Recognition: 1 theorem link
· Lean TheoremOmniOVCD: Streamlining Open-Vocabulary Change Detection with SAM 3
Pith reviewed 2026-05-16 12:48 UTC · model grok-4.3
The pith
A single SAM 3 model with fusion-decoupling strategy delivers state-of-the-art open-vocabulary change detection on remote sensing imagery.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
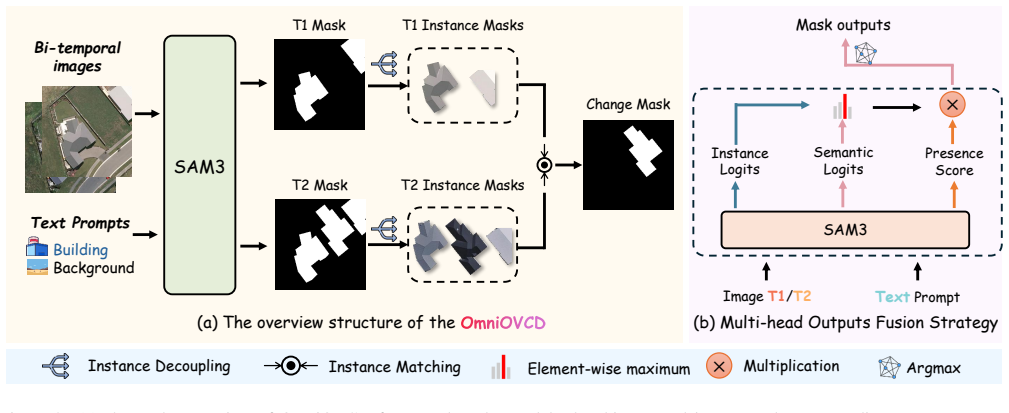
By leveraging the decoupled output heads of SAM 3, the Synergistic Fusion to Instance Decoupling (SFID) strategy first fuses semantic, instance, and presence outputs to construct land-cover masks and then decomposes them into individual instance masks for change comparison. This design preserves high accuracy in category recognition and maintains instance-level consistency across images, enabling accurate change masks for arbitrary land-cover categories.
What carries the argument
The Synergistic Fusion to Instance Decoupling (SFID) strategy, which integrates SAM 3's semantic, instance, and presence outputs to build and then separate land-cover masks for consistent cross-image change comparison.
If this is right
- Change masks can be produced for land-cover categories never seen in training.
- Instance-level consistency holds across image pairs without separate alignment modules.
- IoU performance exceeds every prior method on the four evaluated benchmarks.
- Category recognition stays accurate while instance masks are extracted for change comparison.
Where Pith is reading between the lines
- A single-model pipeline could simplify other remote-sensing tasks that currently chain multiple feature extractors.
- Applying the same fusion-decoupling steps to additional change-detection datasets would test whether the consistency gains hold outside the four reported benchmarks.
- Lower model count may reduce the compute needed for operational land-monitoring systems that must handle open vocabularies.
Load-bearing premise
Fusing SAM 3's semantic, instance, and presence outputs will reliably yield accurate instance-level change masks without creating new alignment or consistency problems between paired images.
What would settle it
Evaluating the model on LEVIR-CD or WHU-CD and obtaining IoU scores below the claimed 67.2 or 66.5, or finding visually mismatched instances when inspecting the generated change masks on the same benchmarks.
Figures



read the original abstract
Change Detection (CD) is a fundamental task in remote sensing. It monitors the evolution of land cover over time. Based on this, Open-Vocabulary Change Detection (OVCD) introduces a new requirement. It aims to reduce the reliance on predefined categories. Existing training-free OVCD methods mostly use CLIP to identify categories. These methods also need extra models like DINO to extract features. However, combining different models often causes problems in matching features and makes the system unstable. Recently, the Segment Anything Model 3 (SAM 3) is introduced. It integrates segmentation and identification capabilities within one promptable model, which offers new possibilities for the OVCD task. In this paper, we propose OmniOVCD, a standalone framework designed for OVCD. By leveraging the decoupled output heads of SAM 3, we propose a Synergistic Fusion to Instance Decoupling (SFID) strategy. SFID first fuses the semantic, instance, and presence outputs of SAM 3 to construct land-cover masks, and then decomposes them into individual instance masks for change comparison. This design preserves high accuracy in category recognition and maintains instance-level consistency across images. As a result, the model can generate accurate change masks. Experiments on four public benchmarks (LEVIR-CD, WHU-CD, S2Looking, and SECOND) demonstrate SOTA performance, achieving IoU scores of 67.2, 66.5, 24.5, and 27.1 (class-average), respectively, surpassing all previous methods. The code is available at https://github.com/Erxucomeon/OmniOVCD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OmniOVCD, a training-free standalone framework for open-vocabulary change detection (OVCD) in remote sensing imagery. It uses the decoupled semantic, instance, and presence heads of SAM 3 together with a Synergistic Fusion to Instance Decoupling (SFID) strategy that first fuses outputs into land-cover masks and then decomposes them into per-instance masks for bi-temporal comparison. Experiments on LEVIR-CD, WHU-CD, S2Looking, and SECOND report SOTA IoU scores of 67.2, 66.5, 24.5, and 27.1 (class-average), respectively, while eliminating reliance on separate CLIP/DINO models.
Significance. If the SFID fusion demonstrably enforces instance-level correspondence and category consistency without explicit registration or matching losses, the approach would meaningfully simplify OVCD pipelines by replacing multi-model feature alignment with a single promptable foundation model. The public code release is a positive factor for reproducibility.
major comments (2)
- [Abstract] Abstract: The central claim that SFID 'maintains instance-level consistency across images' and yields accurate change masks rests on an unstated assumption that independently processed SAM 3 outputs can be directly paired; no description of cross-image registration, feature matching, correspondence loss, or boundary alignment procedure is provided, yet the reported IoU gains presuppose correct instance correspondence.
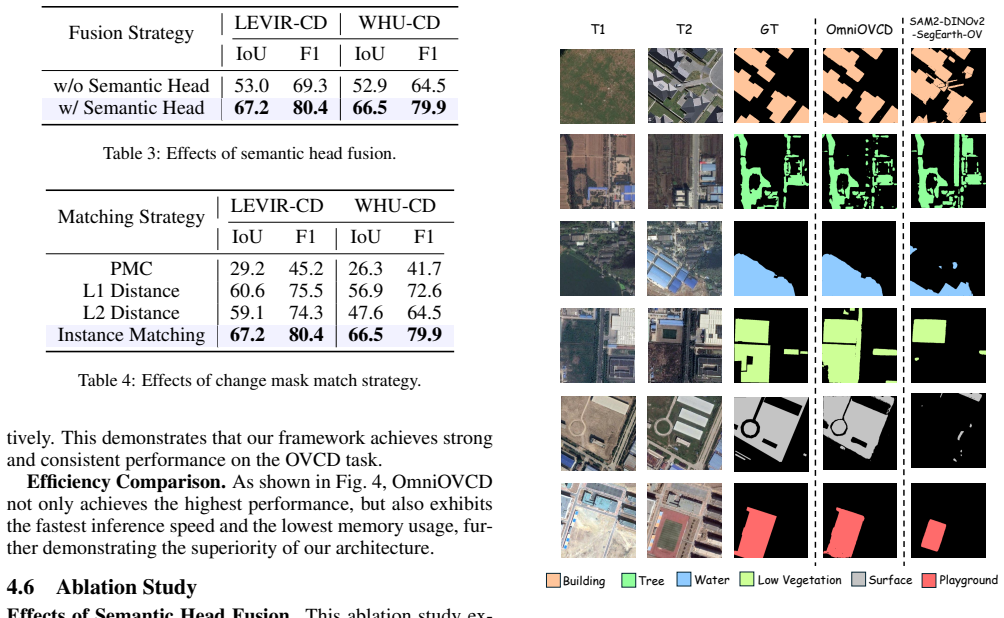
- [Experiments] Experiments section: The specific IoU numbers (67.2/66.5/24.5/27.1) are presented without error bars, run-to-run variance, or ablation tables isolating SFID components (semantic/instance/presence fusion weights, decomposition rules); this leaves the SOTA claim difficult to evaluate against prior methods that also use SAM 3.
minor comments (1)
- [Abstract] Abstract: Clarify whether the 'class-average' IoU on SECOND follows the standard mean-IoU protocol used on the other three benchmarks.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point by point below, indicating the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that SFID 'maintains instance-level consistency across images' and yields accurate change masks rests on an unstated assumption that independently processed SAM 3 outputs can be directly paired; no description of cross-image registration, feature matching, correspondence loss, or boundary alignment procedure is provided, yet the reported IoU gains presuppose correct instance correspondence.
Authors: We thank the referee for this important clarification request. Standard remote-sensing change-detection benchmarks (LEVIR-CD, WHU-CD, etc.) provide pre-registered image pairs; this is the established protocol in the field and is stated in the dataset descriptions. SFID first fuses SAM 3’s semantic, instance, and presence heads into coherent land-cover masks and then decouples them into per-instance masks; because the same promptable model is applied to both time steps, semantic and instance labels remain consistent without an explicit matching loss or registration step. In the revised manuscript we will add a dedicated paragraph in Section 3.2 that explicitly states the pre-registration assumption and details how the fusion-to-decoupling pipeline preserves instance correspondence. revision: yes
-
Referee: [Experiments] Experiments section: The specific IoU numbers (67.2/66.5/24.5/27.1) are presented without error bars, run-to-run variance, or ablation tables isolating SFID components (semantic/instance/presence fusion weights, decomposition rules); this leaves the SOTA claim difficult to evaluate against prior methods that also use SAM 3.
Authors: We agree that additional statistical and ablation evidence will improve transparency. Because OmniOVCD is training-free, run-to-run variance arises only from prompt sampling or minor numerical differences; we will report mean and standard deviation over five independent prompt sets. We will also insert a new ablation table (Table 4) that varies the semantic/instance/presence fusion weights and the decomposition thresholds, showing their individual contributions to the final IoU. Regarding prior SAM-3-based methods, to the best of our knowledge no published OVCD work has yet exploited SAM 3’s decoupled heads in the manner proposed; we will add a short footnote clarifying this point and confirming that all listed baselines rely on separate CLIP/DINO pipelines. revision: yes
Circularity Check
No circularity: SFID is an independent fusion strategy applied to external SAM 3 outputs
full rationale
The paper defines OmniOVCD via a new SFID procedure that fuses SAM 3's semantic/instance/presence heads into land-cover masks then decomposes them for bi-temporal comparison. No equations, fitted parameters, or self-citations are shown reducing the central claim to its own inputs. Performance numbers are reported from experiments on public benchmarks (LEVIR-CD etc.) and do not presuppose the result by construction. The derivation chain is therefore self-contained against external model outputs and data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption SAM 3 provides decoupled semantic, instance, and presence outputs that can be fused via SFID to construct accurate land-cover masks for change detection.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SFID first fuses the semantic, instance, and presence outputs of SAM 3 to construct land-cover masks, and then decomposes them into individual instance masks for change comparison.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
MemOVCD: Training-Free Open-Vocabulary Change Detection via Cross-Temporal Memory Reasoning and Global-Local Adaptive Rectification
MemOVCD reformulates change detection as cross-temporal memory reasoning with weighted bidirectional propagation and adaptive rectification to improve semantic change identification without task-specific training.
Reference graph
Works this paper leans on
-
[1]
[Asadzadehet al., 2022 ] Saeid Asadzadeh, Wilson Jos ´e de Oliveira, and Carlos Roberto de Souza Filho. Uav- based remote sensing for the petroleum industry and environmental monitoring: State-of-the-art and perspec- tives.Journal of Petroleum Science and Engineering, 208:109633,
work page 2022
-
[2]
A transformer-based siamese network for change detection
[Bandara and Patel, 2022] Wele Gedara Chaminda Bandara and Vishal M Patel. A transformer-based siamese network for change detection. InIGARSS 2022-2022 IEEE Interna- tional Geoscience and Remote Sensing Symposium, pages 207–210. IEEE,
work page 2022
-
[3]
[Bovolo and Bruzzone, 2006] Francesca Bovolo and Lorenzo Bruzzone. A theoretical framework for unsuper- vised change detection based on change vector analysis in the polar domain.IEEE Transactions on Geoscience and Remote Sensing, 45(1):218–236,
work page 2006
-
[4]
SAM 3: Segment Anything with Concepts
[Carionet al., 2025 ] Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Emerging properties in self-supervised vision transformers
[Caronet al., 2021 ] Mathilde Caron, Hugo Touvron, Ishan Misra, Herv´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the International Conference on Computer Vision (ICCV),
work page 2021
-
[6]
[Celik, 2009] Turgay Celik. Unsupervised change detection in satellite images using principal component analysis and k-means clustering.IEEE geoscience and remote sensing letters, 6(4):772–776,
work page 2009
-
[7]
[Chen and Shi, 2020] Hao Chen and Zhenwei Shi. A spatial- temporal attention-based method and a new dataset for re- mote sensing image change detection.Remote sensing, 12(10):1662,
work page 2020
-
[8]
[Chenet al., 2022 ] Hao Chen, Zipeng Qi, and Zhenwei Shi. Remote sensing image change detection with transform- ers.IEEE Transactions on Geoscience and Remote Sens- ing, 60:3095166,
work page 2022
-
[9]
Fully convolutional siamese networks for change detection
[Daudtet al., 2018 ] Rodrigo Caye Daudt, Bertr Le Saux, and Alexandre Boulch. Fully convolutional siamese networks for change detection. In2018 25th IEEE international conference on image processing (ICIP), pages 4063–4067. IEEE,
work page 2018
-
[10]
[Dinget al., 2022 ] Lei Ding, Haitao Guo, Sicong Liu, Lichao Mou, Jing Zhang, and Lorenzo Bruzzone. Bi- temporal semantic reasoning for the semantic change de- tection in hr remote sensing images.IEEE Transactions on Geoscience and Remote Sensing, 60:1–14,
work page 2022
-
[11]
[Dinget al., 2024 ] Lei Ding, Kun Zhu, Daifeng Peng, Hao Tang, Kuiwu Yang, and Lorenzo Bruzzone. Adapting seg- ment anything model for change detection in vhr remote sensing images.IEEE Transactions on Geoscience and Remote Sensing, 62:1–11,
work page 2024
-
[12]
[Duet al., 2019 ] Bo Du, Lixiang Ru, Chen Wu, and Liang- pei Zhang. Unsupervised deep slow feature analysis for change detection in multi-temporal remote sensing im- ages.IEEE Transactions on Geoscience and Remote Sens- ing, 57(12):9976–9992,
work page 2019
-
[13]
Convolutional neural network features based change detection in satellite images
[El Aminet al., 2016 ] Arabi Mohammed El Amin, Qingjie Liu, and Yunhong Wang. Convolutional neural network features based change detection in satellite images. InFirst International Workshop on Pattern Recognition, volume 10011, pages 181–186. SPIE,
work page 2016
-
[14]
[Fanget al., 2023 ] Sheng Fang, Kaiyu Li, and Zhe Li. Changer: Feature interaction is what you need for change detection.IEEE Transactions on Geoscience and Remote Sensing, 61:1–11,
work page 2023
-
[15]
[Fenget al., 2023 ] Yuchao Feng, Jiawei Jiang, Honghui Xu, and Jianwei Zheng. Change detection on remote sens- ing images using dual-branch multilevel intertemporal net- work.IEEE Transactions on Geoscience and Remote Sensing, 61:1–15,
work page 2023
-
[16]
[Jiet al., 2019 ] Shunping Ji, Shiqing Wei, and Meng Lu. Fully convolutional networks for multisource building ex- traction from an open aerial and satellite imagery data set. IEEE Transactions on Geoscience and Remote Sensing, 57(1):574–586,
work page 2019
-
[17]
[Kirillovet al., 2023 ] Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. InPro- ceedings of the IEEE/CVF international conference on computer vision, pages 4015–4026,
work page 2023
-
[18]
Prox- yclip: Proxy attention improves clip for open-vocabulary segmentation
[Lanet al., 2024 ] Mengcheng Lan, Chaofeng Chen, Yiping Ke, Xinjiang Wang, Litong Feng, and Wayne Zhang. Prox- yclip: Proxy attention improves clip for open-vocabulary segmentation. InEuropean Conference on Computer Vi- sion, pages 70–88. Springer,
work page 2024
-
[19]
[Liet al., 2025a ] Kaiyu Li, Xiangyong Cao, Yupeng Deng, Chao Pang, Zepeng Xin, Deyu Meng, and Zhi Wang. Dy- namicearth: How far are we from open-vocabulary change detection?arXiv preprint arXiv:2501.12931,
-
[20]
SegEarth-OV3: Exploring SAM 3 for Open-Vocabulary Semantic Segmentation in Remote Sensing Images
[Liet al., 2025c ] Kaiyu Li, Shengqi Zhang, Yupeng Deng, Zhi Wang, Deyu Meng, and Xiangyong Cao. Segearth- ov3: Exploring sam 3 for open-vocabulary semantic seg- mentation in remote sensing images.arXiv preprint arXiv:2512.08730,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
[Meiet al., 2024 ] Liye Mei, Zhaoyi Ye, Chuan Xu, Hongzhu Wang, Ying Wang, Cheng Lei, Wei Yang, and Yansheng Li. Scd-sam: Adapting segment anything model for se- mantic change detection in remote sensing imagery.IEEE Transactions on Geoscience and Remote Sensing, 62:1– 13,
work page 2024
-
[22]
[Penget al., 2021 ] Daifeng Peng, Lorenzo Bruzzone, Yongjun Zhang, Haiyan Guan, and Pengfei He. Scdnet: A novel convolutional network for semantic change de- tection in high resolution optical remote sensing imagery. International Journal of Applied Earth Observation and Geoinformation, 103:102465,
work page 2021
-
[23]
Learning transferable visual models from nat- ural language supervision
[Radfordet al., 2021 ] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from nat- ural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR,
work page 2021
-
[24]
SAM 2: Segment Anything in Images and Videos
[Raviet al., 2024 ] Nikhila Ravi, Valentin Gabeur, Yuan- Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R ¨adle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714,
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Unsupervised deep change vector analysis for multiple-change detection in vhr images
[Sahaet al., 2019 ] Sudipan Saha, Francesca Bovolo, and Lorenzo Bruzzone. Unsupervised deep change vector analysis for multiple-change detection in vhr images. IEEE transactions on geoscience and remote sensing, 57(6):3677–3693,
work page 2019
-
[26]
[Shenet al., 2021 ] Li Shen, Yao Lu, Hao Chen, Hao Wei, Donghai Xie, Jiabao Yue, Rui Chen, Shouye Lv, and Bitao Jiang. S2looking: A satellite side-looking dataset for building change detection.Remote Sensing, 13(24):5094,
work page 2021
-
[27]
[Tanet al., 2024 ] Xiaoliang Tan, Guanzhou Chen, Tong Wang, Jiaqi Wang, and Xiaodong Zhang. Segment change model (scm) for unsupervised change detection in vhr re- mote sensing images: a case study of buildings. InIGARSS 2024-2024 IEEE International Geoscience and Remote Sensing Symposium, pages 8577–8580. IEEE,
work page 2024
-
[28]
[Tanget al., 2021 ] Xu Tang, Huayu Zhang, Lichao Mou, Fang Liu, Xiangrong Zhang, Xiao Xiang Zhu, and Licheng Jiao. An unsupervised remote sensing change de- tection method based on multiscale graph convolutional network and metric learning.IEEE Transactions on Geo- science and Remote Sensing, 60:1–15,
work page 2021
-
[29]
Sclip: Rethinking self-attention for dense vision-language inference
[Wanget al., 2024 ] Feng Wang, Jieru Mei, and Alan Yuille. Sclip: Rethinking self-attention for dense vision-language inference. InEuropean Conference on Computer Vision, pages 315–332. Springer,
work page 2024
-
[30]
[Wellmannet al., 2020 ] Thilo Wellmann, Angela Lausch, Erik Andersson, Sonja Knapp, Chiara Cortinovis, Jessica Jache, Sebastian Scheuer, Peleg Kremer, Andr´e Mascaren- has, Roland Kraemer, et al. Remote sensing in urban plan- ning: Contributions towards ecologically sound policies? Landscape and urban planning, 204:103921,
work page 2020
-
[31]
[Xuet al., 2024 ] Chuan Xu, Zhaoyi Ye, Liye Mei, Hao- nan Yu, Jianchen Liu, Yaxiaer Yalikun, Shuangtong Jin, Sheng Liu, Wei Yang, and Cheng Lei. Hybrid attention- aware transformer network collaborative multiscale fea- ture alignment for building change detection.IEEE Trans- actions on Instrumentation and Measurement, 73:1–14,
work page 2024
-
[32]
[Yanget al., 2022 ] Kunping Yang, Gui-Song Xia, Zicheng Liu, Bo Du, Wen Yang, Marcello Pelillo, and Liang- pei Zhang. Asymmetric siamese networks for semantic change detection in aerial images.IEEE Transactions on Geoscience and Remote Sensing, 60:3113912,
work page 2022
-
[33]
[Zhanget al., 2020 ] Chenxiao Zhang, Peng Yue, Deodato Tapete, Liangcun Jiang, Boyi Shangguan, Li Huang, and Guangchao Liu. A deeply supervised image fusion net- work for change detection in high resolution bi-temporal remote sensing images.ISPRS Journal of Photogramme- try and Remote Sensing, 166:183–200,
work page 2020
-
[34]
Faster Segment Anything: Towards Lightweight SAM for Mobile Applications
[Zhanget al., 2023 ] Chaoning Zhang, Dongshen Han, Yu Qiao, Jung Uk Kim, Sung-Ho Bae, Seungkyu Lee, and Choong Seon Hong. Faster segment anything: Towards lightweight sam for mobile applications.arXiv preprint arXiv:2306.14289,
work page internal anchor Pith review arXiv 2023
-
[35]
A survey on segment anything model (sam): Vision foundation model meets prompt engineering
[Zhaoet al., 2023 ] Xu Zhao, Wenchao Ding, Yongqi An, Yinglong Du, Tao Yu, Min Li, Ming Tang, and Jin- qiao Wang. Fast segment anything.arXiv preprint arXiv:2306.12156,
-
[36]
[Zhenget al., 2021 ] Zhuo Zheng, Yanfei Zhong, Junjue Wang, Ailong Ma, and Liangpei Zhang. Building damage assessment for rapid disaster response with a deep object- based semantic change detection framework: From natural disasters to man-made disasters.Remote Sensing of Envi- ronment, 265:112636,
work page 2021
-
[37]
[Zhenget al., 2024 ] Zhuo Zheng, Yanfei Zhong, Liangpei Zhang, and Stefano Ermon. Segment any change. Advances in Neural Information Processing Systems, 37:81204–81224,
work page 2024
-
[38]
Extract free dense labels from clip
[Zhouet al., 2022 ] Chong Zhou, Chen Change Loy, and Bo Dai. Extract free dense labels from clip. InEuropean conference on computer vision, pages 696–712. Springer, 2022
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.