Sharp description of local minima in the loss landscape of high-dimensional two-layer ReLU neural networks
Pith reviewed 2026-05-10 16:40 UTC · model grok-4.3
The pith
Local minima in two-layer ReLU networks admit an exact low-dimensional representation via summary statistics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
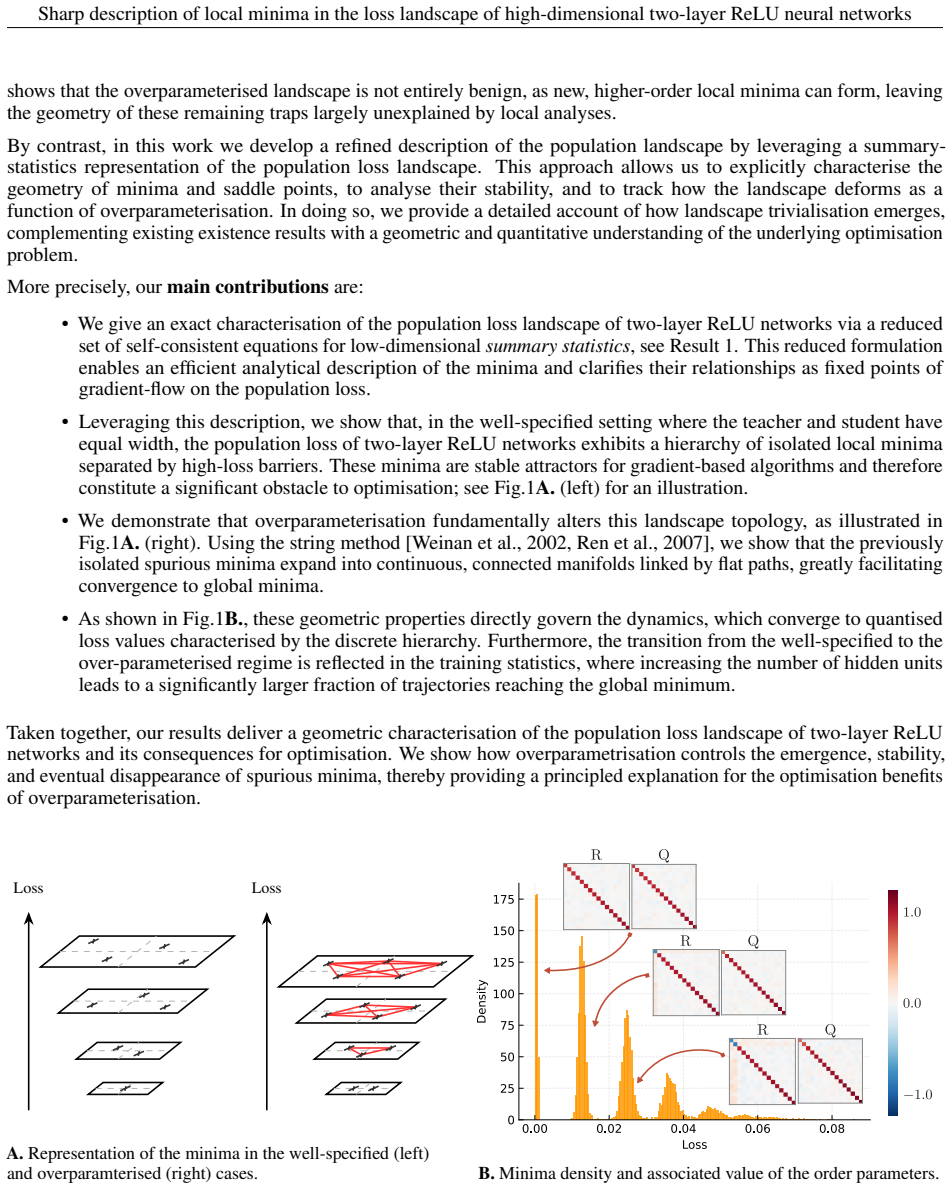
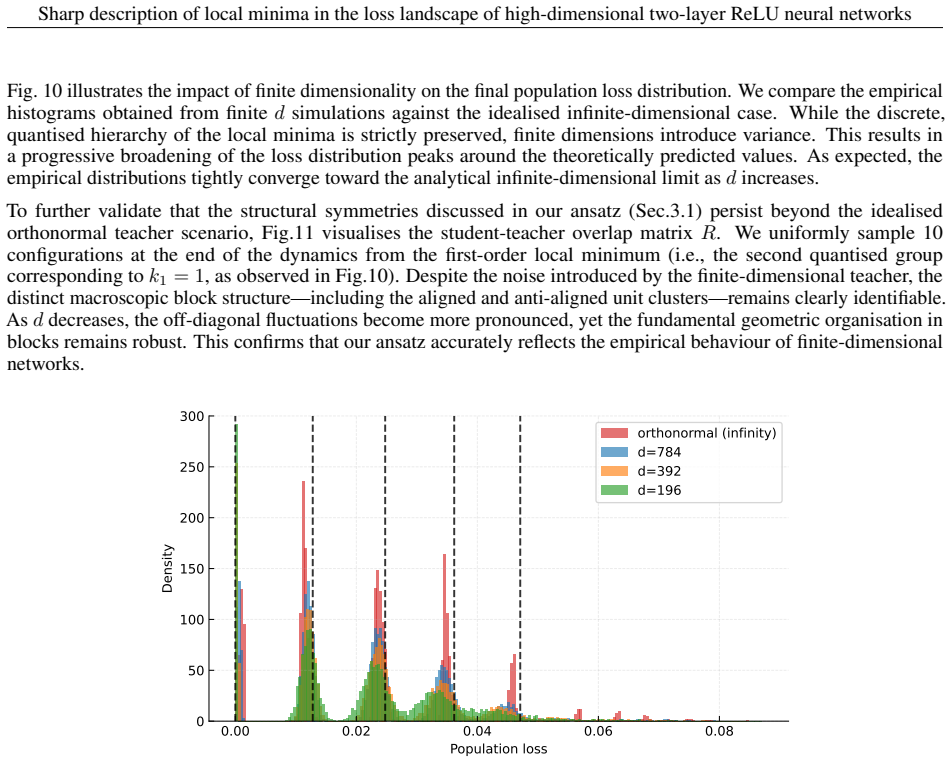
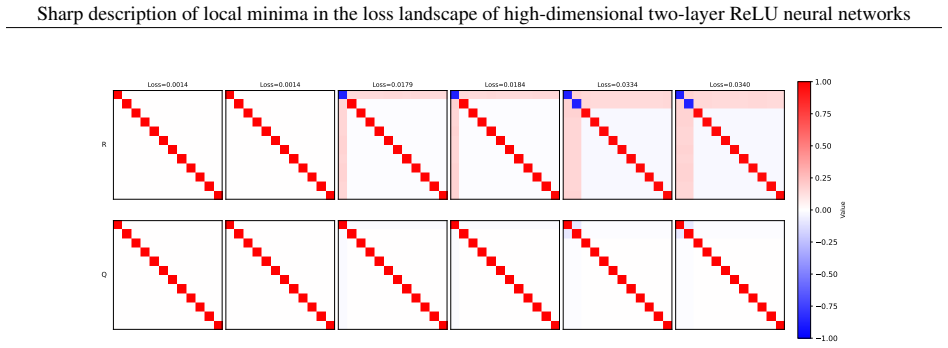
Local minima admit an exact low-dimensional representation in terms of summary statistics, yielding a sharp and interpretable characterisation of the landscape. Local minima correspond to attractive fixed points of the dynamics in summary statistics space. This perspective reveals a hierarchical structure of minima: they are typically isolated in the well-specified regime, but become connected by flat directions as network width increases. In the overparameterised regime, global minima become increasingly accessible, attracting the dynamics and reducing convergence to spurious solutions.
What carries the argument
The exact low-dimensional summary-statistics representation of local minima, which collapses the high-dimensional loss surface to a tractable reduced space and identifies the minima as fixed points of the corresponding SGD flow.
If this is right
- Local minima correspond to attractive fixed points of one-pass SGD dynamics in summary statistics space.
- Minima remain isolated when the teacher-student model is well-specified.
- Flat directions appear and connect minima once network width exceeds the teacher width.
- Global minima attract the reduced dynamics more strongly in the overparameterized regime, limiting trapping at spurious solutions.
- Common simplifying assumptions about the loss landscape miss these connectivity features even for minimal two-layer models.
Where Pith is reading between the lines
- The same summary-statistics reduction might be used to track convergence speed of other first-order methods by writing their updates in the reduced coordinates.
- If the data distribution deviates from Gaussian, the exact fixed-point equations would change, potentially altering the connectivity of minima.
- Initialization schemes that place the summary statistics near the attractive fixed points of the reduced dynamics could be designed and tested directly.
- The hierarchical connectivity pattern may appear in deeper ReLU networks, offering a route to analyze how depth and width jointly shape landscape structure.
Load-bearing premise
The derivation assumes a realizable teacher-student setting with Gaussian covariates and networks consisting of a finite sum of ReLUs.
What would settle it
Numerical optimization locates a local minimum whose full parameter vector fails to satisfy the closed set of equations that the summary statistics must obey at a stationary point.
Figures



















read the original abstract
We study the population loss landscape of two-layer ReLU networks of the form $\sum_{k=1}^K \mathrm{ReLU}(w_k^\top x)$ in a realisable teacher-student setting with Gaussian covariates. We show that local minima admit an exact low-dimensional representation in terms of summary statistics, yielding a sharp and interpretable characterisation of the landscape. We further establish a direct link with one-pass SGD: local minima correspond to attractive fixed points of the dynamics in summary statistics space. This perspective reveals a hierarchical organisation of minima into discrete families and shows how overparameterisation changes their stability and reachability under gradient-based dynamics. In this overparameterised regime, global minima become increasingly accessible, attracting the dynamics and reducing convergence to spurious solutions. Overall, our results reveal intrinsic limitations of common simplifying assumptions, which may miss essential features of the loss landscape even in minimal neural network models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes the population loss landscape of two-layer ReLU networks of the form ∑_{k=1}^K ReLU(w_k^T x) in a realizable teacher-student setting with Gaussian covariates. It claims that local minima admit an exact low-dimensional representation in terms of summary statistics (inner products with the teacher direction and neuron norms), yielding a sharp and interpretable characterization. It further links these minima to attractive fixed points of one-pass SGD dynamics in summary-statistics space, revealing a hierarchical structure: minima are typically isolated in the well-specified regime but become connected by flat directions as width increases, making global minima more accessible and reducing convergence to spurious solutions.
Significance. If the exact closure and SGD correspondence hold, the work provides a valuable precise description of the loss landscape for a minimal neural-network model, moving beyond bounds or approximations to an exact low-dimensional reduction. The direct connection between landscape geometry and SGD fixed-point dynamics is a notable strength, as is the explanation of how overparameterization creates flat directions that improve accessibility to global minima. These insights could inform analyses of optimization in wider or deeper networks and challenge simplifying assumptions common in the literature.
major comments (1)
- [§3 (summary-statistics closure) and §4 (characterization of critical points)] The central claim requires that both the population loss and its gradient (hence the stationarity condition) close exactly under a fixed low-dimensional set of summary statistics. While rotational invariance makes loss closure plausible, the manuscript must verify that ReLU active/inactive sets at critical points introduce no extra degrees of freedom outside the chosen statistics (K inner products plus K norms). If this verification is only for the loss and not the gradient, or if it implicitly assumes all neurons are fully aligned or orthogonal, the representation of local minima is incomplete.
minor comments (2)
- [§2] Clarify the precise definition of the summary-statistics vector early in the paper and state explicitly which quantities are assumed known versus derived.
- [§5] The hierarchical-structure claim would benefit from a small illustrative example or figure showing the transition from isolated to connected minima as K grows.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the need to explicitly confirm closure of both the loss and its gradient. We address this point below and will revise the manuscript to strengthen the presentation.
read point-by-point responses
-
Referee: [§3 (summary-statistics closure) and §4 (characterization of critical points)] The central claim requires that both the population loss and its gradient (hence the stationarity condition) close exactly under a fixed low-dimensional set of summary statistics. While rotational invariance makes loss closure plausible, the manuscript must verify that ReLU active/inactive sets at critical points introduce no extra degrees of freedom outside the chosen statistics (K inner products plus K norms). If this verification is only for the loss and not the gradient, or if it implicitly assumes all neurons are fully aligned or orthogonal, the representation of local minima is incomplete.
Authors: We agree that explicit verification for the gradient is essential. In §3 the population loss is shown to depend only on the K inner products with the teacher and the K neuron norms, by rotational invariance of the isotropic Gaussian measure. In §4 the stationarity equations are obtained by differentiating under the integral; the ReLU active-set indicator for each neuron has expectation and conditional moments that are functions solely of the norm of w_k and its inner product with the teacher direction, because the only distinguished direction in the problem is the teacher vector. Consequently the active/inactive sets introduce no additional degrees of freedom beyond the chosen summary statistics. The derivation nowhere assumes full alignment or orthogonality; it holds for arbitrary configurations of the summary statistics. To make this closure fully transparent we will add a dedicated lemma in the revised version that states the gradient closure explicitly. revision: partial
Circularity Check
No circularity: low-dimensional closure follows from Gaussian rotational invariance and explicit ReLU integration
full rationale
The central claim is that the population loss L(w) and its gradient close exactly under a fixed set of summary statistics (inner products with the teacher vector plus weight norms). This reduction is obtained by direct integration against the Gaussian measure and the piecewise-linear structure of ReLU; it is not obtained by fitting parameters to data, by redefining the target in terms of the statistics, or by invoking a self-citation chain. The stationarity condition is then solved inside the reduced coordinates. Because the derivation begins from the explicit model assumptions (realizable teacher-student, isotropic Gaussian covariates) and produces the closure by explicit calculation rather than by construction or renaming, the chain is self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Gaussian covariates assumption
- domain assumption Realizable teacher-student setting
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.