SPEED-Bench: A Unified and Diverse Benchmark for Speculative Decoding
Pith reviewed 2026-05-16 03:05 UTC · model grok-4.3
The pith
SPEED-Bench establishes a unified benchmark for speculative decoding that covers diverse semantic domains, throughput across concurrencies, and integration with production engines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
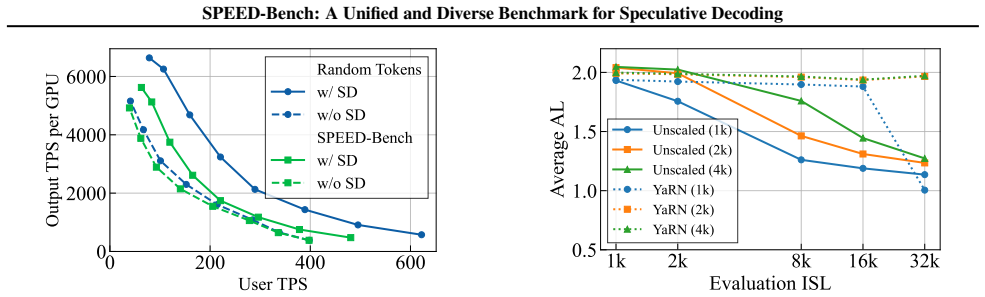
SPEED-Bench establishes a unified evaluation standard for practical comparisons of SD algorithms by offering diverse semantic domains, throughput splits across concurrencies, and integration with production engines like vLLM and TensorRT-LLM. It quantifies how synthetic inputs overestimate real-world throughput, identifies batch-size dependent optimal draft lengths and biases in low-diversity data, and analyzes the caveats of vocabulary pruning in state-of-the-art drafters.
What carries the argument
SPEED-Bench suite, built from a Qualitative data split prioritized for semantic diversity across samples and a Throughput data split spanning latency-sensitive to high-load concurrencies, integrated directly with production engines.
If this is right
- Synthetic inputs overestimate real-world throughput gains from speculative decoding.
- Optimal draft lengths vary with batch size in production settings.
- Low-diversity data introduces systematic biases in measured speedups.
- Vocabulary pruning in current drafters carries identifiable limitations under realistic loads.
Where Pith is reading between the lines
- Widespread use of SPEED-Bench could replace ad-hoc evaluations and make head-to-head claims about new speculative decoding methods more reliable.
- The split design may transfer to other data-dependent LLM serving techniques such as speculative sampling or tree decoding.
- Extending the benchmark with additional languages or multimodal inputs would test whether the current diversity criteria generalize.
Load-bearing premise
That the curated qualitative split and the production-engine integrations are representative enough to reveal behaviors that other benchmarks mask.
What would settle it
If side-by-side runs of the same speculative decoding algorithms on SPEED-Bench and prior benchmarks produce identical speedup rankings and no new batch-size or diversity effects, the added splits and integrations would not change practical conclusions.
Figures












read the original abstract
Speculative Decoding (SD) has emerged as a critical technique for accelerating Large Language Model (LLM) inference. Unlike deterministic system optimizations, SD performance is inherently data-dependent, meaning that diverse and representative workloads are essential for accurately measuring its effectiveness. Existing benchmarks suffer from limited task diversity, inadequate support for throughput-oriented evaluation, and a reliance on high-level implementations that fail to reflect production environments. To address this, we introduce SPEED-Bench, a comprehensive suite designed to standardize SD evaluation across diverse semantic domains and realistic serving regimes. SPEED-Bench offers a carefully curated Qualitative data split, selected by prioritizing semantic diversity across the data samples. Additionally, it includes a Throughput data split, allowing speedup evaluation across a range of concurrencies, from latency-sensitive low-batch settings to throughput-oriented high-load scenarios. By integrating with production engines like vLLM and TensorRT-LLM, SPEED-Bench allows practitioners to analyze system behaviors often masked by other benchmarks. We highlight this by quantifying how synthetic inputs overestimate real-world throughput, identifying batch-size dependent optimal draft lengths and biases in low-diversity data, and analyzing the caveats of vocabulary pruning in state-of-the-art drafters. We release SPEED-Bench to establish a unified evaluation standard for practical comparisons of SD algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SPEED-Bench, a benchmark suite for Speculative Decoding (SD) in LLMs. It features a Qualitative data split curated by prioritizing semantic diversity across samples, a Throughput data split supporting speedup measurements across concurrencies from latency-sensitive low-batch to high-load regimes, and direct integrations with production engines such as vLLM and TensorRT-LLM. The authors claim this enables quantification of synthetic-input overestimation of real-world throughput, identification of batch-size-dependent optimal draft lengths, detection of biases in low-diversity data, and analysis of vocabulary-pruning caveats, thereby establishing a unified standard for practical SD comparisons.
Significance. If the benchmark's data splits prove representative and the engine integrations reliably expose production behaviors, SPEED-Bench could become a standard reference for SD evaluation, enabling more accurate cross-algorithm comparisons and highlighting limitations of synthetic or low-diversity workloads that current benchmarks obscure.
major comments (3)
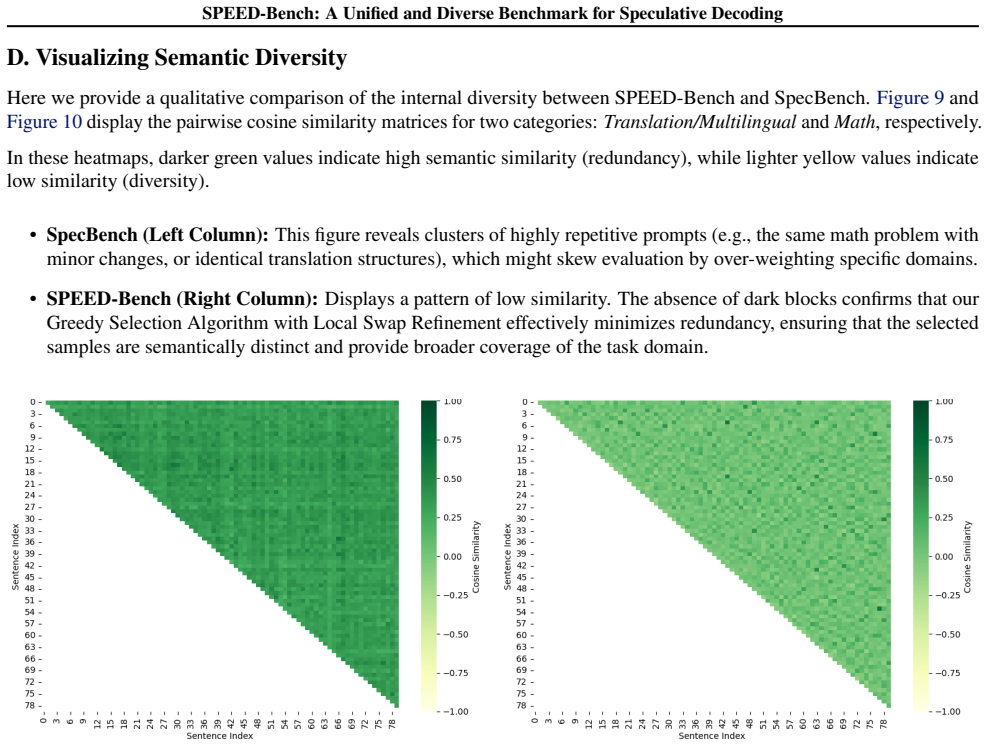
- [Abstract / Data Curation description] The central claim that the Qualitative data split 'sufficiently represents real-world workloads' rests on curation by 'prioritizing semantic diversity,' yet the manuscript provides no quantitative validation metrics (e.g., embedding variance, topic entropy, distributional similarity to production traces, or held-out query validation). This assumption is load-bearing for the assertions about realistic serving regimes and unified evaluation standard.
- [Throughput evaluation and engine integration sections] The Throughput data split and vLLM/TensorRT-LLM integrations are presented as exposing system behaviors masked by high-level implementations, but the manuscript lacks concrete implementation details, quantitative comparisons (e.g., throughput deltas or latency breakdowns), or ablation showing how these integrations differ from prior high-level SD evaluations.
- [Results / Highlighted observations] Observations such as 'synthetic inputs overestimate real-world throughput' and 'batch-size dependent optimal draft lengths' are highlighted, but without accompanying methodology details, data statistics, tables of quantitative results, or error bars, it is not possible to verify the strength of support for these claims.
minor comments (1)
- [Abstract] The abstract refers to 'we highlight this by quantifying...' without cross-references to specific sections, figures, or tables where the quantitative results appear; adding such pointers would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on SPEED-Bench. We address each major comment below and will revise the manuscript to incorporate quantitative validations, implementation details, and expanded results sections as suggested.
read point-by-point responses
-
Referee: [Abstract / Data Curation description] The central claim that the Qualitative data split 'sufficiently represents real-world workloads' rests on curation by 'prioritizing semantic diversity,' yet the manuscript provides no quantitative validation metrics (e.g., embedding variance, topic entropy, distributional similarity to production traces, or held-out query validation). This assumption is load-bearing for the assertions about realistic serving regimes and unified evaluation standard.
Authors: We agree that quantitative validation metrics would strengthen the claim of representativeness. In the revised manuscript, we will add embedding variance, topic entropy, distributional similarity to production traces, and held-out query validation to the data curation section to empirically support the semantic diversity prioritization. revision: yes
-
Referee: [Throughput evaluation and engine integration sections] The Throughput data split and vLLM/TensorRT-LLM integrations are presented as exposing system behaviors masked by high-level implementations, but the manuscript lacks concrete implementation details, quantitative comparisons (e.g., throughput deltas or latency breakdowns), or ablation showing how these integrations differ from prior high-level SD evaluations.
Authors: We will expand these sections with concrete implementation details for the vLLM and TensorRT-LLM integrations, including pseudocode and configuration specifics. Quantitative comparisons such as throughput deltas and latency breakdowns versus high-level baselines, plus ablations, will be added to demonstrate the differences. revision: yes
-
Referee: [Results / Highlighted observations] Observations such as 'synthetic inputs overestimate real-world throughput' and 'batch-size dependent optimal draft lengths' are highlighted, but without accompanying methodology details, data statistics, tables of quantitative results, or error bars, it is not possible to verify the strength of support for these claims.
Authors: We acknowledge the need for greater transparency. The revised Results section will include detailed methodology, data statistics, tables with quantitative results, and error bars from repeated runs to allow verification of the observations on synthetic input overestimation and batch-size dependent draft lengths. revision: yes
Circularity Check
No circularity: benchmark introduction relies on curation choices and integrations, not derived predictions
full rationale
The paper presents SPEED-Bench as a new evaluation suite with curated data splits and production-engine integrations. No equations, fitted parameters, or first-principles derivations appear in the manuscript. The qualitative split is introduced via an explicit curation decision (prioritizing semantic diversity), which is an input rather than a result derived from the benchmark itself. Throughput splits and vLLM/TensorRT-LLM integrations are described as engineering contributions without self-referential reduction. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked to justify core claims. The work is therefore self-contained as an empirical benchmark release.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The qualitative data split selected by prioritizing semantic diversity across samples is representative of real-world semantic domains and workloads
Forward citations
Cited by 1 Pith paper
-
PSD: Pushing the Pareto Frontier of Diffusion LLMs via Parallel Speculative Decoding
PSD is a training-free framework that jointly optimizes spatial unmasking and temporal speculative decoding in diffusion LLMs to reach up to 5.5x tokens per forward pass while preserving accuracy comparable to greedy ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.