People readily follow personal advice from AI but it does not improve their well-being
Pith reviewed 2026-05-17 21:07 UTC · model grok-4.3
The pith
People follow personal advice from AI chatbots at high rates but gain no sustained well-being benefits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
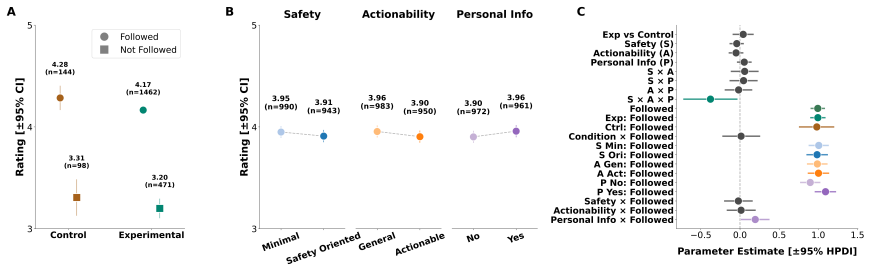
In a longitudinal randomised controlled trial with a representative UK sample of 6,474 participants, up to 79% of those who discussed personal topics with AI chatbots reported following the advice, with rates remaining above 60% even for high-stakes recommendations. The advice itself rarely violated safety best practices according to transcript evaluations. However, participants who received personal advice showed no sustained well-being benefits 2-3 weeks later compared to those who discussed hobbies and interests with the same chatbots.
What carries the argument
The randomised controlled trial that compares self-reported adherence to AI personal advice against a hobby-discussion control, with well-being tracked via scales after 2-3 weeks.
If this is right
- AI chatbots can substantially shape users' real-world personal decisions across health, career, and relationship domains.
- Reliance on AI advice shows weak calibration to the potential consequences of following it.
- Consumer LLMs provide advice that generally aligns with safety best practices.
- Short-term interactions with AI for personal advice do not produce measurable improvements in psychological well-being.
Where Pith is reading between the lines
- Repeated or extended conversations with AI might be required before any well-being effects appear.
- Objective records of behavior, such as actual health or career metrics, could reveal effects hidden by self-reports.
- AI systems may function better as sources of information than as substitutes for human support in personal growth.
Load-bearing premise
Self-reported adherence to advice accurately reflects real behavioral change and the chosen well-being scales are sensitive enough to detect any benefits that might occur within a 2-3 week window.
What would settle it
An independent study that tracks objective behavioral changes or longer-term outcomes and finds larger improvements in the personal-advice group than in the hobby-discussion group.
Figures




read the original abstract
People increasingly seek personal advice from large language models (LLMs), yet whether humans follow their advice, and its consequences for their well-being, remains unknown. In a longitudinal randomised controlled trial with a representative UK sample (N = 6,474), we found that up to 79% of participants who had a 20-minute discussion with one of three AI chatbots (GPT-4o, LLama-3.3-70B, Gemini 3 Pro) about health, careers or relationships subsequently reported following its advice. Advice-following remained above 60% even for high-stakes recommendations, suggesting that users only weakly calibrate their reliance on AI advice to potential consequences. Based on autograder evaluations of chat transcripts, LLM advice rarely violated safety best practice. However, when queried 2-3 weeks later, participants receiving personal advice from AI showed no sustained well-being benefits compared to a control group who discussed hobbies and interests with the same chatbots. These findings reveal that consumer LLMs exert substantial influence over real-world personal decisions without delivering measurable psychological benefits.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports results from a longitudinal randomized controlled trial with a representative UK sample (N=6,474). Participants engaged in 20-minute discussions with one of three AI chatbots (GPT-4o, Llama-3.3-70B, or Gemini 3 Pro) on health, careers, or relationships (treatment) or hobbies and interests (control). The central claims are that up to 79% of participants reported following the AI advice (remaining above 60% for high-stakes recommendations), that LLM advice rarely violated safety best practices per autograder evaluation of transcripts, and that receiving personal advice produced no sustained well-being benefits at 2-3 week follow-up relative to the control condition.
Significance. If the null result on well-being holds, the study offers timely evidence on the substantial real-world influence of consumer LLMs over personal decisions without corresponding psychological benefits. The randomized design, large representative sample, and longitudinal structure provide solid grounding for the adherence and safety findings and contribute directly to HCI research on AI-mediated personal advice.
major comments (2)
- [Results section on well-being outcomes and follow-up assessments] The null finding on well-being benefits (central to the paper's second claim) rests on follow-up assessments whose sensitivity is not quantified. The manuscript does not report power calculations, minimal detectable effect sizes, or responsiveness metrics for the well-being scales used, leaving open the possibility that modest or domain-specific effects from following advice on health/careers/relationships could go undetected within the 2-3 week window.
- [Methods section on adherence measurement] Adherence is assessed exclusively via self-report (reported rates up to 79%). Without any validation against objective behavioral markers or corroborating indicators of actual follow-through, the causal interpretation linking advice receipt to downstream outcomes (including the null well-being result) is weakened.
minor comments (2)
- [Abstract] The abstract states that 'LLM advice rarely violated safety best practice' but provides no detail on the autograder criteria or thresholds; a concise description would aid interpretability.
- [Discussion] The discussion would benefit from an explicit limitations paragraph addressing the short follow-up interval and the reliance on self-reported adherence.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of our longitudinal RCT on AI advice adherence and well-being outcomes. We address each major comment below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Results section on well-being outcomes and follow-up assessments] The null finding on well-being benefits (central to the paper's second claim) rests on follow-up assessments whose sensitivity is not quantified. The manuscript does not report power calculations, minimal detectable effect sizes, or responsiveness metrics for the well-being scales used, leaving open the possibility that modest or domain-specific effects from following advice on health/careers/relationships could go undetected within the 2-3 week window.
Authors: We agree that reporting power calculations, minimal detectable effect sizes, and scale responsiveness would improve interpretation of the null well-being result. With N=6,474 and a longitudinal design, the study has high power to detect small effects, but these metrics were not included in the original submission. In revision, we will add a post-hoc power analysis for the primary well-being outcomes, report the minimal detectable effect size at the 2-3 week follow-up, and discuss the responsiveness of the scales employed. revision: yes
-
Referee: [Methods section on adherence measurement] Adherence is assessed exclusively via self-report (reported rates up to 79%). Without any validation against objective behavioral markers or corroborating indicators of actual follow-through, the causal interpretation linking advice receipt to downstream outcomes (including the null well-being result) is weakened.
Authors: We acknowledge the limitation of relying solely on self-reported adherence without objective behavioral validation. In a large representative sample spanning multiple advice domains, collecting verifiable follow-through data (e.g., documented health or career changes) was not feasible due to scale and participant burden. Self-report is standard in advice-following research. We will revise the discussion to explicitly state this limitation and its implications for causal claims about downstream effects, while noting that the randomized design still supports inference on the overall effect of AI advice receipt versus control. revision: partial
Circularity Check
No circularity: purely empirical RCT with direct measurements
full rationale
The paper reports a longitudinal randomised controlled trial (N=6,474) that directly measures self-reported advice adherence (up to 79%) and well-being outcomes at 2-3 week follow-up via standard scales, comparing AI personal-advice arms to a hobbies control arm. No equations, fitted parameters, model predictions, or derivation chains appear in the abstract or described methods. Claims rest on trial data rather than any self-referential construction, self-citation load-bearing premise, or renamed empirical pattern. The study is self-contained against external benchmarks of RCT design and therefore receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Participants' self-reports of following AI advice correspond to actual behavioral change.
- domain assumption The well-being instruments used are sensitive to any changes produced by following personal advice within 2-3 weeks.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
longitudinal randomised controlled trial ... well-being factor scores ... PHQ-2, GAD-2 ... advice-following remained above 60% even for high-stakes recommendations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
Sycophantic AI makes human interaction feel more effortful and less satisfying over time
Longitudinal experiments show sycophantic AI increases reliance on AI for personal advice and lowers satisfaction with real-world social relationships over time.
-
Sycophantic AI makes human interaction feel more effortful and less satisfying over time
Sycophantic AI delivers quick emotional support like friends but over weeks shifts users toward AI for advice and reduces satisfaction with real human interactions.
-
Language Model Goal Selection Differs from Humans' in a Self-Directed Learning Task
LLMs diverge from human goal selection in self-directed learning by exploiting single solutions with low variability across instances.
Reference graph
Works this paper leans on
-
[1]
Cooper, P.Nearly One in Five Give Britons Turn to AI for Personal Advicehttps://www.ipsos. com / en - uk / nearly - one - five - give - britons - turn - ai - personal - advice - new - ipsos - research-reveals. Accessed: 2025. 2025
work page 2025
-
[2]
Conversational AI increases political knowledge as effectively as self-directed internet search
Luettgau, L.et al. Conversational AI increases political knowledge as effectively as self-directed internet searchPreprint. 2025.https://doi.org/10.48550/arXiv.2509.05219
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.05219 2025
-
[3]
Shahsavar, Y. & Choudhury, A. User Intentions to Use ChatGPT for Self-Diagnosis and Health- Related Purposes: Cross-sectional Survey Study.JMIR Human Factors10,e47564 (2023)
work page 2023
-
[4]
Chatterji, A.et al. How People Use ChatGPTWorking Paper 34255 (National Bureau of Economic Research, 2025).http://www.nber.org/papers/w34255.pdf
work page 2025
-
[5]
Anthropic.Clio: Privacy-Preserving Insights into Real-World AI Use2024.https : / / assets . anthropic.com/m/7e1ab885d1b24176/original/Clio- Privacy- Preserving- Insights- into- Real-World-AI-Use.pdf
-
[6]
Dohn´ any, S.et al. Technological folie ` a deux: Feedback Loops Between AI Chatbots and Mental Illness Preprint. 2025.https://doi.org/10.48550/arXiv.2507.19218
-
[7]
Journal of Legal Analysis16,64–93 (2024)
Dahl, M.et al.Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models. Journal of Legal Analysis16,64–93 (2024)
work page 2024
-
[8]
Large Language Models (LLMs) for Legal Advice: A Scoping ReviewPreprint
Krook, J.et al. Large Language Models (LLMs) for Legal Advice: A Scoping ReviewPreprint. 2024. https://doi.org/10.2139/ssrn.4976189
-
[9]
JAMA Network Open8,e2457879 (2025)
Huo, B.et al.Large Language Models for Chatbot Health Advice Studies: A Systematic Review. JAMA Network Open8,e2457879 (2025)
work page 2025
-
[10]
Bouguettaya, A., Stuart, E. M. & Aboujaoude, E. Racial bias in AI-mediated psychiatric diagnosis and treatment: a qualitative comparison of four large language models.npj Digital Medicine8,332 (2025)
work page 2025
-
[11]
Cross, J. L., Choma, M. A. & Onofrey, J. A. Bias in medical AI: Implications for clinical decision- making.PLOS Digital Health3,e0000651 (2024)
work page 2024
-
[12]
arXiv preprint arXiv:2404.15149 , year=
Poulain, R., Fayyaz, H. & Beheshti, R.Bias patterns in the application of LLMs for clinical decision support: A comprehensive studyPreprint. 2024.https://doi.org/10.48550/arXiv.2404.15149
-
[13]
Osborne, M. R. & Bailey, E. R. Me vs. the machine? Subjective evaluations of human- and AI- generated advice.Scientific Reports15,3980 (2025)
work page 2025
-
[14]
The CHART Collaborativeet al.Reporting Guideline for Chatbot Health Advice Studies: The CHART Statement.JAMA Network Open8,e2530220 (2025)
work page 2025
-
[15]
Increasing happiness through conversations with artificial intelligencePreprint
Heffner, J.et al. Increasing happiness through conversations with artificial intelligencePreprint. 2025.https://doi.org/10.48550/arXiv.2504.02091
-
[16]
Structured AI Dialogues Can Increase Happiness and Meaning in LifePreprint
Sch¨ one, J.et al. Structured AI Dialogues Can Increase Happiness and Meaning in LifePreprint. Oct. 2025.https://doi.org/10.31234/osf.io/2bf7t_v1
-
[17]
Tryon, G. S., Birch, S. E. & Verkuilen, J. Meta-analyses of the relation of goal consensus and collaboration to psychotherapy outcome.Psychotherapy55,372–383 (2018)
work page 2018
-
[18]
G.et al.The Efficacy of Cognitive Behavioral Therapy: A Review of Meta-analyses
Hofmann, S. G.et al.The Efficacy of Cognitive Behavioral Therapy: A Review of Meta-analyses. Cognitive Therapy and Research36,427–440 (2012)
work page 2012
-
[19]
Bailey, R. R. Goal Setting and Action Planning for Health Behavior Change.American Journal of Lifestyle Medicine13,615–618 (2017)
work page 2017
-
[20]
Health Innovation Network South London.Measuring Recoverytech. rep. Accessed: 2025 (Health Innovation Network South London, 2014).https : / / www . healthinnovationoxford . org / wp - content/uploads/2015/11/measuring-recovery-2014.pdf
work page 2025
-
[21]
The Benefit of Additional Opinions.Current Directions in Psychological Science13,75–78 (2004)
Yaniv, I. The Benefit of Additional Opinions.Current Directions in Psychological Science13,75–78 (2004)
work page 2004
-
[22]
Harvey, N. & Fischer, I. Taking Advice: Accepting Help, Improving Judgment, and Sharing Re- sponsibility.Organizational Behavior and Human Decision Processes70,117–133.issn: 0749-5978. https://www.sciencedirect.com/science/article/pii/S0749597897926972(1997)
work page 1997
-
[23]
Dietvorst, B. J., Simmons, J. P. & Massey, C. Algorithm aversion: People erroneously avoid algo- rithms after seeing them err.Journal of Experimental Psychology: General144,114–126 (2015). 30
work page 2015
- [24]
-
[25]
Schultze, T., Rakotoarisoa, A.-F. & Stefan, S.-H. Effects of distance between initial estimates and advice on advice utilization.Judgment and Decision Making10,144–171 (2015)
work page 2015
-
[26]
Fang, C. M.et al. How AI and Human Behaviors Shape Psychosocial Effects of Extended Chatbot Use: A Longitudinal Randomized Controlled Study2025. arXiv:2503.17473 [cs.HC].https:// arxiv.org/abs/2503.17473
work page internal anchor Pith review arXiv
-
[27]
Phang, J.et al. Investigating Affective Use and Emotional Well-being on ChatGPT2025. arXiv: 2504.03888 [cs.HC].https://arxiv.org/abs/2504.03888
-
[28]
Kroenke, K., Spitzer, R. L. & Williams, J. B. The Patient Health Questionnaire-2: Validity of a Two-Item Depression Screener.Medical Care41,1284–1292 (2003)
work page 2003
-
[29]
Kroenke, K.et al.Anxiety disorders in primary care: prevalence, impairment, comorbidity, and detection.Annals of Internal Medicine146,317–325 (2007)
work page 2007
-
[30]
JAMA Internal Medicine174.PMID: 24276929, 399–407 (Mar
Gierk, B.et al.The somatic symptom scale-8 (SSS-8): a brief measure of somatic symptom burden. JAMA Internal Medicine174.PMID: 24276929, 399–407 (Mar. 2014)
work page 2014
-
[31]
Jenkins, C. D.et al.A scale for the estimation of sleep problems in clinical research.Journal of Clinical Epidemiology41,313–321 (1988)
work page 1988
-
[32]
World Health Organization (Geneva, 2024)
World Health Organization.The World Health Organization-Five Well-Being Index (WHO-5)Li- cense: CC-BY-NC-SA 3.0 IGO. World Health Organization (Geneva, 2024)
work page 2024
-
[33]
& Hicks, S.Measuring subjective well-beingtech
Tinkler, L. & Hicks, S.Measuring subjective well-beingtech. rep. (Office for National Statistics, 2011)
work page 2011
-
[34]
Keyes, C. L. M.Social Well-Being ScaleAPA PsycTests. 1998.https://doi.org/10.1037/t13598- 000
-
[35]
Van Katwyk, P. T.et al. Job-Related Affective Well-Being Scale (JAWS)APA PsycTests. 2000. https://doi.org/10.1037/t01753-000
-
[36]
Watson, D., Clark, L. A. & Tellegen, A. Development and validation of brief measures of positive and negative affect: The PANAS scales.Journal of Personality and Social Psychology54,1063–1070 (1988)
work page 1988
-
[37]
Killgore, W. D. S. The Affect Grid: A moderately valid, nonspecific measure of pleasure and arousal. Psychological Reports83,639–642 (1998)
work page 1998
-
[38]
Rodger, A.et al. Negative Anecdotes Reduce Policy Support: Evidence from Three Experimental Studies on Communicating Policy (In) EffectivenessPreprint. 2025.https://osf.io/e2kxc_v1/
work page 2025
-
[39]
HiBayES: A Hierarchical Bayesian Modeling Framework for AI Evaluation Statis- tics2025
Luettgau, L.et al. HiBayES: A Hierarchical Bayesian Modeling Framework for AI Evaluation Statis- tics2025. arXiv:2505.05602 [cs.AI].https://arxiv.org/abs/2505.05602
-
[40]
Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal
Dubois, M.et al. Skewed Score: A statistical framework to assess autograders2025. arXiv:2507. 03772 [cs.LG].https://arxiv.org/abs/2507.03772
-
[41]
Composable Effects for Flexible and Accelerated Probabilistic Programming in NumPyro
Phan, D., Pradhan, N. & Jankowiak, M. Composable Effects for Flexible and Accelerated Proba- bilistic Programming in NumPyro.http://arxiv.org/abs/1912.11554(Dec. 2019)
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[42]
Hoffman, M. D. & Gelman, A. The No-U-Turn Sampler: Adaptively Setting Path Lengths in Hamil- tonian Monte Carlo.http://arxiv.org/abs/1111.4246(Nov. 2011)
work page internal anchor Pith review Pith/arXiv arXiv 2011
- [43]
-
[44]
Did the advice you followed make you feel better?
Watanabe, S. Asymptotic Equivalence of Bayes Cross Validation and Widely Applicable Information Criterion in Singular Learning Theory.Journal of Machine Learning Research11,3571–3594 (2010). 31 Supplementary Information 32 Supplementary Figure S1:Sociodemographic variable distributions in the full sample (N= 2,302). Supplementary Figure S2:Self-reported u...
work page 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.