Recognition: unknown
Beyond Monologue: Interactive Talking-Listening Avatar Generation with Conversational Audio Context-Aware Kernels
Pith reviewed 2026-05-10 15:11 UTC · model grok-4.3
The pith
A multi-head Gaussian kernel bridges the temporal scale gap between talking and listening to enable full-duplex interactive avatars.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
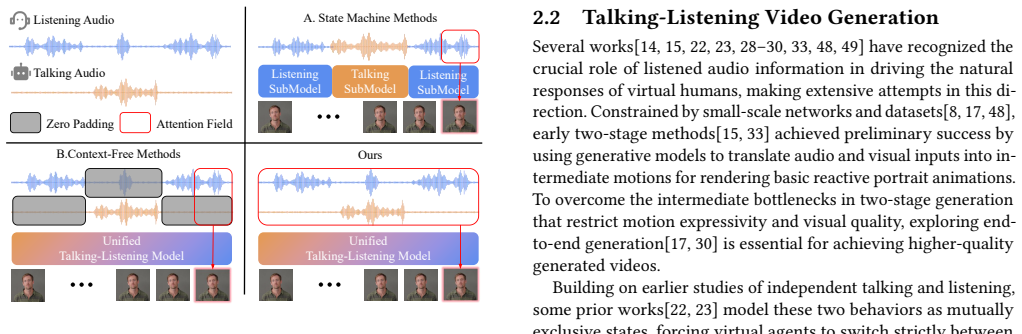
Recognizing the unique temporal scale discrepancy between talking and listening behaviors, we introduce a multi-head Gaussian kernel to explicitly inject this physical intuition into the model as a progressive temporal inductive bias. Building upon this, we construct a full-duplex interactive virtual agent capable of simultaneously processing dual-stream audio inputs for both talking and listening. Furthermore, we introduce a rigorously cleaned Talking-Listening dataset VoxHear featuring perfectly decoupled speech and background audio tracks. Extensive experiments demonstrate that our approach successfully fuses strong temporal alignment with deep contextual semantics.
What carries the argument
multi-head Gaussian kernel that supplies progressive temporal inductive bias to capture the scale discrepancy between short-term talking alignment and longer-range listening context
If this is right
- The same dual-stream audio processing supports simultaneous talking and listening without separate modules.
- The kernel bias lets the model keep precise short-term alignment while still using longer conversational context.
- A cleaned dataset with decoupled speech and background tracks becomes usable for training interactive agents.
- The resulting avatars achieve higher naturalness and responsiveness than prior monologue extensions.
Where Pith is reading between the lines
- Similar scale-aware kernels could be tested on other mismatched-timing generation tasks such as gesture or facial expression synthesis during dialogue.
- The success of an explicit physical bias over generic attention suggests that domain-specific temporal priors may reduce compute in real-time conversational systems.
- Deploying the model on live user audio streams would test whether the inductive bias holds without retraining on every new speaker.
Load-bearing premise
Frame-by-frame alignment makes listening responses rigid while global attention destroys lip synchronization, and the Gaussian kernel resolves the mismatch without new artifacts or full attention.
What would settle it
Side-by-side evaluation on extended live conversations in which the kernel model shows no measurable gain in lip-sync accuracy or naturalness ratings compared with strong frame-alignment or attention baselines.
Figures






read the original abstract
Audio-driven human video generation has achieved remarkable success in monologue scenarios, largely driven by advancements in powerful video generation foundation models. Moving beyond monologues, authentic human communication is inherently a full-duplex interactive process, requiring virtual agents not only to articulate their own speech but also to react naturally to incoming conversational audio. Most existing methods simply extend conventional audio-driven paradigms to listening scenarios. However, relying on strict frame-to-frame alignment renders the model's response to long-range conversational dynamics rigid, whereas directly introducing global attention catastrophically degrades lip synchronization. Recognizing the unique temporal Scale Discrepancy between talking and listening behaviors, we introduce a multi-head Gaussian kernel to explicitly inject this physical intuition into the model as a progressive temporal inductive bias. Building upon this, we construct a full-duplex interactive virtual agent capable of simultaneously processing dual-stream audio inputs for both talking and listening. Furthermore, we introduce a rigorously cleaned Talking-Listening dataset VoxHear featuring perfectly decoupled speech and background audio tracks. Extensive experiments demonstrate that our approach successfully fuses strong temporal alignment with deep contextual semantics, setting a new state-of-the-art for generating highly natural and responsive full-duplex interactive digital humans. The project page is available at https://warmcongee.github.io/beyond-monologue/ .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to advance audio-driven avatar generation beyond monologues to full-duplex interactive scenarios. It introduces a multi-head Gaussian kernel to inject physical intuition about the temporal scale discrepancy between talking and listening as a progressive inductive bias, enabling simultaneous dual-stream audio processing. The work also presents the cleaned VoxHear dataset with decoupled speech and background tracks, and asserts via extensive experiments that the approach fuses strong temporal alignment with contextual semantics to achieve SOTA natural and responsive interactive digital humans.
Significance. If validated, the work could meaningfully advance interactive virtual agent generation by addressing rigidity in frame-to-frame alignment and degradation from global attention through an explicit temporal-scale kernel. The VoxHear dataset with perfectly decoupled tracks is a concrete positive contribution that could support future full-duplex research.
major comments (3)
- Abstract: The central SOTA claim for fusing temporal alignment with deep contextual semantics and generating highly natural full-duplex avatars is asserted without any quantitative metrics, baselines, ablation results, or error analysis, leaving the claim unsupported in the provided text.
- Method (multi-head Gaussian kernel description): The claim that the kernel resolves the temporal scale discrepancy via progressive inductive bias without new artifacts rests on untested premises; no derivation of effective temporal support, parameter sensitivity analysis, or ablation isolating the kernel from dual-stream audio processing is supplied, which is load-bearing for the responsiveness and naturalness assertions.
- Experiments section (implied by abstract): Absence of details on how the kernel's scales/variances were set, specific lip-synchronization or naturalness metrics, or comparisons against strict frame-to-frame and global-attention baselines prevents verification that the kernel outperforms alternatives on the VoxHear dataset.
minor comments (1)
- Abstract: The project page link is a helpful addition for supplementary materials.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights opportunities to strengthen the presentation of our claims and technical details. We address each major comment below and will incorporate revisions to improve clarity and support for the assertions.
read point-by-point responses
-
Referee: Abstract: The central SOTA claim for fusing temporal alignment with deep contextual semantics and generating highly natural full-duplex avatars is asserted without any quantitative metrics, baselines, ablation results, or error analysis, leaving the claim unsupported in the provided text.
Authors: The abstract serves as a high-level summary of the contributions and results. The full manuscript provides quantitative metrics, baseline comparisons, ablations, and error analysis in the Experiments section, demonstrating SOTA performance on the VoxHear dataset. To better support the claim within the abstract itself, we will revise it to include key quantitative highlights such as specific improvements in lip synchronization and naturalness scores. revision: yes
-
Referee: Method (multi-head Gaussian kernel description): The claim that the kernel resolves the temporal scale discrepancy via progressive inductive bias without new artifacts rests on untested premises; no derivation of effective temporal support, parameter sensitivity analysis, or ablation isolating the kernel from dual-stream audio processing is supplied, which is load-bearing for the responsiveness and naturalness assertions.
Authors: The multi-head Gaussian kernel is formulated in Section 3.2 to inject the temporal scale discrepancy as an inductive bias, with different heads applying variances suited to short-term talking alignment versus longer-range listening context. While the design rationale is explained, we agree that additional supporting analysis is warranted. In the revised manuscript, we will add a derivation of the effective temporal support, a parameter sensitivity analysis on the variances, and an ablation isolating the kernel from the dual-stream processing. revision: yes
-
Referee: Experiments section (implied by abstract): Absence of details on how the kernel's scales/variances were set, specific lip-synchronization or naturalness metrics, or comparisons against strict frame-to-frame and global-attention baselines prevents verification that the kernel outperforms alternatives on the VoxHear dataset.
Authors: The Experiments section details evaluations on the VoxHear dataset using lip-synchronization metrics (such as LSE-C and LSE-D) and naturalness via user studies, with comparisons to existing methods. The kernel variances were set via empirical tuning aligned to conversational temporal scales. To enhance verifiability, we will explicitly report the selected variance values, expand metric descriptions, and include direct quantitative comparisons to strict frame-to-frame and global-attention baselines. revision: yes
Circularity Check
No circularity: kernel introduced as explicit inductive bias from stated intuition
full rationale
The paper claims to recognize a temporal scale discrepancy between talking and listening, then introduces a multi-head Gaussian kernel to inject that intuition as progressive temporal inductive bias. This architectural choice is presented as a direct modeling decision rather than a fitted parameter, self-referential definition, or result derived from the target outputs. No equations, self-citations, or steps are shown that would make the claimed fusion of alignment and context equivalent to the inputs by construction. The subsequent claims rest on empirical results with the VoxHear dataset and baseline comparisons, keeping the derivation chain self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- multi-head Gaussian kernel scales/variances
axioms (1)
- domain assumption Talking and listening behaviors exhibit a unique temporal scale discrepancy that standard attention mechanisms cannot handle without degrading lip sync.
Reference graph
Works this paper leans on
-
[1]
Vasu Agrawal, Akinniyi Akinyemi, Kathryn Alvero, Morteza Behrooz, Julia Buffalini, Fabio Maria Carlucci, Joy Chen, Junming Chen, Zhang Chen, Shiyang Cheng, et al. 2025. Seamless interaction: Dyadic audiovisual motion modeling and large-scale dataset.arXiv preprint arXiv:2506.22554(2025)
-
[2]
Lele Chen, Zhiheng Li, Ross K Maddox, Zhiyao Duan, and Chenliang Xu. 2018. Lip movements generation at a glance. InProceedings of the European conference on computer vision (ECCV). 520–535
2018
-
[3]
Zhiyuan Chen, Jiajiong Cao, Zhiquan Chen, Yuming Li, and Chenguang Ma. 2025. Echomimic: Lifelike audio-driven portrait animations through editable landmark conditions. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 2403–2410
2025
- [4]
-
[5]
Jiahao Cui, Hui Li, Yun Zhan, Hanlin Shang, Kaihui Cheng, Yuqi Ma, Shan Mu, Hang Zhou, Jingdong Wang, and Siyu Zhu. 2025. Hallo3: Highly dynamic and 8 realistic portrait image animation with video diffusion transformer. InProceedings of the Computer Vision and Pattern Recognition Conference. 21086–21095
2025
-
[6]
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. 2019. Arcface: Additive angular margin loss for deep face recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 4690–4699
2019
- [7]
-
[8]
Scott Geng, Revant Teotia, Purva Tendulkar, Sachit Menon, and Carl Vondrick
- [9]
-
[10]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. 2017. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems30 (2017)
2017
-
[11]
Jonathan Ho and Tim Salimans. 2022. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. 2024. VBench: Comprehensive Benchmark Suite for Video Generative Models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
2024
-
[13]
Youngjoon Jang, Ji-Hoon Kim, Junseok Ahn, Doyeop Kwak, Hong-Sun Yang, Yoon-Cheol Ju, Il-Hwan Kim, Byeong-Yeol Kim, and Joon Son Chung. 2024. Faces that speak: Jointly synthesising talking face and speech from text. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8818– 8828
2024
-
[14]
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le
-
[15]
Flow matching for generative modeling.arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Jin Liu, Xi Wang, Xiaomeng Fu, Yesheng Chai, Cai Yu, Jiao Dai, and Jizhong Han. 2023. Mfr-net: Multi-faceted responsive listening head generation via denoising diffusion model. InProceedings of the 31st ACM international conference on multimedia. 6734–6743
2023
-
[17]
Xi Liu, Ying Guo, Cheng Zhen, Tong Li, Yingying Ao, and Pengfei Yan. 2024. Customlistener: Text-guided responsive interaction for user-friendly listening head generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2415–2424
2024
- [18]
- [19]
-
[20]
Yifeng Ma, Suzhen Wang, Zhipeng Hu, Changjie Fan, Tangjie Lv, Yu Ding, Zhidong Deng, and Xin Yu. 2023. StyleTalk: one-shot talking head generation with controllable speaking styles. InProceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence and Thirteenth...
- [21]
-
[22]
Rang Meng, Yan Wang, Weipeng Wu, Ruobing Zheng, Yuming Li, and Chenguang Ma. 2026. Echomimicv3: 1.3 b parameters are all you need for unified multi- modal and multi-task human animation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 8008–8015
2026
-
[23]
Niranjan D Narvekar and Lina J Karam. 2011. A no-reference image blur metric based on the cumulative probability of blur detection (CPBD).IEEE Transactions on Image Processing20, 9 (2011), 2678–2683
2011
-
[24]
Evonne Ng, Hanbyul Joo, Liwen Hu, Hao Li, Trevor Darrell, Angjoo Kanazawa, and Shiry Ginosar. 2022. Learning to listen: Modeling non-deterministic dyadic facial motion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 20395–20405
2022
-
[25]
Evonne Ng, Sanjay Subramanian, Dan Klein, Angjoo Kanazawa, Trevor Darrell, and Shiry Ginosar. 2023. Can language models learn to listen?. InProceedings of the IEEE/CVF International Conference on Computer Vision. 10083–10093
2023
-
[26]
William Peebles and Saining Xie. 2023. Scalable diffusion models with transform- ers. InProceedings of the IEEE/CVF international conference on computer vision. 4195–4205
2023
-
[27]
Ziqiao Peng, Wentao Hu, Yue Shi, Xiangyu Zhu, Xiaomei Zhang, Hao Zhao, Jun He, Hongyan Liu, and Zhaoxin Fan. 2024. Synctalk: The devil is in the synchro- nization for talking head synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 666–676
2024
-
[28]
Ofir Press, Noah A Smith, and Mike Lewis. 2021. Train short, test long: At- tention with linear biases enables input length extrapolation.arXiv preprint arXiv:2108.12409(2021)
work page internal anchor Pith review arXiv 2021
-
[29]
Ivan Skorokhodov, Sergey Tulyakov, and Mohamed Elhoseiny. 2022. Stylegan- v: A continuous video generator with the price, image quality and perks of stylegan2. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 3626–3636
2022
-
[30]
Luchuan Song, Guojun Yin, Zhenchao Jin, Xiaoyi Dong, and Chenliang Xu. 2023. Emotional listener portrait: Realistic listener motion simulation in conversation. In2023 IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 20782–20792
2023
-
[31]
Siyang Song, Micol Spitale, Cheng Luo, Cristina Palmero, German Barquero, Hengde Zhu, Sergio Escalera, Michel Valstar, Tobias Baur, Fabien Ringeval, et al
-
[32]
In2024 IEEE 18th International Conference on Automatic Face and Gesture Recognition (FG)
React 2024: the second multiple appropriate facial reaction generation challenge. In2024 IEEE 18th International Conference on Automatic Face and Gesture Recognition (FG). IEEE, 1–5
2024
- [33]
-
[34]
Shuai Tan, Bin Ji, and Ye Pan. 2024. Flowvqtalker: High-quality emotional talking face generation through normalizing flow and quantization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 26317–26327
2024
-
[35]
Linrui Tian, Qi Wang, Bang Zhang, and Liefeng Bo. 2024. Emo: Emote portrait alive generating expressive portrait videos with audio2video diffusion model under weak conditions. InEuropean Conference on Computer Vision. Springer, 244–260
2024
-
[36]
Minh Tran, Di Chang, Maksim Siniukov, and Mohammad Soleymani. 2024. Dim: Dyadic interaction modeling for social behavior generation. InEuropean Confer- ence on Computer Vision. Springer, 484–503
2024
- [37]
-
[38]
Thomas Unterthiner, Sjoerd van Steenkiste, Karol Kurach, Raphaël Marinier, Marcin Michalski, and Sylvain Gelly. 2019. FVD: A new metric for video genera- tion. (2019)
2019
-
[39]
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. 2025. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Haotian Wang, Yuzhe Weng, Jun Du, Haoran Xu, Xiaoyan Wu, Shan He, Bing Yin, Cong Liu, Jianqing Gao, and Qingfeng Liu. 2026. Read: Real-time and efficient asynchronous diffusion for audio-driven talking head generation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 9766–9774
2026
-
[41]
Haotian Wang, Yuzhe Weng, Yueyan Li, Zilu Guo, Jun Du, Shutong Niu, Jiefeng Ma, Shan He, Xiaoyan Wu, Qiming Hu, Bing Yin, Cong Liu, and Qingfeng Liu. 2025. EmotiveTalk: Expressive Talking Head Generation through Audio Information Decoupling and Emotional Video Diffusion. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashvill...
-
[42]
Kaisiyuan Wang, Qianyi Wu, Linsen Song, Zhuoqian Yang, Wayne Wu, Chen Qian, Ran He, Yu Qiao, and Chen Change Loy. 2020. MEAD: A Large-scale Audio-visual Dataset for Emotional Talking-face Generation. InECCV
2020
-
[43]
Mengchao Wang, Qiang Wang, Fan Jiang, Yaqi Fan, Yunpeng Zhang, Yonggang Qi, Kun Zhao, and Mu Xu. 2025. Fantasytalking: Realistic talking portrait generation via coherent motion synthesis. InProceedings of the 33rd ACM International Conference on Multimedia. 9891–9900
2025
- [44]
- [45]
-
[46]
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang
-
[47]
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. InCVPR
- [48]
-
[49]
Zhimeng Zhang, Lincheng Li, Yu Ding, and Changjie Fan. 2021. Flow-guided one-shot talking face generation with a high-resolution audio-visual dataset. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 3661–3670
2021
-
[50]
Shengkui Zhao, Yukun Ma, Chongjia Ni, Chong Zhang, Hao Wang, Trung Hieu Nguyen, Kun Zhou, Jia Qi Yip, Dianwen Ng, and Bin Ma. 2024. Mossformer2: Combining transformer and rnn-free recurrent network for enhanced time- domain monaural speech separation. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEE...
2024
- [51]
-
[52]
Mohan Zhou, Yalong Bai, Wei Zhang, Ting Yao, Tiejun Zhao, and Tao Mei. 2022. Responsive listening head generation: a benchmark dataset and baseline. In European conference on computer vision. Springer, 124–142
2022
-
[53]
Yongming Zhu, Longhao Zhang, Zhengkun Rong, Tianshu Hu, Shuang Liang, and Zhipeng Ge. 2025. INFP: Audio-driven interactive head generation in dyadic conversations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10667–10677. 10
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.