Image-to-Video Diffusion: From Foundations to Open Frontiers
Pith reviewed 2026-05-20 15:01 UTC · model grok-4.3
The pith
Image-to-video diffusion reduces to four core designs identified through a dedicated taxonomy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
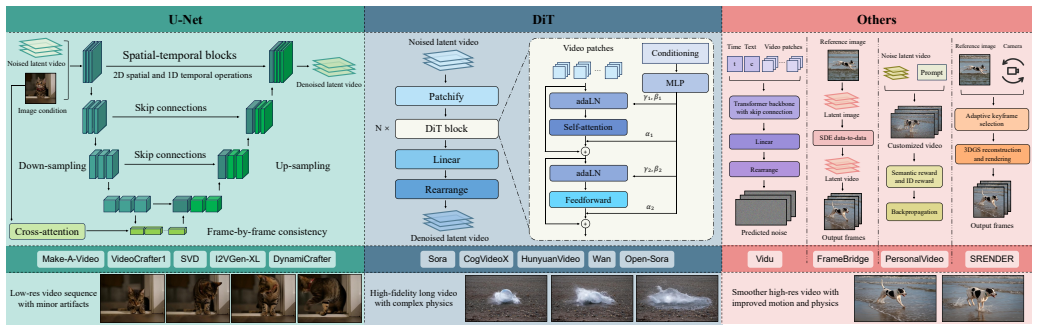
By creating a taxonomy organized by architecture and training paradigm, the work shows that image-to-video diffusion models share four key design elements—condition encoding, temporal modeling, noise prior design, and spatial-temporal upsampling—which together address the requirements for content consistency, identity preservation, and motion coherence.
What carries the argument
Taxonomy of methods based on architecture and training paradigm, which distills four core designs: condition encoding, temporal modeling, noise prior design, and spatial-temporal upsampling.
If this is right
- Future models can be designed by selecting and combining specific implementations for each of the four core designs.
- Comparisons between methods become more straightforward when evaluated against variations in condition encoding or temporal modeling.
- Datasets and metrics can be refined to better test the effectiveness of noise prior choices and upsampling strategies.
- Applications in content creation gain from targeted improvements in temporal coherence and identity preservation.
Where Pith is reading between the lines
- Similar taxonomies could be applied to text-to-video or other conditional generation tasks to find overlapping design principles.
- Empirical studies that vary one core design while holding others fixed could quantify the contribution of each to overall video quality.
- Integration with efficiency considerations might identify design choices that maintain quality at lower computational cost.
Load-bearing premise
That a focused taxonomy and analysis for image-to-video diffusion alone will yield clearer organization and insights than embedding it in wider video generation discussions.
What would settle it
Finding that most recent high-performing I2V models do not rely on the proposed four core designs or fit outside the taxonomy would indicate the classification is incomplete.
Figures





read the original abstract
Diffusion-based \textit{image-to-video} (I2V) generation has become a central direction in generative models by turning a reference image, with optional conditions, into a temporally coherent video. Compared with broader video generation settings, this task places stricter demands on content consistency, identity preservation, and motion coherence. Although the literature grows rapidly, existing works mostly discuss I2V generation within broader topics and still lack a dedicated taxonomy together with a systematic analysis centered on this field. This work addresses that gap by treating diffusion I2V generation as a standalone subject. It first reviews the task formulation, model architectures, datasets, and evaluation metrics, and then organizes existing methods through a taxonomy based on architecture and training paradigm. It further distills four core designs, namely condition encoding, temporal modeling, noise prior design, and spatial-temporal upsampling, and discusses representative application scenarios together with major open challenges.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a survey on diffusion-based image-to-video (I2V) generation, claiming to address a gap where prior works treat I2V only within broader video generation topics. It reviews task formulation, model architectures, datasets, and evaluation metrics; organizes methods via a taxonomy based on architecture and training paradigm; distills four core designs (condition encoding, temporal modeling, noise prior design, spatial-temporal upsampling); and discusses applications and open challenges.
Significance. If the taxonomy is shown to be exhaustive and the gap claim is substantiated by direct comparison to existing video diffusion surveys, the work could provide a useful organizing framework for a fast-moving subfield, highlighting design choices and challenges that are specific to the stricter consistency requirements of I2V.
major comments (2)
- [Introduction] Introduction: The assertion that 'existing works mostly discuss I2V generation within broader topics and still lack a dedicated taxonomy' is load-bearing for the central contribution; the manuscript should include an explicit comparison (e.g., a table or dedicated subsection) to recent video diffusion surveys to demonstrate that their I2V coverage is not already comparable in organization or depth.
- [Taxonomy] Taxonomy section: The taxonomy organized by architecture and training paradigm must be justified as exhaustive; without a clear accounting of how all representative methods (including those published after the survey cutoff) map onto the categories, the claim of a systematic analysis centered on I2V risks appearing selective.
minor comments (2)
- [Datasets and Evaluation Metrics] Datasets and metrics sections: Provide more detail on how the listed datasets and metrics specifically capture identity preservation and motion coherence, which the abstract identifies as stricter demands for I2V.
- [Core Designs] Four core designs: When distilling condition encoding, temporal modeling, noise prior design, and spatial-temporal upsampling, include a brief cross-reference table showing which methods exemplify each design to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our survey. These suggestions will help strengthen the justification for our contribution and the systematic nature of the taxonomy. We respond to each major comment below.
read point-by-point responses
-
Referee: [Introduction] Introduction: The assertion that 'existing works mostly discuss I2V generation within broader topics and still lack a dedicated taxonomy' is load-bearing for the central contribution; the manuscript should include an explicit comparison (e.g., a table or dedicated subsection) to recent video diffusion surveys to demonstrate that their I2V coverage is not already comparable in organization or depth.
Authors: We agree that an explicit comparison strengthens the central claim. In the revised manuscript we will add a dedicated subsection (and accompanying table) in the Introduction that directly compares our survey against recent video diffusion surveys. The table will summarize differences in scope, depth of I2V-specific analysis (condition encoding, temporal modeling, noise prior, and upsampling), and organizational structure, thereby substantiating that prior works treat I2V only peripherally and lack a dedicated taxonomy. revision: yes
-
Referee: [Taxonomy] Taxonomy section: The taxonomy organized by architecture and training paradigm must be justified as exhaustive; without a clear accounting of how all representative methods (including those published after the survey cutoff) map onto the categories, the claim of a systematic analysis centered on I2V risks appearing selective.
Authors: We acknowledge the value of demonstrating coverage. The taxonomy is organized along two axes—architecture (convolutional versus transformer-based backbones) and training paradigm (from-scratch training versus adaptation/fine-tuning)—because these axes capture the principal design decisions that differentiate I2V diffusion methods. In revision we will add an explicit justification paragraph and a mapping table that places representative methods into the categories. For works published after the survey cutoff we will insert a brief discussion noting that emerging methods continue to align with the same architectural and training paradigms; we will also state our intention to incorporate post-cutoff papers in future updates. This approach preserves the systematic character of the analysis while remaining transparent about temporal scope. revision: partial
Circularity Check
No significant circularity in external literature synthesis
full rationale
The paper is a survey synthesizing task formulations, architectures, datasets, metrics, and methods from external literature into a taxonomy organized by architecture/training paradigm and four distilled core designs. No derivations, equations, parameter fittings, or predictions appear that could reduce to the paper's own inputs by construction. The gap assertion (existing works lack a dedicated I2V-centered taxonomy) is an external claim about prior surveys, verifiable independently and not self-referential or load-bearing via self-citation chains. The work remains self-contained as an organizational review without any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Dynamic-i2v: Exploring image-to-video generation models via multimodal llm,
P. Liu, X. Ren, F. Liu, Q. Xie, Q. Zheng, Y . Zhang, H. Lu, and Y . Yang, “Dynamic-i2v: Exploring image-to-video generation models via multimodal llm,”arXiv preprint arXiv:2505.19901, 2025
-
[2]
Levitor: 3d trajectory oriented image-to-video synthesis,
H. Wang, H. Ouyang, Q. Wang, W. Wang, K. L. Cheng, Q. Chen, Y . Shen, and L. Wang, “Levitor: 3d trajectory oriented image-to-video synthesis,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 12 490–12 500
work page 2025
-
[3]
Motioncanvas: Cinematic shot design with controllable image-to-video generation,
J. Xing, L. Mai, C. Ham, J. Huang, A. Mahapatra, C.-W. Fu, T.- T. Wong, and F. Liu, “Motioncanvas: Cinematic shot design with controllable image-to-video generation,” inProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference, 2025, pp. 1–11
work page 2025
-
[4]
Versatile transi- tion generation with image-to-video diffusion,
Z. Yang, J. Zhang, Y . Yu, S. Lu, and S. Bai, “Versatile transi- tion generation with image-to-video diffusion,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 16 981–16 990
work page 2025
-
[5]
I2v3d: Controllable image-to-video generation with 3d guidance,
Z. Zhang, D. Chen, and J. Liao, “I2v3d: Controllable image-to-video generation with 3d guidance,”arXiv preprint arXiv:2503.09733, 2025
-
[6]
Realcam-i2v: Real-world image-to-video generation with interactive complex camera control,
T. Li, G. Zheng, R. Jiang, S. Zhan, T. Wu, Y . Lu, Y . Lin, C. Deng, Y . Xiong, M. Chen, L. Cheng, and X. Li, “Realcam-i2v: Real-world image-to-video generation with interactive complex camera control,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 28 785–28 796
work page 2025
-
[7]
J. Tian, X. Qu, Z. Lu, W. Wei, S. Liu, and Y . Cheng, “Extrapolating and decoupling image-to-video generation models: Motion modeling is easier than you think,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 12 512–12 521
work page 2025
-
[8]
Tagrpo: Boosting grpo on image-to-video generation with direct trajectory alignment,
J. Wang, J. Lu, G. Xu, C. Chen, H. Yang, L. Wang, P. Chen, M. Chen, Z. Hu, L. Wu, S. Shao, Q. Lu, and P. Luo, “Tagrpo: Boosting grpo on image-to-video generation with direct trajectory alignment,”arXiv preprint arXiv:2601.05729, 2026
-
[9]
Auto-Encoding Variational Bayes
D. P. Kingma and M. Welling, “Auto-encoding variational bayes,”arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[10]
I4vgen: Image as free stepping stone for text-to-video generation,
X. Guo, J. Liu, M. Cui, L. Bo, and D. Huang, “I4vgen: Image as free stepping stone for text-to-video generation,”arXiv preprint arXiv:2406.02230, 2024
-
[11]
Emu video: Factorizing text-to-video generation by explicit image conditioning,
R. Girdhar, M. Singh, A. Brown, Q. Duval, S. Azadi, S. S. Rambhatla, A. Shah, X. Yin, D. Parikh, and I. Misra, “Emu video: Factorizing text-to-video generation by explicit image conditioning,”arXiv preprint arXiv:2311.10709, 2023
-
[12]
Rv-gan: Recurrent gan for uncondi- tional video generation,
S. Gupta, A. Keshari, and S. Das, “Rv-gan: Recurrent gan for uncondi- tional video generation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 2024–2033. 13
work page 2022
-
[13]
Styleinv: A temporal style modulated inversion network for unconditional video generation,
Y . Wang, L. Jiang, and C. C. Loy, “Styleinv: A temporal style modulated inversion network for unconditional video generation,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 22 851–22 861
work page 2023
-
[14]
Realisdance: Equip controllable character animation with realistic hands,
J. Zhou, B. Wang, W. Chen, J. Bai, D. Li, A. Zhang, H. Xu, M. Yang, and F. Wang, “Realisdance: Equip controllable character animation with realistic hands,”arXiv preprint arXiv:2409.06202, 2024
-
[15]
Animate anyone: Consistent and controllable image-to-video synthesis for character animation,
L. Hu, “Animate anyone: Consistent and controllable image-to-video synthesis for character animation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 8153–8163
work page 2024
-
[16]
CamCo: Camera-Controllable 3D-Consistent Image-to-Video Generation
D. Xu, W. Nie, C. Liu, S. Liu, J. Kautz, Z. Wang, and A. Vahdat, “Camco: Camera-controllable 3d-consistent image-to-video genera- tion,”arXiv preprint arXiv:2406.02509, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
M. Niu, X. Cun, X. Wang, Y . Zhang, Y . Shan, and Y . Zheng, “Mofa-video: Controllable image animation via generative motion field adaptions in frozen image-to-video diffusion model,” inProceedings of the European Conference on Computer Vision. Springer, 2024, pp. 111–128
work page 2024
-
[18]
Champ: Controllable and consistent human image animation with 3d parametric guidance,
S. Zhu, J. L. Chen, Z. Dai, Z. Dong, Y . Xu, X. Cao, Y . Yao, H. Zhu, and S. Zhu, “Champ: Controllable and consistent human image animation with 3d parametric guidance,” inProceedings of the European Conference on Computer Vision. Springer, 2024, pp. 145– 162
work page 2024
-
[19]
Human video generation from a single image with 3d pose and view control,
T. Wang, C.-H. Yao, T. Hu, M. B. R. Reddy, M.-H. Yang, and V . Jampani, “Human video generation from a single image with 3d pose and view control,”arXiv preprint arXiv:2602.21188, 2026
-
[20]
Pia: Your per- sonalized image animator via plug-and-play modules in text-to-image models,
Y . Zhang, Z. Xing, Y . Zeng, Y . Fang, and K. Chen, “Pia: Your per- sonalized image animator via plug-and-play modules in text-to-image models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 7747–7756
work page 2024
-
[21]
Customcrafter: Customized video generation with preserving motion and concept composition abilities,
T. Wu, Y . Zhang, X. Wang, X. Zhou, G. Zheng, Z. Qi, Y . Shan, and X. Li, “Customcrafter: Customized video generation with preserving motion and concept composition abilities,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 8, 2025, pp. 8469– 8477
work page 2025
-
[22]
U-net: Convolutional net- works for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional net- works for biomedical image segmentation,” inProceedings of the Medical Image Computing and Computer-Assisted Intervention, 2015, pp. 234–241
work page 2015
-
[23]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
A. Blattmann, T. Dockhorn, S. Kulal, D. Mendelevitch, M. Kilian, D. Lorenz, Y . Levi, Z. English, V . V oleti, A. Letts, J. Varun, and R. Rombach, “Stable video diffusion: Scaling latent video diffusion models to large datasets,”arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
S. Yang, H. Li, J. Wu, M. Jing, L. Li, R. Ji, J. Liang, H. Fan, and J. Wang, “Megactor-sigma: Unlocking flexible mixed-modal control in portrait animation with diffusion transformer,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 9, 2025, pp. 9256–9264
work page 2025
-
[25]
Tora: Trajectory-oriented diffusion transformer for video generation,
Z. Zhang, J. Liao, M. Li, Z. Dai, B. Qiu, S. Zhu, L. Qin, and W. Wang, “Tora: Trajectory-oriented diffusion transformer for video generation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 2063–2073
work page 2025
-
[26]
Humandit: Pose-guided diffusion transformer for long-form human motion video generation,
Q. Gan, Y . Ren, C. Zhang, Z. Ye, P. Xie, X. Yin, Z. Yuan, B. Peng, and J. Zhu, “Humandit: Pose-guided diffusion transformer for long-form human motion video generation,”arXiv preprint arXiv:2502.04847, 2025
-
[27]
A survey on video diffusion models,
Z. Xing, Q. Feng, H. Chen, Q. Dai, H. Hu, H. Xu, Z. Wu, and Y .-G. Jiang, “A survey on video diffusion models,”ACM Computing Surveys, vol. 57, no. 2, pp. 1–42, 2024
work page 2024
-
[28]
Survey of video diffusion models: Foundations, implementations, and applications,
Y . Wang, X. Liu, W. Pang, L. Ma, S. Yuan, P. Debevec, and N. Yu, “Survey of video diffusion models: Foundations, implementations, and applications,”arXiv preprint arXiv:2504.16081, 2025
-
[29]
Con- trollable video generation: A survey.arXiv preprint arXiv:2507.16869, 2025
Y . Ma, K. Feng, Z. Hu, X. Wang, Y . Wang, M. Zheng, B. Wang, Q. Wang, X. He, H. Wang, C. Zhu, H. Liu, Y . He, Z. Wang, Z. Li, X. Li, S. Han, Y . Guo, W. Liu, D. Xu, L. Zhang, and Q. Chen, “Controllable video generation: A survey,”arXiv preprint arXiv:2507.16869, 2025
-
[30]
Diffusion model-based video editing: A survey,
W. Sun, R.-C. Tu, J. Liao, and D. Tao, “Diffusion model-based video editing: A survey,”arXiv preprint arXiv:2407.07111, 2024
-
[31]
Efficient diffusion models: A comprehen- sive survey from principles to practices,
Z. Ma, Y . Zhang, G. Jia, L. Zhao, Y . Ma, M. Ma, G. Liu, K. Zhang, N. Ding, J. Li, and B. Zhou, “Efficient diffusion models: A comprehen- sive survey from principles to practices,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[32]
Bridging text and video generation: A survey,
N. Kumar, P. Bhandari, and G. Maragatham, “Bridging text and video generation: A survey,”arXiv preprint arXiv:2510.04999, 2025
-
[33]
Human motion video generation: A survey,
H. Xue, X. Luo, Z. Hu, X. Zhang, X. Xiang, Y . Dai, J. Liu, Z. Zhang, M. Li, J. Yang, F. Ma, Z. Wu, C. Yang, Z. Dai, and F. R. Yu, “Human motion video generation: A survey,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[34]
Diffusion models: A comprehensive survey of methods and applications,
L. Yang, Z. Zhang, Y . Song, S. Hong, R. Xu, Y . Zhao, W. Zhang, B. Cui, and M.-H. Yang, “Diffusion models: A comprehensive survey of methods and applications,”ACM Computing Surveys, vol. 56, no. 4, pp. 1–39, 2023
work page 2023
-
[35]
Humanvid: demystifying training data for camera-controllable human image animation,
Z. Wang, Y . Li, Y . Zeng, Y . Fang, Y . Guo, W. Liu, J. Tan, K. Chen, T. Xue, B. Dai, and D. Lin, “Humanvid: demystifying training data for camera-controllable human image animation,” inProceedings of the Conference on Neural Information Processing Systems, 2024, pp. 20 111–20 131
work page 2024
-
[36]
Unianimate: Taming unified video diffusion models for consistent human image animation,
X. Wang, S. Zhang, C. Gao, J. Wang, X. Zhou, Y . Zhang, L. Yan, and N. Sang, “Unianimate: Taming unified video diffusion models for consistent human image animation,”Science China Information Sciences, vol. 68, no. 10, pp. 1–14, 2025
work page 2025
-
[37]
Dimensionx: Create any 3d and 4d scenes from a single image with decoupled video diffusion,
W. Sun, S. Chen, F. Liu, Z. Chen, Y . Duan, J. Zhu, J. Zhang, and Y . Wang, “Dimensionx: Create any 3d and 4d scenes from a single image with decoupled video diffusion,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 13 695–13 706
work page 2025
-
[38]
Phyrpr: Training-free physics- constrained video generation,
Y . Zhao, H. Li, X. He, and B. Wu, “Phyrpr: Training-free physics- constrained video generation,”arXiv preprint arXiv:2601.09255, 2026
-
[39]
Prompt image to life: Training- free text-driven image-to-video generation
J. Liu, Y . Yao, B. Zhu, F. Wang, W. Luo, J. Su, Y . Zhang, Y . Wang, L. Ma, Q. Liu, J. Luo, and G.-J. Qi, “Prompt image to life: Training- free text-driven image-to-video generation.”
-
[40]
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Y . Gao, H. Guo, T. Hoang, W. Huang, L. Jiang, F. Kong, H. Li, J. Li, L. Li, X. Li, X. Li, Y . Li, S. Lin, Z. Lin, J. Liu, S. Liu, X. Nie, Z. Qing, Y . Ren, L. Sun, Z. Tian, R. Wang, S. Wang, G. Wei, G. Wu, J. Wu, R. Xia, F. Xiao, X. Xiao, J. Yan, C. Yang, J. Yang, R. Yang, T. Yang, Y . Yang, Z. Ye, X. Zeng, Y . Zeng, H. Zhang, Y . Zhao, X. Zheng, P. Zhu,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
J. Chen, Y . Zhao, J. Yu, R. Chu, J. Chen, S. Yang, X. Wang, Y . Pan, D. Zhou, H. Ling, H. Liu, H. Yi, H. Zhang, M. Li, Y . Chen, H. Cai, S. Fidler, P. Luo, S. Han, and E. Xie, “Sana-video: Efficient video generation with block linear diffusion transformer,”arXiv preprint arXiv:2509.24695, 2025
-
[42]
Frame context packing and drift prevention in next-frame-prediction video diffusion models,
L. Zhang, S. Cai, M. Li, G. Wetzstein, and M. Agrawala, “Frame context packing and drift prevention in next-frame-prediction video diffusion models,” inProceedings of the Conference on Neural Infor- mation Processing Systems, 2025
work page 2025
-
[43]
Animate anyone 2: High-fidelity charac- ter image animation with environment affordance,
L. Hu, G. Wang, Z. Shen, X. Gao, D. Meng, L. Zhuo, P. Zhang, B. Zhang, and L. Bo, “Animate anyone 2: High-fidelity charac- ter image animation with environment affordance,”arXiv preprint arXiv:2502.06145, 2025
-
[44]
Make-a-video: Text-to-video generation without text-video data,
U. Singer, A. Polyak, T. Hayes, X. Yin, J. An, S. Zhang, Q. Hu, H. Yang, O. Ashual, O. Gafni, D. Parikh, S. Gupta, and Y . Taigman, “Make-a-video: Text-to-video generation without text-video data,” in Proceedings of the International Conference on Learning Representa- tions, 2023
work page 2023
-
[45]
Mvportrait: Text-guided motion and emotion control for multi-view vivid portrait animation,
Y . Lin, H. Fung, J. Xu, Z. Ren, A. S. Lau, G. Yin, and X. Li, “Mvportrait: Text-guided motion and emotion control for multi-view vivid portrait animation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 26 242–26 252
work page 2025
-
[46]
Stiv: Scalable text and image conditioned video generation,
Z. Lin, W. Liu, C. Chen, J. Lu, W. Hu, T.-J. Fu, J. Allardice, Z. Lai, L. Song, B. Zhang, C. Chen, Y . Fei, L. Li, Y . Yang, Y . Sun, and K.-W. Chang, “Stiv: Scalable text and image conditioned video generation,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 16 249–16 259
work page 2025
-
[47]
Conditional image- to-video generation with latent flow diffusion models,
H. Ni, C. Shi, K. Li, S. X. Huang, and M. R. Min, “Conditional image- to-video generation with latent flow diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition, 2023, pp. 18 444–18 455
work page 2023
-
[48]
Mardini: Masked autoregressive diffusion for video generation at scale,
H. Liu, S. Liu, Z. Zhou, M. Xu, Y . Xie, X. Han, J. C. P ´erez, D. Liu, K. Kahatapitiya, M. Jia, J.-C. Wu, S. He, T. Xiang, J. Schmidhuber, and J.-M. P ´erez-R´ua, “Mardini: Masked autoregressive diffusion for video generation at scale,”arXiv preprint arXiv:2410.20280, 2024
-
[49]
LTX-Video: Realtime Video Latent Diffusion
Y . HaCohen, N. Chiprut, B. Brazowski, D. Shalem, D. Moshe, E. Richardson, E. Levin, G. Shiran, N. Zabari, O. Gordon, P. Panet, S. Weissbuch, V . Kulikov, Y . Bitterman, Z. Melumian, and O. Bibi, “Ltx-video: Realtime video latent diffusion,”arXiv preprint arXiv:2501.00103, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
Leanvae: An ultra-efficient reconstruction vae for video diffusion models,
Y . Cheng and F. Yuan, “Leanvae: An ultra-efficient reconstruction vae for video diffusion models,”arXiv preprint arXiv:2503.14325, 2025
-
[51]
Motion-i2v: Consistent and controllable image-to-video generation with explicit 14 motion modeling,
X. Shi, Z. Huang, F.-Y . Wang, W. Bian, D. Li, Y . Zhang, M. Zhang, K. C. Cheung, S. See, H. Qin, J. Dai, and H. Li, “Motion-i2v: Consistent and controllable image-to-video generation with explicit 14 motion modeling,” inProceedings of the ACM SIGGRAPH 2024 Conference, 2024, pp. 1–11
work page 2024
-
[52]
Dynamicrafter: Animating open-domain images with video diffusion priors,
J. Xing, M. Xia, Y . Zhang, H. Chen, W. Yu, H. Liu, G. Liu, X. Wang, Y . Shan, and T.-T. Wong, “Dynamicrafter: Animating open-domain images with video diffusion priors,” inProceedings of the European Conference on Computer Vision. Springer, 2024, pp. 399–417
work page 2024
-
[53]
Reducio! generating 1k video within 16 seconds using extremely compressed motion latents,
R. Tian, Q. Dai, J. Bao, K. Qiu, Y . Yang, C. Luo, Z. Wu, and Y .- G. Jiang, “Reducio! generating 1k video within 16 seconds using extremely compressed motion latents,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 19 237– 19 247
work page 2025
-
[54]
Wan: Open and Advanced Large-Scale Video Generative Models
T. Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, J. Zeng, J. Wang, J. Zhang, J. Zhou, J. Wang, J. Chen, K. Zhu, K. Zhao, K. Yan, L. Huang, M. Feng, N. Zhang, P. Li, P. Wu, R. Chu, R. Feng, S. Zhang, S. Sun, T. Fang, T. Wang, T. Gui, T. Weng, T. Shen, W. Lin, W. Wang, W. Wang, W. Zhou, W. Wang, W. Shen, W. Yu, X. Shi, X....
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
L. Tian, Q. Wang, B. Zhang, and L. Bo, “Emo: Emote portrait alive generating expressive portrait videos with audio2video diffusion model under weak conditions,” inProceedings of the European Conference on Computer Vision. Springer, 2024, pp. 244–260
work page 2024
-
[56]
Talkingmachines: Real-time audio-driven facetime-style video via autoregressive diffusion models,
C. Low and W. Wang, “Talkingmachines: Real-time audio-driven facetime-style video via autoregressive diffusion models,”arXiv preprint arXiv:2506.03099, 2025
-
[57]
I2VGen-XL: High-Quality Image-to-Video Synthesis via Cascaded Diffusion Models
S. Zhang, J. Wang, Y . Zhang, K. Zhao, H. Yuan, Z. Qin, X. Wang, D. Zhao, and J. Zhou, “I2vgen-xl: High-quality image-to-video synthe- sis via cascaded diffusion models,”arXiv preprint arXiv:2311.04145, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[58]
Trip: Temporal residual learning with image noise prior for image-to-video diffusion models,
Z. Zhang, F. Long, Y . Pan, Z. Qiu, T. Yao, Y . Cao, and T. Mei, “Trip: Temporal residual learning with image noise prior for image-to-video diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 8671–8681
work page 2024
-
[59]
Atomovideo: High fidelity image-to-video generation,
L. Gong, Y . Zhu, W. Li, X. Kang, B. Wang, T. Ge, and B. Zheng, “Atomovideo: High fidelity image-to-video generation,”arXiv preprint arXiv:2403.01800, 2024
-
[60]
Ti2v-zero: Zero-shot image conditioning for text-to-video diffusion models,
H. Ni, B. Egger, S. Lohit, A. Cherian, Y . Wang, T. Koike-Akino, S. X. Huang, and T. K. Marks, “Ti2v-zero: Zero-shot image conditioning for text-to-video diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 9015–9025
work page 2024
-
[61]
Consisti2v: Enhancing visual consistency for image-to-video genera- tion,
W. Ren, H. Yang, G. Zhang, C. Wei, X. Du, W. Huang, and W. Chen, “Consisti2v: Enhancing visual consistency for image-to-video genera- tion,”arXiv preprint arXiv:2402.04324, 2024
-
[62]
VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
H. Chen, M. Xia, Y . He, Y . Zhang, X. Cun, S. Yang, J. Xing, Y . Liu, Q. Chen, X. Wang, C. Weng, and Y . Shan, “Videocrafter1: Open diffusion models for high-quality video generation,”arXiv preprint arXiv:2310.19512, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[63]
Videocrafter2: Overcoming data limitations for high-quality video diffusion models,
H. Chen, Y . Zhang, X. Cun, M. Xia, X. Wang, C. Weng, and Y . Shan, “Videocrafter2: Overcoming data limitations for high-quality video diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 7310–7320
work page 2024
-
[64]
Open-Sora: Democratizing Efficient Video Production for All
Z. Zheng, X. Peng, T. Yang, C. Shen, S. Li, H. Liu, Y . Zhou, T. Li, and Y . You, “Open-sora: Democratizing efficient video production for all,”arXiv preprint arXiv:2412.20404, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[65]
Open-Sora Plan: Open-Source Large Video Generation Model
B. Lin, Y . Ge, X. Cheng, Z. Li, B. Zhu, S. Wang, X. He, Y . Ye, S. Yuan, L. Chen, T. Jia, J. Zhang, Z. Tang, Y . Pang, B. She, C. Yan, Z. Hu, X. Dong, L. Chen, Z. Pan, X. Zhou, S. Dong, Y . Tian, and L. Yuan, “Open-sora plan: Open-source large video generation model,”arXiv preprint arXiv:2412.00131, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[66]
CogVideoX: Text-to-video diffusion models with an expert transformer,
Z. Yang, J. Teng, W. Zheng, M. Ding, S. Huang, J. Xu, Y . Yang, W. Hong, X. Zhang, G. Feng, D. Yin, Y . Zhang, W. Wang, Y . Cheng, B. Xu, X. Gu, Y . Dong, and J. Tang, “CogVideoX: Text-to-video diffusion models with an expert transformer,” inProceedings of the International Conference on Learning Representations, 2025
work page 2025
-
[67]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
W. Kong, Q. Tian, Z. Zhang, R. Min, Z. Dai, J. Zhou, J. Xiong, X. Li, B. Wu, J. Zhang, K. Wu, Q. Lin, J. Yuan, Y . Long, A. Wang, A. Wang, C. Li, D. Huang, F. Yang, H. Tan, H. Wang, J. Song, J. Bai, J. Wu, J. Xue, J. Wang, K. Wang, M. Liu, P. Li, S. Li, W. Wang, W. Yu, X. Deng, Y . Li, Y . Chen, Y . Cui, Y . Peng, Z. Yu, Z. He, Z. Xu, Z. Zhou, Z. Xu, Y . ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[68]
Mimicmotion: High-quality human motion video generation with confidence-aware pose guidance,
Y . Zhang, J. Gu, L.-W. Wang, H. Wang, J. Cheng, Y . Zhu, and F. Zou, “Mimicmotion: High-quality human motion video generation with confidence-aware pose guidance,” inProceedings of the International Conference on Machine Learning. PMLR, 2025, pp. 74 896–74 910
work page 2025
-
[69]
Box- imator: Generating rich and controllable motions for video synthesis,
J. Wang, Y . Zhang, J. Zou, Y . Zeng, G. Wei, L. Yuan, and H. Li, “Box- imator: Generating rich and controllable motions for video synthesis,” inProceedings of the International Conference on Machine Learning. PMLR, 2024, pp. 52 274–52 289
work page 2024
-
[70]
Lmp: Leveraging motion prior in zero-shot video generation with diffusion transformer,
C. Chen, X. Yang, J. Shu, C. Wang, and Y . Li, “Lmp: Leveraging motion prior in zero-shot video generation with diffusion transformer,” arXiv preprint arXiv:2505.14167, 2025
-
[71]
Movideo: Motion-aware video generation with diffusion model,
J. Liang, Y . Fan, K. Zhang, R. Timofte, L. Van Gool, and R. Ranjan, “Movideo: Motion-aware video generation with diffusion model,” in Proceedings of the European Conference on Computer Vision, 2024, pp. 56–74
work page 2024
-
[72]
Loopy: Taming audio-driven portrait avatar with long-term motion depen- dency,
J. Jiang, C. Liang, J. Yang, G. Lin, T. Zhong, and Y . Zheng, “Loopy: Taming audio-driven portrait avatar with long-term motion depen- dency,” inProceedings of the International Conference on Learning Representations, 2025
work page 2025
-
[73]
Hallo: Hierarchical audio-driven visual synthesis for portrait image animation,
M. Xu, H. Li, Q. Su, H. Shang, L. Zhang, C. Liu, J. Wang, Y . Yao, and S. Zhu, “Hallo: Hierarchical audio-driven visual synthesis for portrait image animation,”arXiv preprint arXiv:2406.08801, 2024
-
[74]
Hallo2: Long-duration and high-resolution audio-driven portrait image animation,
J. Cui, H. Li, Y . Yao, H. Zhu, H. Shang, K. Cheng, H. Zhou, S. Zhu, and J. Wang, “Hallo2: Long-duration and high-resolution audio-driven portrait image animation,”arXiv preprint arXiv:2410.07718, 2024
-
[75]
Sonic: Shifting focus to global audio perception in portrait animation,
X. Ji, X. Hu, Z. Xu, J. Zhu, C. Lin, Q. He, J. Zhang, D. Luo, Y . Chen, Q. Lin, Q. Lu, and C. Wang, “Sonic: Shifting focus to global audio perception in portrait animation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025, pp. 193–203
work page 2025
-
[76]
Echomimic: Lifelike audio-driven portrait animations through editable landmark conditions,
Z. Chen, J. Cao, Z. Chen, Y . Li, and C. Ma, “Echomimic: Lifelike audio-driven portrait animations through editable landmark conditions,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 3, 2025, pp. 2403–2410
work page 2025
-
[77]
Aniportrait: Audio-driven synthesis of photorealistic portrait animation,
H. Wei, Z. Yang, and Z. Wang, “Aniportrait: Audio-driven synthesis of photorealistic portrait animation,”arXiv preprint arXiv:2403.17694, 2024
-
[78]
Stableavatar: Infinite-length audio-driven avatar video generation,
S. Tu, Y . Pan, Y . Huang, X. Han, Z. Xing, Q. Dai, C. Luo, Z. Wu, and Y .-G. Jiang, “Stableavatar: Infinite-length audio-driven avatar video generation,”arXiv preprint arXiv:2508.08248, 2025
-
[79]
Omniavatar: Efficient audio-driven avatar video generation with adaptive body animation,
Q. Gan, R. Yang, J. Zhu, S. Xue, and S. Hoi, “Omniavatar: Efficient audio-driven avatar video generation with adaptive body animation,” arXiv preprint arXiv:2506.18866, 2025
-
[80]
Cyberhost: A one-stage diffusion framework for audio-driven talking body generation,
G. Lin, J. Jiang, C. Liang, T. Zhong, J. Yang, Z. Zheng, and Y . Zheng, “Cyberhost: A one-stage diffusion framework for audio-driven talking body generation,” inProceedings of the International Conference on Learning Representations, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.