Recognition: 2 theorem links
· Lean TheoremVoxtral TTS
Pith reviewed 2026-05-15 00:35 UTC · model grok-4.3
The pith
Voxtral TTS generates natural multilingual speech from 3 seconds of reference audio and wins 68.4% preference over ElevenLabs in listener tests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
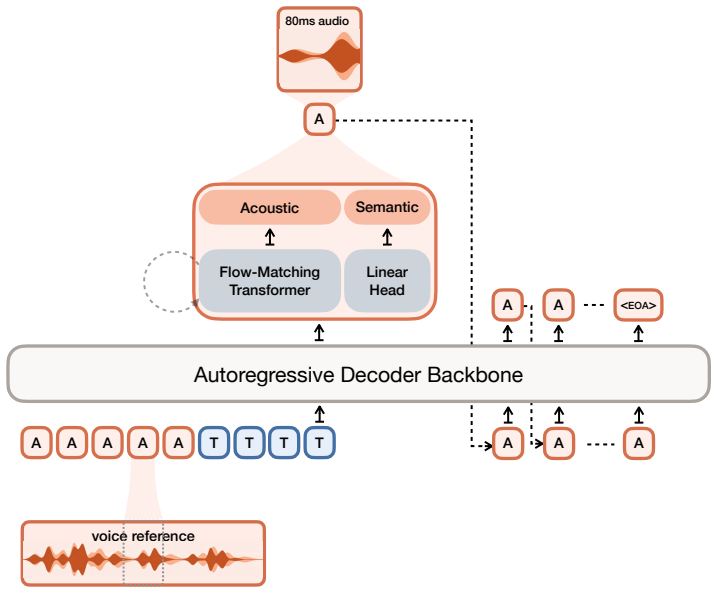
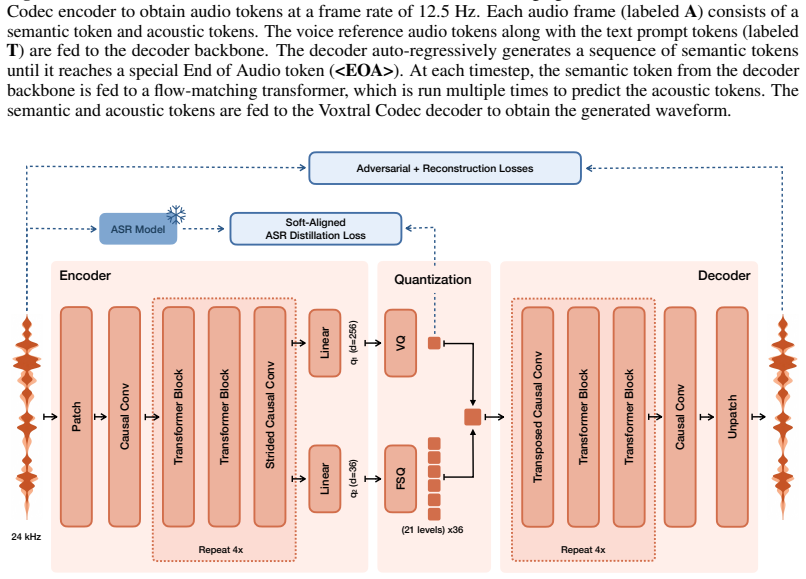
Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4% win rate over ElevenLabs Flash v2.5.
What carries the argument
Hybrid architecture that pairs autoregressive semantic token generation with flow-matching acoustic token generation, decoded by the Voxtral Codec using VQ-FSQ quantization.
Load-bearing premise
Human preference ratings from native speakers are unbiased, representative, and powered enough to establish real superiority.
What would settle it
A blinded replication test with at least 100 native listeners per language pair, pre-registered analysis, and statistical controls that yields a win rate at or below 50 percent.
Figures


read the original abstract
We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. It employs a hybrid architecture combining autoregressive generation of semantic speech tokens with flow-matching for acoustic tokens; these are handled by Voxtral Codec, a tokenizer trained from scratch using a hybrid VQ-FSQ quantization scheme. The central claim is that Voxtral TTS is preferred for multilingual voice cloning due to naturalness and expressivity, achieving a 68.4% win rate over ElevenLabs Flash v2.5 in human evaluations by native speakers. Model weights are released under CC BY-NC.
Significance. If the performance claims hold under rigorous validation, the work would provide a competitive open-source multilingual TTS system with strong low-shot voice cloning capabilities, advancing expressivity and accessibility in the field. The public release of weights is a clear community benefit.
major comments (1)
- [Abstract and Evaluation section] Abstract and Evaluation section: The headline 68.4% win-rate result is presented without any accompanying methodology, sample size, number of raters or utterances, language coverage, blinding/randomization procedures, or statistical measures (p-value, confidence interval, or error bars). This information is required to evaluate whether the binomial proportion is reliable or could be consistent with chance or bias, and its absence is load-bearing for the superiority claim.
minor comments (2)
- [§3 (Architecture)] §3 (Architecture): Provide a diagram or explicit equations showing how the autoregressive semantic tokens condition the flow-matching acoustic stage, including any cross-attention or concatenation details.
- [Table 1 or results] Table 1 or results: Report per-language win rates or breakdowns rather than a single aggregate figure to support the multilingual claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation methodology. We agree that additional details are necessary to support the reported win rate and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and Evaluation section] Abstract and Evaluation section: The headline 68.4% win-rate result is presented without any accompanying methodology, sample size, number of raters or utterances, language coverage, blinding/randomization procedures, or statistical measures (p-value, confidence interval, or error bars). This information is required to evaluate whether the binomial proportion is reliable or could be consistent with chance or bias, and its absence is load-bearing for the superiority claim.
Authors: We acknowledge that the abstract and Evaluation section currently lack the requested methodological details for the human evaluation. In the revised manuscript we will expand the Evaluation section to describe the full protocol, including the total number of utterances, number of native-speaker raters, language coverage, blinding and randomization procedures, and statistical measures (binomial p-value, confidence interval, and error bars) for the 68.4% win rate. This addition will allow readers to assess the reliability of the result. revision: yes
Circularity Check
No derivation chain or self-referential reductions present
full rationale
The paper is an empirical model release describing Voxtral TTS architecture (AR semantic tokens + flow-matching acoustic tokens + hybrid VQ-FSQ codec) and reporting a human preference result (68.4% win rate). No equations, first-principles derivations, parameter fittings, predictions, or uniqueness theorems are claimed. The central claim rests on external human evaluations rather than any internal reduction to inputs by construction. No self-citations, ansatzes, or renamings of known results appear in the abstract or described content. This is a standard non-circular empirical release; the missing evaluation statistics (sample size, controls) raise validity concerns but not circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human preference judgments by native speakers are reliable proxies for naturalness and expressivity.
invented entities (1)
-
Voxtral Codec
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens... hybrid VQ-FSQ quantization scheme
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Voxtral TTS is preferred... achieving a 68.4% win rate over ElevenLabs Flash v2.5
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2406.02430. Kaito Baba, Wataru Nakata, Yuki Saito, and Hiroshi Saruwatari. The t05 system for the V oiceMOS Challenge 2024: Transfer learning from deep image classifier to naturalness MOS prediction of high-quality synthetic speech. InIEEE Spoken Language Technology Workshop (SLT), pages 818–824,
-
[2]
doi: 10.1109/SLT61566.2024.10832315. Donald J. Berndt and James Clifford. Using dynamic time warping to find patterns in time series. InProceedings of the 3rd International Conference on Knowledge Discovery and Data Mining, AAAIWS’94, page 359–370. AAAI Press,
-
[3]
Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T
doi: 10.1109/TASLP.2023.3288409. Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T. Freeman. Maskgit: Masked generative image transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11315–11325, June
-
[4]
High Fidelity Neural Audio Compression
Alexandre Défossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi. High fidelity neural audio compression.arXiv preprint arXiv:2210.13438,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Moshi: a speech-text foundation model for real-time dialogue
Alexandre Défossez, Laurent Mazaré, Manu Orsini, Amélie Royer, Patrick Pérez, Hervé Jégou, Edouard Grave, and Neil Zeghidour. Moshi: a speech-text foundation model for real-time dialogue. arXiv preprint arXiv:2410.00037,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Brecht Desplanques, Jenthe Thienpondt, and Kris Demuynck. ECAPA-TDNN: Emphasized channel attention, propagation and aggregation in TDNN based speaker verification. InInterspeech 2020, pages 3830–3834,
work page 2020
-
[7]
Classifier-Free Diffusion Guidance
doi: 10.21437/Interspeech.2020-2650. Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.21437/interspeech.2020-2650 2020
-
[8]
Classifier-Free Diffusion Guidance
URLhttps://arxiv.org/abs/2207.12598. Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with PagedAttention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
In: Proceedings of the 29th Symposium on Operating Systems Principles
doi: 10.1145/3600006.3613165. Matt Le, Apoorv Vyas, Bowen Shi, Brian Karrer, Leda Sari, Rashel Moritz, Mary Williamson, Vimal Manohar, Yossi Adi, Jay Mahadeokar, and Wei-Ning Hsu. V oicebox: Text-guided multilingual universal speech generation at scale. InAdvances in Neural Information Processing Systems, volume 36,
-
[10]
Alexander H Liu, Sung-Lin Yeh, and James R Glass
URL https://proceedings.neurips.cc/paper_files/paper/2023/ha sh/2d8911db9ecedf866015091b28946e15-Abstract-Conference.html. Alexander H Liu, Sung-Lin Yeh, and James R Glass. Revisiting self-supervised learning of speech representation from a mutual information perspective. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Pro...
work page 2023
-
[11]
URLhttps://arxiv.org/abs/2507.13264. 14 Alexander H Liu, Kartik Khandelwal, Sandeep Subramanian, Victor Jouault, Abhinav Rastogi, Adrien Sadé, Alan Jeffares, Albert Jiang, Alexandre Cahill, Alexandre Gavaudan, et al. Ministral 3.arXiv preprint arXiv:2601.08584,
-
[12]
Tu Anh Nguyen, Wei-Ning Hsu, Antony d’Avirro, Bowen Shi, Itai Gat, Maryam Fazel-Zarani, Tal Remez, Jade Copet, Gabriel Synnaeve, Michael Hassid, et al. Expresso: A benchmark and analysis of discrete expressive speech resynthesis.arXiv preprint arXiv:2308.05725,
-
[13]
Scaling transformers for low-bitrate high-quality speech coding.arXiv preprint arXiv:2411.19842,
Julian D Parker, Anton Smirnov, Jordi Pons, CJ Carr, Zack Zukowski, Zach Evans, and Xubo Liu. Scaling transformers for low-bitrate high-quality speech coding.arXiv preprint arXiv:2411.19842,
-
[14]
URL https://proceedings.mlr.press/v139/popov21a. html. Ofir Press, Noah A Smith, and Mike Lewis. Train short, test long: Attention with linear biases enables input length extrapolation.arXiv preprint arXiv:2108.12409,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
URL https://arxiv.org/abs/2305.18290. Hugo Touvron, Matthieu Cord, Alexandre Sablayrolles, Gabriel Synnaeve, and Hervé Jégou. Going deeper with image transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 32–42,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Stab: Speech tokenizer assessment benchmark.arXiv preprint arXiv:2409.02384,
Shikhar Vashishth, Harman Singh, Shikhar Bharadwaj, Sriram Ganapathy, Chulayuth Asawaro- engchai, Kartik Audhkhasi, Andrew Rosenberg, Ankur Bapna, and Bhuvana Ramabhadran. Stab: Speech tokenizer assessment benchmark.arXiv preprint arXiv:2409.02384,
-
[18]
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
URL https://arxiv.org/abs/2301.02111. Haibin Wu, Naoyuki Kanda, Sefik Emre Eskimez, and Jinyu Li. Ts3-codec: Transformer-based simple streaming single codec.arXiv preprint arXiv:2411.18803,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
URLhttps://arxiv.org/abs/2602.02204. Bowen Zhang, Congchao Guo, Geng Yang, Hang Yu, Haozhe Zhang, Heidi Lei, Jialong Mai, Junjie Yan, Kaiyue Yang, Mingqi Yang, Peikai Huang, Ruiyang Jin, Sitan Jiang, Weihua Cheng, Yawei Li, Yichen Xiao, Yiying Zhou, Yongmao Zhang, Yuan Lu, and Yucen He. Minimax- speech: Intrinsic zero-shot text-to-speech with a learnable ...
-
[20]
15 Xin Zhang, Dong Zhang, Shimin Li, Yaqian Zhou, and Xipeng Qiu
URL https: //arxiv.org/abs/2505.07916. 15 Xin Zhang, Dong Zhang, Shimin Li, Yaqian Zhou, and Xipeng Qiu. Speechtokenizer: Unified speech tokenizer for speech large language models.arXiv preprint arXiv:2308.16692,
- [21]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.