Vision-as-Inverse-Graphics Agent via Interleaved Multimodal Reasoning
Pith reviewed 2026-05-16 13:46 UTC · model grok-4.3
The pith
VIGA agent reconstructs images into editable programs using interleaved code and visual reasoning
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
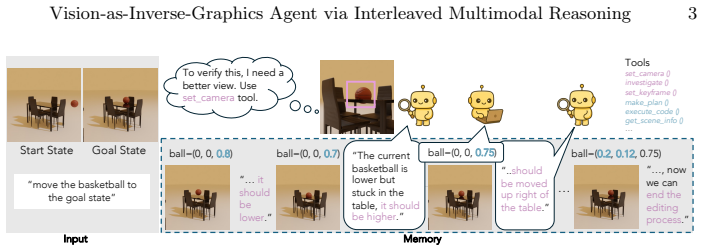
VIGA operates through a tightly coupled code-render-inspect loop where symbolic logic and visual perception actively cross-verify each other, allowing the synthesis of programs that are rendered to images, inspected for discrepancies, and iteratively edited using an evolving multimodal memory to sustain long-horizon modifications without task-specific training.
What carries the argument
The code-render-inspect loop, in which symbolic programs are generated, rendered into visual states, and discrepancies are inspected to drive iterative edits while maintaining consistency via multimodal memory.
If this is right
- Delivers accuracy improvements of 35.32 percent on BlenderGym, 117.17 percent on SlideBench, and 124.70 percent on the new BlenderBench over one-shot baselines.
- Seamlessly handles 2D document generation, 3D reconstruction, multi-step 3D editing, and 4D physical interaction in one task-agnostic framework.
- Remains training-free, relying on the loop and memory rather than fine-tuning for broad applicability.
- The cross-verification between symbolic code and rendered visuals reduces reliance on perfect one-shot spatial understanding.
Where Pith is reading between the lines
- The same loop structure could be tested on inferring editable parameters from real-world video rather than synthetic renders.
- If memory prevents drift, similar interleaved verification might apply to other agent tasks requiring precise spatial output like robot motion planning.
- The gains on BlenderBench suggest the method scales to harder visual-to-code problems where single-pass generation fails.
Load-bearing premise
The vision-language model can sustain evidence-based iterative edits over long horizons without error accumulation or drift in the code-render-inspect loop.
What would settle it
Observing clear performance degradation or increasing visual discrepancies after many iterations on long-horizon tasks within BlenderBench would show that sustained accuracy does not hold.
Figures







read the original abstract
Vision-as-inverse-graphics, the concept of reconstructing images into editable programs, remains challenging for Vision-Language Models (VLMs), which inherently lack fine-grained spatial grounding in one-shot settings. To address this, we introduce VIGA (Vision-as-Inverse-Graphics Agent), an interleaved multimodal reasoning framework where symbolic logic and visual perception actively cross-verify each other. VIGA operates through a tightly coupled code-render-inspect loop: synthesizing symbolic programs, projecting them into visual states, and inspecting discrepancies to guide iterative edits. Equipped with high-level semantic skills and an evolving multimodal memory, VIGA sustains evidence-based modifications over long horizons. This training-free, task-agnostic framework seamlessly supports 2D document generation, 3D reconstruction, multi-step 3D editing, and 4D physical interaction. Finally, we introduce BlenderBench, a challenging visual-to-code benchmark. Empirically, VIGA substantially improves accuracy compared with one-shot baselines in BlenderGym (35.32%), SlideBench (117.17%) and our proposed BlenderBench (124.70%).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VIGA, a training-free, task-agnostic interleaved multimodal reasoning agent for vision-as-inverse-graphics tasks. It operates via a tightly coupled code-render-inspect loop that synthesizes symbolic programs, renders them visually, and uses discrepancies to guide iterative edits, supported by semantic skills and multimodal memory. The framework is applied to 2D document generation, 3D reconstruction, multi-step 3D editing, and 4D physical interaction, and the authors introduce BlenderBench as a new benchmark. Empirically, VIGA is claimed to deliver relative accuracy gains of 35.32% on BlenderGym, 117.17% on SlideBench, and 124.70% on BlenderBench over one-shot baselines.
Significance. If the central loop stability claim holds and the reported gains are reproducible with proper controls, the work would offer a concrete demonstration of how symbolic-visual cross-verification can enable long-horizon, training-free performance on inverse-graphics problems that one-shot VLMs struggle with. The introduction of BlenderBench and the explicit emphasis on evidence-based iterative editing would also provide a useful testbed for future agent research.
major comments (2)
- [Abstract] Abstract: the headline accuracy improvements (35.32% BlenderGym, 117.17% SlideBench, 124.70% BlenderBench) are stated without any accompanying information on the number of trials, error bars, statistical significance, or how discrepancies are quantified and fed back into the loop; these omissions make the central empirical claim impossible to evaluate.
- [Abstract] Abstract and framework description: no ablation or diagnostic results are supplied on iteration depth, per-step error rates, or drift metrics in the code-render-inspect loop, even though the paper's training-free advantage and long-horizon performance rest entirely on the assumption that the VLM can sustain evidence-based edits without compounding hallucinations.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments on the empirical presentation. We have revised the manuscript to provide the requested details on trial counts, statistical reporting, and loop diagnostics while preserving the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline accuracy improvements (35.32% BlenderGym, 117.17% SlideBench, 124.70% BlenderBench) are stated without any accompanying information on the number of trials, error bars, statistical significance, or how discrepancies are quantified and fed back into the loop; these omissions make the central empirical claim impossible to evaluate.
Authors: We agree the abstract requires additional context. The revised abstract now states that gains are averaged over 100 trials per benchmark with standard deviations reported in the main results (Section 4). Discrepancies are quantified via a combination of LPIPS perceptual distance and symbolic AST diff, verbalized into natural-language feedback that drives the next edit; this mechanism is detailed in Section 3.2. Paired t-test p-values (<0.01) confirming significance are added to the supplementary material. revision: yes
-
Referee: [Abstract] Abstract and framework description: no ablation or diagnostic results are supplied on iteration depth, per-step error rates, or drift metrics in the code-render-inspect loop, even though the paper's training-free advantage and long-horizon performance rest entirely on the assumption that the VLM can sustain evidence-based edits without compounding hallucinations.
Authors: We accept that the original submission lacked explicit diagnostics. The revised manuscript adds Section 4.5 with an ablation on iteration depth (Table 4 shows diminishing returns beyond 4 iterations), per-step error-rate curves (Figure 8), and a drift metric defined as the fraction of edits that increase reconstruction error (held below 7% by the multimodal memory). These results support loop stability over the reported horizons. revision: yes
Circularity Check
No circularity; VIGA framework is an independent empirical contribution
full rationale
The paper introduces VIGA as a training-free interleaved multimodal reasoning agent built around a code-render-inspect loop that cross-verifies symbolic programs and visual states. No mathematical derivations, fitted parameters, or self-citations are used to justify the core mechanism or the reported accuracy gains. The improvements (35–124% relative to one-shot baselines) are presented as direct empirical measurements on BlenderGym, SlideBench, and the new BlenderBench rather than predictions forced by construction from the inputs. The central claim rests on the stability of the iterative loop itself, which is described as a novel process without reduction to prior fitted quantities or renamed known results.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption VLMs can generate symbolic programs that, when rendered, produce visual states comparable to input images
- domain assumption Discrepancies between rendered and target images can be reliably translated into program edits
invented entities (1)
-
VIGA agent
no independent evidence
Forward citations
Cited by 4 Pith papers
-
SceneOrchestra: Efficient Agentic 3D Scene Synthesis via Full Tool-Call Trajectory Generation
SceneOrchestra trains an orchestrator to generate full tool-call trajectories for 3D scene synthesis and uses a discriminator during training to select high-quality plans, yielding state-of-the-art results with lower runtime.
-
Text-Guided 6D Object Pose Rearrangement via Closed-Loop VLM Agents
Closed-loop VLM agents using multi-view reasoning, object-centered visualization, and single-axis rotation prediction achieve superior text-guided 6D pose rearrangement for target objects in scenes.
-
Code-as-Room: Generating 3D Rooms from Top-Down View Images via Agentic Code Synthesis
Code-as-Room is an MLLM-based agentic pipeline that parses top-down images into multi-stage Blender code synthesis with cross-stage memory to generate functional 3D rooms.
-
LychSim: A Controllable and Interactive Simulation Framework for Vision Research
LychSim introduces a controllable simulation platform on Unreal Engine 5 with Python API, procedural generation, and LLM integration for vision research tasks.
Reference graph
Works this paper leans on
- [1]
-
[2]
Retrieved from https://deepmind.google/models/gemini/pro/ 22
AI, G.D..G.: Gemini 2.5 pro: A reasoning-optimized multimodal model (2025), model page. Retrieved from https://deepmind.google/models/gemini/pro/ 22
work page 2025
-
[3]
Anthropic: Claude sonnet 4 (model id: claude-sonnet-4@20250514) (2025), model card. Retrieved from https://docs.cloud.google.com/vertex- ai/generative-ai/docs/partner-models/claude/sonnet-4 22
work page 2025
-
[4]
Anthropic: The complete guide to building skills for claude. Tech. rep., Anthropic (jan 2026), https://resources.anthropic.com/hubfs/The- Complete-Guide-to-Building-Skill-for-Claude.pdf , accessed: 2026- 03-05 9
work page 2026
- [5]
-
[6]
In: Mahamood, S., Minh, N.L., Ippolito, D
Bandyopadhyay, S., Maheshwari, H., Natarajan, A., Saxena, A.: Enhancing presentation slide generation by LLMs with a multi-staged end-to-end ap- proach. In: Mahamood, S., Minh, N.L., Ippolito, D. (eds.) Proceedings of the 17th International Natural Language Generation Conference. pp. 222–
-
[7]
https://doi.org/10.18653/v1/2024.inlg-main.184
Association for Computational Linguistics, Tokyo, Japan (Sep 2024). https://doi.org/10.18653/v1/2024.inlg-main.184
-
[8]
Blanz, V., Vetter, T.: A morphable model for the synthesis of 3d faces. Seminal Graphics Papers: Pushing the Boundaries, Volume 2 (1999),https: //api.semanticscholar.org/CorpusID:2037052112
work page 1999
-
[9]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Chen, B., Xu, Z., Kirmani, S., Ichter, B., Sadigh, D., Guibas, L., Xia, F.: Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 14455–14465 (June 2024) 4
work page 2024
-
[10]
Cheng, A.C., Yin, H., Fu, Y., Guo, Q., Yang, R., Kautz, J., Wang, X., Liu, S.: Spatialrgpt: Grounded spatial reasoning in vision-language models. In: NeurIPS (2024) 4
work page 2024
-
[11]
In: NeurIPS (2022), outstanding Paper Award 4
Deitke, M., VanderBilt, E., Herrasti, A., Weihs, L., Salvador, J., Ehsani, K., Han, W., Kolve, E., Farhadi, A., Kembhavi, A., Mottaghi, R.: ProcTHOR: Large-Scale Embodied AI Using Procedural Generation. In: NeurIPS (2022), outstanding Paper Award 4
work page 2022
-
[12]
In: Proceedings of the British Machine Vision Conference (BMVC)
Dwedari, M.M., Niessner, M., Chen, Z.: Generating context-aware natural answers for questions in 3d scenes. In: Proceedings of the British Machine Vision Conference (BMVC). BMVA Press (2023) 4 16 Shaofeng Yin et al
work page 2023
-
[13]
In: Proceedings of the 37th International Conference on Neural Information Processing Systems
Feng, W., Zhu, W., Fu, T.j., Jampani, V., Akula, A., He, X., Basu, S., Wang, X.E., Wang, W.Y.: Layoutgpt: compositional visual planning and genera- tion with large language models. In: Proceedings of the 37th International Conference on Neural Information Processing Systems. NIPS ’23 (2023) 4
work page 2023
-
[14]
ACM Transactions on Graphics (ToG), Proc
Feng, Y., Feng, H., Black, M.J., Bolkart, T.: Learning an animatable detailed 3D face model from in-the-wild images. ACM Transactions on Graphics (ToG), Proc. SIGGRAPH40(4), 88:1–88:13 (Aug 2021) 2
work page 2021
-
[15]
In: European Conference on Computer Vision
Ge, J., Subramanian, S., Shi, B., Herzig, R., Darrell, T.: Recursive visual programming. In: European Conference on Computer Vision. pp. 1–18. Springer (2024) 4
work page 2024
-
[16]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Ge, J., Wang, Z.Z., Zhou, X., Peng, Y.H., Subramanian, S., Tan, Q., Sap, M., Suhr, A., Fried, D., Neubig, G., et al.: Autopresent: Designing structured visuals from scratch. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 2902–2911 (2025) 4, 14, 21, 24
work page 2025
-
[17]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Gu, Y., Huang, I., Je, J., Yang, G., Guibas, L.: Blendergym: Benchmarking foundational model systems for graphics editing. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 18574–18583 (2025) 4, 5, 11, 12, 14, 21
work page 2025
-
[18]
Gulwani, S., Polozov, O., Singh, R.: Program synthesis. Found. Trends Pro- gram. Lang.4(1–2), 1–119 (2017).https://doi.org/10.1561/2500000010 4
-
[19]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Gupta, T., Kembhavi, A.: Visual programming: Compositional visual rea- soning without training. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 14953–14962 (2023) 4
work page 2023
-
[20]
He, J., Treude, C., Lo, D.: Llm-based multi-agent systems for software engineering: Literature review, vision, and the road ahead. ACMTrans.Softw. Eng. Methodol.34(5) (May 2025). https://doi.org/10.1145/3712003 4
-
[21]
Hong, K., Troynikov, A., Huber, J.: Context rot: How increasing input tokens impacts llm performance. Tech. rep., Chroma (July 2025),https: //research.trychroma.com/context-rot8
work page 2025
-
[22]
In: Advances in Neural Information Processing Systems (NeurIPS)
Hong, Y., Zhen, H., Chen, P., Zheng, S., Du, Y., Chen, Z., Gan, C.: 3dllm: Injecting the 3d world into large language models. In: Advances in Neural Information Processing Systems (NeurIPS). vol. 36, pp. 20482–20494. Curran Associates, Inc. (2023) 4
work page 2023
-
[23]
Hu, Y., Stretcu, O., Lu, C.T., Viswanathan, K., Hata, K., Luo, E., Kr- ishna, R., Fuxman, A.: Visual program distillation: Distilling tools and programmatic reasoning into vision-language models (2023) 4
work page 2023
-
[24]
In: Forty-first International Conference on Machine Learning (2024) 4
Hu, Z., Iscen, A., Jain, A., Kipf, T., Yue, Y., Ross, D.A., Schmid, C., Fathi, A.: Scenecraft: An llm agent for synthesizing 3d scenes as blender code. In: Forty-first International Conference on Machine Learning (2024) 4
work page 2024
-
[25]
In: European Conference on Computer Vision
Huang, I., Yang, G., Guibas, L.: Blenderalchemy: Editing 3d graphics with vision-language models. In: European Conference on Computer Vision. pp. 297–314. Springer (2024) 12, 14, 21
work page 2024
-
[26]
In: ACM SIGGRAPH Asia 2023 Conference Papers
Kodnongbua, M., Jones, B., Ahmad, M.B.S., Kim, V., Schulz, A.: Reparam- cad: Zero-shot cad re-parameterization for interactive manipulation. In: ACM SIGGRAPH Asia 2023 Conference Papers. ACM, New York, NY, USA (2023).https://doi.org/10.1145/3610548.36182194 Vision-as-Inverse-Graphics Agent via Interleaved Multimodal Reasoning 17
-
[27]
Koh, J.Y., Lo, R., Jang, L., Duvvur, V., Lim, M.C., Huang, P.Y., Neubig, G., Zhou, S., Salakhutdinov, R., Fried, D.: Visualwebarena: Evaluating multimodal agents on realistic visual web tasks. In: ICLR 2024 Workshop on Large Language Model (LLM) Agents (2024),https://openreview.net/ forum?id=RPKxrKTJbj4
work page 2024
-
[28]
Transactions on Machine Learning Research (2024) 5
Kulits,P.,Feng,H.,Liu,W.,Abrevaya,V.F.,Black,M.J.:Re-thinkinginverse graphics with large language models. Transactions on Machine Learning Research (2024) 5
work page 2024
-
[29]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Kulkarni, T.D., Kohli, P., Tenenbaum, J.B., Mansinghka, V.: Picture: A probabilistic programming language for scene perception. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE Computer Society (June 2015) 4
work page 2015
-
[30]
Scenethesis: A language and vision agentic framework for 3d scene generation,
Ling, L., Lin, C.H., Lin, T.Y., Ding, Y., Zeng, Y., Sheng, Y., Ge, Y., Liu, M.Y., Bera, A., Li, Z.: Scenethesis: A language and vision agentic framework for 3d scene generation. arXiv preprint arXiv:2505.02836 (2025) 4, 5, 24
-
[31]
Liu, N.F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., Liang, P.: Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics12, 157–173 (2024).https://doi.org/10.1162/tacl_a_006388
-
[32]
2019 IEEE/CVF International Con- ference on Computer Vision (ICCV) pp
Liu, S., Li, T., Chen, W., Li, H.: Soft rasterizer: A differentiable ren- derer for image-based 3d reasoning. 2019 IEEE/CVF International Con- ference on Computer Vision (ICCV) pp. 7707–7716 (2019),https://api. semanticscholar.org/CorpusID:1024840002
work page 2019
-
[33]
In: European Conference on Computer Vision (2014), https : / / api
Loper, M., Black, M.J.: Opendr: An approximate differentiable renderer. In: European Conference on Computer Vision (2014), https : / / api . semanticscholar.org/CorpusID:178680982
work page 2014
-
[34]
Meshy: Meshy: Fast 3d generative ai.https://www.meshy.ai/(2024) 14
work page 2024
-
[35]
Öcal, B.M., Tatarchenko, M., Karaoğlu, S., Gevers, T.: Sceneteller: Language- to-3d scene generation. In: Computer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, Part LXXXV. pp. 362–378 (2024).https://doi.org/10.1007/978- 3- 031- 73013-9_214
-
[36]
Retrieved from https://cdn.openai.com/gpt-4o-system-card.pdf 22
OpenAI: Gpt-4o (“omni”): An autoregressive omni model for text, vision, audio and video (2024), system Card. Retrieved from https://cdn.openai.com/gpt-4o-system-card.pdf 22
work page 2024
-
[37]
OpenAI: Gpt-5 (Aug 2025), https://openai.com/index/introducing- gpt-5/, released August 7, 2025 22
work page 2025
-
[38]
2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Qin, Y., Xu, Z., Liu, Y.: Apply hierarchical-chain-of-generation to complex attributes text-to-3d generation. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 18521–18530 (2025),https: //api.semanticscholar.org/CorpusID:2784813494
work page 2025
-
[39]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Qin, Y., Ye, Y., Fang, J., Wang, H., Liang, S., Tian, S., Zhang, J., Li, J., Li, Y., Huang, S., et al.: Ui-tars: Pioneering automated gui interaction with native agents. arXiv preprint arXiv:2501.12326 (2025) 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
J.: Infinite photorealistic worlds using procedural generation
Raistrick, A., Lipson, L., Ma, Z., Mei, L., Wang, M., Zuo, Y., Kayan, K., Wen, H., Han, B., Wang, Y., Newell, A., Law, H., Goyal, A., Yang, K., Deng, 18 Shaofeng Yin et al. J.: Infinite photorealistic worlds using procedural generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12630–12641 (2023) 4
work page 2023
-
[41]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Raistrick, A., Mei, L., Kayan, K., Yan, D., Zuo, Y., Han, B., Wen, H., Parakh, M., Alexandropoulos, S., Lipson, L., Ma, Z., Deng, J.: Infinigen indoors: Photorealistic indoor scenes using procedural generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 21783–21794 (June 2024) 4
work page 2024
-
[42]
Ritchie, D., Guerrero, P., Jones, R.K., Mitra, N.J., Schulz, A., Willis, K.D.D., Wu, J.: Neurosymbolic models for computer graphics. Computer Graphics Forum42(2), 545–568 (2023),https://onlinelibrary.wiley.com/doi/ abs/10.1111/cgf.147754
-
[43]
Roberts, L.G.: Machine Perception of Three-Dimensional Solids. Ph.D. thesis, Massachusetts Institute of Technology, Cambridge, Massachusetts, USA (1963) 2, 4
work page 1963
-
[44]
arXiv preprint arXiv:2306.05392 (2023) 4
Subramanian, S., Narasimhan, M., Khangaonkar, K., Yang, K., Nagrani, A., Schmid, C., Zeng, A., Darrell, T., Klein, D.: Modular visual question answering via code generation. arXiv preprint arXiv:2306.05392 (2023) 4
-
[45]
In: 2025 International Conference on 3D Vision (3DV)
Sun, C., Han, J., Deng, W., Wang, X., Qin, Z., Gould, S.: 3d-gpt: Procedural 3d modeling with large language models. In: 2025 International Conference on 3D Vision (3DV). pp. 1253–1263. IEEE (2025) 4, 5
work page 2025
-
[46]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Sun, F.Y., Liu, W., Gu, S., Lim, D., Bhat, G., Tombari, F., Li, M., Haber, N., Wu, J.: Layoutvlm: Differentiable optimization of 3d layout via vision- language models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 29469–29478 (2025)
work page 2025
-
[47]
Sun, F.Y., Wu, S., Jacobsen, C., Yim, T., Zou, H., Zook, A., Li, S., Chou, Y.H.,Can,E.,Wu,X.,Eppner,C.,Blukis,V.,Tremblay,J.,Wu,J.,Birchfield, S., Haber, N.: 3d-generalist: Self-improving vision-language-action models for crafting 3d worlds (2025),https://arxiv.org/abs/2507.06484 2, 4, 24
-
[48]
In: Proceedings of the IEEE/CVF international conference on computer vision
Surís, D., Menon, S., Vondrick, C.: Vipergpt: Visual inference via python execution for reasoning. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 11888–11898 (2023) 4
work page 2023
-
[49]
Dy- namic cheatsheet: Test-time learning with adaptive memory, 2025.URL https://arxiv
Suzgun, M., Yuksekgonul, M., Bianchi, F., Jurafsky, D., Zou, J.: Dy- namic cheatsheet: Test-time learning with adaptive memory. arXiv preprint arXiv:2504.07952 (2025) 4
- [50]
-
[51]
arXiv preprint arXiv:2510.03463 , year=
Tawosi, V., Ramani, K., Alamir, S., Liu, X.: Almas: an autonomous llm- based multi-agent software engineering framework (2025),https://arxiv. org/abs/2510.034634
-
[52]
SAM 3D: 3Dfy Anything in Images
Team, S.D., Chen, X., Chu, F.J., Gleize, P., Liang, K.J., Sax, A., Tang, H., Wang, W., Guo, M., Hardin, T., Li, X., Lin, A., Liu, J., Ma, Z., Sagar, A., Song, B., Wang, X., Yang, J., Zhang, B., Dollár, P., Gkioxari, G., Feiszli, M., Vision-as-Inverse-Graphics Agent via Interleaved Multimodal Reasoning 19 Malik, J.: Sam 3d: 3dfy anything in images. arXiv p...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Tripo AI: Tripo: Ai 3d model generator.https://www.tripo3d.ai/ (2024) 14
work page 2024
-
[54]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Wang, F., Zhao, Z., Liu, Y., Zhang, D., Gao, J., Sun, H., Li, X.: Svgen: Interpretable vector graphics generation with large language models. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 9608–9617. MM ’25, Association for Computing Machinery, New York, NY, USA (2025).https://doi.org/10.1145/3746027.37550114
-
[55]
In: Proceedings of the 38th International Conference on Neural Information Processing Systems
Wang, J., Ming, Y., Shi, Z., Vineet, V., Wang, X., Li, Y., Joshi, N.: Is a picture worth a thousand words? delving into spatial reasoning for vision language models. In: Proceedings of the 38th International Conference on Neural Information Processing Systems. NIPS ’24 (2024) 4
work page 2024
-
[56]
Wang, Z.Z., Mao, J., Fried, D., Neubig, G.: Agent workflow memory. In: Forty-second International Conference on Machine Learning (2025),https: //openreview.net/forum?id=NTAhi2JEEE4
work page 2025
-
[57]
In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017) 2, 5
Wu, J., Tenenbaum, J.B., Kohli, P.: Neural scene de-rendering. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2017) 2, 5
work page 2017
-
[58]
2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp
Wu, R., Su, W., Liao, J.: Chat2svg: Vector graphics generation with large language models and image diffusion models. 2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) pp. 23690–23700 (2024),https://api.semanticscholar.org/CorpusID:2742805544
work page 2025
-
[59]
Xie, T., Zhang, D., Chen, J., Li, X., Zhao, S., Cao, R., Hua, T.J., Cheng, Z., Shin, D., Lei, F., Liu, Y., Xu, Y., Zhou, S., Savarese, S., Xiong, C., Zhong, V., Yu, T.: OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments. In: The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks...
work page 2024
-
[60]
Empowering llms to understand and generate complex vector graphics
Xing, X., Hu, J., Liang, G., Zhang, J., Xu, D., Yu, Q.: Empowering llms to understand and generate complex vector graphics. arXiv preprint arXiv:2412.11102 (2024) 4
-
[61]
In: Advances in Neural Information Processing Systems (2025) 4
Xu, W., Liang, Z., Mei, K., Gao, H., Tan, J., Zhang, Y.: A-mem: Agentic memory for llm agents. In: Advances in Neural Information Processing Systems (2025) 4
work page 2025
-
[62]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Xue, L., Gao, M., Xing, C., Martín-Martín, R., Wu, J., Xiong, C., Xu, R., Niebles, J.C., Savarese, S.: Ulip: Learning a unified representation of language, images, and point clouds for 3d understanding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 1179–1189. IEEE Computer Society (2023) 4
work page 2023
-
[63]
Advances in Neural Information Processing Systems37, 50528– 50652 (2024) 4 20 Shaofeng Yin et al
Yang, J., Jimenez, C.E., Wettig, A., Lieret, K., Yao, S., Narasimhan, K., Press, O.: Swe-agent: Agent-computer interfaces enable automated software engineering. Advances in Neural Information Processing Systems37, 50528– 50652 (2024) 4 20 Shaofeng Yin et al
work page 2024
-
[64]
Omnisvg: A unified scalable vector graphics generation model.arXiv preprint arXiv:2504.06263, 2025
Yang, Y., Cheng, W., Chen, S., Zeng, X., Zhang, J., Wang, L., Yu, G., Ma, X., Jiang, Y.G.: Omnisvg: A unified scalable vector graphics generation model. arXiv preprint arXiv:2504.06263 (2025) 4
-
[65]
Advances in Neural Information Processing Systems35, 20744–20757 (2022) 4
Yao, S., Chen, H., Yang, J., Narasimhan, K.: Webshop: Towards scalable real-world web interaction with grounded language agents. Advances in Neural Information Processing Systems35, 20744–20757 (2022) 4
work page 2022
- [66]
-
[67]
In: Advances in Neural Information Processing Systems (NeurIPS) 31
Yi, K., Wu, J., Gan, C., Torralba, A., Kohli, P., Tenenbaum, J.: Neural- symbolic vqa: Disentangling reasoning from vision and language understand- ing. In: Advances in Neural Information Processing Systems (NeurIPS) 31. pp. 1039–1050 (2018) 2
work page 2018
-
[68]
arXiv preprint arXiv:2307.02485 , year=
Zhang, H., Du, W., Shan, J., Zhou, Q., Du, Y., Tenenbaum, J.B., Shu, T., Gan, C.: Building cooperative embodied agents modularly with large language models. arXiv preprint arXiv:2307.02485 (2023) 4
-
[69]
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Zhang, Q., Hu, C., Upasani, S., Ma, B., Hong, F., Kamanuru, V., Rainton, J., Wu, C., Ji, M., Li, H., et al.: Agentic context engineering: Evolving contexts for self-improving language models. arXiv preprint arXiv:2510.04618 (2025) 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
Zheng, H., Guan, X., Kong, H., Zheng, J., Zhou, W., Lin, H., Lu, Y., He, B., Han, X., Sun, L.: Pptagent: Generating and evaluating presentations beyond text-to-slides. arXiv preprint arXiv:2501.03936 (2025) 4
-
[71]
Zhou, M., Wang, Y., Hou, J., Zhang, S., Li, Y., Luo, C., Peng, J., Zhang, Z.: Scenex: procedural controllable large-scale scene generation. In: Proceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty- Seventh Conference on Innovative Applications of Artificial Intelligence and Fifteenth Symposium on Educational Advances in Ar...
work page 2025
-
[72]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Zhou, S., Xu, F.F., Zhu, H., Zhou, X., Lo, R., Sridhar, A., Cheng, X., Ou, T., Bisk, Y., Fried, D., et al.: Webarena: A realistic web environment for building autonomous agents. arXiv preprint arXiv:2307.13854 (2023) 4 Vision-as-Inverse-Graphics Agent via Interleaved Multimodal Reasoning Supplementary Material A Evaluation Settings A.1 Quantitative Settin...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.