Recognition: 2 theorem links
· Lean TheoremLanguage Model Goal Selection Differs from Humans' in a Self-Directed Learning Task
Pith reviewed 2026-05-16 06:46 UTC · model grok-4.3
The pith
Language models diverge from humans by exploiting single solutions rather than gradually exploring goals in self-directed learning tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
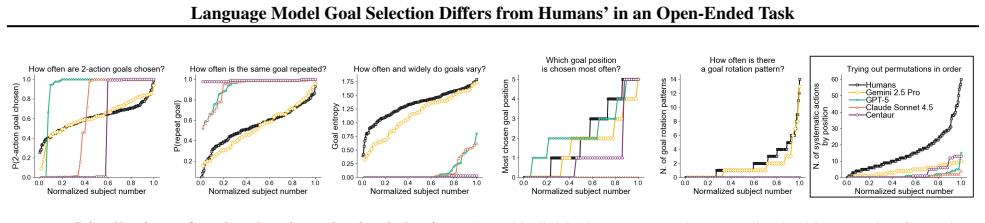
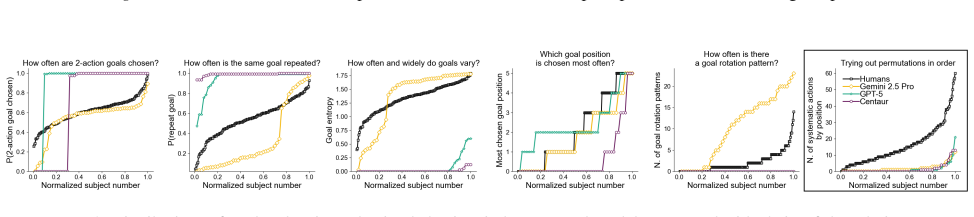
In the self-directed learning task, humans gradually explore and learn to achieve goals with diversity across individuals, whereas the tested language models exploit a single identified solution or show surprisingly low performance, displaying distinct patterns across models and little variability across instances of the same model.
What carries the argument
The self-directed learning task from cognitive science that requires participants to select and pursue their own goals without external instructions.
If this is right
- Current LLMs are unlikely to serve as accurate stand-ins for humans when the task involves choosing which goals to pursue rather than executing given ones.
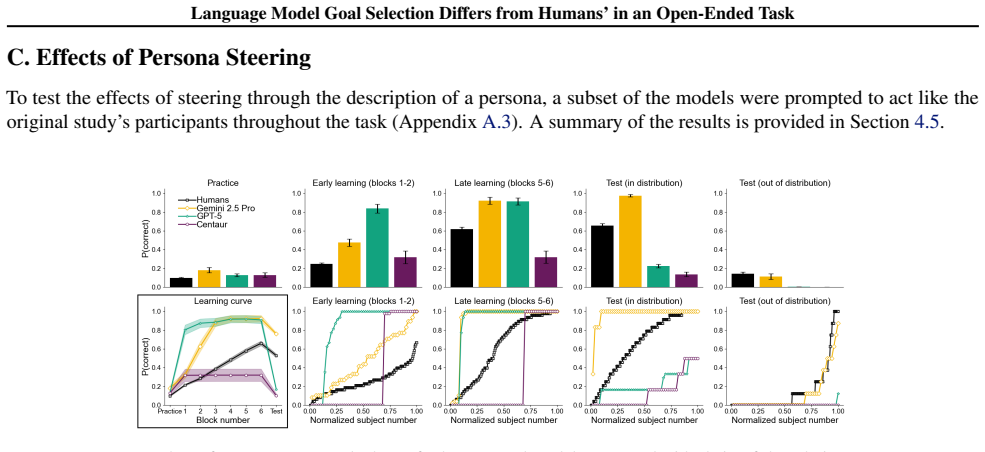
- Chain-of-thought reasoning and persona steering yield only limited gains in producing human-like goal exploration.
- Each model exhibits its own characteristic pattern of goal selection, so outcomes depend on which specific model is used.
- The findings remain consistent across experimental settings, suggesting the divergence is robust within the tested paradigm.
Where Pith is reading between the lines
- If the gap persists outside the lab, AI agents deployed for open-ended planning could produce narrower sets of goals than human collaborators would generate.
- The low within-model variability may reduce usefulness in applications that benefit from creative or individualized goal proposals.
- Targeted training that rewards diverse goal pursuit strategies could narrow the observed difference in future models.
- Similar divergence might appear in other open-ended choice tasks such as project selection or hypothesis generation.
Load-bearing premise
The borrowed cognitive science self-directed learning task validly measures the kind of goal selection preferences that LLMs are being asked to replace in real-world agentic, social, or chat settings.
What would settle it
A demonstration that any of the tested models produces gradual exploration trajectories and high individual-to-individual variability matching the human distribution on the same task would directly challenge the reported divergence.
Figures








read the original abstract
Whether in agentic workflows, social studies, or chat settings, large language models (LLMs) are increasingly being asked to replace humans in choosing which goals to pursue, rather than completing predefined tasks. However, the assumption that LLMs accurately reflect human preferences for goal setting remains largely untested. We assess the validity of LLMs as proxies for human goal selection in a controlled, self-directed learning task borrowed from cognitive science. Across five models (GPT-5, Gemini 2.5 Pro, Claude Sonnet 4.5, Qwen3 32B, and Centaur), we find substantial divergence from human behavior. While people gradually explore and learn to achieve goals with diversity across individuals, most models exploit a single identified solution or show surprisingly low performance, with distinct patterns across models and little variability across instances of the same model. Chain-of-thought reasoning and persona steering provide limited improvements, and our conclusions hold across experimental settings. While they await confirmation in applied settings, these findings highlight the uniqueness of human goal selection and caution against its replacement with current models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports an empirical study comparing goal selection in a self-directed learning task borrowed from cognitive science. Humans are described as gradually exploring and achieving goals with high individual diversity. In contrast, five LLMs (GPT-5, Gemini 2.5 Pro, Claude Sonnet 4.5, Qwen3 32B, Centaur) mostly exploit a single identified solution or exhibit low performance, showing model-specific patterns but little variability across repeated instances of the same model. Chain-of-thought reasoning and persona steering yield only limited improvements, and the divergence persists across experimental settings. The authors conclude that current LLMs are not faithful proxies for human goal-selection preferences and caution against their direct replacement in agentic, social, or chat contexts.
Significance. If the reported divergence is robust, the work would demonstrate that LLMs do not replicate human patterns of exploration versus exploitation in self-directed goal selection, with implications for agent design, AI alignment, and applications where models are asked to choose goals rather than execute given ones. The use of multiple frontier models and the controlled task provide a concrete baseline. However, the significance is limited by the absence of evidence that the borrowed task structure maps onto the open-ended goal spaces encountered in real agentic workflows; without that mapping the divergence may be task-specific rather than general.
major comments (2)
- [Methods] Methods: The central claim of substantial, general divergence rests on the assumption that the borrowed cognitive-science self-directed learning task is a valid proxy for the goal-selection preferences LLMs would exhibit in agentic or chat settings. No mapping is provided between the task's feedback loops, goal space, or iteration limits and those real-world contexts, so the observed divergence could be an artifact of the specific experimental framing.
- [Results] Results: No sample sizes, exact prompt templates, performance metrics, statistical tests, or quantitative measures of exploration/exploitation are supplied, preventing evaluation of the strength or reliability of the reported human-model differences. This information is load-bearing for the claim that models 'exploit a single identified solution' versus humans' gradual exploration.
minor comments (3)
- [Methods] Specify the precise model versions, access dates, and temperature settings used for each LLM.
- [Introduction] Add a reference to the original cognitive-science paper from which the self-directed learning task was borrowed.
- [Results] Clarify what 'surprisingly low performance' means quantitatively and how it was scored.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments correctly identify areas where additional clarity and explicit discussion are needed. We address each major comment below and have prepared revisions to incorporate the requested information and discussion.
read point-by-point responses
-
Referee: [Methods] Methods: The central claim of substantial, general divergence rests on the assumption that the borrowed cognitive-science self-directed learning task is a valid proxy for the goal-selection preferences LLMs would exhibit in agentic or chat settings. No mapping is provided between the task's feedback loops, goal space, or iteration limits and those real-world contexts, so the observed divergence could be an artifact of the specific experimental framing.
Authors: We agree that an explicit mapping between the experimental task and real-world agentic or chat settings would strengthen the interpretation. The task was selected because it isolates iterative goal selection under controlled feedback, a core component of self-directed learning that appears in many agentic workflows. In the revised manuscript we will add a new subsection in the Discussion that (a) maps the task's feedback loops, goal space size, and iteration limits to typical agentic scenarios, (b) discusses boundary conditions under which the observed divergence may or may not generalize, and (c) explicitly states the limitations of using this proxy. We believe this addition addresses the concern without overstating the current results. revision: yes
-
Referee: [Results] Results: No sample sizes, exact prompt templates, performance metrics, statistical tests, or quantitative measures of exploration/exploitation are supplied, preventing evaluation of the strength or reliability of the reported human-model differences. This information is load-bearing for the claim that models 'exploit a single identified solution' versus humans' gradual exploration.
Authors: We apologize that these details were not presented with sufficient prominence in the main text. The original manuscript contains: human sample size N=120, 50 independent instances per model across the five LLMs, full prompt templates in Appendix A, performance metrics (goal achievement rate and number of unique goals per instance), an exploration/exploitation ratio defined as unique solutions divided by total attempts, and statistical tests (chi-square tests for categorical differences and ANOVA for continuous metrics, with exact p-values). In revision we will move a concise summary table of these quantities and the definition of the exploration index into the main Results section, while retaining the full details in the appendix. revision: yes
Circularity Check
No circularity: purely empirical comparison with no derivations or self-referential steps
full rationale
The paper reports an empirical study that borrows an existing cognitive-science task and directly compares human and LLM behavior on it. No equations, fitted parameters, predictions derived from inputs, or self-citation chains are used to support any central claim. All findings rest on observed performance differences across models and humans, with no reduction of results to their own inputs by construction. The analysis is therefore self-contained and free of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The self-directed learning task borrowed from cognitive science accurately captures human goal-selection preferences relevant to LLM replacement scenarios.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We assess the validity of LLMs as proxies for human goal selection in a controlled, self-directed learning task... goal selection entropy... probability of repeating a goal... goal cycles
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
humans gradually explore and learn... models exploit a single identified solution or show surprisingly low performance
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Aher, G., Arriaga, R. I., and Kalai, A. T. Using large language models to simulate multiple humans.arXiv preprint arXiv:2208.10264, 5,
-
[2]
Concrete Problems in AI Safety
Amodei, D., Olah, C., Steinhardt, J., Christiano, P., Schul- man, J., and Man ´e, D. Concrete problems in ai safety. arXiv preprint arXiv:1606.06565,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Burda, Y ., Edwards, H., Pathak, D., Storkey, A., Darrell, T., and Efros, A. A. Large-scale study of curiosity-driven learning.arXiv preprint arXiv:1808.04355,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Lan- guage models trained on media diets can predict public opinion.arXiv preprint arXiv:2303.16779,
Chu, E., Andreas, J., Ansolabehere, S., and Roy, D. Lan- guage models trained on media diets can predict public opinion.arXiv preprint arXiv:2303.16779,
-
[5]
Coda-Forno, J., Binz, M., Wang, J. X., and Schulz, E. Cog- bench: a large language model walks into a psychology lab.arXiv preprint arXiv:2402.18225,
-
[6]
Dasgupta, I., Lampinen, A. K., Chan, S. C., Creswell, A., Kumaran, D., McClelland, J. L., and Hill, F. Language models show human-like content effects on reasoning. arXiv preprint arXiv:2207.07051, 2(3),
-
[7]
Faldor, M., Zhang, J., Cully, A., and Clune, J. OMNI- EPIC: Open-endedness via models of human notions of interestingness with environments programmed in code. arXiv preprint arXiv:2405.15568,
-
[8]
Hagendorff, T., Dasgupta, I., Binz, M., Chan, S. C., Lampinen, A., Wang, J. X., Akata, Z., and Schulz, E. Machine psychology.arXiv preprint arXiv:2303.13988,
-
[9]
Measuring Massive Multitask Language Understanding
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. Measuring mas- sive multitask language understanding.arXiv preprint arXiv:2009.03300,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[10]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Lu, C., Lu, C., Lange, R. T., Foerster, J., Clune, J., and Ha, D. The AI scientist: Towards fully automated open-ended scientific discovery.arXiv preprint arXiv:2408.06292,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
People readily follow personal advice from AI but it does not improve their well-being
Luettgau, L., Cheung, V ., Dubois, M., Juechems, K., Bergs, J., Davidson, H., O’Dell, B., Kirk, H. R., Rollwage, M., and Summerfield, C. People readily follow personal advice from ai but it does not improve their well-being. arXiv preprint arXiv:2511.15352,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Mitchener, L., Yiu, A., Chang, B., Bourdenx, M., Nadol- ski, T., Sulovari, A., Landsness, E. C., Barabasi, D. L., Narayanan, S., Evans, N., et al. Kosmos: An ai scientist for autonomous discovery.arXiv preprint arXiv:2511.02824,
-
[13]
Molinaro, G. and Collins, A. G. Reward function compres- sion facilitates goal-dependent reinforcement learning. arXiv preprint arXiv:2509.06810,
-
[14]
Orr, M., Cranford, D., Ford, K., Gluck, K., Hancock, W., Lebiere, C., Pirolli, P., Ritter, F., and Stocco, A. Not even wrong: On the limits of prediction as explanation in cognitive science.arXiv preprint arXiv:2510.03311,
-
[15]
A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications
Sahoo, P., Singh, A. K., Saha, S., Jain, V ., Mondal, S., and Chadha, A. A systematic survey of prompt engineering in large language models: Techniques and applications. arXiv preprint arXiv:2402.07927,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Schmidhuber, J. Formal theory of creativity, fun, and in- trinsic motivation (1990–2010).IEEE transactions on autonomous mental development, 2(3):230–247,
work page 1990
-
[17]
M., Ye, A., Jiang, L., Lu, X., Dziri, N., et al
10 Language Model Goal Selection Differs from Humans’ in an Open-Ended Task Sorensen, T., Moore, J., Fisher, J., Gordon, M., Mireshghal- lah, N., Rytting, C. M., Ye, A., Jiang, L., Lu, X., Dziri, N., et al. A roadmap to pluralistic alignment.arXiv preprint arXiv:2402.05070,
-
[18]
R., Hackenburg, K., Fist, C., Slama, K., Ding, N., Ansel- metti, R., Strait, A., et al
Summerfield, C., Luettgau, L., Dubois, M., Kirk, H. R., Hackenburg, K., Fist, C., Slama, K., Ding, N., Ansel- metti, R., Strait, A., et al. Lessons from a chimp: AI ” scheming” and the quest for ape language.arXiv preprint arXiv:2507.03409,
-
[19]
Clio: Privacy-preserving insights into real-world AI use.arXiv preprint arXiv:2412.13678,
Tamkin, A., McCain, M., Handa, K., Durmus, E., Lovitt, L., Rathi, A., Huang, S., Mountfield, A., Hong, J., Ritchie, S., et al. Clio: Privacy-preserving insights into real-world AI use.arXiv preprint arXiv:2412.13678,
-
[20]
White, J., Fu, Q., Hays, S., Sandborn, M., Olea, C., Gilbert, H., Elnashar, A., Spencer-Smith, J., and C., S. D. A prompt pattern catalog to enhance prompt engineering with ChatGPT.arXiv preprint arXiv:2302.11382,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Zhang, J., Lehman, J., Stanley, K., and Clune, J. Omni: Open-endedness via models of human notions of interest- ingness.arXiv preprint arXiv:2306.01711,
-
[22]
WildChat: 1M ChatGPT Interaction Logs in the Wild
Zhao, W., Ren, X., Hessel, J., Cardie, C., Choi, Y ., and Deng, Y . Wildchat: 1m chatgpt interaction logs in the wild.arXiv preprint arXiv:2405.01470,
work page internal anchor Pith review arXiv
- [23]
-
[24]
11 Language Model Goal Selection Differs from Humans’ in an Open-Ended Task A. Prompts Below, we report information about the prompts used in our study. Additional empty lines were omitted to save space. A.1. Main Study Prompts for each trial started with an introduction to the game: “You are participating in an alchemy game where you create potions by co...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.