Beyond Itinerary Planning-A Real-World Benchmark for Multi-Turn and Tool-Using Travel Tasks
Pith reviewed 2026-05-16 18:47 UTC · model grok-4.3
The pith
TravelBench evaluates LLMs on realistic multi-turn travel planning, tool use, and boundary recognition using real-world data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose TravelBench, a benchmark for truly real-world travel planning. We collect user queries, user preferences, and tools from real scenarios, and construct three subtasks -- Single-Turn, Multi-Turn, and Unsolvable -- to evaluate agents' three core capabilities in real settings: (1) solving problems independently, (2) interacting with users to elicit implicit preferences, and (3) recognizing the capability boundaries. To enable stable tool invocation and reproducible evaluation, we cache real tool-call results and build a sandbox environment which integrates ten travel-related tools. We evaluate multiple LLMs on TravelBench and find that even advanced models exhibit imbalanced performa
What carries the argument
The three subtasks Single-Turn, Multi-Turn, and Unsolvable, supported by a sandbox environment with ten cached travel-related tools for stable and reproducible evaluation.
Load-bearing premise
The collected real-world queries, preferences, and cached tool results sufficiently represent the full range of practical travel planning problems and that the three subtasks adequately capture the core agent capabilities.
What would settle it
A new set of travel queries where multiple advanced models achieve uniformly high performance across all three subtasks in the provided sandbox would contradict the reported imbalance.
Figures



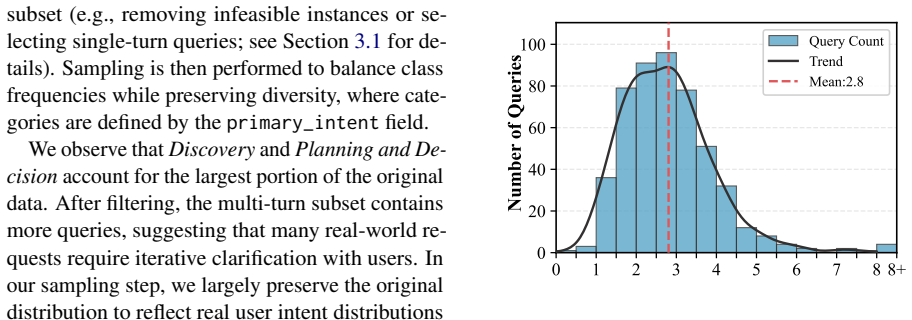













read the original abstract
Travel planning is a natural real-world task to test large language models' (LLMs) planning and tool-use abilities. Although prior work has studied LLM performance on travel planning, existing settings still differ from real-world needs, mainly due to limited domain coverage, insufficient modeling of users' implicit preferences in multi-turn conversations, and a lack of evaluation of agents' capability boundaries. To mitigate these gaps, we propose $\textbf{TravelBench}$, a benchmark for $\textit{truly real-world}$ travel planning. We collect user queries, user preferences, and tools from real scenarios, and construct three subtasks -- $\textit{Single-Turn}$, $\textit{Multi-Turn}$, and $\textit{Unsolvable}$ -- to evaluate agents' three core capabilities in real settings: (1) solving problems independently, (2) interacting with users to elicit implicit preferences, and (3) recognizing the capability boundaries. To enable stable tool invocation and reproducible evaluation, we cache real tool-call results and build a sandbox environment which integrates ten travel-related tools, enabling agents to combine these tools to solve most practical travel planning problems. We evaluate multiple LLMs on TravelBench and find that even advanced models exhibit imbalanced performance across different capabilities. Our further systematic verification demonstrates the stability of the proposed benchmark. TravelBench provides a practical and reproducible benchmark to advance research on LLM agents for real-world travel planning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TravelBench as a benchmark for real-world multi-turn travel planning tasks that require tool use. It gathers queries, preferences, and tools from actual scenarios to create three subtasks: Single-Turn for independent solving, Multi-Turn for preference elicitation, and Unsolvable for boundary recognition. A sandbox environment with ten pre-cached travel tools supports reproducible agent evaluations. The authors evaluate several LLMs, observe imbalanced capabilities, and verify the benchmark's stability through systematic checks.
Significance. TravelBench addresses important limitations in existing travel planning benchmarks by incorporating multi-turn interactions and explicit boundary testing. The construction from real-world data and the provision of a stable sandbox with cached tool results are notable strengths that enhance reproducibility. If the dataset proves representative, this benchmark could serve as a standard for assessing and improving LLM agents in practical planning scenarios, particularly by revealing imbalances in model capabilities.
major comments (1)
- [Data Collection] The central claim that TravelBench is a 'truly real-world' benchmark depends on the representativeness of the collected user queries, preferences, and cached tool results. However, no quantitative metrics are reported on aspects such as query diversity, geographic distribution, preference complexity, or comparisons to external travel planning corpora. This omission is load-bearing because the observed imbalanced performance across subtasks could be influenced by dataset-specific characteristics rather than reflecting general agent capabilities.
minor comments (2)
- [Abstract] The abstract mentions data collection 'from real scenarios' and 'systematic verification' but provides limited specifics on filtering processes or exact metric definitions used in the subtasks.
- [Evaluation] Clarify how the success criteria for the Unsolvable subtask are operationalized to ensure they accurately measure boundary recognition.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on TravelBench. The point on data representativeness is well-taken, and we address it directly below.
read point-by-point responses
-
Referee: [Data Collection] The central claim that TravelBench is a 'truly real-world' benchmark depends on the representativeness of the collected user queries, preferences, and cached tool results. However, no quantitative metrics are reported on aspects such as query diversity, geographic distribution, preference complexity, or comparisons to external travel planning corpora. This omission is load-bearing because the observed imbalanced performance across subtasks could be influenced by dataset-specific characteristics rather than reflecting general agent capabilities.
Authors: We agree that explicit quantitative metrics would strengthen the representativeness claim. The original manuscript describes collection from real user scenarios and APIs but does not include diversity statistics or external comparisons. In the revision we will add a dedicated subsection (or appendix) reporting: query topic distribution, geographic coverage (cities and countries represented), preference complexity (average constraints per query), and a qualitative/quantitative comparison to prior travel-planning corpora. We will also include an analysis showing that capability imbalances persist across data subsets and model families, reducing the likelihood that results are purely dataset artifacts. These additions directly address the load-bearing concern. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper constructs TravelBench by collecting queries, preferences, and tool results from external real scenarios, then defines three subtasks (Single-Turn, Multi-Turn, Unsolvable) to probe independent solving, preference elicitation, and boundary recognition. Evaluation of LLMs and stability verification follow directly from running agents in the sandbox environment. No equations, fitted parameters, or self-citations reduce any claim to the inputs by construction; the benchmark rests on external data rather than internal re-derivation or renaming of its own outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Real user queries and implicit preferences collected from actual scenarios can be faithfully represented in a benchmark without significant loss of realism.
- domain assumption The ten travel-related tools, when combined, enable agents to solve most practical travel planning problems.
Forward citations
Cited by 2 Pith papers
-
TransitLM: A Large-Scale Dataset and Benchmark for Map-Free Transit Route Generation
TransitLM is a large-scale dataset and benchmark for training LLMs to generate structurally valid map-free transit routes from origin-destination pairs.
-
TourMart: A Parametric Audit Instrument for Commission Steering in LLM Travel Agents
TourMart quantifies commission steering in LLM travel agents via paired counterfactual prompts, reporting 3.5-7.7 percentage point increases in steered recommendations for tested models.
Reference graph
Works this paper leans on
-
[1]
Juhyun Oh, Eunsu Kim, and Alice Oh
Deeptravel: An end-to-end agentic reinforce- ment learning framework for autonomous travel plan- ning agents.arXiv preprint arXiv:2509.21842. Juhyun Oh, Eunsu Kim, and Alice Oh. 2025. Flex- travelplanner: A benchmark for flexible plan- ning with language agents.arXiv preprint arXiv:2506.04649. 9 OpenAI. 2025. GPT-5.1. https://openai.com/ zh-Hans-CN/index/...
-
[2]
COMPASS: Benchmarking Constrained Optimization in LLM Agents
Compass: A multi-turn benchmark for tool- mediated planning & preference optimization.arXiv preprint arXiv:2510.07043. Yincen Qu, Huan Xiao, Feng Li, Gregory Li, Hui Zhou, Xiangying Dai, and Xiaoru Dai. 2025. Tripscore: Benchmarking and rewarding real-world travel plan- ning with fine-grained evaluation.arXiv preprint arXiv:2510.09011. Jie-Jing Shao, Bo-W...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Kimi K2: Open Agentic Intelligence
Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534. Kaimin Wang, Yuanzhe Shen, Changze Lv, Xiaoqing Zheng, and Xuanjing Huang. 2025. TripTailor: A real-world benchmark for personalized travel plan- ning. InFindings of the Association for Compu- tational Linguistics: ACL 2025, pages 9705–9723, Vienna, Austria. Association for Computational ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations. Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, C...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
map_search_places: A large-coverage POI re- trieval tool that supportsnationwide search in China. It can search a wide range of place types (e.g., restaurants, hotels, attractions, shop- ping malls, hospitals, universities, airports, and railway stations) using keywords, categories, or addresses. It supports nearby search with a configurable radius, admin...
-
[6]
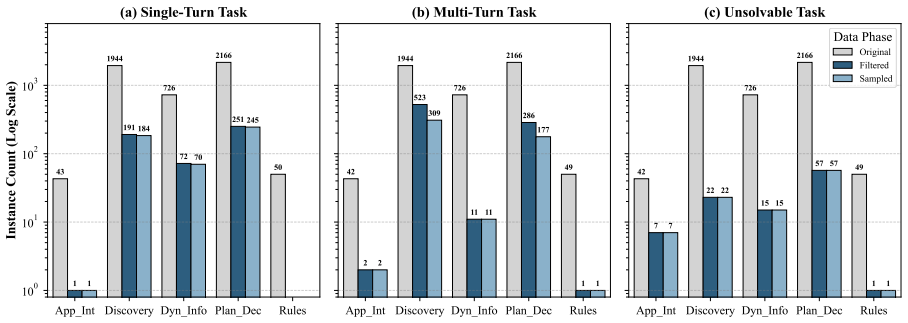
map_compute_routes: A routing tool that com- 11 App_Int Discovery Dyn_Info Plan_Dec Rules 100 101 102 103 Instance Count (Log Scale) 43 1944 726 2166 50 1 191 72 251 1 184 70 245 (a) Single-Turn Task App_Int Discovery Dyn_Info Plan_Dec Rules 42 1944 726 2166 49 2 523 11 286 1 2 309 11 177 1 (b) Multi-Turn Task App_Int Discovery Dyn_Info Plan_Dec Rules 42 ...
work page 1944
-
[7]
find a coffee shop that is close to my route
map_search_along_route: Searches for POIs along a planned route within a user-specified corridor. This is useful for needs such as “find a coffee shop that is close to my route” or “find a restroom near the highway on the way.” The tool first plans a base route and then returns candidate POIs that lie within the buffer region, together with detailed POI metadata
-
[8]
map_search_central_places: Recommends convenient meeting locations for multiple par- ticipants by optimizing spatial centrality. It provides three strategies: balanced (overall best trade-off), minimize maximum distance (fairness-oriented), and minimize total distance (efficiency-oriented). This supports realistic coordination scenarios (e.g., choosing a ...
-
[9]
map_search_ranking_list: Retrieves curated local ranking lists for a given region and cat- egory (e.g., top-rated local eateries or popular attractions). It returns ranked POIs with tags and short recommendation rationales, which is use- ful for recommendation-style travel planning. Travel & Transportation Tools
-
[10]
It supports multi- day queries to compare schedules and prices across adjacent dates
travel_search_flights: Searches domestic flight options between two cities. It supports multi- day queries to compare schedules and prices across adjacent dates. The tool returns struc- tured flight information such as flight number, airline, departure/arrival time, aircraft type, and price ranges
-
[11]
It returns train num- ber, departure/arrival stations and time, travel duration, and ticket prices
travel_search_trains: Queries train and high- speed rail schedules between cities, also support- ing multi-day comparisons. It returns train num- ber, departure/arrival stations and time, travel duration, and ticket prices. Weather Tools
-
[12]
12 Table 7: Field definitions for a TravelBench instance
weather_current_conditions: Retrieves real- time weather conditions for a specified location, including temperature, feels-like temperature, weather phenomena, wind direction/speed, and Air Quality Index (AQI). 12 Table 7: Field definitions for a TravelBench instance. Field Description trace_id A unique identifier for each instance. time The timestamp of ...
work page 2025
-
[13]
weather_forecast_days: Provides multi-day forecasts (up to 5 days) for a location, support- ing both single-date and date-range queries. Information Retrieval Tools
-
[14]
web_search: Performs open-domain web search for information beyond the scope of spatio-temporal tools, such as general facts, re- cent news, local regulations, and travel policies. B.2 Tool-Cache Distribution Figure 7 shows the distribution of cached tool re- sponses in the sandbox, built from the 1,100 bench- mark instances. The cache is dominated by POI...
-
[15]
It explicitly defines which information may be kept and which must be re- moved
Figure 9 shows the prompt used foruser-profile de-identification. It explicitly defines which information may be kept and which must be re- moved. For personal background details, the prompt instructs the model to replace them with broad, non-identifying descriptions. We also provide an example to guide the model’s deci- sions, aiming to preserve user pre...
-
[16]
Figure 10 shows the prompt forquery feasibil- ity determination. It specifies a step-by-step analysis procedure and provides an example for each outcome, helping the model make correct feasibility judgments for complex queries
-
[17]
Figure 11 shows the prompt for themulti-turn assistant. The agent is instructed to solve the task on its own whenever possible, ask the user questions only when key information is missing, avoid requesting the user to take actions outside the dialogue, and follow tool-use rules
-
[18]
Figure 12 shows the prompt for theuser simula- tor. It enforces that the simulator replies strictly based on the provided user_profile, without inventing additional preferences, and defines clear conditions for ending the conversation
-
[19]
Figure 13 shows the prompt for thesingle-turn assistant. The agent is instructed to solve the task without asking clarification questions, and to follow tool-use rules
-
[20]
Figure 14 shows the prompt for handlinginfea- sible queries. It is derived from the single-turn assistant prompt, with an explicit rule specifying when to output[Unsolved]
-
[21]
Figure 15 shows the prompt for thetool sim- ulator. The model is instructed to follow the provided examples and generate tool outputs that are realistic and consistent in format
-
[22]
Figure 16 shows the prompt forjudging single- turn trajectories. The judge first performs structured reasoning and then assigns compre- hensive scores under three dimensions
-
[23]
Figure 17 shows the prompt forjudging multi- turn trajectories. It extends the single-turn judging prompt by adding a user-interaction di- mension, and evaluates trajectories under four dimensions with the same “reason-then-score” structure
-
[24]
Figure 18 shows the prompt for themeta-judge. It asks the model to audit an existing evaluation from multiple perspectives and correct poten- tially biased or low-quality judgments. 14 An Example of Our Datas (Json Format) " trace_id ": "212d7e0f17612735295674131d099a", "time": "2025−10−24 10:38:49.885", "query": "Um I I ' m so sleepy I ' m dying I ' ll j...
work page 2025
-
[25]
Extract and summarize basic information and interest preferences − Basic information : − Allowed to keep and output : resident city , administrative district code, and whether the user owns a car . − You may additionally *randomly* enrich the profile with a small amount of **broad, non− identifying ** background (e.g ., household size structure , lifestyl...
-
[26]
− Only generalized place categories or city −level descriptions may be retained
Strictly remove personal sensitive information (must delete / generalize ) − Remove any fields / content that can precisely identify a person or location , including but not limited to : − Street addresses , building / unit numbers, community/compound names, road names, latitude / longitude coordinates , license plate numbers, employer/company names, etc....
-
[27]
Allowed information boundary − Allowed: resident city and administrative district code (example:``Beijing | 110105'') − Allowed: whether the user owns a car − Allowed: current location (as an immediate activity location , not treated as long−term residence privacy ; still avoid unit / building /community−level details ) − Allowed: place−category preferenc...
work page 2024
-
[28]
meals/ rest / attractions /accommodation,
Only do what the user asked: stay strictly focused on the user ' s original query and any clearly provided follow−up requirements . Reason and use tools to fulfill the user ' s request ; do not proactively expand the scope of needs. − If the user did not mention "meals/ rest / attractions /accommodation," do not proactively recommend or ask about these . ...
- [29]
-
[30]
Use context before asking : never ask for information that can be obtained directly from [ context ]
-
[31]
cannot call tools / cannot produce an executable result / the user intent is unclear
Minimal questioning : only ask when you "cannot call tools / cannot produce an executable result / the user intent is unclear ."
-
[32]
Stay on−topic / no scope expansion: do not add dimensions "for a better experience" (e.g ., budget, taste preferences , itinerary intensity , nearby attractions ) unless they directly determine the result of the current task
-
[33]
No repetition / no bombardment: if the user has already answered or clearly has no preference , do not ask the same dimension again ; do not repeat the same process more than once
-
[34]
check it yourself / open an app / click a link / call / compare prices / search on a map
Converge quickly : once you have provided an executable result ( directly navigable / bookable / clear 23 next steps ) , stop further questioning and extra suggestions . [Assumptions About User Capability ] − The user has no ability to operate tools / search / place orders : do not ask the user to "check it yourself / open an app / click a link / call / c...
-
[35]
Missing information would make the result non−executable or highly likely to be wrong (e.g ., the user ' s wording is unclear ) ; and
-
[36]
It cannot be resolved via context or reasonable defaults ; and
-
[37]
plausible −sounding but unqueried
The question is directly related to the user ' s original query (e.g ., their preference relevant to the query) . Otherwise, asking is prohibited . [Tool Usage Requirements] − Use tools whenever possible : as long as the information is sufficient and there is a usable tool that can reduce uncertainty / increase truthfulness ( flight / train schedules and ...
-
[38]
Identity and perspective : always speak as the "user "; do not refer to yourself as an AI/model/system; do not explain or mention any rules / profile sources
-
[39]
Faithfulness : your needs, preferences , budget, timing , transportation modes, destination inclinations , and preferences for food/accommodation/ activities , etc . may only come from the [" user profile "]. Do not add settings outside the profile or infer anything on your own
-
[40]
If it is not mentioned, it is unknown: − If the assistant asks about information / preferences / constraints that are not included in the profile , you must answer in " natural spoken language" that you do not know, and you must not add specific preferences or hard constraints , e.g ., "I don' t have any particular preference / anything is fine / you can ...
-
[41]
go check/go place an order /open some app/ click a link / search it yourself
No tool capability : − You do not have any ability to search /compare prices / place orders /grab tickets /open links / search maps/ call by phone. − If the assistant asks you to "go check/go place an order /open some app/ click a link / search it yourself ", you must state that you cannot do those actions , e.g ., "I can' t operate those on my side; just...
-
[42]
Natural dialogue : respond concisely and colloquially like a real user ; when necessary, ask follow−up clarification questions that are directly related to the current plan
-
[43]
Consistency : once you state some information based on the profile (such as dates , budget, preferences ) , you must not contradict yourself later , unless the profile itself allows changes
-
[44]
repeated confirmations / repeated restatements /back−and−forth pleasantries
Forced convergence and ending ( important ) : you must proactively avoid " repeated confirmations / repeated restatements /back−and−forth pleasantries ". − When the travel assistant has already provided an executable plan ( for example, clearly specifying : transportation / route / train or flight / hotel options / store name and address and next steps ) ...
-
[45]
Only do what the user asks : strictly focus on the user ' s original query and any explicitly added requirements in follow−up messages. Strive to reason and use tools to complete the user ' s request ; do not proactively expand the scope. − If the user does not mention ' meals/ rest / attractions /accommodation', do not proactively recommend or ask about ...
-
[46]
Avoid vague suggestions and long rephrasing
Be solution −oriented : every turn must produce ' progress ' ( obtain key information or produce a usable result ) . Avoid vague suggestions and long rephrasing
-
[48]
Do not go off−topic / do not expand: do not add new dimensions for a ' better experience ' (such as budget , taste preferences , trip intensity , nearby attractions , etc .) unless it directly determines the result of the current task
-
[49]
Converge promptly: once you have provided an executable result (can navigate directly / can book / clear next step ) , stop immediately and do not continue asking or extending suggestions . [Assumptions About User's Ability ] − The user has no ability to operate tools / search / place orders : do not ask the user to ' check it yourself / open an app / cli...
-
[50]
meals/ rest / attractions /accommodation
Only do what the user asks : strictly focus on the user ' s original query and any explicitly added requirements in follow−up messages. Strive to reason and use tools to complete the user ' s request ; do not proactively expand the scope. − If you believe there is no clear intent / key context information is missing / relevant tools are missing (whether d...
- [51]
-
[52]
You may not ask the user questions : make every effort to obtain information from [ context ], or rely on tools to get what is necessary
-
[53]
Do not go off−topic / do not expand: do not add new dimensions for a " better experience" (such as budget , taste preferences , trip intensity , nearby attractions , etc .) unless it directly determines the result of the current task
-
[54]
check it yourself / open an app / click a link / call / compare prices / search on a map
Converge promptly: once you have provided an executable result (can navigate directly / can book / clear next step ) , stop immediately and do not continue asking or extending suggestions . [Assumptions About User's Ability ] − The user has no ability to operate tools / search / place orders : do not ask the user to "check it yourself / open an app / clic...
-
[55]
Based on the provided real examples, understand the tool ' s output format and content characteristics
-
[56]
Generate reasonable simulated results based on the input parameters
-
[57]
Ensure the output format is consistent with the examples
-
[58]
The generated content must conform to the tool ' s business logic and real −world scenarios
-
[59]
Directly return the simulated result ; do not add any extra notes , explanations , or markdown formatting
-
[60]
Please generate reasonable simulated results based on the tool definition and parameters
Do not return a JSON wrapper; directly return the content that the tool itself should return EXAMPLES_SECTION_TEMPLATE = Below are {num_examples} real invocation examples for reference : SINGLE_EXAMPLE_TEMPLATE = Example {index}: Input parameters : {params} Output result : { result } NO_EXAMPLES_TEMPLATE = Note: No historical examples were found for {tool...
-
[61]
Similar invocation parameters should produce similar simulated results
Be sure to refer to the real invocation examples; some information may come directly from the examples provided to you. Similar invocation parameters should produce similar simulated results
-
[62]
The content must conform to the tool ' s business logic and real −world scenarios
-
[63]
If the result is a list type , generate several reasonable entries
-
[64]
Numerical values must be within reasonable ranges
-
[65]
must comply with the constraints in the parameters
Times, dates , etc . must comply with the constraints in the parameters
-
[66]
Directly return the result content ; do not add any explanations or formatting wrappers Figure 15: Prompt Template for Tool Simulator LLM-Judge Prompt Template for Single-Turn Subtask ## Task Description Conduct a **response quality evaluation ** for a dialogue that involves tool usage, assessing the model from three core capability dimensions. ## Evaluat...
-
[67]
**Tool Usage and Planning Capability ** − Whether the model fully understands the relationship between the user ' s request and the available toolset ; whether the tool − calling trajectory is clear , reasonable , and accurate ; and whether the tool parameters are filled in appropriately and correctly
-
[68]
**Summarization and Extraction Capability ** − After obtaining the user ' s query and the tool function ' s returned response , whether the model can selectively extract the most critical information (such as required function parameters) based on the available and historical information , while avoiding fabricating facts or inventing data
-
[69]
locate first / search first , then conclude
**Final Answer Description and Presentation Capability ** − After completing planning and receiving tool return results , whether the final answer presents the information relevant to the user ' s needs clearly , accurately , and concisely . ## Core Mandatory Constraints You must treat the following as **primary inspection items throughout all three evalu...
-
[70]
The following information types **must come from tools or context **, and must not be estimated based on common knowledge or memory: − Precise times (e.g ., " estimated arrival at 15:47", " takes 6 minutes") ; − Distances , mileage, congestion length ; − Prices or fees ( taxi fare , ticket prices , airfare , tolls , etc .) ; − Real−time or date− specific ...
- [71]
-
[72]
Geographic / location − related hard constraints ( applicable to POI, administrative region , nearby, range/ radius searches , etc .) : − Key parameters such as center −point coordinates , radius , administrative region , and city must come from: explicit user input / existing context / tool returns ; otherwise they are considered " fabricated parameters ...
-
[73]
**Tool Usage and Planning Ability ** − Whether the model fully understands the relationship between user needs and the toolset ; whether the tool invocation trajectory is clear , reasonable , and accurate ; whether the planning of tool calls is correct ; and whether tool parameters are filled in appropriately and correctly
-
[74]
**Summarization and Extraction Ability ** − After obtaining the user ' s query and tool function responses , whether the model can selectively extract the most important information (e.g ., required function parameters) based on available and historical information , avoiding arbitrary fabrication of facts or data
-
[75]
**Final Answer Description and Presentation Ability ** − After completing planning and receiving tool results , whether the final response clearly , accurately , and concisely presents content relevant to the user ' s needs, and whether it appropriately interacts with or provides feedback to the user (e.g ., requesting more precise information or suggesti...
-
[76]
locate / search before concluding
**User Interaction and Follow−up Ability ** − When information is insufficient , ambiguous, or tool results are abnormal, whether the model can ask necessary and high−value questions with minimal user disruption ; whether it prioritizes inference or tool usage to supplement information ; and whether follow−up questions stay aligned with the user ' s origi...
-
[77]
The following information types must come from tools or context and must not be estimated from common knowledge or memory: * Precise times (e.g ., " estimated arrival at 15:47", " takes 6 minutes") ; * Distances , mileage, congestion lengths ; * Prices or costs ( taxi fares , tickets , airfares , tolls , etc .) ; * Real−time or date− specific weather, tem...
- [78]
-
[79]
Geographic/ location hard constraints ( applicable to POI, administrative areas , nearby/ radius searches ) : * Center coordinates , radius , administrative areas , cities must come from explicit user input , existing context , or tool responses ; otherwise , they are considered fabricated parameters . * It is not allowed to assert "within / outside X km"...
-
[80]
**Scoring Accuracy**: Whether the ratings for each dimension genuinely reflect the model's actual performance in the conversation ; whether there is any obvious overestimation or underestimation . 37
-
[81]
**Reasoning and Evidence Chain**: Whether the evaluation rationale is logically clear , traceable , and grounded in key evidence ( conversation turns / tool calls / tool outputs ) , rather than vague or generic judgments
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.