MVI-Bench: A Comprehensive Benchmark for Evaluating Robustness to Misleading Visual Inputs in LVLMs
Pith reviewed 2026-05-21 19:45 UTC · model grok-4.3
The pith
MVI-Bench shows large vision-language models are vulnerable to misleading visual inputs across three key levels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
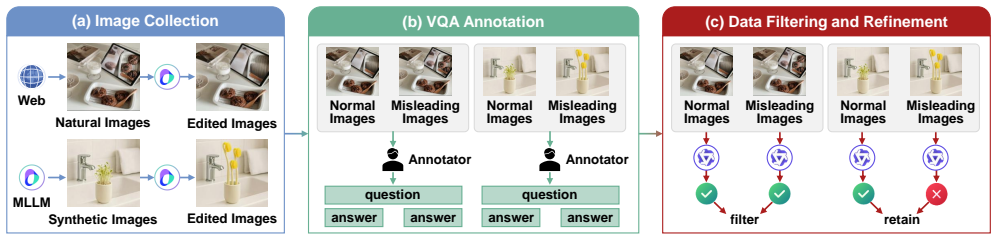
MVI-Bench is the first comprehensive benchmark designed to evaluate the robustness of LVLMs to misleading visual inputs. It is grounded in fundamental visual primitives with a hierarchical taxonomy consisting of Visual Concept, Visual Attribute, and Visual Relationship levels. From this, six representative categories are curated into 1,248 VQA instances with expert annotations. The benchmark includes the MVI-Sensitivity metric for fine-grained evaluation, and testing reveals pronounced vulnerabilities in current LVLMs along with insights for developing more robust models.
What carries the argument
The three-level taxonomy of misleading visual inputs (Visual Concept, Visual Attribute, Visual Relationship) that structures the benchmark and enables the creation of MVI-Sensitivity for granular robustness assessment.
If this is right
- LVLMs exhibit pronounced vulnerabilities when faced with misleading visual inputs in VQA scenarios.
- The MVI-Bench provides a structured way to identify specific weaknesses in visual understanding.
- Analyses from the benchmark offer actionable insights for enhancing LVLM reliability.
- Future model development can target the identified categories to reduce errors from deceptive visuals.
Where Pith is reading between the lines
- Extending the taxonomy to dynamic video inputs could reveal additional robustness issues in multimodal systems.
- Integrating MVI-Bench into training pipelines might help mitigate the observed vulnerabilities through targeted data augmentation.
- The benchmark's focus on visual primitives suggests it could complement existing text-based robustness tests for more complete evaluations.
Load-bearing premise
The three-level taxonomy and six categories together with expert annotations capture the main types of misleading visual inputs that affect real-world LVLM performance.
What would settle it
Demonstrating that a new LVLM achieves high performance on MVI-Bench yet still fails significantly in real-world applications involving misleading visuals would challenge the benchmark's effectiveness.
Figures







read the original abstract
Evaluating the robustness of Large Vision-Language Models (LVLMs) is essential for their continued development and responsible deployment in real-world applications. However, existing robustness benchmarks typically focus on hallucination or misleading textual inputs, while largely overlooking the equally critical challenge posed by misleading visual inputs in assessing visual understanding. To fill this important gap, we introduce MVI-Bench, the first comprehensive benchmark specially designed for evaluating how Misleading Visual Inputs undermine the robustness of LVLMs. Grounded in fundamental visual primitives, the design of MVI-Bench centers on three hierarchical levels of misleading visual inputs: Visual Concept, Visual Attribute, and Visual Relationship. Using this taxonomy, we curate six representative categories and compile 1,248 expertly annotated VQA instances. To facilitate fine-grained robustness evaluation, we further introduce MVI-Sensitivity, a novel metric that characterizes LVLM robustness at a granular level. Empirical results across 18 state-of-the-art LVLMs uncover pronounced vulnerabilities to misleading visual inputs, and our in-depth analyses on MVI-Bench provide actionable insights that can guide the development of more reliable and robust LVLMs. The benchmark and codebase can be accessed at https://github.com/chenyil6/MVI-Bench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MVI-Bench, the first comprehensive benchmark for evaluating Large Vision-Language Models' (LVLMs) robustness to misleading visual inputs. It grounds the benchmark in a three-level taxonomy (Visual Concept, Visual Attribute, Visual Relationship), curates six representative categories, and compiles 1,248 expertly annotated VQA instances. A novel MVI-Sensitivity metric is proposed for granular robustness evaluation. Empirical results on 18 state-of-the-art LVLMs report pronounced vulnerabilities, with in-depth analyses yielding actionable insights for more reliable LVLMs. The benchmark and codebase are released publicly.
Significance. If the benchmark construction and metric are rigorously documented, this work addresses a clear gap in LVLM robustness evaluation, which has largely emphasized textual hallucinations rather than visual misleading inputs. The hierarchical taxonomy based on fundamental visual primitives, multi-model evaluation, and public release of the benchmark represent strengths that could support reproducible research and guide improvements in LVLM visual understanding.
major comments (3)
- [§3] §3 (Benchmark Construction): The claim that the three-level taxonomy and six curated categories provide comprehensive coverage of misleading visual inputs lacks supporting validation or discussion of potential omissions (e.g., culturally specific misinterpretations or multi-object contextual contradictions). This is load-bearing for the generalizability of the 'pronounced vulnerabilities' findings across the 18 models.
- [§4] §4 (MVI-Sensitivity Metric): The novel MVI-Sensitivity metric is introduced to enable fine-grained evaluation, but its exact computation, aggregation method, and normalization are not specified with equations or algorithmic details. This prevents verification of the reported empirical results and undermines reproducibility.
- [§3.2] §3.2 (Annotation Protocol): No information is provided on the expert annotation protocol, selection criteria for annotators, guidelines used, or inter-annotator agreement for the 1,248 VQA instances. These details are essential to establish the reliability of the benchmark instances underlying all claims.
minor comments (2)
- [Abstract] The abstract and introduction could more explicitly contrast MVI-Bench with existing robustness benchmarks focused on textual inputs to highlight the novelty.
- [Conclusion] Ensure that the GitHub repository link includes clear documentation on how to reproduce the MVI-Sensitivity scores and access the annotated instances.
Simulated Author's Rebuttal
We sincerely thank the referee for their thorough and constructive review of our manuscript. We have carefully addressed each major comment below and will incorporate revisions to strengthen the paper's clarity, rigor, and reproducibility.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The claim that the three-level taxonomy and six curated categories provide comprehensive coverage of misleading visual inputs lacks supporting validation or discussion of potential omissions (e.g., culturally specific misinterpretations or multi-object contextual contradictions). This is load-bearing for the generalizability of the 'pronounced vulnerabilities' findings across the 18 models.
Authors: We appreciate this observation regarding the scope of our taxonomy. The three-level hierarchy (Visual Concept, Visual Attribute, Visual Relationship) is explicitly grounded in established visual primitives from computer vision literature, and the six categories were chosen as representative based on their prevalence in visual understanding tasks. However, we acknowledge that explicit validation of coverage and discussion of omissions would better support generalizability claims. In the revised manuscript, we will add a dedicated limitations paragraph in §3 that discusses potential omissions, including culturally specific misinterpretations and multi-object contextual contradictions, while clarifying how the current design still enables meaningful evaluation of pronounced vulnerabilities across the 18 models. revision: yes
-
Referee: [§4] §4 (MVI-Sensitivity Metric): The novel MVI-Sensitivity metric is introduced to enable fine-grained evaluation, but its exact computation, aggregation method, and normalization are not specified with equations or algorithmic details. This prevents verification of the reported empirical results and undermines reproducibility.
Authors: Thank you for highlighting this issue. We will revise §4 to include the complete mathematical formulation of the MVI-Sensitivity metric. This will comprise explicit equations for per-instance sensitivity computation, the aggregation method across the 1,248 VQA instances (including any weighting), and normalization procedures. These additions will enable full verification and reproduction of the reported results on the 18 LVLMs. revision: yes
-
Referee: [§3.2] §3.2 (Annotation Protocol): No information is provided on the expert annotation protocol, selection criteria for annotators, guidelines used, or inter-annotator agreement for the 1,248 VQA instances. These details are essential to establish the reliability of the benchmark instances underlying all claims.
Authors: We agree that detailed annotation information is essential for establishing benchmark reliability. In the revised version, we will substantially expand §3.2 to describe the expert annotation protocol, including annotator selection criteria (requiring expertise in computer vision and multimodal AI), the annotation guidelines and interface, the quality control process, and quantitative inter-annotator agreement results (e.g., Fleiss' kappa) computed over the 1,248 instances. revision: yes
Circularity Check
No circularity: benchmark construction and empirical evaluation are independent artifacts
full rationale
The paper constructs MVI-Bench from a proposed three-level taxonomy and six curated categories with expert annotations, defines the MVI-Sensitivity metric, and reports empirical results on 18 LVLMs. No equations, fitted parameters, predictions, or derivations are present that reduce to self-defined inputs or self-citations. The taxonomy and benchmark are presented as new contributions rather than derived from prior results by construction, making the evaluation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert annotations accurately identify which visual inputs are misleading for the given questions
invented entities (1)
-
MVI-Sensitivity metric
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosurereality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Grounded in fundamental visual primitives, the design of MVI-Bench centers on three hierarchical levels of misleading visual inputs: Visual Concept, Visual Attribute, and Visual Relationship... six representative categories and compile 1,248 expertly annotated VQA instances... MVI-Sensitivity
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Empirical results across 18 state-of-the-art LVLMs uncover pronounced vulnerabilities to misleading visual inputs
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
When Text Hijacks Vision: Benchmarking and Mitigating Text Overlay-Induced Hallucination in Vision Language Models
VLMs hallucinate by prioritizing contradictory on-screen text over visual content, addressed via the VisualTextTrap benchmark with 6,057 human-validated samples and the VTHM-MoE dual-encoder framework using dimension-...
-
Stop When Reasoning Converges: Semantic-Preserving Early Exit for Reasoning Models
PUMA detects reasoning-level semantic redundancy to enable early exit in chains of thought, achieving 26.2% average token reduction across five LRMs and five benchmarks while preserving accuracy and CoT quality.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.