Pixel-to-4D: Camera-Controlled Image-to-Video Generation with Dynamic 3D Gaussians
Pith reviewed 2026-05-21 16:00 UTC · model grok-4.3
The pith
A single image can generate camera-controlled videos by constructing a dynamic 3D Gaussian scene in one forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
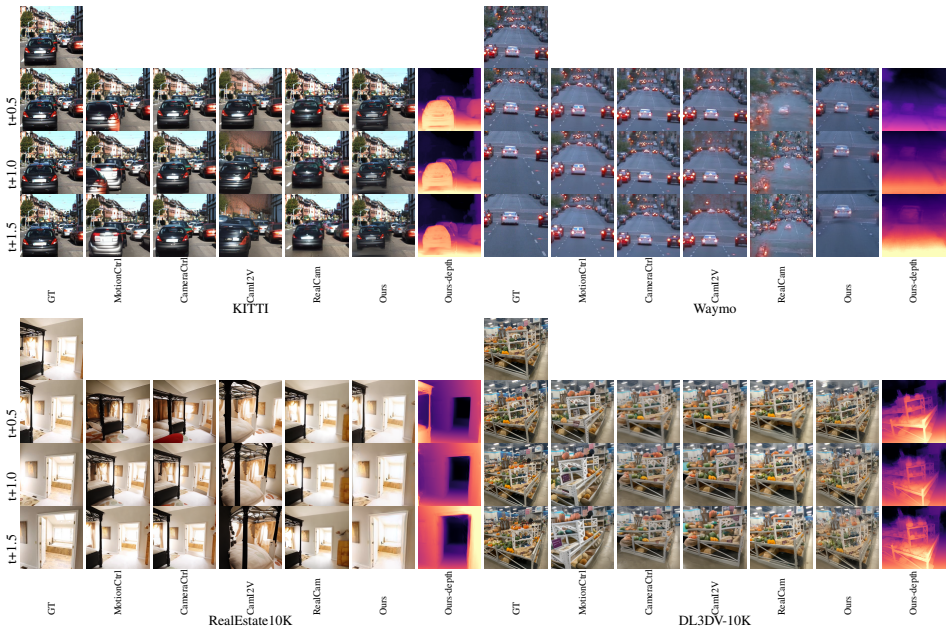
We propose a novel framework that constructs a 3D Gaussian scene representation and samples plausible object motion, given a single image in a single forward pass. This enables fast, camera-guided video generation without the need for iterative denoising to inject object motion into render frames. Experiments on the KITTI, Waymo, RealEstate10K and DL3DV-10K datasets demonstrate state-of-the-art video quality and inference efficiency.
What carries the argument
Dynamic 3D Gaussian scene representation, a point-based model that captures both static geometry and sampled object motion from a single input image.
If this is right
- Camera paths can be modified freely while maintaining temporal coherence in the output video.
- Object motion is injected without iterative denoising, speeding up inference significantly.
- Geometric integrity is preserved better than in two-stage point cloud methods.
- State-of-the-art results are achieved on KITTI, Waymo, RealEstate10K, and DL3DV-10K datasets.
Where Pith is reading between the lines
- This could allow real-time animation of static photos in consumer apps by extending the single-pass approach.
- Testing on non-rigid scenes like humans or animals might reveal limits in the motion sampling.
- Integration with other sensors could relax the single-image assumption in future iterations.
Load-bearing premise
The single input image contains sufficient geometric and appearance information to construct a complete 3D Gaussian scene whose dynamics can be sampled plausibly without additional views or depth sensors.
What would settle it
Running the method on a single image of a complex indoor scene with hidden objects or ambiguous depths and observing whether the generated video maintains consistent 3D structure and plausible motion across frames.
Figures



read the original abstract
Humans excel at forecasting the future dynamics of a scene given just a single image. Video generation models that can mimic this ability are an essential component for intelligent systems. Recent approaches have improved temporal coherence and 3D consistency in single-image-conditioned video generation. However, these methods often lack robust user controllability, such as modifying the camera path, limiting their applicability in real-world applications. Most existing camera-controlled image-to-video models struggle with accurately modeling camera motion, maintaining temporal consistency, and preserving geometric integrity. Leveraging explicit intermediate 3D representations offers a promising solution by enabling coherent video generation aligned with a given camera trajectory. Although these methods often use 3D point clouds to render scenes and introduce object motion in a later stage, this two-step process still falls short in achieving full temporal consistency, despite allowing precise control over camera movement. We propose a novel framework that constructs a 3D Gaussian scene representation and samples plausible object motion, given a single image in a single forward pass. This enables fast, camera-guided video generation without the need for iterative denoising to inject object motion into render frames. Extensive experiments on the KITTI, Waymo, RealEstate10K and DL3DV-10K datasets demonstrate that our method achieves state-of-the-art video quality and inference efficiency. The project page is available at https://melonienimasha.github.io/Pixel-to-4D-Website.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Pixel-to-4D, a framework that lifts a single input image to a dynamic 3D Gaussian scene representation in one forward pass, samples plausible object motion parameters, and renders temporally consistent video frames under user-specified camera trajectories without iterative denoising.
Significance. If the central claims hold, the work would offer a meaningful efficiency and controllability advance over diffusion-based image-to-video methods by using explicit dynamic 3D Gaussians for geometric consistency. The single-pass design and reported results on KITTI, Waymo, RealEstate10K, and DL3DV-10K could influence downstream applications requiring camera control, provided the monocular 3D lifting is shown to be robust.
major comments (2)
- [§3.2] §3.2 and Eq. (3): the construction of per-Gaussian motion parameters and covariances from monocular RGB alone is load-bearing for the temporal-consistency claim, yet the text provides no explicit mechanism or loss term that resolves scale ambiguity or occluded geometry; small depth errors at object boundaries would propagate into incorrect 3D velocities once the camera moves, directly contradicting the “no iterative denoising” guarantee.
- [Table 2] Table 2, KITTI and Waymo rows: the reported PSNR/SSIM gains are presented without error bars, statistical tests, or comparison against multi-view or depth-supervised baselines; this leaves open whether the improvements stem from the dynamic Gaussian formulation or from dataset-specific post-processing choices.
minor comments (2)
- [Abstract] Abstract: the claim of “state-of-the-art video quality” is stated without any numerical values; a single sentence summarizing the key metrics would improve readability.
- [Figure 4] Figure 4: the rendered frames under large camera rotations show visible stretching at depth discontinuities; adding an inset with the corresponding 3D Gaussian point cloud would clarify whether the artifacts originate from the motion sampling or the initial lifting.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment point by point below, providing clarifications based on the manuscript and indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [§3.2] §3.2 and Eq. (3): the construction of per-Gaussian motion parameters and covariances from monocular RGB alone is load-bearing for the temporal-consistency claim, yet the text provides no explicit mechanism or loss term that resolves scale ambiguity or occluded geometry; small depth errors at object boundaries would propagate into incorrect 3D velocities once the camera moves, directly contradicting the “no iterative denoising” guarantee.
Authors: We agree that monocular input introduces inherent scale ambiguity and challenges with occluded geometry, which must be handled carefully to support the temporal consistency claim. In the current framework, the network predicting per-Gaussian motion parameters and covariances (Eq. 3) is trained end-to-end on video datasets that provide camera pose supervision and multi-frame photometric consistency. This implicitly anchors the scale through the observed camera motion and encourages plausible 3D velocities via a combination of reconstruction losses on rendered frames and a motion regularization term. The explicit 3D Gaussian representation further helps by allowing differentiable rendering that penalizes inconsistent motion across views. However, we acknowledge that the manuscript text in §3.2 does not sufficiently detail these training mechanisms or discuss boundary error mitigation. We will revise this section to explicitly describe the loss terms, how scale is resolved via pose supervision, and the role of Gaussian splatting in handling occlusions. This revision will strengthen the explanation without altering the method. revision: yes
-
Referee: Table 2, KITTI and Waymo rows: the reported PSNR/SSIM gains are presented without error bars, statistical tests, or comparison against multi-view or depth-supervised baselines; this leaves open whether the improvements stem from the dynamic Gaussian formulation or from dataset-specific post-processing choices.
Authors: The referee is correct that Table 2 currently lacks error bars, statistical tests, and additional baseline comparisons. The reported metrics are averages over the respective test sets, and the gains are supported by the ablation studies isolating the dynamic Gaussian components. To address this, we will add standard deviations across sequences and include statistical significance tests (such as paired t-tests) in the revised Table 2. For baselines, our primary comparisons focus on monocular image-to-video methods to maintain a fair setting; multi-view or depth-supervised approaches operate under different input assumptions and are not directly comparable without additional data. We will add a clarifying paragraph in the experiments section explaining this choice and, if space allows, report results from a depth-supervised ablation in the supplementary material to further isolate the contribution of our formulation. We do not believe the gains arise from post-processing, as the method is end-to-end and the ablations control for this. revision: partial
Circularity Check
No significant circularity; derivation relies on learned monocular lifting validated externally
full rationale
The paper proposes a learned framework that predicts 3D Gaussian parameters and motion from a single RGB image in one forward pass, then renders camera-controlled video. This is a standard supervised prediction setup trained and evaluated on external datasets (KITTI, Waymo, RealEstate10K, DL3DV-10K) rather than any self-referential definition, fitted parameter renamed as prediction, or load-bearing self-citation chain. No equations appear in the abstract or description that reduce the output representation to its inputs by construction; the monocular depth and dynamics inference is an empirical modeling choice whose accuracy is tested against held-out data, not assumed tautologically. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a novel framework that constructs a 3D Gaussian scene representation and samples plausible object motion, given a single image in a single forward pass.
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Each pixel predicts parameters for N≥1 Gaussians: P={(δi,Δi,ri,si,σi,ci,vi,ai)}Ni=1
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Image-to-Video Diffusion: From Foundations to Open Frontiers
A survey that organizes diffusion image-to-video methods into a taxonomy, distills core designs in condition encoding, temporal modeling, noise prior, and upsampling, and discusses applications plus challenges.
Reference graph
Works this paper leans on
-
[1]
Ren- derdiffusion: Image diffusion for 3d reconstruction, inpaint- ing and generation
Titas Anciukevi ˇcius, Zexiang Xu, Matthew Fisher, Paul Hen- derson, Hakan Bilen, Niloy J Mitra, and Paul Guerrero. Ren- derdiffusion: Image diffusion for 3d reconstruction, inpaint- ing and generation. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 12608–12618, 2023. 2
work page 2023
-
[2]
Denoising diffusion via image-based rendering
Titas Anciukevi ˇcius, Fabian Manhardt, Federico Tombari, and Paul Henderson. Denoising diffusion via image-based rendering. InThe Twelfth International Conference on Learning Representations, 2024. 2
work page 2024
-
[3]
Sherwin Bahmani, Ivan Skorokhodov, Guocheng Qian, Ali- aksandr Siarohin, Willi Menapace, Andrea Tagliasacchi, David B. Lindell, and Sergey Tulyakov. Ac3d: Analyzing and improving 3d camera control in video diffusion trans- formers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22875–22889, 2025. 2
work page 2025
-
[4]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
A. Blattmann et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint, arXiv:2311.15127, 2023. Accessed: Oct. 08, 2024. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Depth Pro: Sharp Monocular Metric Depth in Less Than a Second
Aleksei Bochkovskii, Ama ¨el Delaunoy, Hugo Germain, Marcel Santos, Yichao Zhou, Stephan R Richter, and Vladlen Koltun. Depth pro: Sharp monocular metric depth in less than a second.arXiv preprint arXiv:2410.02073, 2024. 4
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
DINOv2: Learning Robust Visual Features without Supervision
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Di- nov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 2, 4, 8
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Are we ready for autonomous driving? the kitti vision benchmark suite
Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. InConference on Computer Vision and Pattern Recog- nition (CVPR), 2012. 7
work page 2012
-
[8]
Vision meets robotics: The kitti dataset, 2013
Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset, 2013. 2, 5
work page 2013
-
[9]
CameraCtrl: Enabling Camera Control for Text-to-Video Generation
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for text-to-video generation.arXiv preprint arXiv:2404.02101, 2024. 1, 2, 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Paul Henderson and Christoph H Lampert. Unsupervised object-centric video generation and decomposition in 3d.Ad- vances in Neural Information Processing Systems, 33:3106– 3117, 2020. 1, 2
work page 2020
-
[11]
Denoising dif- fusion implicit models
Stefano Ermon Jiaming Song, Chenlin Meng. Denoising dif- fusion implicit models. InICLR, 2021. 7
work page 2021
-
[12]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1,
-
[13]
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42 (4), 2023. 4
work page 2023
-
[14]
Zhengfei Kuang, Shengqu Cai, Hao He, Yinghao Xu, Hong- sheng Li, Leonidas J Guibas, and Gordon Wetzstein. Collab- orative video diffusion: Consistent multi-video generation 8 with camera control.Advances in Neural Information Pro- cessing Systems, 37:16240–16271, 2024. 2
work page 2024
-
[15]
Zihang Lai, Sifei Liu, Alexei A. Efros, and Xiaolong Wang. Video autoencoder: Self-supervised disentangle- ment of static 3d structure and motion. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 9730–9740, 2021. 1, 2
work page 2021
-
[16]
Realcam-i2v: Real-world image-to-video generation with interactive complex camera control
Teng Li, Guangcong Zheng, Rui Jiang, Shuigen Zhan, Tao Wu, Yehao Lu, Yining Lin, Chuanyun Deng, Yepan Xiong, Min Chen, et al. Realcam-i2v: Real-world image-to-video generation with interactive complex camera control. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 28785–28796, 2025. 1, 2, 7
work page 2025
-
[17]
Jiajing Lin, Zhenzhong Wang, Yongjie Hou, Yuzhou Tang, and Min Jiang. Phy124: Fast physics-driven 4d con- tent generation from a single image.arXiv preprint arXiv:2409.07179, 2024. 2, 3
-
[18]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vi- sion
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, Xuanmao Li, Xingpeng Sun, Rohan Ashok, Anirud- dha Mukherjee, Hao Kang, Xiangrui Kong, Gang Hua, Tianyi Zhang, Bedrich Benes, and Aniket Bera. Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vi- sion. InProceedings of the IEEE/CVF ...
work page 2024
-
[19]
Minghua Liu, Chao Xu, Haian Jin, Linghao Chen, Mukund Varma T, Zexiang Xu, and Hao Su. One-2-3-45: Any single image to 3d mesh in 45 seconds without per-shape optimiza- tion.Advances in Neural Information Processing Systems, 36:22226–22246, 2023. 2
work page 2023
-
[20]
Zero-1-to-3: Zero-shot one image to 3d object, 2023
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tok- makov, Sergey Zakharov, and Carl V ondrick. Zero-1-to-3: Zero-shot one image to 3d object, 2023. 2
work page 2023
-
[21]
Syncdreamer: Gen- erating multiview-consistent images from a single-view im- age, 2024
Yuan Liu, Cheng Lin, Zijiao Zeng, Xiaoxiao Long, Lingjie Liu, Taku Komura, and Wenping Wang. Syncdreamer: Gen- erating multiview-consistent images from a single-view im- age, 2024. 2
work page 2024
-
[22]
Wonder3d: Sin- gle image to 3d using cross-domain diffusion
Xiaoxiao Long, Yuan-Chen Guo, Cheng Lin, Yuan Liu, Zhiyang Dou, Lingjie Liu, Yuexin Ma, Song-Hai Zhang, Marc Habermann, Christian Theobalt, et al. Wonder3d: Sin- gle image to 3d using cross-domain diffusion. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9970–9980, 2024. 2
work page 2024
-
[23]
Jiageng Mao, Boyi Li, Boris Ivanovic, Yuxiao Chen, Yan Wang, Yurong You, Chaowei Xiao, Danfei Xu, Marco Pavone, and Yue Wang. Dreamdrive: Generative 4d scene modeling from street view images.arXiv preprint arXiv:2501.00601, 2024. 3
-
[24]
Waymo open dataset: Panoramic video panoptic segmentation
Jieru Mei, Alex Zihao Zhu, Xinchen Yan, Hang Yan, Siyuan Qiao, Liang-Chieh Chen, and Henrik Kretzschmar. Waymo open dataset: Panoramic video panoptic segmentation. In European Conference on Computer Vision, pages 53–72. Springer, 2022. 2, 5, 7
work page 2022
-
[25]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, et al. Grounded sam: Assembling open-world models for diverse visual tasks.arXiv preprint arXiv:2401.14159,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Gen3c: 3d-informed world-consistent video generation with precise camera con- trol
Xuanchi Ren, Tianchang Shen, Jiahui Huang, Huan Ling, Yifan Lu, Merlin Nimier-David, Thomas M ¨uller, Alexan- der Keller, Sanja Fidler, and Jun Gao. Gen3c: 3d-informed world-consistent video generation with precise camera con- trol. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 6121–6132, 2025. 1, 2
work page 2025
-
[27]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InMICCAI, 2015. 3
work page 2015
-
[28]
Make-it-4d: Synthesizing a consistent long-term dynamic scene video from a single image
Liao Shen, Xingyi Li, Huiqiang Sun, Juewen Peng, Ke Xian, Zhiguo Cao, and Guosheng Lin. Make-it-4d: Synthesizing a consistent long-term dynamic scene video from a single image. InProceedings of the 31st ACM International Con- ference on Multimedia, pages 8167–8175, 2023. 2, 3
work page 2023
-
[29]
Mvdream: Multi-view diffusion for 3d gen- eration, 2024
Yichun Shi, Peng Wang, Jianglong Ye, Mai Long, Kejie Li, and Xiao Yang. Mvdream: Multi-view diffusion for 3d gen- eration, 2024. 2
work page 2024
-
[30]
Dimensionx: Create any 3d and 4d scenes from a single image with de- coupled video diffusion
Wenqiang Sun, Shuo Chen, Fangfu Liu, Zilong Chen, Yueqi Duan, Jun Zhu, Jun Zhang, and Yikai Wang. Dimensionx: Create any 3d and 4d scenes from a single image with de- coupled video diffusion. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13695– 13706, 2025. 2, 3
work page 2025
-
[31]
Viewset diffusion:(0-) image-conditioned 3d gener- ative models from 2d data
Stanislaw Szymanowicz, Christian Rupprecht, and Andrea Vedaldi. Viewset diffusion:(0-) image-conditioned 3d gener- ative models from 2d data. InProceedings of the IEEE/CVF international conference on computer vision, pages 8863– 8873, 2023. 2
work page 2023
-
[32]
Henriques, Christian Rup- precht, and Andrea Vedaldi
Stanislaw Szymanowicz, Eldar Insafutdinov, Chuanxia Zheng, Dylan Campbell, Jo ˜ao F. Henriques, Christian Rup- precht, and Andrea Vedaldi. Flash3d: Feed-forward gener- alisable 3d scene reconstruction from a single image.arXiv preprint arXiv:2402.03807, 2024. 2
-
[33]
Splatter image: Ultra-fast single-view 3d recon- struction
Stanislaw Szymanowicz, Chrisitian Rupprecht, and Andrea Vedaldi. Splatter image: Ultra-fast single-view 3d recon- struction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10208– 10217, 2024. 2, 3, 7
work page 2024
-
[34]
Dreamgaussian: Generative gaussian splatting for ef- ficient 3d content creation, 2024
Jiaxiang Tang, Jiawei Ren, Hang Zhou, Ziwei Liu, and Gang Zeng. Dreamgaussian: Generative gaussian splatting for ef- ficient 3d content creation, 2024. 2
work page 2024
-
[35]
Consistent view synthe- sis with pose-guided diffusion models
Hung-Yu Tseng, Qinbo Li, Changil Kim, Suhib Alsisan, Jia- Bin Huang, and Johannes Kopf. Consistent view synthe- sis with pose-guided diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16773–16783, 2023. 1, 2
work page 2023
-
[36]
Motionctrl: A unified and flexible motion controller for video generation
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Yaowei Li, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. Motionctrl: A unified and flexible motion controller for video generation. InACM SIGGRAPH 2024 Conference Pa- pers, pages 1–11, 2024. 1, 2, 7
work page 2024
-
[37]
Dynamicrafter: Animating open-domain images with video diffusion priors
Jinbo Xing, Menghan Xia, Yong Zhang, Haoxin Chen, Wangbo Yu, Hanyuan Liu, Gongye Liu, Xintao Wang, Ying Shan, and Tien-Tsin Wong. Dynamicrafter: Animating open-domain images with video diffusion priors. InEu- 9 ropean Conference on Computer Vision, pages 399–417. Springer, 2024. 1, 2
work page 2024
-
[38]
CamCo: Camera-Controllable 3D-Consistent Image-to-Video Generation
Dejia Xu, Weili Nie, Chao Liu, Sifei Liu, Jan Kautz, Zhangyang Wang, and Arash Vahdat. Camco: Camera- controllable 3d-consistent image-to-video generation.arXiv preprint arXiv:2406.02509, 2024. 1
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Forecasting future videos from novel views via disentangled 3d scene representation
Sudhir Yarram and Junsong Yuan. Forecasting future videos from novel views via disentangled 3d scene representation. InEuropean Conference on Computer Vision, pages 58–76. Springer, 2024. 1, 2
work page 2024
-
[40]
Long-term photometric consistent novel view synthesis with diffusion models
Jason J Yu, Fereshteh Forghani, Konstantinos G Derpanis, and Marcus A Brubaker. Long-term photometric consistent novel view synthesis with diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 7094–7104, 2023. 2
work page 2023
-
[41]
Cami2v: Camera-controlled image-to-video dif- fusion model.arXiv preprint arXiv:2402.00000, 2024
Guangcong Zheng, Teng Li, Rui Jiang, Yehao Lu, Tao Wu, and Xi Li. Cami2v: Camera-controlled image-to-video dif- fusion model.arXiv preprint arXiv:2402.00000, 2024. 1, 2, 7
-
[42]
A unified approach for text- and image-guided 4d scene generation
Yufeng Zheng, Xueting Li, Koki Nagano, Sifei Liu, Otmar Hilliges, and Shalini De Mello. A unified approach for text- and image-guided 4d scene generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7300–7309, 2024. 2, 3
work page 2024
-
[43]
Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnification: Learning view synthesis using multiplane images.ACM Transactions on Graphics (TOG), 37(4):1–12, 2018. Proceedings of SIG- GRAPH 2018. 2, 5
work page 2018
-
[44]
Matthias Zwicker, Hanspeter Pfister, Jeroen Van Baar, and Markus Gross. Ewa volume splatting. InProceedings Visu- alization, 2001. VIS’01., pages 29–538. IEEE, 2001. 1, 2, 3 10
work page 2001
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.