Reward Engineering for Spatial Epidemic Simulations: A Reinforcement Learning Platform for Individual Behavioral Learning
Pith reviewed 2026-05-25 07:55 UTC · model grok-4.3
The pith
A potential field reward in a new RL platform for spatial epidemics enables agents to learn maximal intervention adherence and spatial avoidance strategies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
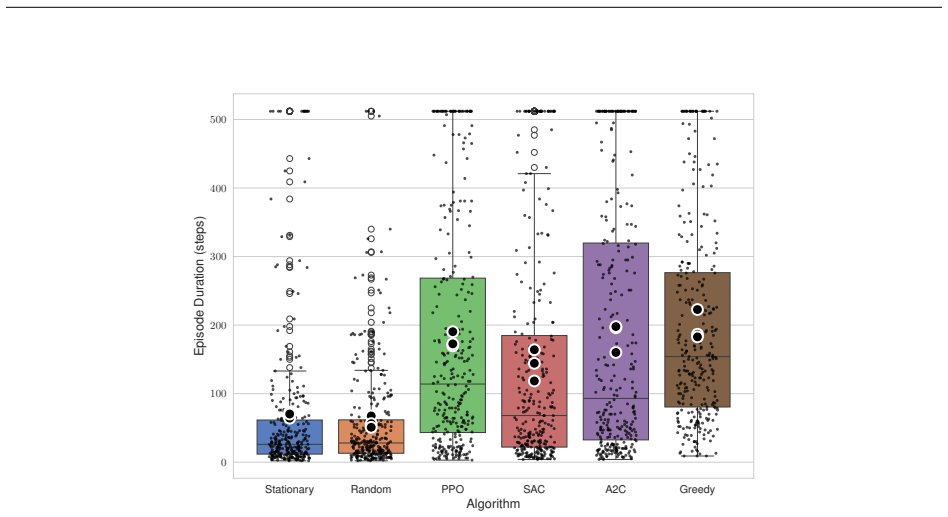
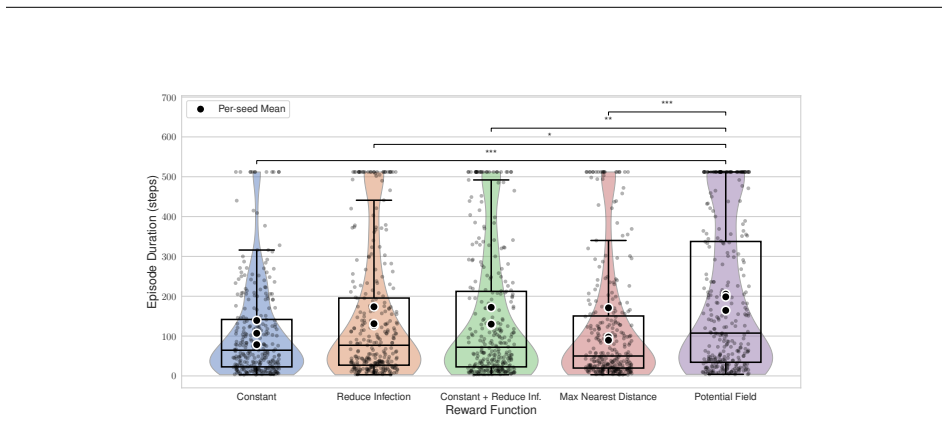
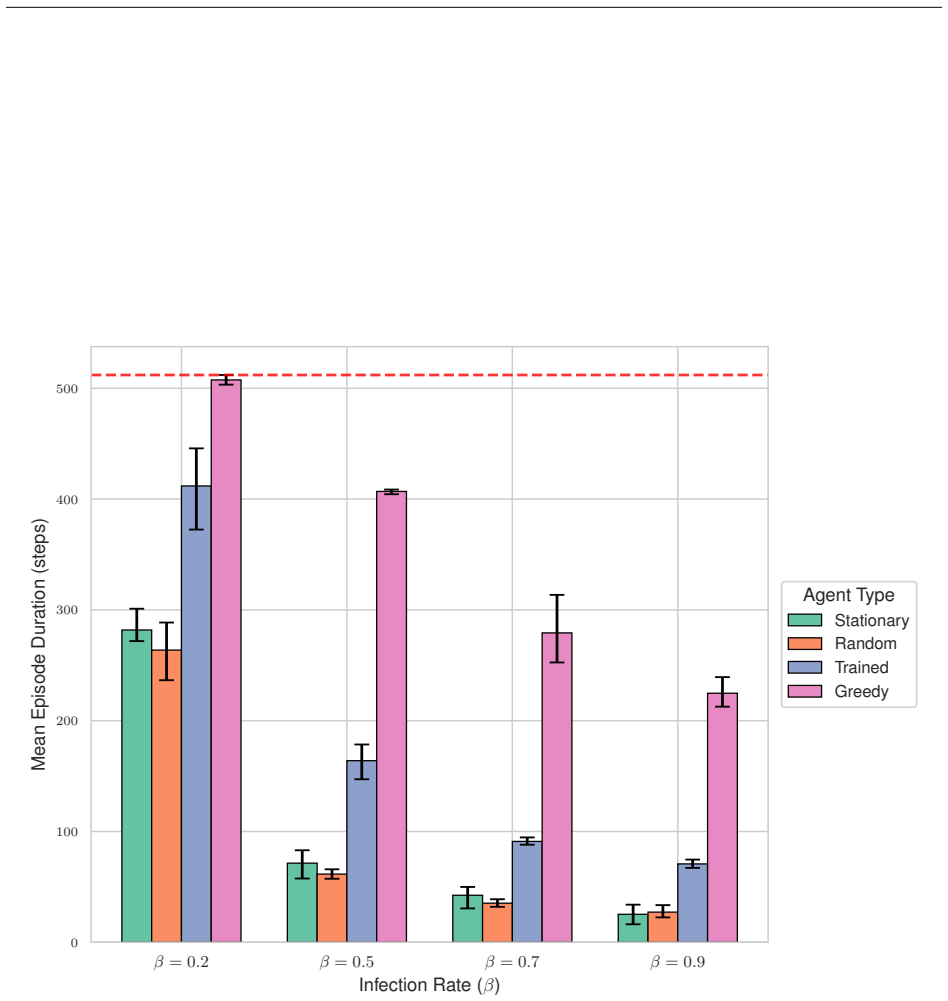
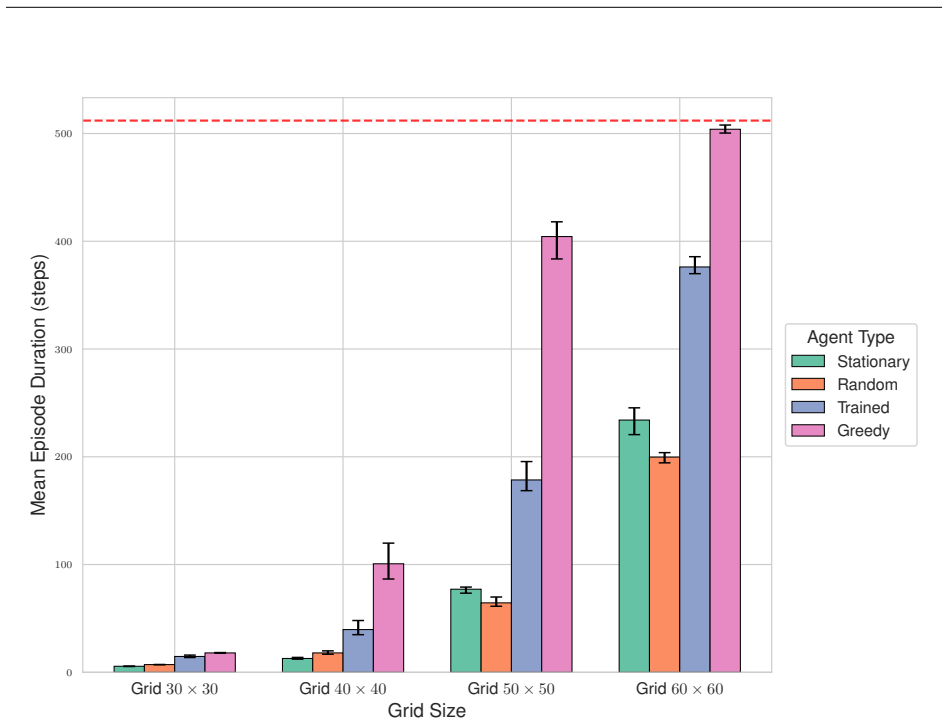
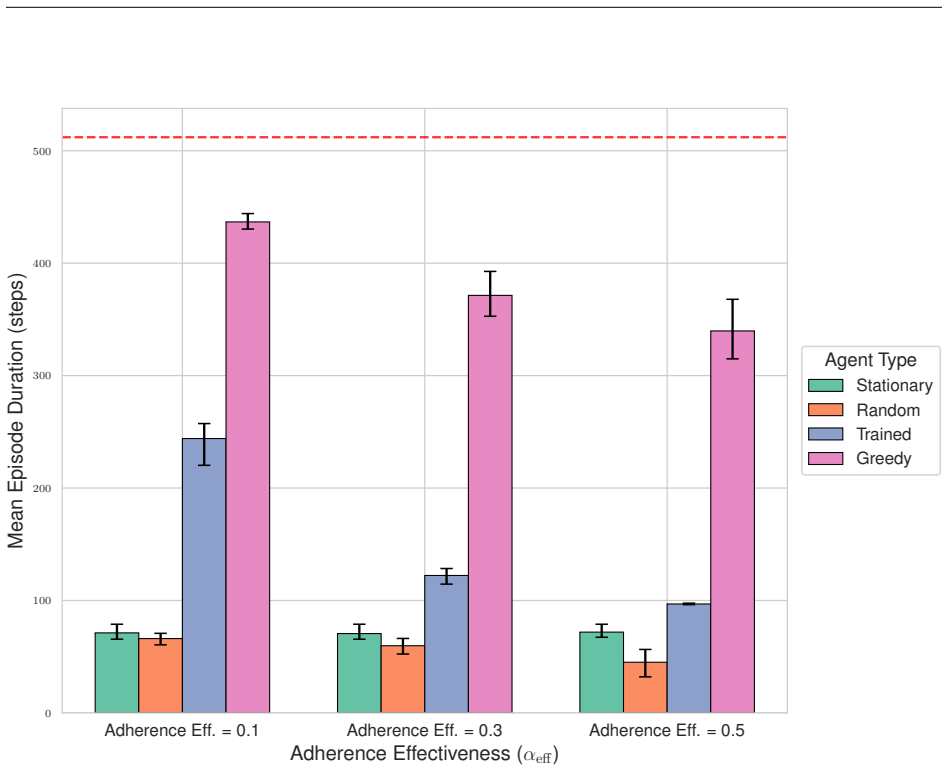
ContagionRL integrates a spatial SIRS+D model with configurable parameters into a Gymnasium environment, permitting systematic evaluation of reward designs from sparse survival bonuses to a novel potential field formulation. Ablation studies across algorithms and scenarios show that directional guidance combined with explicit adherence incentives is essential for robust learning. Agents trained on the potential field reward achieve superior survival, maximal adherence to interventions, and complex spatial strategies, while other rewards yield weaker or less adaptive policies.
What carries the argument
The potential field reward function, which supplies directional guidance toward safer regions together with explicit incentives for intervention adherence inside the spatial SIRS+D Gymnasium environment.
If this is right
- Directional guidance and adherence incentives prove critical for robust policy learning across tested algorithms.
- Reward function choice dramatically changes agent behavior and survival rates under varied infection rates and grid sizes.
- The modular platform supports stress-testing of rewards under limited observability and heterogeneous population dynamics.
- Agents develop sophisticated spatial avoidance strategies specifically when trained with the potential field reward.
- Systematic ablation reveals that sparse survival bonuses alone are insufficient for effective learning in these settings.
Where Pith is reading between the lines
- The platform could be used to simulate how different public incentive structures affect real-world compliance levels.
- Extending the single-agent setup to multiple interacting agents might expose emergent group-level epidemic control behaviors.
- The emphasis on information structure and environmental predictability could transfer to reward design in other spatial simulation domains such as traffic flow or resource allocation.
- Direct comparison of learned policies against empirical mobility data during past outbreaks would test whether the discovered strategies align with observed human responses.
Load-bearing premise
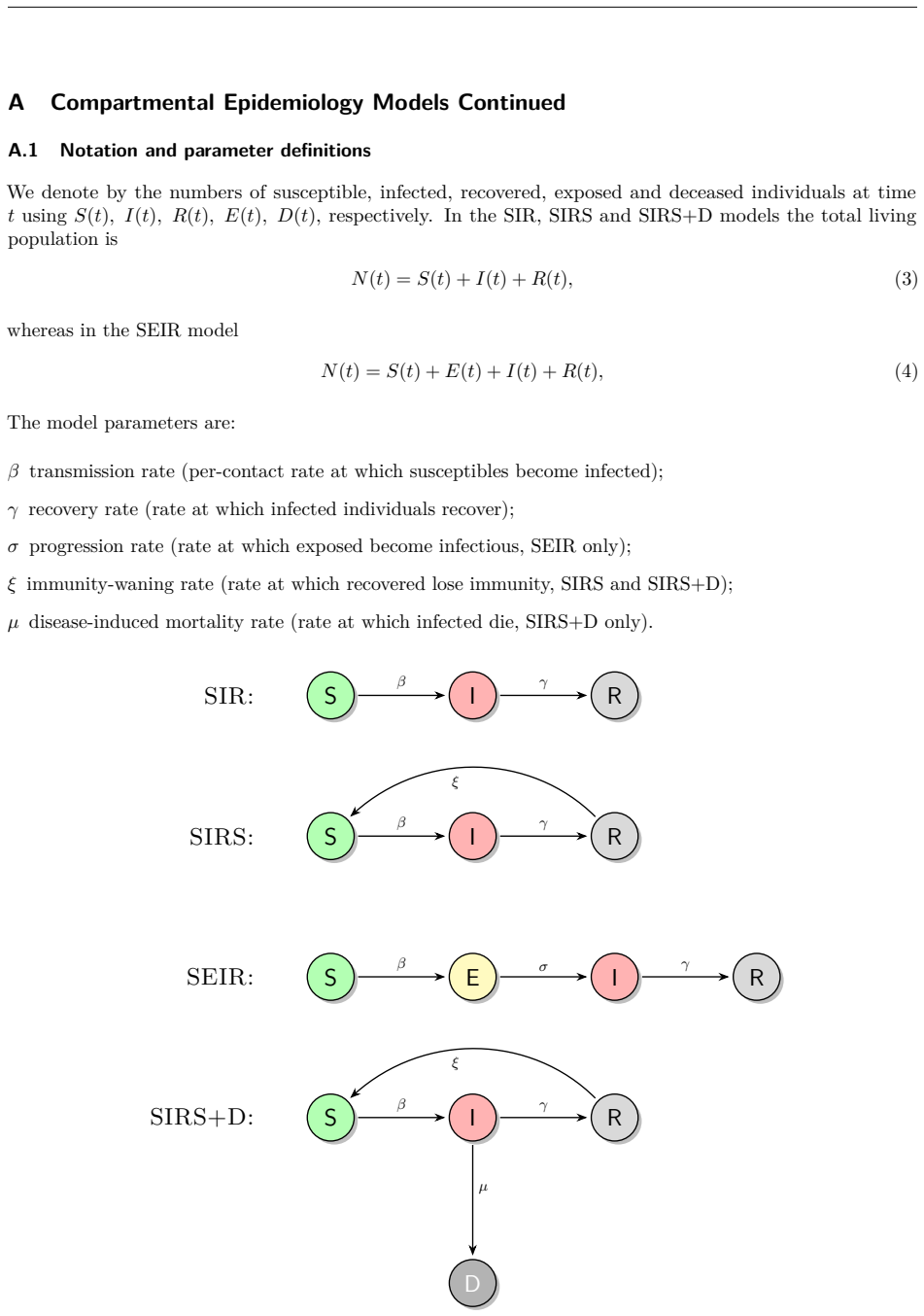
The spatial SIRS+D model and the chosen observation and action spaces are realistic enough that reward-driven policies will yield meaningful behavioral insights.
What would settle it
If agents using the potential field reward fail to outperform the other four designs when the environment is altered to include different movement patterns or stronger stochastic infection rules, the superiority result would be falsified.
Figures








read the original abstract
We present ContagionRL, a Gymnasium-compatible reinforcement learning platform specifically designed for systematic reward engineering in spatial epidemic simulations. Unlike traditional agent-based models that rely on fixed behavioral rules, our platform enables rigorous evaluation of how reward function design affects learned survival strategies across diverse epidemic scenarios. ContagionRL integrates a spatial SIRS+D epidemiological model with configurable environmental parameters, allowing researchers to stress-test reward functions under varying conditions including limited observability, different movement patterns, and heterogeneous population dynamics. We evaluate five distinct reward designs, ranging from sparse survival bonuses to a novel potential field approach, across multiple RL algorithms (PPO, SAC, A2C). Through systematic ablation studies, we identify that directional guidance and explicit adherence incentives are critical components for robust policy learning. Our comprehensive evaluation across varying infection rates, grid sizes, visibility constraints, and movement patterns reveals that reward function choice dramatically impacts agent behavior and survival outcomes. Agents trained with our potential field reward consistently achieve superior performance, learning maximal adherence to non-pharmaceutical interventions while developing sophisticated spatial avoidance strategies. The platform's modular design enables systematic exploration of reward-behavior relationships, addressing a knowledge gap in models of this type where reward engineering has received limited attention. ContagionRL is an effective platform for studying adaptive behavioral responses in epidemic contexts and highlight the importance of reward design, information structure, and environmental predictability in learning. Our code is publicly available at https://github.com/redradman/ContagionRL
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ContagionRL, a Gymnasium-compatible RL platform that couples a configurable spatial SIRS+D epidemiological model with five reward formulations (including a novel potential-field design) and evaluates them under PPO, SAC, and A2C across varied grid sizes, infection rates, observability constraints, and movement patterns. The central empirical claim is that the potential-field reward produces policies with maximal NPI adherence and sophisticated spatial avoidance, outperforming sparse survival, adherence-only, and other baselines.
Significance. If the reported performance ordering is reproducible, the work supplies a modular, open-source testbed that isolates the effect of reward engineering on learned epidemic behavior—an area that has received little systematic attention. The public GitHub release and the explicit ablation across algorithms and environmental parameters constitute concrete strengths that lower the barrier for follow-on studies.
major comments (2)
- [Evaluation / Results] The manuscript states that 'systematic ablation studies' demonstrate superiority of the potential-field reward, yet supplies neither the numerical performance tables, confidence intervals, nor the precise experimental protocol (number of seeds, episode lengths, hyper-parameter grids) that would allow independent verification of that ordering. This gap directly affects the load-bearing empirical claim.
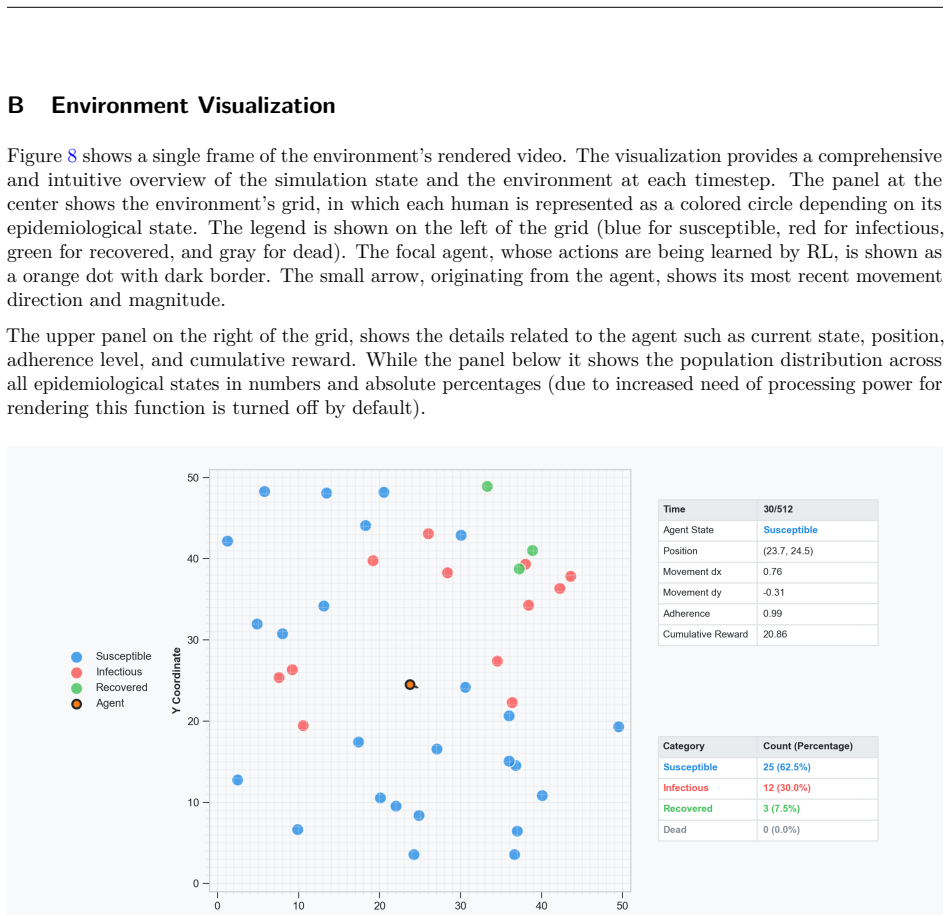
- [Environment Definition] The observation and action spaces are described at a high level, but the precise mapping from the SIRS+D state variables to the agent’s observation vector (and the dimensionality of the action space) is not given; without these definitions it is impossible to assess whether the reported spatial-avoidance strategies are artifacts of the chosen interface rather than genuine behavioral learning.
minor comments (2)
- [Abstract] The abstract claims 'maximal adherence' without defining the quantitative metric used to measure adherence; a short paragraph or equation in §3 would clarify this.
- [Figures] Figure captions and axis labels for the ablation plots should explicitly state the number of independent runs and whether shaded regions represent standard error or min/max.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address the two major comments below and will incorporate the requested clarifications into a revised manuscript.
read point-by-point responses
-
Referee: [Evaluation / Results] The manuscript states that 'systematic ablation studies' demonstrate superiority of the potential-field reward, yet supplies neither the numerical performance tables, confidence intervals, nor the precise experimental protocol (number of seeds, episode lengths, hyper-parameter grids) that would allow independent verification of that ordering. This gap directly affects the load-bearing empirical claim.
Authors: We agree that the current manuscript lacks the quantitative tables, confidence intervals, and full experimental protocol needed for independent verification. In the revision we will add (i) mean and standard-deviation performance tables for all reward–algorithm combinations, (ii) 95 % confidence intervals computed over multiple random seeds, and (iii) an explicit protocol section stating the number of seeds, episode lengths, and the hyper-parameter grids searched for PPO, SAC, and A2C. revision: yes
-
Referee: [Environment Definition] The observation and action spaces are described at a high level, but the precise mapping from the SIRS+D state variables to the agent’s observation vector (and the dimensionality of the action space) is not given; without these definitions it is impossible to assess whether the reported spatial-avoidance strategies are artifacts of the chosen interface rather than genuine behavioral learning.
Authors: We acknowledge that the precise observation vector construction and action-space dimensionality were only sketched at a high level. The revised manuscript will include (a) the exact mapping from each SIRS+D compartment and spatial coordinate to the observation components, (b) the resulting observation dimensionality, and (c) the discrete or continuous action-space size together with the movement semantics. These additions will be accompanied by a short pseudocode block clarifying the Gymnasium interface. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical RL platform (ContagionRL) and reports direct performance comparisons of five distinct reward designs across PPO/SAC/A2C on a spatial SIRS+D Gymnasium environment. No equations, fitted parameters, or derivations are shown that reduce reported outcomes to quantities defined by the paper's own inputs; results are scoped to simulation outcomes inside the defined environment with no load-bearing self-citations or self-definitional steps visible in the provided text.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The environment is a Markov decision process with the stated observation and action spaces.
- domain assumption The spatial SIRS+D dynamics adequately represent epidemic spread for the purpose of behavioral learning studies.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We evaluate five distinct reward designs, ranging from sparse survival bonuses to a novel potential field approach
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SIRS+D epidemiological model with configurable environmental parameters
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Health Reward (rhealth):This is a binary reward for maintaining a susceptible state. rhealth = { 1ifS a =Susceptible 0otherwise (26) (This component can be ablated to 0 via the no health variant)
-
[2]
Letαa be the agent’s current adherence (a value in[0,1])
Adherence Reward (radherence):This reward is directly proportional to the agent’s NPI adherence level. Letαa be the agent’s current adherence (a value in[0,1]). radherence =αa (27) (This component can be ablated to 0 via the no adherence variant)
-
[3]
Let the agent’s current position be pa = (xa,ya)and human j’s position bepj = (xj,yj)
Movement Reward (rmove):This component rewards the agent for moving in alignment with a suggested force vectorFand optionally for matching its magnitude. Let the agent’s current position be pa = (xa,ya)and human j’s position bepj = (xj,yj). The shortest displacement vector on the toroidal grid from humanjto the agent is∆p j = (∆x j,∆y j), where: ∆x j = (x...
work page 2048
-
[4]
Identify the set of currently infected humansI(t)
Identify Nearest Threat:Let the agent’s position at timet bep a(t) = (xa(t),ya(t)). Identify the set of currently infected humansI(t). This step utilizes privileged knowledge of the true state Sj ∈{S,I,R,D}for all humansj. If I(t)is empty, the agent defaults to a stationary action m∗= (0,0). 26
-
[5]
Target Selection:If I(t)is not empty, calculate the Euclidean distanced(pa(t), pj(t))for all j∈I(t), wherepj(t)is the position of infected humanj and d(·,·)accounts for the toroidal grid geometry. Identify the single infected humanhnearest(t)corresponding to the minimum distance: hnearest(t) = arg min j∈I(t) d(pa(t),pj(t)) The exact positionphnearest(t)is...
-
[6]
Evaluate Potential Moves:Define a discrete set of candidate movement vectorsAmove. This set includes the zero vector(0, 0)and scaled unit vectors representing the maximum possible step in the eight cardinal and diagonal directions, e.g.,{(0, 0), (±sM, 0), (0,±sM), (±sM/ √ 2,±sM/ √ 2)}, where sM is the maximum movement scale (typically 1.0)
-
[7]
Select Best Move:For each candidate movementmi = (∆xi, ∆yi)∈Amove, calculate the agent’s potential next positionp′ a,i(t + 1)by applying the movement topa(t)and considering the grid’s periodic boundaries. Evaluate the distance from this potential position to the initially identified nearest threat’s current positionphnearest(t). Select the movement vector...
-
[8]
Winner” indicates the model with significantly longer duration after correction. “Mean Diff
Set Adherence:The adherence component of the action is deterministically set to the maximum value,α= 1.0. 6.Final Action:The resulting action for timesteptisa(t) = (m ∗,α= 1.0). This implementation defines a simple, reactive strategy that exploits complete and accurate environmental state information to maximize instantaneous separation from the nearest p...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.