Detecting Model Misspecification in Bayesian Inverse Problems via Variational Gradient Descent
Pith reviewed 2026-05-17 02:54 UTC · model grok-4.3
The pith
Comparing the standard Bayesian posterior to a predictively oriented mixing distribution detects model misspecification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
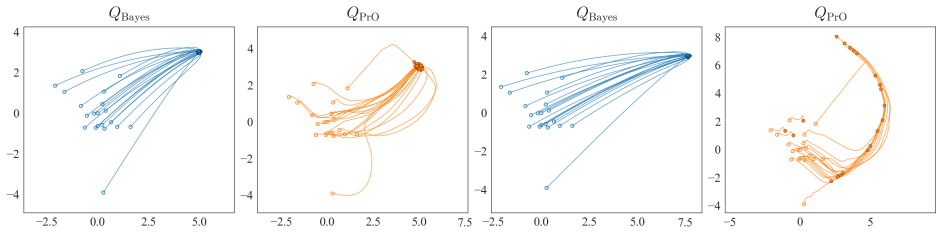
Model misspecification is detected by comparing the standard Bayesian posterior to the PrO posterior Q. The PrO posterior is the mixing distribution in the lifted infinite mixture model that minimises an entropy-regularised objective. In the well-specified case Q concentrates around the true data-generating parameter as data volume grows; this singular concentration is absent under misspecification. A variational gradient descent algorithm computes Q efficiently, and the resulting comparison detects misspecification in both simulated data and a detailed Bayesian inverse problem from seismology.
What carries the argument
The predictively oriented (PrO) posterior Q, the mixing distribution fitted to the infinite mixture of the original model by minimising an entropy-regularised objective functional, used as a comparator that concentrates only under correct specification.
If this is right
- In well-specified models the PrO posterior Q concentrates around the true data-generating parameter with growing data volume.
- Under misspecification Q does not concentrate, producing a visible discrepancy from the standard Bayesian posterior.
- The variational gradient descent algorithm renders computation of Q feasible for high-dimensional inverse problems.
- The comparison framework applies directly to real Bayesian inverse problems such as those arising in seismology.
Where Pith is reading between the lines
- The method could be added as an automatic diagnostic inside existing Bayesian inverse-problem pipelines without requiring extra data collection.
- Hybrid inference schemes might switch between standard Bayesian updates and PrO updates once misspecification is flagged by the comparison.
- The same concentration test could be examined for other forms of regularisation or for models with structured parameter spaces.
Load-bearing premise
The mixing distribution Q concentrates around the true parameter in the large-data limit only when the model is well-specified, but fails to concentrate when the model is misspecified.
What would settle it
Generate data from a known true parameter under a correctly specified model, compute Q with increasing sample sizes, and verify that Q concentrates on the true parameter; repeat the experiment after deliberately altering the model to be misspecified and check that concentration disappears.
Figures






read the original abstract
Bayesian inference is optimal when the statistical model is well-specified, while outside this setting Bayesian inference can catastrophically fail; accordingly a wealth of post-Bayesian methodologies have been proposed. Predictively oriented (PrO) approaches lift the statistical model $P_\theta$ to an (infinite) mixture model $\int P_\theta \; \mathrm{d}Q(\theta)$ and fit this predictive distribution via minimising an entropy-regularised objective functional. In the well-specified setting one expects the mixing distribution $Q$ to concentrate around the true data-generating parameter in the large data limit, while such singular concentration will typically not be observed if the model is misspecified. Our contribution is to demonstrate that one can empirically detect model misspecification by comparing the standard Bayesian posterior to the PrO `posterior' $Q$. To operationalise this, we present an efficient numerical algorithm based on variational gradient descent. A simulation study, and a more detailed case study involving a Bayesian inverse problem in seismology, confirm that model misspecification can be automatically detected using this framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes detecting model misspecification in Bayesian inverse problems by comparing the standard Bayesian posterior to the predictively oriented (PrO) mixing distribution Q, obtained by minimizing an entropy-regularized objective over an infinite mixture model via variational gradient descent. In the well-specified case, Q is expected to concentrate around the true parameter in the large-data limit, while remaining diffuse under misspecification; this difference is used as a diagnostic. The approach is demonstrated via a simulation study and a seismology case study.
Significance. If the central claim holds, the work offers a practical, computationally efficient diagnostic for an important failure mode of Bayesian inference in inverse problems. The variational gradient descent algorithm provides a concrete numerical tool, and the inclusion of both simulated and real-data (seismology) examples is a strength. The paper does not claim parameter-free derivations or machine-checked proofs, but the empirical operationalization of the PrO comparison is a clear contribution if the concentration behavior is validated in the relevant regime.
major comments (3)
- [Abstract and §2] Abstract and §2 (theoretical background): the concentration of Q around the true parameter under well-specification is presented as an 'expectation' rather than derived from first principles. In ill-posed inverse problems the forward map is typically compact, so even a correctly specified model yields a non-degenerate posterior for finite data; the same smoothing may prevent Q from becoming singular, removing the diagnostic power of the posterior-vs-Q comparison. This assumption is load-bearing for the detection procedure.
- [§4] §4 (simulation study): the study is said to confirm that detection is possible, yet no quantitative performance metrics (e.g., detection error rates, ROC curves, or explicit thresholding rule for the posterior comparison) are reported. Without these, the empirical support for the central claim remains qualitative and difficult to assess.
- [§5] §5 (seismology case study): this is the only experiment in the relevant ill-posed regime, but the manuscript provides no details on how the comparison between the Bayesian posterior and Q is operationalized (e.g., distance metric, concentration diagnostic, or decision threshold). The lack of such specification makes it impossible to reproduce or evaluate the reported detection.
minor comments (2)
- [§3] Notation for the entropy-regularized objective functional is introduced without an explicit equation number; adding a numbered display equation would improve clarity.
- [Figures 2-4] Figure captions in the simulation and case-study sections should explicitly state the sample size, noise level, and misspecification type used in each panel.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments. We respond point-by-point to the major comments below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract and §2] Abstract and §2 (theoretical background): the concentration of Q around the true parameter under well-specification is presented as an 'expectation' rather than derived from first principles. In ill-posed inverse problems the forward map is typically compact, so even a correctly specified model yields a non-degenerate posterior for finite data; the same smoothing may prevent Q from becoming singular, removing the diagnostic power of the posterior-vs-Q comparison. This assumption is load-bearing for the detection procedure.
Authors: We acknowledge that the concentration of Q is stated as an expectation grounded in the entropy-regularized objective rather than a first-principles derivation; a full theoretical treatment for general inverse problems is technically demanding and outside the paper's scope, which centers on the empirical diagnostic. In ill-posed regimes both the posterior and Q remain non-degenerate, yet our simulations indicate that misspecification still produces measurably greater dispersion in Q, preserving diagnostic value. We will add a clarifying paragraph in §2 discussing this subtlety and the reliance on empirical behavior. revision: partial
-
Referee: [§4] §4 (simulation study): the study is said to confirm that detection is possible, yet no quantitative performance metrics (e.g., detection error rates, ROC curves, or explicit thresholding rule for the posterior comparison) are reported. Without these, the empirical support for the central claim remains qualitative and difficult to assess.
Authors: We agree that quantitative metrics would strengthen the empirical section. In the revision we will report detection error rates across misspecification levels, include ROC curves for the posterior-versus-Q comparison, and explicitly state the thresholding rule used. revision: yes
-
Referee: [§5] §5 (seismology case study): this is the only experiment in the relevant ill-posed regime, but the manuscript provides no details on how the comparison between the Bayesian posterior and Q is operationalized (e.g., distance metric, concentration diagnostic, or decision threshold). The lack of such specification makes it impossible to reproduce or evaluate the reported detection.
Authors: We thank the referee for noting this gap. The revised §5 will specify the distance metric (2-Wasserstein), the concentration diagnostic (trace of covariance), and the decision threshold applied to the seismology example, enabling full reproducibility. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper defines the PrO mixing measure Q via minimization of an entropy-regularized objective on the lifted predictive model and proposes to detect misspecification by comparing it to the standard Bayesian posterior. The key supporting statement—that Q concentrates to a Dirac at the true parameter under well-specification—is presented as an expectation in the large-data limit rather than derived from the paper's own equations. No load-bearing step reduces by construction to a fitted parameter, self-citation chain, or renamed input; the method is instead validated through explicit simulation and a seismology case study. The derivation therefore remains independent of its target diagnostic.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption In the well-specified setting the mixing distribution Q concentrates around the true parameter in the large-data limit.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
QPrO := arg min −∑ log pQ(yi|xi) + KLD(Q||Q0)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
VGD dynamics and KGD consistency for LPrO
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Concentration and Calibration in Predictive Bayesian Inference
Predictive Bayesian inference posteriors concentrate onto a forward-model-dependent quantity and produce miscalibrated credible sets unless the predictive model contains the true data-generating process.
Reference graph
Works this paper leans on
-
[1]
M. A. Alvarez, D. Luengo, and N. D. Lawrence. Linear latent force models using G aussian processes. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35 0 (11): 0 2693--2705, 2013
work page 2013
-
[2]
L. Ambrosio, N. Gigli, and G. Savar \'e . Gradient Flows: In Metric Spaces and in the Space of Probability Measures. Springer Science & Business Media, 2008
work page 2008
-
[3]
S. Banerjee, K. Balasubramanian, and P. Ghosal. Improved finite-particle convergence rates for S tein variational gradient descent. In The Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[4]
M. Bayarri and J. O. Berger. P values for composite null models. Journal of the American Statistical Association, 95 0 (452): 0 1127--1142, 2000
work page 2000
-
[5]
P. G. Bissiri, C. C. Holmes, and S. G. Walker. A general framework for updating belief distributions. Journal of the Royal Statistical Society Series B: Statistical Methodology, 78 0 (5): 0 1103--1130, 2016
work page 2016
- [6]
- [7]
-
[8]
A. Curtis and R. Snieder. Probing the earth's interior with seismic tomography. International Geophysics, 81A: 0 861--874, 2002
work page 2002
- [9]
-
[10]
P. Dupuis and R. S. Ellis. A Weak Convergence Approach to the Theory of Large Deviations. John Wiley & Sons, 2011
work page 2011
-
[11]
A. M. Dziewonski, T.-A. Chou, and J. H. Woodhouse. Determination of earthquake source parameters from waveform data for studies of global and regional seismicity. Journal of Geophysical Research: Solid Earth, 86 0 (B4): 0 2825--2852, 1981
work page 1981
-
[12]
E. Fong and C. C. Holmes. On the marginal likelihood and cross-validation. Biometrika, 107 0 (2): 0 489--496, 2020
work page 2020
-
[13]
Large sample analysis of the median heuristic
D. Garreau, W. Jitkrittum, and M. Kanagawa. Large sample analysis of the median heuristic. arXiv preprint arXiv:1707.07269, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[14]
A. Gelman, X.-L. Meng, and H. Stern. Posterior predictive assessment of model fitness via realized discrepancies. Statistica Sinica, 6 0 (4): 0 733--760, 1996
work page 1996
-
[15]
P. Hartman. Ordinary Differential Equations. SIAM, 2002
work page 2002
-
[16]
K. Hu, Z. Ren, D. S i s ka, and . Szpruch. Mean-field L angevin dynamics and energy landscape of neural networks. Annales de l'Institut Henri Poincare (B) Probabilites et statistiques, 57 0 (4): 0 2043--2065, 2021
work page 2043
-
[17]
M. Jankowiak, G. Pleiss, and J. Gardner. Deep sigma point processes. In Conference on Uncertainty in Artificial Intelligence, pages 789--798. PMLR, 2020 a
work page 2020
-
[18]
M. Jankowiak, G. Pleiss, and J. Gardner. Parametric G aussian process regressors. In International Conference on Machine Learning, pages 4702--4712. PMLR, 2020 b
work page 2020
-
[19]
Testing hypotheses via a mixture estimation model
K. Kamary, K. Mengersen, C. P. Robert, and J. Rousseau. Testing hypotheses via a mixture estimation model. arXiv preprint arXiv:1412.2044, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2044
-
[20]
R. E. Kass and A. E. Raftery. Bayes factors. Journal of the American Statistical Association, 90 0 (430): 0 773--795, 1995
work page 1995
-
[21]
M. C. Kennedy and A. O'Hagan. Bayesian calibration of computer models. Journal of the Royal Statistical Society Series B, 63 0 (3): 0 425--464, 2001
work page 2001
- [22]
-
[23]
J. Knoblauch, J. Jewson, and T. Damoulas. An optimization-centric view on B ayes' rule: Reviewing and generalizing variational inference. Journal of Machine Learning Research, 23 0 (132): 0 1--109, 2022
work page 2022
- [24]
-
[25]
N. Laird. Nonparametric maximum likelihood estimation of a mixing distribution. Journal of the American Statistical Association, 73 0 (364): 0 805--811, 1978
work page 1978
-
[26]
B. G. Lindsay. Mixture Models: Theory, Geometry, and Applications. 1995
work page 1995
- [27]
- [28]
-
[29]
Y. McLatchie, B.-E. Cherief-Abdellatif, D. T. Frazier, and J. Knoblauch. Predictively oriented posteriors. arXiv preprint arXiv:2510.01915, 2025
-
[30]
G. E. Moran, D. M. Blei, and R. Ranganath. Holdout predictive checks for B ayesian model criticism. Journal of the Royal Statistical Society Series B, 86 0 (1): 0 194--214, 2024
work page 2024
-
[31]
W. R. Morningstar, A. Alemi, and J. V. Dillon. PACm-Bayes : N arrowing the empirical risk gap in the misspecified B ayesian regime. In International Conference on Artificial Intelligence and Statistics, pages 8270--8298. PMLR, 2022
work page 2022
-
[32]
D. J. Nott, C. Drovandi, and D. T. Frazier. Bayesian inference for misspecified generative models. Annual Review of Statistics and Its Application, 11: 0 179--202, 2023
work page 2023
-
[33]
J. Piironen and A. Vehtari. Comparison of B ayesian predictive methods for model selection. Statistics and Computing, 27 0 (3): 0 711--735, 2017
work page 2017
-
[34]
A. Rabinowicz and S. Rosset. Cross-validation for correlated data. Journal of the American Statistical Association, 117 0 (538): 0 718--731, 2022
work page 2022
-
[35]
N. Rawlinson and M. Sambridge. The fast marching method: A n effective tool for tomographic imaging and tracking multiple phases in complex layered media. Exploration Geophysics, 36 0 (4): 0 341--350, 2005
work page 2005
-
[36]
D. B. Rubin. Bayesianly justifiable and relevant frequency calculations for the applied statistician. The Annals of Statistics, 12 0 (4): 0 1151--1172, 1984
work page 1984
-
[37]
Z. Shen, J. Knoblauch, S. Power, and C. J. Oates. Prediction-centric uncertainty quantification via MMD . In AISTATS, 2025
work page 2025
-
[38]
R. Sheth and R. Khardon. Pseudo- B ayesian learning via direct loss minimization with applications to sparse G aussian process models. In Symposium on Advances in Approximate Bayesian Inference, pages 1--18. PMLR, 2020
work page 2020
-
[39]
S. G. Walker. Bayesian inference with misspecified models. Journal of Statistical Planning and Inference, 143 0 (10): 0 1621--1633, 2013
work page 2013
-
[40]
D. Wang and Q. Liu. Nonlinear S tein variational gradient descent for learning diversified mixture models. In International Conference on Machine Learning, pages 6576--6585. PMLR, 2019
work page 2019
- [41]
- [42]
-
[43]
A. Zellner. Optimal information processing and B ayes's theorem. The American Statistician, 42 0 (4): 0 278--280, 1988
work page 1988
-
[44]
X. Zhang and A. Curtis. Seismic tomography using variational inference methods. Journal of Geophysical Research: Solid Earth, 125 0 (4): 0 e2019JB018589, 2020
work page 2020
- [45]
-
[46]
X. Zhao, A. Curtis, and X. Zhang. Bayesian seismic tomography using normalizing flows. Geophysical Journal International, 228 0 (1): 0 213--239, 2022
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.