AOP-Smart: A RAG-Enhanced Large Language Model Framework for Adverse Outcome Pathway Analysis
Pith reviewed 2026-05-10 16:33 UTC · model grok-4.3
The pith
A retrieval-augmented system called AOP-Smart lifts large language model accuracy on adverse outcome pathway tasks from under 35 percent to 95-100 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By feeding user questions to an LLM together with retrieved excerpts from AOP-Wiki XML records on key events and their relationships, the AOP-Smart framework produces answers whose accuracy on identification, upstream-downstream, and complex retrieval tasks matches or exceeds human-curated references.
What carries the argument
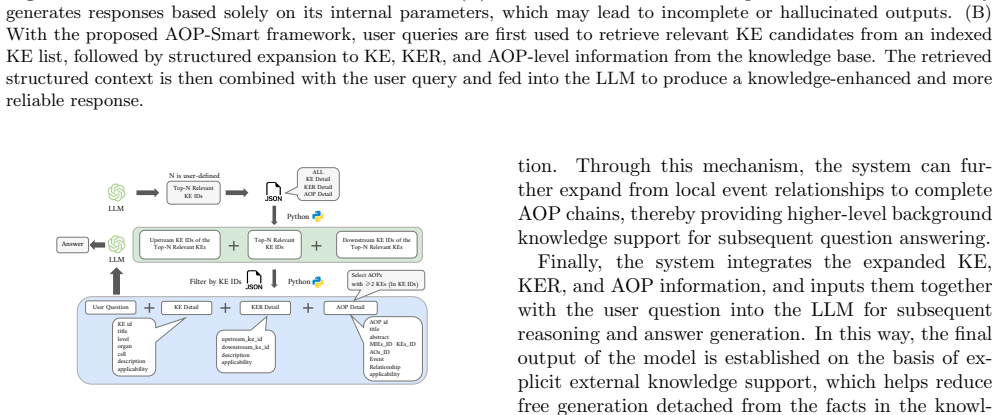
Retrieval-Augmented Generation pipeline that selects and injects relevant Key Events, Key Event Relationships, and AOP metadata from the AOP-Wiki XML corpus before the language model generates its response.
If this is right
- Complex AOP retrieval tasks that currently require manual literature searches can be automated at high reliability.
- Hallucination rates in LLM outputs on toxicology knowledge drop sharply once official pathway data are retrieved and supplied.
- The same retrieval pattern can be applied to any domain whose knowledge is stored in structured XML or ontology formats.
- Downstream applications such as automated AOP network construction or regulatory report drafting become more feasible.
Where Pith is reading between the lines
- If the accuracy gains hold on larger and more diverse question sets, AOP-Smart could serve as a first-pass tool that toxicologists then verify rather than a replacement for expert curation.
- The approach suggests a general template for reducing LLM errors in any scientific field that maintains a public, machine-readable knowledge base.
- Testing the framework on questions that cross multiple AOPs or that require inference across pathways would reveal whether the current retrieval scope is sufficient.
Load-bearing premise
The authors' 20-question test set represents typical real-world AOP tasks and that correctness was judged without bias or post-selection adjustments.
What would settle it
An independently assembled collection of at least 100 AOP questions on which the RAG-enhanced models fall below 80 percent accuracy or on which the unaugmented models match or exceed the reported scores.
Figures


read the original abstract
Adverse Outcome Pathways (AOPs) are an important knowledge framework in toxicological research and risk assessment. In recent years, large language models (LLMs) have gradually been applied to AOP-related question answering and mechanistic reasoning tasks. However, due to the existence of the hallucination problem, that is, the model may generate content that is inconsistent with facts or lacks evidence, their reliability is still limited. To address this issue, this study proposes an AOP-oriented Retrieval-Augmented Generation (RAG) framework, AOP-Smart. Based on the official XML data from AOP-Wiki, this method uses Key Events (KEs), Key Event Relationships (KERs), and specific AOP information to retrieve relevant knowledge for user questions, thereby improving the reliability of the generated results of large language models. To evaluate the effectiveness of the proposed method, this study constructed a test set containing 20 AOP-related question answering tasks, covering KE identification, upstream and downstream KE retrieval, and complex AOP retrieval tasks. Experiments were conducted on three mainstream large language models, Gemini, DeepSeek, and ChatGPT, and comparative tests were performed under two settings: without RAG and with RAG. The experimental results show that, without using RAG, the accuracies of GPT, DeepSeek, and Gemini were 15.0\%, 35.0\%, and 20.0\%, respectively; after using RAG, their accuracies increased to 95.0\%, 100.0\%, and 95.0\%, respectively. The results indicate that AOP-Smart can significantly alleviate the hallucination problem of large language models in AOP knowledge tasks, and greatly improve the accuracy and consistency of their answers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AOP-Smart, a retrieval-augmented generation (RAG) framework that retrieves Key Events (KEs), Key Event Relationships (KERs), and AOP information from AOP-Wiki XML data to ground large language model responses for AOP-related question answering. It evaluates the framework on three LLMs (GPT, DeepSeek, Gemini) using a custom test set of 20 AOP tasks covering KE identification, upstream/downstream KE retrieval, and complex AOP retrieval, reporting accuracy gains from 15.0%/35.0%/20.0% (no RAG) to 95.0%/100.0%/95.0% (with RAG) and concluding that the approach significantly alleviates hallucination.
Significance. If the reported gains are shown to generalize, AOP-Smart would provide a practical, domain-specific RAG pipeline for improving LLM reliability in toxicological mechanistic reasoning. The direct grounding in official AOP-Wiki XML is a clear methodological strength, and the magnitude of the before/after delta on structured knowledge tasks suggests RAG can be particularly effective here. The work is timely given growing interest in LLMs for regulatory science.
major comments (2)
- [Evaluation section] Evaluation section (test set construction and results): The central empirical claim rests on accuracy improvements observed on an author-constructed set of only 20 questions, yet the manuscript provides no sampling protocol, diversity metrics, question sourcing details, or inter-annotator agreement for correctness judgments. This directly affects the load-bearing assertion that the method 'significantly alleviate[s] the hallucination problem,' as the observed delta cannot be distinguished from performance on a narrow, potentially favorable subset without these controls.
- [Results] Results paragraph and Table (implied by the reported percentages): No error analysis, breakdown of remaining 5% errors after RAG, or comparison against standard (non-AOP-specific) RAG baselines is presented. Without these, it is unclear whether the gains are attributable to the AOP-oriented retrieval design or simply to any retrieval augmentation on this particular test distribution.
minor comments (2)
- [Abstract] The abstract and method description could more explicitly note the small scale and custom nature of the test set as a limitation when claiming broad alleviation of hallucinations.
- [Experiments] Notation for the three LLMs (GPT, DeepSeek, Gemini) is used inconsistently with the full model names in the results; clarifying the exact versions would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The concerns regarding the evaluation methodology are important, and we address each major comment below with our responses and planned revisions.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section (test set construction and results): The central empirical claim rests on accuracy improvements observed on an author-constructed set of only 20 questions, yet the manuscript provides no sampling protocol, diversity metrics, question sourcing details, or inter-annotator agreement for correctness judgments. This directly affects the load-bearing assertion that the method 'significantly alleviate[s] the hallucination problem,' as the observed delta cannot be distinguished from performance on a narrow, potentially favorable subset without these controls.
Authors: We acknowledge that the manuscript provides only a high-level description of the 20-task test set and omits detailed information on its construction. The tasks were selected to span the categories of KE identification, upstream/downstream retrieval, and complex AOP retrieval using content from AOP-Wiki. To address this concern, we will revise the Evaluation section to include a more explicit account of question sourcing, selection criteria, and how ground-truth correctness was determined by reference to the official XML data. These additions will improve transparency without altering the reported results. revision: yes
-
Referee: [Results] Results paragraph and Table (implied by the reported percentages): No error analysis, breakdown of remaining 5% errors after RAG, or comparison against standard (non-AOP-specific) RAG baselines is presented. Without these, it is unclear whether the gains are attributable to the AOP-oriented retrieval design or simply to any retrieval augmentation on this particular test distribution.
Authors: We agree that the absence of error analysis and baseline comparisons limits interpretation of the results. In the revised manuscript we will add a short error analysis describing the nature of the residual errors after RAG. A quantitative comparison to generic RAG was not performed in the original work because the retrieval component is deliberately specialized to the AOP-Wiki XML schema and KE/KER structure; however, we will expand the discussion to explain this design choice and its expected advantages over off-the-shelf RAG. If space and resources allow, we will also include a minimal generic-RAG baseline for the same test set. revision: partial
Circularity Check
No significant circularity; empirical accuracy gains are measured outcomes on an external benchmark
full rationale
The paper describes a standard RAG pipeline over AOP-Wiki XML data and reports direct before/after accuracy measurements on a 20-question test set. No equations, fitted parameters, or derivations are present that could reduce results to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The evaluation, while limited by the small author-constructed set, consists of observable accuracy deltas rather than tautological restatements, satisfying the criteria for a self-contained empirical claim.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Retrieval from official AOP-Wiki XML using KEs, KERs, and AOP metadata will provide accurate and sufficient context to suppress LLM hallucinations on AOP tasks
Reference graph
Works this paper leans on
-
[1]
Gerald T. Ankley, Richard S. Bennett, Rus- sell J. Erickson, Dale J. Hoff, Michael W. Hor- nung, Rodney D. Johnson, David R. Mount, John W. Nichols, Christine L. Russom, Patricia K. 5 Schmieder, Jose A. Serrrano, Joseph E. Tietge, and Daniel L. Villeneuve. Adverse outcome path- ways: A conceptual framework to support eco- toxicology research and risk asse...
work page 2009
-
[2]
Anna Bal-Price and M.E. (Bette) Meek. Adverse outcome pathways: Application to enhance mech- anistic understanding of neurotoxicity.Pharmacol- ogy & Therapeutics, 179:84–95, November 2017
work page 2017
-
[3]
Florence Jornod, Thomas Jaylet, Ludek Blaha, Denis Sarigiannis, Luc Tamisier, and Karine Au- douze. Aop-helpfinder webserver: a tool for com- prehensive analysis of the literature to support ad- verse outcome pathways development.Bioinfor- matics, 38(4):1173–1175, October 2021
work page 2021
-
[4]
Saurav Kumar, Deepika Deepika, Karin Slater, and Vikas Kumar. Aopwiki-explorer: An in- teractive graph-based query engine leveraging large language models.Computational Toxicology, 30:100308, June 2024
work page 2024
-
[5]
Attention is all you need.Advances in neural information pro- cessing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information pro- cessing systems, 30, 2017
work page 2017
-
[6]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhari- wal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural infor- mation processing systems, 33:1877–1901, 2020
work page 1901
-
[7]
Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. Biobert: a pre-trained biomedical language representation model for biomedical text mining.Bioinformatics, 36(4):1234–1240, Septem- ber 2019
work page 2019
-
[8]
Haochun Shi and Yanbin Zhao. Integration of ad- vanced large language models into the construction of adverse outcome pathways: Opportunities and challenges.Environmental Science & Technology, 58(35):15355–15358, August 2024
work page 2024
-
[9]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, An- drea Madotto, and Pascale Fung. Survey of hal- lucination in natural language generation.ACM Computing Surveys, 55(12):1–38, March 2023
work page 2023
-
[10]
Truthfulqa: Measuring how models mimic human falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods. InProceedings of the 60th annual meet- ing of the association for computational linguistics (volume 1: long papers), pages 3214–3252, 2022
work page 2022
-
[11]
Patrick Lewis, Ethan Perez, Aleksandra Pik- tus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K¨ uttler, Mike Lewis, Wen-tau Yih, Tim Rockt¨ aschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Ad- vances in neural information processing systems, 33:9459–9474, 2020
work page 2020
-
[12]
Reading wikipedia to answer open- domain questions
Danqi Chen, Adam Fisch, Jason Weston, and An- toine Bordes. Reading wikipedia to answer open- domain questions. InProceedings of the 55th Annual Meeting of the Association forComputa- tional Linguistics (Volume 1: Long Papers), page 1870–1879. Association for Computational Lin- guistics, 2017
work page 2017
-
[13]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InProceed- ings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 6769–6781, 2020. 6
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.