From Video to Control: A Survey of Learning Manipulation Interfaces from Temporal Visual Data
Pith reviewed 2026-05-13 16:59 UTC · model grok-4.3
The pith
Video-based robot manipulation methods are limited most by how predictions connect to reliable physical actions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
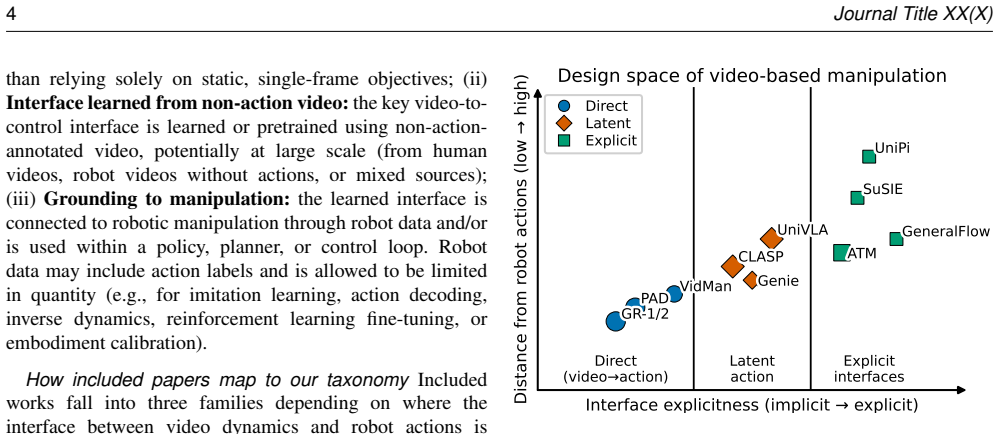
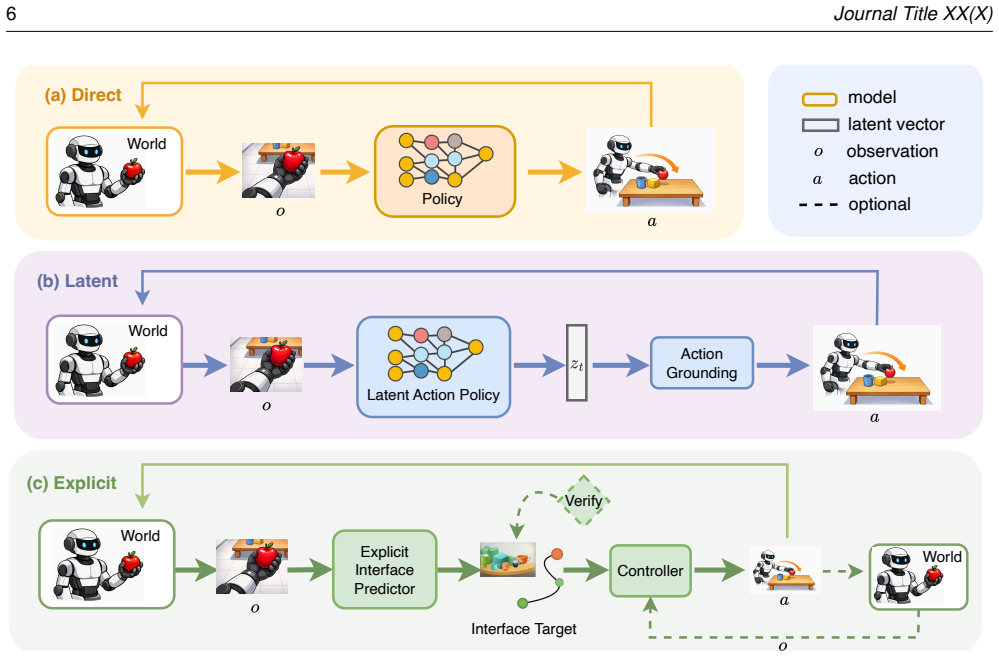
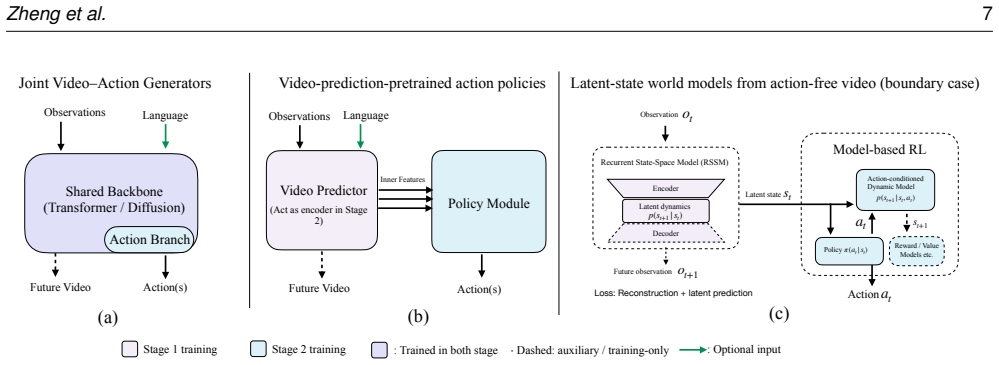
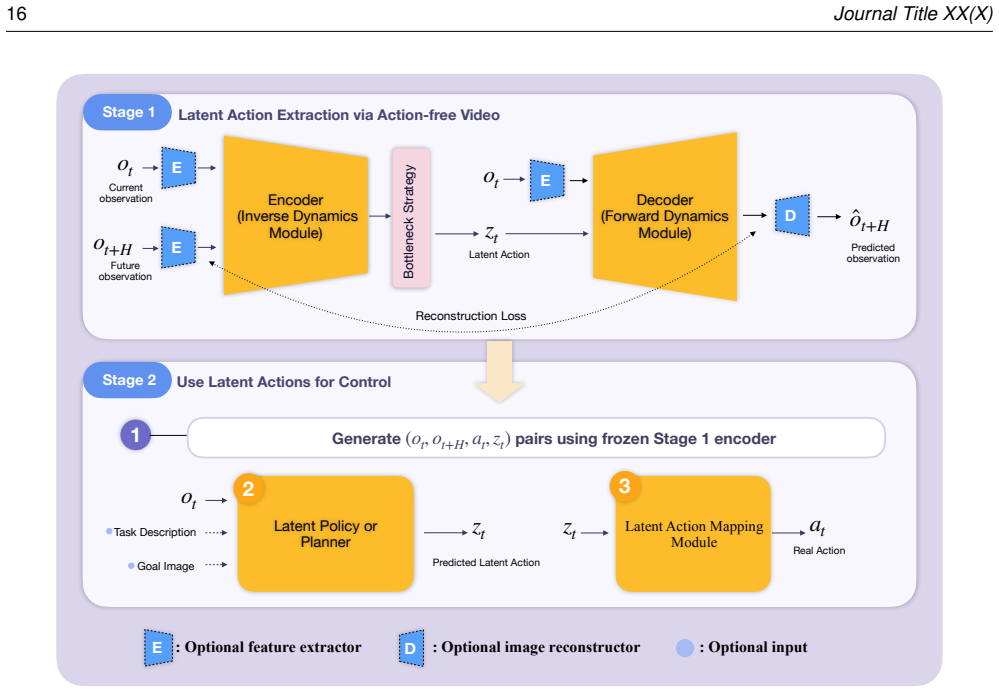
The paper defines an interface-centric taxonomy that places existing video-to-control methods into three families: direct video-action policies that keep the mapping implicit, latent-action methods that pass temporal structure through a compact learned representation, and explicit visual interfaces that output interpretable targets for separate controllers. Analysis of control-integration properties across families shows that the robotics integration layer remains the primary barrier to dependable execution.
What carries the argument
The interface-centric taxonomy that classifies methods by the construction site of the video-to-control interface and the resulting control properties.
If this is right
- Each family closes the control loop at a different stage and admits different forms of pre-execution verification.
- Failure modes enter at distinct points depending on whether the interface is implicit, latent, or explicit.
- Further progress requires targeted work on the robotics integration layer that translates video predictions into safe robot commands.
- The taxonomy supplies a common language for comparing how different methods handle embodiment gaps and missing action labels.
Where Pith is reading between the lines
- Hybrid methods that borrow elements from multiple families could address integration weaknesses that single-family approaches leave open.
- Standardized testbeds focused on integration properties would make it easier to measure whether new techniques actually improve dependable behavior.
- Deployment on physical robots with changing viewpoints and contact dynamics would expose integration shortcomings more clearly than simulation results alone.
Load-bearing premise
The proposed three-family taxonomy captures the essential differences among current video-to-control methods without missing major approaches or imposing artificial divisions.
What would settle it
A published video-based manipulation technique that cannot be assigned to any of the three families in the taxonomy.
Figures




read the original abstract
Video is a scalable observation of physical dynamics: it captures how objects move, how contact unfolds, and how scenes evolve under interaction -- all without requiring robot action labels. Yet translating this temporal structure into reliable robotic control remains an open challenge, because video lacks action supervision and differs from robot experience in embodiment, viewpoint, and physical constraints. This survey reviews methods that exploit non-action-annotated temporal video to learn control interfaces for robotic manipulation. We introduce an interface-centric taxonomy organized by where the video-to-control interface is constructed and what control properties it enables, identifying three families: direct video-action policies, which keep the interface implicit; latent-action methods, which route temporal structure through a compact learned intermediate; and explicit visual interfaces, which predict interpretable targets for downstream control. For each family, we analyze control-integration properties -- how the loop is closed, what can be verified before execution, and where failures enter. A cross-family synthesis reveals that the most pressing open challenges center on the robotics integration layer -- the mechanisms that connect video-derived predictions to dependable robot behavior -- and we outline research directions toward closing this gap.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This survey reviews methods that exploit non-action-annotated temporal video to learn control interfaces for robotic manipulation. It introduces an interface-centric taxonomy organized by where the video-to-control interface is constructed, identifying three families: direct video-action policies (implicit interface), latent-action methods (compact learned intermediate), and explicit visual interfaces (interpretable targets for downstream control). For each family the paper analyzes control-integration properties including loop closure, pre-execution verifiability, and failure modes. A cross-family synthesis concludes that the robotics integration layer constitutes the dominant open challenge and outlines research directions to close the gap.
Significance. If the taxonomy and per-family analyses hold, the survey supplies a useful organizing lens that shifts emphasis from isolated algorithmic advances to the mechanisms needed to connect video-derived predictions to dependable robot behavior. This framing can help the community prioritize integration-layer research, which is essential for translating abundant video data into practical manipulation systems.
minor comments (2)
- [Abstract] Abstract: the three-family taxonomy is presented as capturing essential distinctions, yet the boundary between latent-action and explicit visual interfaces is not illustrated with a borderline example; adding one concrete method that could plausibly fit either category would strengthen the taxonomy's clarity without altering the central claim.
- [Synthesis section] The cross-family synthesis identifies the robotics integration layer as the primary open challenge; a short table or bullet list enumerating the specific integration shortcomings observed in each family would make this claim more immediately verifiable for readers.
Simulated Author's Rebuttal
We thank the referee for the positive and accurate summary of our survey, for highlighting the utility of the interface-centric taxonomy, and for recommending acceptance. We appreciate the recognition that the work shifts focus toward the robotics integration layer as the central open challenge.
Circularity Check
No significant circularity
full rationale
This is a survey paper that reviews existing methods, proposes an interface-centric taxonomy as an organizing lens, and synthesizes open challenges from the literature. No equations, derivations, fitted parameters, or predictions appear anywhere in the manuscript. The central claim (robotics integration layer as dominant challenge) is a qualitative observation drawn from per-family analysis of external work, not a reduction to any internal definition or self-citation chain. The taxonomy is explicitly presented as a useful framing rather than a uniqueness theorem or ansatz. All citations are to independent prior literature; no load-bearing step collapses to the authors' own prior results by construction. The paper is therefore self-contained against external benchmarks with zero circularity.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce an interface-centric taxonomy organized by where the video-to-control interface is constructed and what control properties it enables, identifying three families: direct video–action policies... latent-action methods... explicit visual interfaces...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.