the work's potential impact. We address each major comment below with specific plans for revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of 2-8×, 2-6×, and 15-70× speedups with quality retention are stated without reference to any tables, figures, workload characterizations (e.g., selectivity or cardinality distributions), error bars, or ablation studies, leaving the load-bearing performance assertions unsupported by visible evidence.
Authors: We agree that the abstract would be strengthened by explicit links to supporting evidence. In the revised manuscript we will update the abstract to reference the evaluation sections, figures, and tables that present workload characterizations (including selectivity and cardinality distributions), error bars, and ablation studies for each technique. This will make the performance claims directly traceable without altering the abstract's length or focus. revision: yes
-
Referee: [Deployment section] Deployment section: The techniques are described as informed by and validated on Snowflake customer data, yet no quantitative details are supplied on LLM latency variance, model pair choices, or join cardinalities; this makes it impossible to assess whether the cost models, routing thresholds, and classification reformulations transfer beyond the specific observed distributions.
Authors: The deployment section is based on aggregated production data subject to customer confidentiality constraints, so we cannot release exact per-customer values for latency variance, specific model pairs, or join cardinalities. We will revise the section to include additional aggregated characterizations of the observed distributions (e.g., typical ranges for selectivity, cardinality, and model quality metrics) and a discussion of how the chosen thresholds and reformulations were validated across diverse analytics, search, and content workloads. This will improve assessment of transferability while respecting privacy requirements. revision: partial
Circularity Check
No circularity: empirical performance claims from production deployment
full rationale
The paper presents an implemented SQL engine with three optimization techniques whose reported speedups (2-8×, 2-6×, 15-70×) and quality metrics are stated as observed outcomes from Snowflake production workloads. No equations, parameter fits, or derivations are described that reduce by construction to the reported results themselves. The abstract and description contain no self-citations, uniqueness theorems, or ansatzes that serve as load-bearing premises; the central claims rest on direct deployment measurements rather than self-referential definitions or fitted inputs renamed as predictions. This satisfies the criteria for a self-contained empirical report.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
AI-aware query optimization treats AI inference cost as a first-class optimization objective... adaptive model cascades... semantic join query rewriting
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Production deployment data from Snowflake customers directly shaped our design choices
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
PLOP: Cost-Based Placement of Semantic Operators in Hybrid Query Plans
PLOP is a cost-based optimizer that finds optimal placements for semantic LLM operators in hybrid query plans via dynamic programming, delivering up to 1.5x speedup and 4.29x cost reduction on 44 benchmark queries whi...
-
Agent-Aided Design for Dynamic CAD Models
AADvark extends agent-aided CAD design to dynamic 3D assemblies with movable parts by integrating constraint solvers and visual feedback to create a verification signal for the agent.
-
Access Paths for Efficient Ordering with Large Language Models
Introduces the LLM ORDER BY semantic operator with algorithmic improvements, a semantic-aware external merge sort, and a budget-aware optimizer that selects near-optimal access paths for LLM-based ordering.
Reference graph
Works this paper leans on
-
[1]
E. Anderson, J. Fritz, A. Lee, B. Li, M. Lindblad, H. Lindeman, A. Meyer, P. Parmar, T. Ranade, M. A. Shah, et al. The design of an llm-powered unstructured analytics system.arXiv preprint arXiv:2409.00847, 2024
- [2]
- [3]
-
[4]
S. Chaudhuri and K. Shim. Optimization of queries with user-defined predicates. ACM Trans. Database Syst., 24(2):177–228, June 1999
work page 1999
-
[5]
L. Chen, M. Zaharia, and J. Zou. Frugalgpt: How to use large language models while reducing cost and improving performance, 2023
work page 2023
-
[6]
H. Dai, B. Y. Wang, X. Wan, B. Dai, S. Yang, A. Nova, P. Yin, P. M. Phothilimthana, C. Sutton, and D. Schuurmans. Uqe: a query engine for unstructured databases. In Proceedings of the 38th International Conference on Neural Information Processing Systems, NIPS ’24, Red Hook, NY, USA, 2025. Curran Associates Inc
work page 2025
-
[7]
J. Ding, U. F. Minhas, J. Yu, C. Wang, J. Do, Y. Li, H. Zhang, B. Chandramouli, J. Gehrke, D. Kossmann, D. Lomet, and T. Kraska. Alex: An updatable adaptive learned index. InProceedings of the 2020 ACM SIGMOD International Conference on Management of Data, SIGMOD ’20, page 969–984, New York, NY, USA, 2020. Association for Computing Machinery
work page 2020
-
[8]
S. Fernandes and J. Bernardino. What is bigquery? InProceedings of the 19th International Database Engineering & Applications Symposium, IDEAS ’15, page 202–203, New York, NY, USA, 2015. Association for Computing Machinery
work page 2015
-
[9]
J. M. Hellerstein and J. F. Naughton. Query execution techniques for caching expensive methods. InProceedings of the 1996 ACM SIGMOD International Con- ference on Management of Data, SIGMOD ’96, page 423–434, New York, NY, USA,
work page 1996
-
[10]
Association for Computing Machinery
-
[11]
J. M. Hellerstein, C. Ré, F. Schoppmann, D. Z. Wang, E. Fratkin, A. Gorajek, K. S. Ng, C. Welton, X. Feng, K. Li, and A. Kumar. The madlib analytics library: or mad skills, the sql.Proc. VLDB Endow., 5(12):1700–1711, Aug. 2012. 13 , , Liskowski et al
work page 2012
-
[12]
J. M. Hellerstein and M. Stonebraker. Predicate migration: optimizing queries with expensive predicates. InProceedings of the 1993 ACM SIGMOD International Conference on Management of Data, SIGMOD ’93, page 267–276, New York, NY, USA, 1993. Association for Computing Machinery
work page 1993
-
[13]
B. Hilprecht, A. Schmidt, M. Kulessa, A. Molina, K. Kersting, and C. Binnig. Deepdb: learn from data, not from queries!Proc. VLDB Endow., 13(7):992–1005, Mar. 2020
work page 2020
- [14]
-
[15]
D. Kang, P. Bailis, and M. Zaharia. Blazeit: optimizing declarative aggregation and limit queries for neural network-based video analytics.Proc. VLDB Endow., 13(4):533–546, Dec. 2019
work page 2019
- [16]
-
[17]
D. Kang, J. Guibas, P. D. Bailis, T. Hashimoto, and M. Zaharia. Tasti: Semantic indexes for machine learning-based queries over unstructured data. InProceedings of the 2022 International Conference on Management of Data, SIGMOD ’22, page 1934–1947, New York, NY, USA, 2022. Association for Computing Machinery
work page 2022
-
[18]
A. Kipf, T. Kipf, B. Radke, V. Leis, P. Boncz, and A. Kemper. Learned cardinalities: Estimating correlated joins with deep learning.arXiv preprint arXiv:1809.00677, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[19]
T. Kraska, M. Alizadeh, A. Beutel, E. H. Chi, A. Kristo, G. Leclerc, S. Madden, H. Mao, and V. Nathan. Sagedb: A learned database system. In9th Biennial Conference on Innovative Data Systems Research, CIDR 2019, Asilomar, CA, USA, January 13-16, 2019, Online Proceedings. www.cidrdb.org, 2019
work page 2019
- [20]
- [21]
-
[22]
C. Liu, M. Russo, M. Cafarella, L. Cao, P. B. Chen, Z. Chen, M. Franklin, T. Kraska, S. Madden, R. Shahout, and G. Vitagliano. Palimpzest: Optimizing ai-powered analytics with declarative query processing. InProceedings of the Conference on Innovative Database Research (CIDR)
-
[23]
S. Liu, J. Xu, W. Tjangnaka, S. Semnani, C. Yu, and M. Lam. SUQL: Conversational search over structured and unstructured data with large language models. In K. Duh, H. Gomez, and S. Bethard, editors,Findings of the Association for Compu- tational Linguistics: NAACL 2024, pages 4535–4555, Mexico City, Mexico, June
work page 2024
-
[24]
Association for Computational Linguistics
- [25]
- [26]
-
[27]
R. Marcus and O. Papaemmanouil. Deep reinforcement learning for join order enumeration. InProceedings of the First International Workshop on Exploiting Artificial Intelligence Techniques for Data Management, aiDM’18, New York, NY, USA, 2018. Association for Computing Machinery
work page 2018
- [28]
- [29]
- [30]
-
[31]
S. Shankar, T. Chambers, T. Shah, A. G. Parameswaran, and E. Wu. Docetl: Agentic query rewriting and evaluation for complex document processing.Proc. VLDB Endow., 18(9):3035–3048, Sept. 2025
work page 2025
-
[32]
M. Stillger, G. M. Lohman, V. Markl, and M. Kandil. Leo - db2’s learning optimizer. InProceedings of the 27th International Conference on Very Large Data Bases, VLDB ’01, page 19–28, San Francisco, CA, USA, 2001. Morgan Kaufmann Publishers Inc
work page 2001
-
[33]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
D. Van Aken, A. Pavlo, G. J. Gordon, and B. Zhang. Automatic database manage- ment system tuning through large-scale machine learning. InProceedings of the 2017 ACM International Conference on Management of Data, SIGMOD ’17, page 1009–1024, New York, NY, USA, 2017. Association for Computing Machinery
work page 2017
-
[35]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V. Le, D. Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
work page 2022
-
[36]
Z. Yang, E. Liang, A. Kamsetty, C. Wu, Y. Duan, X. Chen, P. Abbeel, J. M. Heller- stein, S. Krishnan, and I. Stoica. Deep unsupervised cardinality estimation.Proc. VLDB Endow., 13(3):279–292, Nov. 2019
work page 2019
-
[37]
M. J. Zellinger and M. Thomson. Rational tuning of llm cascades via probabilistic modeling, 2025
work page 2025
-
[38]
J. Zhang, Y. Liu, K. Zhou, G. Li, Z. Xiao, B. Cheng, J. Xing, Y. Wang, T. Cheng, L. Liu, M. Ran, and Z. Li. An end-to-end automatic cloud database tuning system using deep reinforcement learning. InProceedings of the 2019 International Conference on Management of Data, SIGMOD ’19, page 415–432, New York, NY, USA, 2019. Association for Computing Machinery. 14
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.