Recognition: unknown
From Perception to Planning: Evolving Ego-Centric Task-Oriented Spatiotemporal Reasoning via Curriculum Learning
Pith reviewed 2026-05-10 16:30 UTC · model grok-4.3
The pith
EgoTSR curriculum evolves vision-language models from spatial perception to long-horizon planning, removing chronological biases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
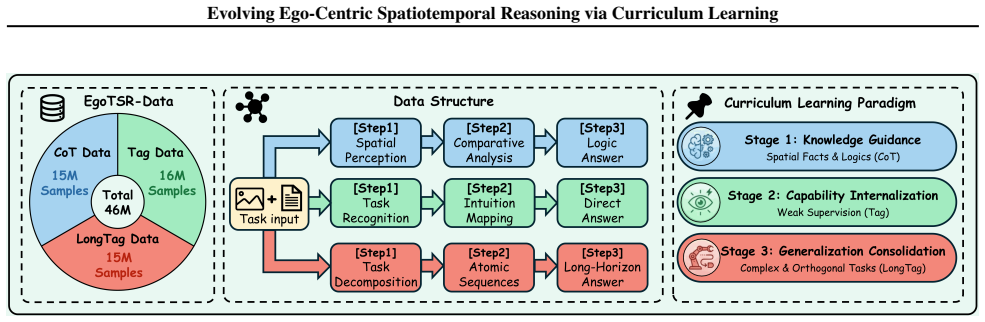
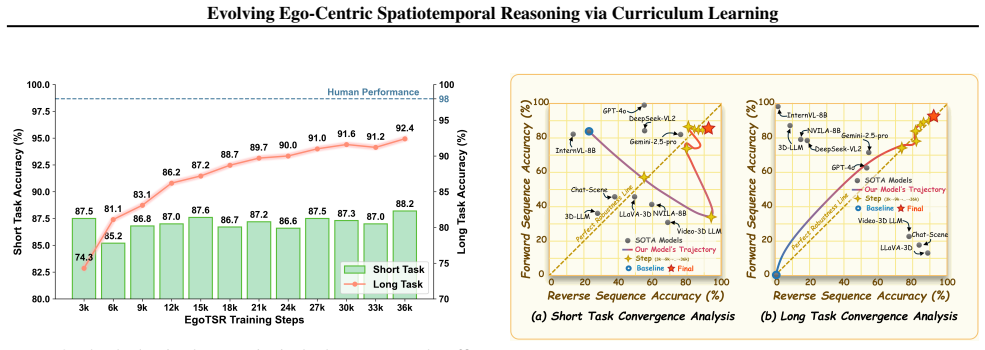
EgoTSR is a curriculum-based framework that teaches task-oriented spatiotemporal reasoning by progressing from explicit spatial understanding with Chain-of-Thought supervision, through weakly supervised task-state tagging, to long-horizon sequence planning on the EgoTSR-Data dataset of 46 million samples. This staged approach eliminates reliance on chronological priors acquired from passive video, yielding 92.4 percent accuracy on long-horizon logical reasoning tasks while retaining high perceptual precision and outperforming existing open- and closed-source models.
What carries the argument
The three-stage curriculum that advances egocentric reasoning from spatial perception to internalized task-state assessment to long-horizon planning.
If this is right
- Models reach 92.4 percent accuracy on long-horizon logical reasoning tasks.
- Performance remains high on fine-grained perceptual tasks while reasoning improves.
- The approach outperforms both open-source and closed-source state-of-the-art models.
- Generalization improves in dynamic, embodied environments by avoiding passive temporal priors.
Where Pith is reading between the lines
- Similar staged curricula could reduce order biases in other multimodal models trained on internet-scale video.
- Robotics applications may gain safer long-term planning by adopting this perception-to-planning progression.
- The method suggests synthetic data pipelines can target specific reasoning deficits that real-world video alone cannot fix.
Load-bearing premise
The constructed EgoTSR-Data dataset and its three-stage organization accurately reflect the intended progression from spatial understanding to planning without introducing new biases during data creation.
What would settle it
Test the trained model on egocentric video inputs whose event order has been deliberately randomized or reversed and measure whether accuracy on long-horizon reasoning drops sharply.
Figures





read the original abstract
Modern vision-language models achieve strong performance in static perception, but remain limited in the complex spatiotemporal reasoning required for embodied, egocentric tasks. A major source of failure is their reliance on temporal priors learned from passive video data, which often leads to spatiotemporal hallucinations and poor generalization in dynamic environments. To address this, we present EgoTSR, a curriculum-based framework for learning task-oriented spatiotemporal reasoning. EgoTSR is built on the premise that embodied reasoning should evolve from explicit spatial understanding to internalized task-state assessment and finally to long-horizon planning. To support this paradigm, we construct EgoTSR-Data, a large-scale dataset comprising 46 million samples organized into three stages: Chain-of-Thought (CoT) supervision, weakly supervised tagging, and long-horizon sequences. Extensive experiments demonstrate that EgoTSR effectively eliminates chronological biases, achieving 92.4% accuracy on long-horizon logical reasoning tasks while maintaining high fine-grained perceptual precision, significantly outperforming existing open-source and closed-source state-of-the-art models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EgoTSR, a curriculum-based framework for egocentric spatiotemporal reasoning in vision-language models. It constructs a 46-million-sample dataset (EgoTSR-Data) organized into three stages—Chain-of-Thought supervision, weakly supervised tagging, and long-horizon sequences—with the central claim that this progression eliminates chronological biases from passive video data, yielding 92.4% accuracy on long-horizon logical reasoning tasks while preserving fine-grained perceptual precision and outperforming both open- and closed-source state-of-the-art models.
Significance. If the performance claims prove robust, the work would meaningfully advance embodied AI by offering a structured curriculum to move models from explicit spatial perception to internalized planning, directly targeting a documented failure mode of temporal hallucinations in VLMs. The scale of the proposed dataset and the explicit three-stage design provide a concrete, testable path for bias mitigation that could influence future training paradigms for task-oriented agents.
major comments (3)
- [Abstract] Abstract: the claim that EgoTSR 'effectively eliminates chronological biases' is presented without any description of the bias quantification metric, the procedure used to measure residual temporal priors, or the statistical test confirming elimination; this is load-bearing for the central contribution.
- [Dataset Construction] Dataset section: the construction details for the 46M-sample EgoTSR-Data (including the rule-based or model-based synthesis of long-horizon sequences and weak tags) are absent, creating a circularity risk that reported gains reflect synthetic artifacts (e.g., action-order statistics or object-persistence patterns) rather than genuine reasoning improvements.
- [Experiments] Experiments section: no information is supplied on evaluation protocols, baseline re-implementations, train/test splits that control for chronological leakage, or statistical significance testing of the 92.4% accuracy figure, rendering the quantitative superiority claim impossible to assess from the manuscript.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments correctly identify areas where the manuscript requires greater transparency and elaboration to support its central claims. We address each point below and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that EgoTSR 'effectively eliminates chronological biases' is presented without any description of the bias quantification metric, the procedure used to measure residual temporal priors, or the statistical test confirming elimination; this is load-bearing for the central contribution.
Authors: We agree that the abstract claim requires explicit supporting methodology to be fully substantiated. The manuscript's experimental section demonstrates reduced reliance on temporal order through controlled comparisons, but we acknowledge the absence of a dedicated quantification procedure and statistical test in the original text. In the revised manuscript we have added a new subsection (4.3) that defines the chronological bias score as the relative accuracy drop on temporally shuffled test sequences, describes the shuffling procedure, and reports bootstrap-based significance testing (1000 resamples). The abstract has been updated to reference this evaluation protocol. revision: yes
-
Referee: [Dataset Construction] Dataset section: the construction details for the 46M-sample EgoTSR-Data (including the rule-based or model-based synthesis of long-horizon sequences and weak tags) are absent, creating a circularity risk that reported gains reflect synthetic artifacts (e.g., action-order statistics or object-persistence patterns) rather than genuine reasoning improvements.
Authors: We accept that the original dataset section provided only an overview and omitted the precise synthesis rules, thereby leaving open the possibility of artifact-driven results. The revised manuscript expands Section 3 with full construction details: long-horizon sequences are generated via a rule-based task-graph engine that samples from a library of egocentric action templates with enforced diversity in ordering and object co-occurrence; weak tags are produced by a frozen VLM followed by automated consistency filtering and manual verification on a 5% subset. Pseudocode, prompt templates, and dataset statistics are now included to permit reproduction and to demonstrate that performance gains exceed what could be explained by simple order or persistence statistics alone. revision: yes
-
Referee: [Experiments] Experiments section: no information is supplied on evaluation protocols, baseline re-implementations, train/test splits that control for chronological leakage, or statistical significance testing of the 92.4% accuracy figure, rendering the quantitative superiority claim impossible to assess from the manuscript.
Authors: We agree that the experimental reporting was incomplete and prevents independent verification. The revised version adds a dedicated evaluation subsection (4.1) that specifies: (i) train/test splits performed at the video-ID level to eliminate chronological leakage, (ii) re-implementation details and hyperparameter search for all baselines, (iii) the exact prompting and decoding settings used for closed-source models, and (iv) statistical testing of the 92.4% result via five independent runs with reported mean, standard deviation, and two-tailed t-test p-values against the strongest baseline. These additions make the superiority claim fully assessable. revision: yes
Circularity Check
No circularity in the derivation chain.
full rationale
The paper describes an empirical curriculum-learning framework (three stages on a constructed 46M-sample dataset) whose central claims are performance numbers on long-horizon tasks. No equations, self-definitional reductions, fitted-parameter-as-prediction steps, or load-bearing self-citations appear in the provided text that would make any claimed result equivalent to its inputs by construction. The progression from spatial understanding to planning is presented as a training paradigm supported by data construction, not as a mathematical derivation that collapses tautologically. This is the normal case of an applied ML paper whose results remain falsifiable on external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
EgoTSR three-stage curriculum
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Ahn, M., Brohan, A., Brown, N., Chebotar, Y ., Cortes, O., David, B., Finn, C., Fu, C., Gopalakrishnan, K., Hausman, K., et al. Do as i can, not as i say: Grounding language in robotic affordances.arXiv preprint arXiv:2204.01691,
work page internal anchor Pith review arXiv
-
[2]
Rearrangement: A challenge for embodied ai.arXiv preprint arXiv:2011.01975, 2020
Batra, D., Chang, A. X., Chernova, S., Davison, A. J., Deng, J., Koltun, V ., Levine, S., Malik, J., Mordatch, I., Mot- taghi, R., et al. Rearrangement: A challenge for embodied ai.arXiv preprint arXiv:2011.01975,
-
[4]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
doi: 10.48550. arXiv preprint ARXIV .2410.24164. Floridi, L. and Chiriatti, M. Gpt-3: Its nature, scope, limits, and consequences.Minds and machines, 30(4):681–694,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Mobile ALOHA: Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation
Fu, Z., Zhao, T. Z., and Finn, C. Mobile aloha: Learning bimanual mobile manipulation with low-cost whole-body teleoperation.arXiv preprint arXiv:2401.02117,
work page internal anchor Pith review arXiv
-
[6]
Toward General-Purpose Robots via Foundation Mod- els: A Survey and Meta-Analysis,
Hu, Y ., Xie, Q., Jain, V ., Francis, J., Patrikar, J., Keetha, N., Kim, S., Xie, Y ., Zhang, T., Fang, H.-S., et al. Toward general-purpose robots via foundation models: A survey and meta-analysis.arXiv preprint arXiv:2312.08782,
-
[7]
Inner Monologue: Embodied Reasoning through Planning with Language Models
Huang, W., Xia, F., Xiao, T., Chan, H., Liang, J., Florence, P., Zeng, A., Tompson, J., Mordatch, I., Chebotar, Y ., et al. Inner monologue: Embodied reasoning through planning with language models.arXiv preprint arXiv:2207.05608,
work page internal anchor Pith review arXiv
-
[8]
Kung, C.-H., Ramirez, F., Ha, J., Chen, Y .-T., Crandall, D., and Tsai, Y .-H. What changed and what could have changed? state-change counterfactuals for procedure- aware video representation learning.arXiv preprint arXiv:2503.21055,
-
[9]
Reward design with language models.arXiv preprint arXiv:2303.00001, 2023
Kwon, M., Xie, S. M., Bullard, K., and Sadigh, D. Re- ward design with language models.arXiv preprint arXiv:2303.00001,
-
[10]
SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension
Li, B., Wang, R., Wang, G., Ge, Y ., Ge, Y ., and Shan, Y . Seed-bench: Benchmarking multimodal llms with gener- ative comprehension.arXiv preprint arXiv:2307.16125, 2023a. Li, H., Yang, S., Chen, Y ., Tian, Y ., Yang, X., Chen, X., Wang, H., Wang, T., Zhao, F., Lin, D., et al. Cronusvla: Transferring latent motion across time for multi-frame prediction i...
work page internal anchor Pith review arXiv
-
[11]
Evaluating Object Hallucination in Large Vision-Language Models
Li, Y ., Du, Y ., Zhou, K., Wang, J., Zhao, W. X., and Wen, J.-R. Evaluating object hallucination in large vision- language models.arXiv preprint arXiv:2305.10355, 2023b. Li, Z. and Hoiem, D. Learning without forgetting.IEEE transactions on pattern analysis and machine intelligence, 40(12):2935–2947,
work page internal anchor Pith review arXiv
-
[12]
Tempcompass: Do video llms really understand videos?,
Liu, B., Zhu, Y ., Gao, C., Feng, Y ., Liu, Q., Zhu, Y ., and Stone, P. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023a. Liu, H., Li, C., Wu, Q., and Lee, Y . J. Visual instruction tun- ing.Advances in neural information processing systems, 36:34892–34916, 2023b. ...
-
[13]
Lu, X., Chen, Z., Hu, X., Zhou, Y ., Zhang, W., Liu, D., Sheng, L., and Shao, J. Is-bench: Evaluating interactive safety of vlm-driven embodied agents in daily household tasks.arXiv preprint arXiv:2506.16402,
-
[14]
Eureka: Human-Level Reward Design via Coding Large Language Models
Ma, Y . J., Liang, W., Wang, G., Huang, D.-A., Bastani, O., Jayaraman, D., Zhu, Y ., Fan, L., and Anandkumar, A. Eureka: Human-level reward design via coding large lan- guage models.arXiv preprint arXiv:2310.12931,
work page internal anchor Pith review arXiv
-
[15]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Shridhar, M., Yuan, X., C ˆot´e, M.-A., Bisk, Y ., Trischler, A., and Hausknecht, M. Alfworld: Aligning text and embodied environments for interactive learning.arXiv preprint arXiv:2010.03768,
work page internal anchor Pith review arXiv 2010
-
[16]
Gemini: A Family of Highly Capable Multimodal Models
Team, G., Anil, R., Borgeaud, S., Alayrac, J.-B., Yu, J., Sori- cut, R., Schalkwyk, J., Dai, A. M., Hauth, A., Millican, K., et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Time Blindness: Why Video-Language Models Can't See What Humans Can?
10 Evolving Ego-Centric Spatiotemporal Reasoning via Curriculum Learning Upadhyay, U., Ranjan, M., Shen, Z., and Elhoseiny, M. Time blindness: Why video-language models can’t see what humans can?arXiv preprint arXiv:2505.24867,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Large language models still can’t plan (a bench- mark for llms on planning and reasoning about change)
Valmeekam, K., Olmo, A., Sreedharan, S., and Kambham- pati, S. Large language models still can’t plan (a bench- mark for llms on planning and reasoning about change). InNeurIPS 2022 Foundation Models for Decision Mak- ing Workshop,
2022
-
[19]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Wang, G., Xie, Y ., Jiang, Y ., Mandlekar, A., Xiao, C., Zhu, Y ., Fan, L., and Anandkumar, A. V oyager: An open- ended embodied agent with large language models.arXiv preprint arXiv:2305.16291,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Multimodal chain-of-thought reasoning: A comprehensive survey.arXiv preprint arXiv:2503.12605, 2025
Wang, Y ., Wu, S., Zhang, Y ., Yan, S., Liu, Z., Luo, J., and Fei, H. Multimodal chain-of-thought reasoning: A comprehensive survey.arXiv preprint arXiv:2503.12605,
-
[21]
Xu, B., Wang, Z., Du, Y ., Song, Z., Zheng, S., and Jin, Q. Do egocentric video-language models truly understand hand- object interactions?arXiv preprint arXiv:2405.17719,
-
[22]
Yang, S., Li, H., Chen, Y ., Wang, B., Tian, Y ., Wang, T., Wang, H., Zhao, F., Liao, Y ., and Pang, J. In- structvla: Vision-language-action instruction tuning from understanding to manipulation.arXiv preprint arXiv:2507.17520,
-
[23]
Multimodal Chain-of-Thought Reasoning in Language Models
Zhang, Z., Zhang, A., Li, M., Zhao, H., Karypis, G., and Smola, A. Multimodal chain-of-thought reasoning in lan- guage models.arXiv preprint arXiv:2302.00923,
work page internal anchor Pith review arXiv
-
[24]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Zhou, D., Sch ¨arli, N., Hou, L., Wei, J., Scales, N., Wang, X., Schuurmans, D., Cui, C., Bousquet, O., Le, Q., et al. Least-to-most prompting enables complex reasoning in large language models.arXiv preprint arXiv:2205.10625,
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.