TransitLM: A Large-Scale Dataset and Benchmark for Map-Free Transit Route Generation
Pith reviewed 2026-05-22 05:44 UTC · model grok-4.3
The pith
An LLM trained on historical transit records can generate valid routes and ground GPS points to stations without any maps or routing engines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
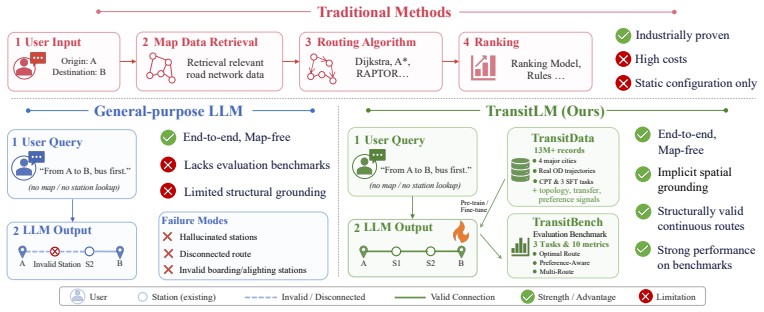
The paper establishes that transit route planning reduces to a sequence-generation task that a large language model can master when given a large corpus of past origin-destination records. After training, the model outputs complete, structurally valid itineraries and, without any separate location database, maps raw GPS coordinates to the nearest appropriate stations. The results indicate that the implicit regularities in historical travel data are sufficient to support generalization to new queries.
What carries the argument
The TransitLM dataset of 13 million historical route records, used as continual pre-training data, supplies the implicit network structure that lets the model learn valid sequences and coordinate-to-station mappings directly.
If this is right
- Route generation becomes possible with only origin and destination text or coordinates as input.
- No separate map database or graph engine is required at inference time.
- The same model can handle both textual addresses and raw GPS locations in one forward pass.
- New cities or lines can be incorporated simply by adding more historical records to the training corpus.
Where Pith is reading between the lines
- The method could be tested on other sequential planning tasks such as delivery routing or multi-modal journey planning where explicit graphs are costly to maintain.
- Accuracy might improve further if the training data were augmented with synthetic but realistic route variations that preserve line constraints.
- Deployment in low-resource settings becomes feasible because the only required runtime component is the trained model weights.
Load-bearing premise
Historical route records already contain enough hidden regularities that a model can learn to connect arbitrary new origin and destination points without ever seeing an explicit map.
What would settle it
Test the trained model on a held-out set of origin-destination pairs that require transfers or use stations never seen in training; if the fraction of routes that violate line connectivity or station existence exceeds a small threshold, the claim does not hold.
Figures






read the original abstract
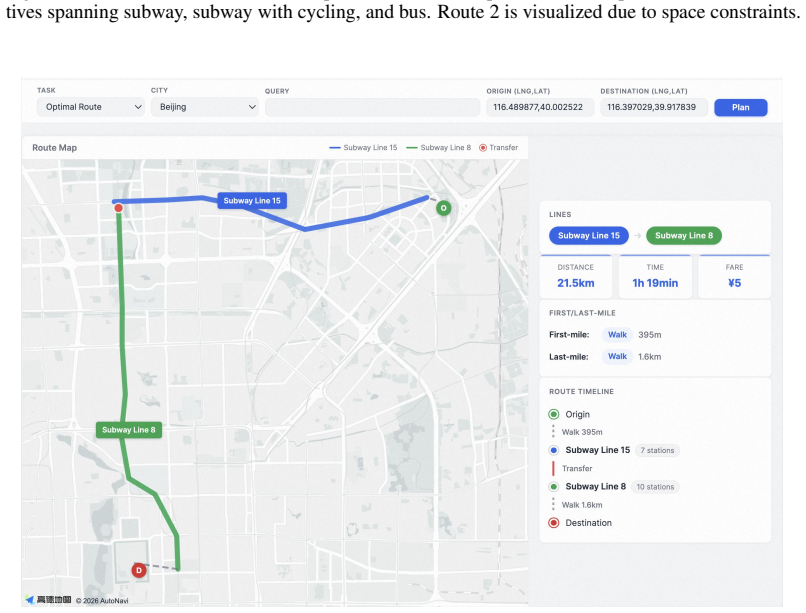
Public transit route planning traditionally depends on structured map infrastructure and complex routing engines, and no existing dataset supports training models to bypass this dependency. We present TransitLM, a large-scale dataset of over 13 million transit route planning records from four Chinese cities covering 120,845 stations and 13,666 lines, released as a continual pre-training corpus and benchmark data for three evaluation tasks with complementary metrics. Experiments show that an LLM trained on TransitLM produces structurally valid routes at high accuracy and implicitly grounds arbitrary GPS coordinates to appropriate stations without any explicit mapping. These results demonstrate that transit route planning can be learned entirely from data, enabling end-to-end, map-free route generation directly from origin-destination information. The dataset and benchmark are available at https://huggingface.co/datasets/GD-ML/TransitLM, with evaluation code at https://github.com/HotTricker/TransitLM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TransitLM, a large-scale dataset of over 13 million transit route planning records from four Chinese cities covering 120,845 stations and 13,666 lines. It is positioned as a continual pre-training corpus and benchmark for three evaluation tasks with complementary metrics. The central claim is that an LLM trained on TransitLM produces structurally valid routes at high accuracy and implicitly grounds arbitrary GPS coordinates to appropriate stations without any explicit mapping, enabling end-to-end map-free route generation directly from origin-destination information.
Significance. If substantiated with quantitative evidence, the result would be significant for demonstrating that complex spatial and routing tasks can be learned entirely from historical data without maps or engines. The public release of the dataset and evaluation code is a clear strength supporting reproducibility and further work in data-driven transit planning.
major comments (2)
- Abstract: The assertion that the LLM 'produces structurally valid routes at high accuracy' supplies no quantitative metrics, error analysis, baseline comparisons, or details on how structural validity was measured. This leaves the central claim without visible supporting evidence and requires explicit results in the experiments section to be load-bearing.
- Experiments section: The claim of implicit GPS-to-station grounding without explicit mapping is central to the map-free contribution. The manuscript provides no details on GPS tokenization, whether station coordinates are leaked into inputs, or the geographic spread of test queries relative to training data. This raises a correctness risk that success may stem from proximity to training locations rather than learned general structure, directly testing the assumption that historical records contain sufficient implicit structure for generalization to new queries.
minor comments (1)
- Clarify the exact definitions and metrics for the three evaluation tasks in the benchmark description to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the presentation of our central claims. We address each major comment below and have prepared revisions to strengthen the manuscript's evidentiary support and technical details.
read point-by-point responses
-
Referee: Abstract: The assertion that the LLM 'produces structurally valid routes at high accuracy' supplies no quantitative metrics, error analysis, baseline comparisons, or details on how structural validity was measured. This leaves the central claim without visible supporting evidence and requires explicit results in the experiments section to be load-bearing.
Authors: We agree that the abstract would be strengthened by including key quantitative results. In the revised manuscript, we have added a sentence to the abstract reporting the primary accuracy figures for structural validity (e.g., route validity rate and station grounding accuracy) along with a brief note on the evaluation metrics. We have also expanded the experiments section (Section 4) to include explicit baseline comparisons, error analysis broken down by route complexity, and a dedicated paragraph detailing how structural validity is operationalized via the three complementary tasks and their metrics. These changes make the central claim directly supported by visible evidence. revision: yes
-
Referee: Experiments section: The claim of implicit GPS-to-station grounding without explicit mapping is central to the map-free contribution. The manuscript provides no details on GPS tokenization, whether station coordinates are leaked into inputs, or the geographic spread of test queries relative to training data. This raises a correctness risk that success may stem from proximity to training locations rather than learned general structure, directly testing the assumption that historical records contain sufficient implicit structure for generalization to new queries.
Authors: We appreciate the referee highlighting the need for greater transparency on the map-free mechanism. In the revision, we have added a new subsection in the experiments section that describes the GPS tokenization scheme (coordinate discretization into tokens without any station ID or coordinate leakage into the input sequence), confirms that station coordinates are never provided as input features, and reports the geographic distribution of test queries (including a split showing performance on queries from regions with low overlap to training data). We further include results from an out-of-distribution evaluation set to demonstrate generalization beyond proximity to training locations, supporting that the model learns implicit structure from historical records. revision: yes
Circularity Check
No significant circularity; results from external dataset and standard training
full rationale
The paper collects a large external dataset of over 13 million real-world transit records from four Chinese cities, releases it as a pre-training corpus and benchmark, and reports empirical results from training an LLM on this data. The central claim of implicit GPS-to-station grounding and valid route generation is presented as an observed experimental outcome on held-out evaluation tasks, not as a mathematical derivation that reduces to its own inputs by construction. No self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided abstract or described methodology. The approach is self-contained against the externally gathered data and follows standard ML dataset/benchmark practices.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Transit route planning patterns can be learned implicitly from historical route data without explicit map or routing engine knowledge.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experiments show that an LLM trained on TransitLM produces structurally valid routes at high accuracy and implicitly grounds arbitrary GPS coordinates to appropriate stations without any explicit mapping.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. GPT-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Fast routing in very large public transportation networks using transfer patterns
Hannah Bast, Erik Carlsson, Arno Eigenwillig, Robert Geisberger, Chris Harrelson, Veselin Raychev, and Fabien Viger. Fast routing in very large public transportation networks using transfer patterns. InEuropean Symposium on Algorithms, pages 290–301, 2010
work page 2010
-
[3]
Route planning in transportation networks
Hannah Bast, Daniel Delling, Andrew Goldberg, Matthias M ¨uller-Hannemann, Thomas Pajor, Peter Sanders, Dorothea Wagner, and Renato F Werneck. Route planning in transportation networks. In Algorithm engineering: Selected results and surveys, pages 19–80. 2016
work page 2016
-
[4]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in Neural Information Processing Systems, 33:1877–1901, 2020
work page 1901
-
[5]
TripCraft: A benchmark for spatio-temporally fine grained travel planning
Soumyabrata Chaudhuri, Pranav Purkar, Ritwik Raghav, Shubhojit Mallick, Manish Gupta, Abhik Jana, and Shreya Ghosh. TripCraft: A benchmark for spatio-temporally fine grained travel planning. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics, pages 17035–17064, 2025
work page 2025
-
[6]
Beyond Itinerary Planning-A Real-World Benchmark for Multi-Turn and Tool-Using Travel Tasks
Xiang Cheng, Yulan Hu, Xiangwen Zhang, Lu Xu, Zheng Pan, Xin Li, and Yong Liu. TravelBench: A real-world benchmark for multi-turn and tool-augmented travel planning.arXiv preprint arXiv:2512.22673, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Unique in the crowd: The privacy bounds of human mobility.Scientific reports, 3(1):1376, 2013
Yves-Alexandre De Montjoye, C´esar A Hidalgo, Michel Verleysen, and Vincent D Blondel. Unique in the crowd: The privacy bounds of human mobility.Scientific reports, 3(1):1376, 2013
work page 2013
-
[8]
Round-based public transit routing.Transportation Science, 49(3):591–604, 2015
Daniel Delling, Thomas Pajor, and Renato F Werneck. Round-based public transit routing.Transportation Science, 49(3):591–604, 2015
work page 2015
-
[9]
Fast and exact public transit routing with restricted pareto sets
Daniel Delling, Julian Dibbelt, and Thomas Pajor. Fast and exact public transit routing with restricted pareto sets. InProceedings of the Twenty-First Workshop on Algorithm Engineering and Experiments, pages 54–65, 2019
work page 2019
-
[10]
Connection scan algorithm.Journal of Experimental Algorithmics, 23:1–56, 2018
Julian Dibbelt, Thomas Pajor, Ben Strasser, and Dorothea Wagner. Connection scan algorithm.Journal of Experimental Algorithmics, 23:1–56, 2018
work page 2018
-
[11]
A note on two problems in connexion with graphs
Edsger W Dijkstra. A note on two problems in connexion with graphs. InEdsger Wybe Dijkstra: his life, work, and legacy, pages 287–290. 2022
work page 2022
-
[12]
Bowen Fang, Zixiao Yang, and Xuan Di. TraveLLM: Could you plan my public transit alternatives in face of a network disruption? In2025 IEEE 28th International Conference on Intelligent Transportation Systems (ITSC), pages 4711–4717, 2025
work page 2025
-
[13]
CityBench: Evaluating the capabilities of large language models for urban tasks
Jie Feng, Jun Zhang, Tianhui Liu, Xin Zhang, Tianjian Ouyang, Junbo Yan, Yuwei Du, Siqi Guo, and Yong Li. CityBench: Evaluating the capabilities of large language models for urban tasks. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pages 5413–5424, 2025
work page 2025
-
[14]
Sicheng Feng, Song Wang, Shuyi Ouyang, Lingdong Kong, Zikai Song, Jianke Zhu, Huan Wang, and Xinchao Wang. Can MLLMs guide me home? A benchmark study on fine-grained visual reasoning from transit maps.arXiv preprint arXiv:2505.18675, 2025
-
[15]
Don’t stop pretraining: Adapt language models to domains and tasks
Suchin Gururangan, Ana Marasovi ´c, Swabha Swayamdipta, Kyle Lo, Iz Beltagy, Doug Downey, and Noah A Smith. Don’t stop pretraining: Adapt language models to domains and tasks. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8342–8360, 2020
work page 2020
-
[16]
OpenStreetMap: User-generated street maps.IEEE Pervasive Computing, 7(4):12–18, 2008
Mordechai Haklay and Patrick Weber. OpenStreetMap: User-generated street maps.IEEE Pervasive Computing, 7(4):12–18, 2008
work page 2008
-
[17]
Peter E Hart, Nils J Nilsson, and Bertram Raphael. A formal basis for the heuristic determination of minimum cost paths.IEEE Transactions on Systems Science and Cybernetics, 4(2):100–107, 1968
work page 1968
-
[18]
Training compute- optimal large language models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, et al. Training compute- optimal large language models. InAdvances in Neural Information Processing Systems, pages 30016– 30030, 2022. 10
work page 2022
-
[19]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Information Systems, 43(2):1–55, 2025
work page 2025
-
[20]
Position: LLMs can’t plan, but can help planning in LLM-modulo frameworks
Subbarao Kambhampati, Karthik Valmeekam, Lin Guan, Mudit Verma, Kaya Stechly, Siddhant Bhambri, Lucas Paul Saldyt, and Anil B Murthy. Position: LLMs can’t plan, but can help planning in LLM-modulo frameworks. InInternational Conference on Machine Learning, 2024
work page 2024
-
[21]
Siqi Lai, Yansong Ning, Zirui Yuan, Zhixi Chen, and Hao Liu. USTBench: Benchmarking and dissecting spatiotemporal reasoning of LLMs as urban agents.arXiv preprint arXiv:2505.17572, 2025
-
[22]
GridRoute: A benchmark for LLM-based route planning with cardinal movement in grid environments
Kechen Li, Yaotian Tao, Ximing Wen, Quanwei Sun, Zifei Gong, Chang Xu, Xizhe Zhang, and Tianbo Ji. GridRoute: A benchmark for LLM-based route planning with cardinal movement in grid environments. arXiv preprint arXiv:2505.24306, 2025
-
[23]
GeoLM: Empowering language models for geospatially grounded language understanding
Zekun Li, Wenxuan Zhou, Yao-Yi Chiang, and Muhao Chen. GeoLM: Empowering language models for geospatially grounded language understanding. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 5227–5240, 2023
work page 2023
-
[24]
LLM-A*: Large language model enhanced incremental heuristic search on path planning
Silin Meng, Yiwei Wang, Cheng-Fu Yang, Nanyun Peng, and Kai-Wei Chang. LLM-A*: Large language model enhanced incremental heuristic search on path planning. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 1087–1102, 2024
work page 2024
-
[25]
Luis Moreira-Matias, Joao Gama, Michel Ferreira, Joao Mendes-Moreira, and Luis Damas. Predicting taxi–passenger demand using streaming data.IEEE Transactions on Intelligent Transportation Systems, 14 (3):1393–1402, 2013
work page 2013
-
[26]
Hang Ni, Fan Liu, Xinyu Ma, Lixin Su, Shuaiqiang Wang, Dawei Yin, Hui Xiong, and Hao Liu. TP-RAG: Benchmarking retrieval-augmented large language model agents for spatiotemporal-aware travel planning. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 12403–12429, 2025
work page 2025
-
[27]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, et al. Training language models to follow instructions with human feedback. InAdvances in Neural Information Processing Systems, volume 35, pages 27730–27744, 2022
work page 2022
-
[28]
MapTrace: Scalable data generation for route tracing on maps.arXiv preprint arXiv:2512.19609, 2025
Artemis Panagopoulou, Aveek Purohit, Achin Kulshrestha, Soroosh Yazdani, and Mohit Goyal. MapTrace: Scalable data generation for route tracing on maps.arXiv preprint arXiv:2512.19609, 2025
-
[29]
Zero: Memory optimizations toward training trillion parameter models
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimizations toward training trillion parameter models. InSC20: international conference for high performance computing, networking, storage and analysis, pages 1–16. IEEE, 2020
work page 2020
-
[30]
Timo Schick, Jane Dwivedi-Yu, Roberto Dess`ı, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in Neural Information Processing Systems, 36:68539–68551, 2023
work page 2023
-
[31]
ChinaTravel: An open-ended benchmark for language agents in Chinese travel planning
Jie-Jing Shao, Bo-Wen Zhang, Xiao-Wen Yang, Baizhi Chen, Siyu Han, Wen-Da Wei, Guohao Cai, Zhenhua Dong, Lan-Zhe Guo, and Yu-Feng Li. ChinaTravel: An open-ended benchmark for language agents in Chinese travel planning. InNeurIPS 2025 Workshop on Evaluating the Evolving LLM Lifecycle, 2025
work page 2025
-
[32]
Yuanzhe Shen, Zisu Huang, Zhengyuan Wang, et al. TRIP-Bench: A benchmark for long-horizon interactive agents in real-world scenarios.arXiv preprint arXiv:2602.01675, 2026
-
[33]
Zhiheng Song, Jingshuai Zhang, Chuan Qin, et al. MobilityBench: A benchmark for evaluating route- planning agents in real-world mobility scenarios.arXiv preprint arXiv:2602.22638, 2026
-
[34]
On the planning abilities of large language models – a critical investigation
Karthik Valmeekam, Matthew Marquez, Sarath Sreedharan, and Subbarao Kambhampati. On the planning abilities of large language models – a critical investigation. InAdvances in Neural Information Processing Systems, volume 36, pages 75993–76005, 2023
work page 2023
-
[35]
TripTailor: A real- world benchmark for personalized travel planning
Kaimin Wang, Yuanzhe Shen, Changze Lv, Xiaoqing Zheng, and Xuan-Jing Huang. TripTailor: A real- world benchmark for personalized travel planning. InFindings of the Association for Computational Linguistics: ACL 2025, pages 9705–9723, 2025
work page 2025
-
[36]
Liang Wang, He Wei, Yu Guan, Libin Ouyang, DanDan Xu, Xuehua Han, Min Zhang, Meng Chen, Daosheng Sun, Daqing Gong, et al. China public transport operation network dataset (CPTOND-2025): National-scale bus-metro vector dataset.Scientific Data, 2026. 11
work page 2025
-
[37]
Finetuned language models are zero-shot learners
Jason Wei, Maarten Bosma, Vincent Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners. InInternational Conference on Learning Representations, 2022
work page 2022
-
[38]
James Wong. Leveraging the general transit feed specification for efficient transit analysis.Transportation Research Record, 2338(1):11–19, 2013
work page 2013
-
[39]
TravelPlanner: A benchmark for real-world planning with language agents
Jian Xie, Kai Zhang, Jiangjie Chen, Tinghui Zhu, Renze Lou, Yuandong Tian, Yanghua Xiao, and Yu Su. TravelPlanner: A benchmark for real-world planning with language agents. InInternational Conference on Machine Learning, pages 54590–54613, 2024
work page 2024
-
[40]
Can large vision language models read maps like a human?arXiv preprint arXiv:2503.14607, 2025
Shuo Xing, Zezhou Sun, Shuangyu Xie, Kaiyuan Chen, Yanjia Huang, Yuping Wang, Jiachen Li, Dezhen Song, and Zhengzhong Tu. MapBench: Can large vision language models read maps like a human?arXiv preprint arXiv:2503.14607, 2025
-
[41]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
T-drive: Driving directions based on taxi trajectories
Jing Yuan, Yu Zheng, Chengyang Zhang, Wenlei Xie, Xing Xie, Guangzhong Sun, and Yan Huang. T-drive: Driving directions based on taxi trajectories. InProceedings of the 18th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, pages 99–108, 2010
work page 2010
-
[43]
Huaixiu Steven Zheng, Swaroop Mishra, Hugh Zhang, Xinyun Chen, Minmin Chen, Azade Nova, Le Hou, Heng-Tze Cheng, Quoc V Le, Ed H Chi, et al. NATURAL PLAN: Benchmarking LLMs on natural language planning.arXiv preprint arXiv:2406.04520, 2024
-
[44]
Yu Zheng. Trajectory data mining: an overview.ACM Transactions on Intelligent Systems and Technology, 6(3):1–41, 2015
work page 2015
-
[45]
Yu Zheng, Xing Xie, and Wei-Ying Ma. GeoLife: A collaborative social networking service among user, location and trajectory.IEEE Data Engineering Bulletin, 33(2):32–39, 2010. 12 A Data Visualization Figure 3 visualizes the spatial distribution of route planning origins across the four cities. The heatmaps reveal dense coverage in urban cores with natural ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.