Document Optimization for Black-Box Retrieval via Reinforcement Learning
Pith reviewed 2026-05-10 19:04 UTC · model grok-4.3
The pith
Document optimization through reinforcement learning enhances black-box retrieval by rewriting documents to better match expected queries under a target retriever.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
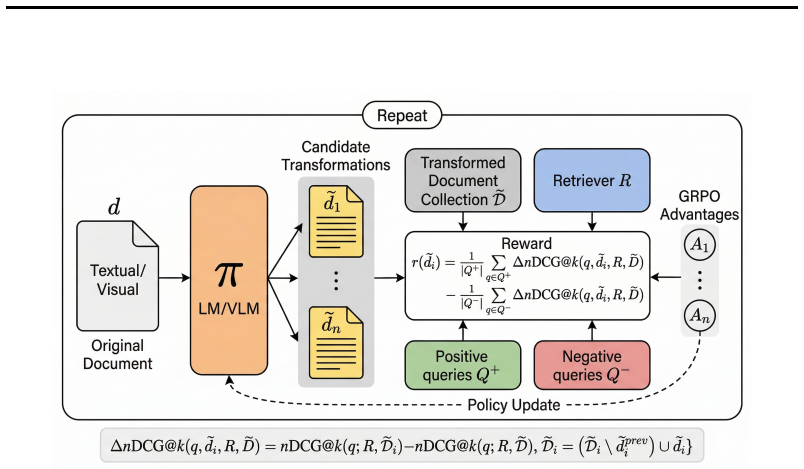
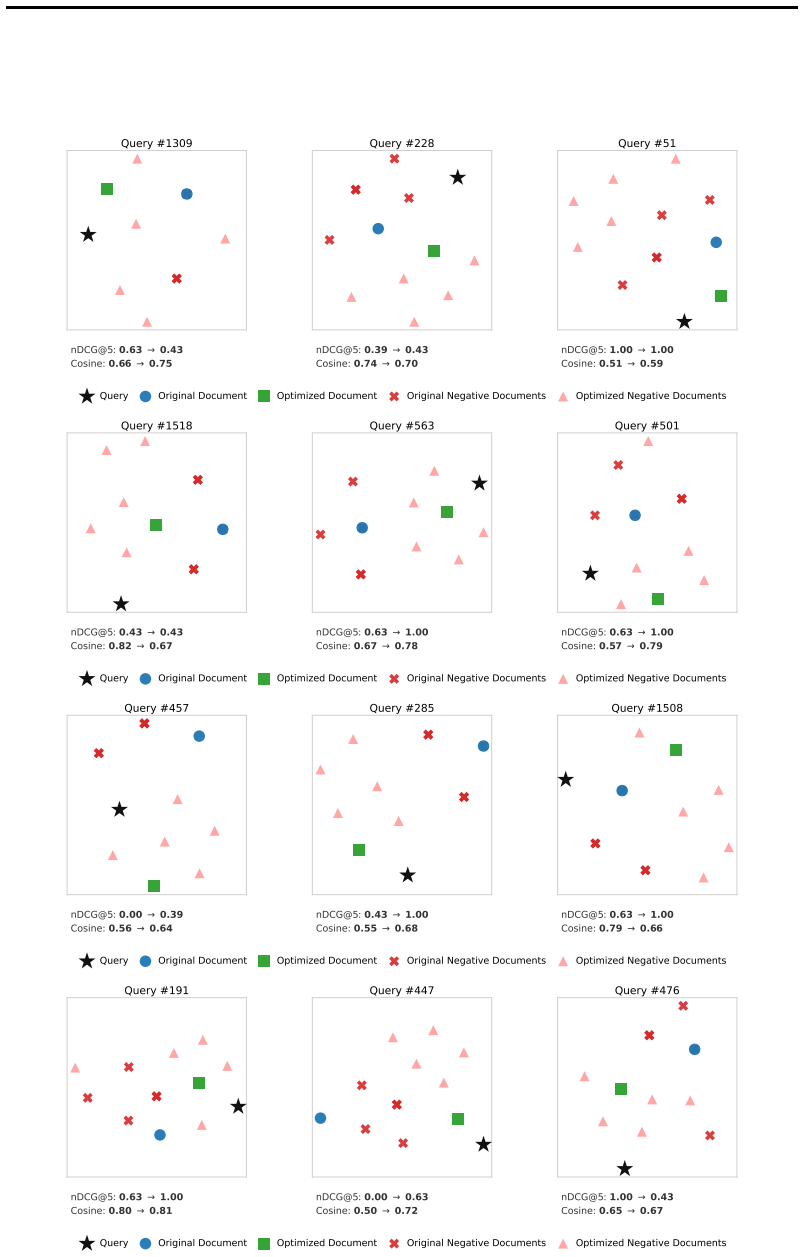
The central claim is that document expansion can be replaced by a learned optimization process in which a generative model is fine-tuned via reinforcement learning to rewrite documents, using the target retriever's ranking improvements as the sole reward signal. This produces transformed documents that align more closely with the query distribution the retriever expects, yielding measurable retrieval gains across single-vector, multi-vector, and lexical retrievers while requiring no internal access to the retriever.
What carries the argument
The reinforcement learning procedure that uses the retriever's ranking improvements as the reward signal to guide document transformations.
If this is right
- Smaller and cheaper retrievers can achieve higher accuracy than larger ones after the documents have been optimized.
- Document optimization is often competitive with retriever fine-tuning and their combination produces the best results when both are feasible.
- The method works for single-vector, multi-vector, and lexical retrievers alike using only black-box rank feedback.
- All improvements occur offline, so no extra computation is added at query time.
Where Pith is reading between the lines
- The approach could be applied to other retrieval-dependent tasks such as open-domain question answering to reduce the need for ever-larger embedding models.
- Document optimization might become a standard preprocessing step that is run once per retriever and then reused across many downstream applications.
- Testing the same optimization loop on multimodal retrievers or on retrieval-augmented generation pipelines would reveal how broadly the ranking-reward signal generalizes.
Load-bearing premise
Ranking improvements measured on the queries used for optimization will translate into better retrieval on new queries without adding noise or overfitting to the particular retriever and query distribution seen during training.
What would settle it
Apply the learned document transformations to the same retriever but evaluate on a fresh query set drawn from a different domain or task distribution and check whether the ranking gains disappear or reverse.
Figures



read the original abstract
Document expansion is a classical technique for improving retrieval quality, and is attractive since it shifts computation offline, avoiding additional query-time processing. However, when applied to modern retrievers, it has been shown to degrade performance, often introducing noise that obfuscates the discriminative signal. We recast document expansion as a document optimization problem: a language model or a vision language model is fine-tuned to transform documents into representations that better align with the expected query distribution under a target retriever, using GRPO with the retriever's ranking improvements as rewards. This approach requires only black-box access to retrieval ranks, and is applicable across single-vector, multi-vector and lexical retrievers. We evaluate our approach on code retrieval and visual document retrieval (VDR) tasks. We find that learned document transformations yield retrieval gains and in many settings enable smaller, more efficient retrievers to outperform larger ones. For example, applying document optimization to OpenAI text-embedding-3-small model improves nDCG5 on code (58.7 to 66.8) and VDR (53.3 to 57.6), even slightly surpassing the 6.5X more expensive OpenAI text-embedding-3-large model (66.3 on code; 57.0 on VDR). When retriever weights are accessible, document optimization is often competitive with fine-tuning, and in most settings their combination performs best, improving Jina-ColBERT-V2 from 55.8 to 63.3 on VDR and from 48.6 to 61.8 on code retrieval.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper recasts document expansion as a black-box optimization problem solved by fine-tuning an LM/VLM with GRPO, using rewards derived solely from a target retriever's ranking improvements on a query set. It reports that the resulting document transformations improve nDCG@5 on code retrieval (e.g., text-embedding-3-small from 58.7 to 66.8, surpassing text-embedding-3-large) and VDR (53.3 to 57.6), are competitive with fine-tuning when weights are available, and yield the best results when combined with fine-tuning (e.g., Jina-ColBERT-V2 to 63.3 on VDR and 61.8 on code).
Significance. If the gains are shown to generalize beyond the optimization queries, the work offers a practical, weight-free method to enhance any retriever (single-vector, multi-vector, or lexical) by shifting computation offline. The concrete numerical improvements and the finding that optimized small models can beat larger ones would be a notable contribution to retrieval augmentation techniques.
major comments (2)
- [Experimental Evaluation] Experimental section: the abstract and results report large gains (58.7→66.8 nDCG@5 on code for text-embedding-3-small) but supply no information on whether the query set used to compute GRPO rewards is disjoint from the test queries used for final evaluation. This is load-bearing for the central generalization claim; without a held-out split or ablation on query distribution shift, the improvements could reflect overfitting to optimization-set patterns rather than broadly useful transformations.
- [Experimental Evaluation] §4 (or equivalent experimental setup): insufficient detail is provided on baseline implementations, statistical significance testing, number of optimization runs, or controls for confounds such as query distribution shift. These omissions prevent verification that the reported improvements are robust and support the claim that document optimization is often competitive with or additive to fine-tuning.
minor comments (2)
- [Abstract] Abstract: the acronym GRPO is introduced without expansion; spell out Group Relative Policy Optimization on first use.
- [Method] Notation: the reward formulation is described at a high level; a short pseudocode or explicit equation for how ranking output is converted to scalar reward would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The points raised about experimental rigor are well-taken, and we have revised the paper to provide the requested clarifications and additional analyses. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Experimental Evaluation] Experimental section: the abstract and results report large gains (58.7→66.8 nDCG@5 on code for text-embedding-3-small) but supply no information on whether the query set used to compute GRPO rewards is disjoint from the test queries used for final evaluation. This is load-bearing for the central generalization claim; without a held-out split or ablation on query distribution shift, the improvements could reflect overfitting to optimization-set patterns rather than broadly useful transformations.
Authors: We thank the referee for highlighting this critical detail. The queries used to compute GRPO rewards were drawn exclusively from the training splits of the code and VDR datasets, while final evaluation used the standard held-out test splits; the two sets are therefore disjoint. To make this explicit and directly address generalization concerns, the revised manuscript adds a dedicated paragraph in Section 4 describing the exact data splits, together with a new ablation that measures performance under controlled query distribution shift (e.g., optimizing on one domain and testing on another). The ablation shows that the majority of the reported gains persist, supporting that the learned transformations are not merely overfitting to the optimization queries. revision: yes
-
Referee: [Experimental Evaluation] §4 (or equivalent experimental setup): insufficient detail is provided on baseline implementations, statistical significance testing, number of optimization runs, or controls for confounds such as query distribution shift. These omissions prevent verification that the reported improvements are robust and support the claim that document optimization is often competitive with or additive to fine-tuning.
Authors: We agree that greater experimental transparency is needed. The revised Section 4 now includes: (i) complete implementation details and hyper-parameters for all baselines, with pointers to public code where available; (ii) statistical significance results obtained via bootstrap resampling (1,000 iterations) with reported p-values for the key improvements; (iii) the number of independent optimization runs (five runs with distinct random seeds, reporting mean and standard deviation); and (iv) explicit controls for query distribution shift via the ablation described in the previous response. These additions allow readers to verify both the robustness of the gains and the claim that document optimization is competitive with, and often additive to, fine-tuning. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper recasts document expansion as a black-box optimization task solved via GRPO, where the reward is computed directly from the target retriever's ranking metric (nDCG or similar) on supplied queries. This reward is external to the policy parameters being optimized and is not defined in terms of the learned transformations themselves. No equations, self-citations, or ansatzes are shown that reduce the claimed gains to a tautology or fitted input renamed as prediction. The derivation chain consists of an RL training loop whose success is evaluated empirically on retrieval metrics; it does not contain self-definitional steps or load-bearing self-citations that would force the result by construction. The reported improvements (e.g., 58.7 to 66.8 nDCG@5) are therefore presented as experimental outcomes rather than logical identities.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption GRPO policy optimization converges to a useful policy when the reward signal is the change in retriever ranking quality
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We recast document expansion as a document optimization problem: a language model ... is fine-tuned to transform documents ... using GRPO with the retriever's ranking improvements as rewards.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Rewards are defined counterfactually: ... ΔnDCG@k(q) ... ri(˜di) aggregates positive gains and negative penalties.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[3]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[4]
Deltas are absolute changes relative to the corresponding Direct Retrieval row
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.