Recognition: unknown
Relax: An Asynchronous Reinforcement Learning Engine for Omni-Modal Post-Training at Scale
Pith reviewed 2026-05-10 16:01 UTC · model grok-4.3
The pith
Decoupling RL roles into independent services and a tunable-staleness TransferQueue delivers up to 2x faster omni-modal post-training while matching on-policy rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
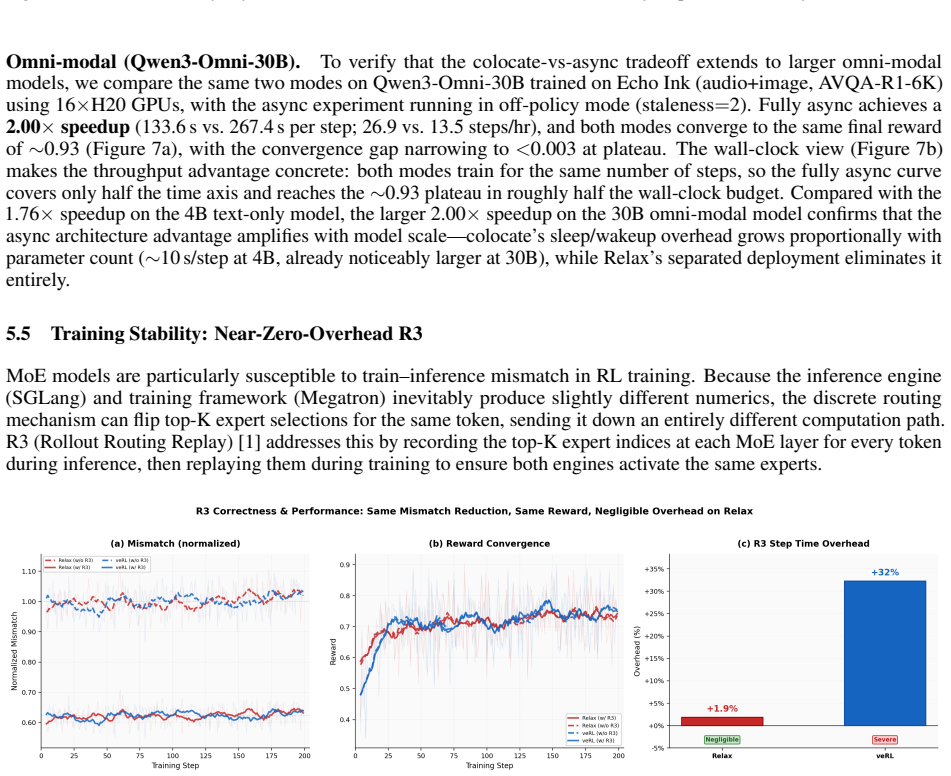
Relax implements an omni-native architecture that embeds multimodal support across data preprocessing, parallelism, and generation; runs every RL role as an independent, recoverable service; and routes data through a TransferQueue that lets a single staleness value interpolate between fully on-policy and fully asynchronous execution. On Qwen3-4B this yields a 1.20× end-to-end speedup over veRL in on-policy mode and 1.76× in fully async mode; on the 30B omni-modal model the async mode reaches 2.00× over colocate while all three modes converge to identical reward curves. The same system supports R3 replay for MoE models at 1.9 % overhead and sustains stable training for more than 2,000 steps 0
What carries the argument
The TransferQueue data bus, which decouples independent RL services so that a single staleness parameter controls the degree of asynchrony while preserving end-to-end learning dynamics.
If this is right
- On-policy, near-on-policy, and fully async modes all reach the same final reward on the tested models.
- Fully async execution yields 1.76× speedup on 4B and 2.00× on 30B omni-modal models compared with colocated baselines.
- R3 routing for MoE models incurs only 1.9 % overhead instead of the 32 % degradation seen in prior engines.
- Stable convergence holds across image, text, audio, and video inputs for at least 2,000 steps.
Where Pith is reading between the lines
- The same service decoupling could simplify adding new input modalities or swapping individual components without restarting the entire training run.
- Tuning the single staleness parameter might offer a practical knob for trading compute efficiency against sample quality on tasks not yet tested.
- The approach may reduce the hardware specialization needed for large-scale RL by improving utilization on existing clusters.
Load-bearing premise
The architectural separation of services and the TransferQueue preserve the same reward convergence that synchronous on-policy training would achieve.
What would settle it
Training the identical Qwen3-Omni-30B workload in fully async mode and observing a lower final reward than the on-policy baseline after the same number of steps would falsify the claim.
Figures









read the original abstract
Reinforcement learning (RL) post-training has proven effective at unlocking reasoning, self-reflection, and tool-use capabilities in large language models. As models extend to omni-modal inputs and agentic multi-turn workflows, RL training systems face three interdependent challenges: heterogeneous data flows, operational robustness at scale, and the staleness -- throughput tradeoff. We present \textbf{Relax} (Reinforcement Engine Leveraging Agentic X-modality), an open-source RL training engine that addresses these challenges through three co-designed architectural layers. First, an \emph{omni-native architecture} builds multimodal support into the full stack -- from data preprocessing and modality-aware parallelism to inference generation -- rather than retrofitting it onto a text-centric pipeline. Second, each RL role runs as an independent, fault-isolated service that can be scaled, recovered, and upgraded without global coordination. Third, service-level decoupling enables asynchronous training via the TransferQueue data bus, where a single staleness parameter smoothly interpolates among on-policy, near-on-policy, and fully asynchronous execution. Relax achieves a 1.20$\times$ end-to-end speedup over veRL on Qwen3-4B on-policy training. Its fully async mode delivers a 1.76$\times$ speedup over colocate on Qwen3-4B and a 2.00$\times$ speedup on Qwen3-Omni-30B, while all modes converge to the same reward level. Relax supports R3 (Rollout Routing Replay)~\cite{ma2025r3} for MoE models with only 1.9\% overhead, compared to 32\% degradation in veRL under the same configuration. It further demonstrates stable omni-modal RL convergence on Qwen3-Omni across image, text, and audio, sustaining over 2{,}000 steps on video without degradation. Relax is available at https://github.com/rednote-ai/Relax.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Relax, an open-source asynchronous RL training engine for omni-modal post-training of LLMs. It describes an omni-native architecture with modality-aware parallelism, independent fault-isolated services for RL roles, and a TransferQueue data bus controlled by a single staleness parameter that interpolates between on-policy, near-on-policy, and fully asynchronous modes. Central empirical claims include a 1.20× end-to-end speedup over veRL on Qwen3-4B on-policy training, 1.76× and 2.00× speedups in fully async mode on Qwen3-4B and Qwen3-Omni-30B, equivalent final reward levels across modes, 1.9% overhead for R3 on MoE models (vs. 32% degradation in veRL), and stable convergence over 2,000 steps on video data across image/text/audio modalities.
Significance. If the results are robust, the work offers a practical engineering contribution for scaling RL post-training to large omni-modal and MoE models by decoupling throughput from staleness without apparent performance loss. The open-source release, explicit support for R3, and demonstration of long-horizon video stability are concrete strengths that could aid reproducibility and adoption. The design addresses real operational challenges in heterogeneous data flows and fault tolerance at scale.
major comments (3)
- [Experimental Evaluation] Abstract and Experimental Evaluation: The headline claim that on-policy, near-on-policy, and fully-async modes all converge to identical reward levels is load-bearing for the architectural contribution, yet no training curves, per-seed variance, or statistical tests are shown. Without these, it is impossible to verify that the single staleness parameter in TransferQueue produces updates whose effective data distribution and gradient bias remain sufficiently close to on-policy.
- [Abstract] Performance claims in Abstract: The specific speedups (1.20× over veRL, 1.76× and 2.00× for async) and overhead numbers (1.9% for R3) are presented without error bars, number of independent runs, hardware configuration details, or baseline implementation notes. These quantitative results are central to the paper's value proposition but cannot be assessed for robustness or reproducibility from the given information.
- [Omni-Modal and MoE Experiments] Omni-modal and MoE sections: The assertion of stable omni-modal RL over 2,000 steps on video and low-overhead R3 support lacks ablations on how modality-aware parallelism or MoE routing interacts with the async TransferQueue, or any observed failure modes. This is required to substantiate that the decoupling preserves dynamics across the tested configurations.
minor comments (2)
- [Related Work] The citation for R3 (ma2025r3) is referenced but the integration details and differences from the original R3 implementation could be clarified in the methods or related work to aid readers.
- [Figures] Ensure all figures (if present) for reward curves or speedup breakdowns include clear legends distinguishing the three execution modes and any variance indicators.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We agree that strengthening the experimental evaluation with additional visualizations, statistics, and ablations will improve the robustness and reproducibility of our claims. We address each major comment below and commit to the corresponding revisions.
read point-by-point responses
-
Referee: [Experimental Evaluation] Abstract and Experimental Evaluation: The headline claim that on-policy, near-on-policy, and fully-async modes all converge to identical reward levels is load-bearing for the architectural contribution, yet no training curves, per-seed variance, or statistical tests are shown. Without these, it is impossible to verify that the single staleness parameter in TransferQueue produces updates whose effective data distribution and gradient bias remain sufficiently close to on-policy.
Authors: We agree that the submitted manuscript does not include training curves, per-seed variance, or statistical tests for the convergence claim. In the revised version we will add reward curves for on-policy, near-on-policy, and fully-async modes across multiple seeds (N=3) with standard-deviation bands. We will also report statistical tests (paired t-tests on final rewards) confirming no significant difference. On the data-distribution concern, the TransferQueue staleness parameter explicitly bounds maximum sample age; we will add a short analysis of observed sample-age histograms to show that gradient bias remains negligible within the tested range, supporting the architectural claim while acknowledging the need for the requested evidence. revision: yes
-
Referee: [Abstract] Performance claims in Abstract: The specific speedups (1.20× over veRL, 1.76× and 2.00× for async) and overhead numbers (1.9% for R3) are presented without error bars, number of independent runs, hardware configuration details, or baseline implementation notes. These quantitative results are central to the paper's value proposition but cannot be assessed for robustness or reproducibility from the given information.
Authors: We acknowledge that the abstract and experimental sections lack error bars, run counts, hardware details, and baseline notes. We will revise both the abstract and main text to report mean speedups and overheads with standard deviations from N=3 independent runs, specify the exact hardware configuration (e.g., 8×H100 cluster with interconnect details), and document the precise veRL version and configuration flags used. These additions will directly address reproducibility concerns. revision: yes
-
Referee: [Omni-Modal and MoE Experiments] Omni-modal and MoE sections: The assertion of stable omni-modal RL over 2,000 steps on video and low-overhead R3 support lacks ablations on how modality-aware parallelism or MoE routing interacts with the async TransferQueue, or any observed failure modes. This is required to substantiate that the decoupling preserves dynamics across the tested configurations.
Authors: We agree that the current sections would benefit from targeted ablations. In revision we will add experiments that vary the staleness parameter while measuring per-modality throughput and routing statistics under modality-aware parallelism. For MoE models we will include routing-frequency histograms under async versus on-policy settings. Our 2,000-step video runs exhibited no degradation or failure modes; we will explicitly report this observation and any edge cases considered (e.g., extreme modality imbalance). These additions will substantiate that the TransferQueue decoupling preserves training dynamics. revision: yes
Circularity Check
No circularity: results are empirical benchmarks against external baselines
full rationale
The paper presents an engineering system (Relax) with architectural choices for async RL and omni-modal support, then reports measured speedups (1.20× over veRL, 1.76×/2.00× for async modes) and convergence to equivalent rewards across modes. These outcomes are obtained by running the implemented system on Qwen3 models and comparing against independent external systems (veRL, colocate). No equations, fitted parameters, or first-principles derivations are claimed; the single staleness parameter is a configurable design knob whose effects are validated empirically rather than derived by construction. Self-citations (e.g., to R3) are peripheral and not load-bearing for the core speedup or convergence claims. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
MinT: Managed Infrastructure for Training and Serving Millions of LLMs
MinT enables efficient management of million-scale LoRA-adapted LLM policies over shared 1T-parameter base models by moving only small adapters through training and serving pipelines.
Reference graph
Works this paper leans on
-
[1]
Wenhan Ma, Hailin Zhang, Liang Zhao, Yifan Song, Yudong Wang, Zhifang Sui, and Fuli Luo. Stabilizing MoE reinforcement learning by aligning training and inference routers.arXiv preprint arXiv:2510.11370, 2025. Proposed Rollout Routing Replay (R3): records inference-time routing distributions and replays them during training to stabilize MoE RL
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. Demonstrated that pure RL can incentivize emergent reasoning (self-reflection, verification) in LLMs with...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017. Introduced PPO, a simple and effective policy gradient method with clipped surrogate objectives for stable RL training
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y .K. Li, Y . Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. Introduced Group Relative Policy Optimization (GRPO), a memory-efficient variant of PPO for mathemati...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. DAPO: An open-source LLM reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025. Proposed Decoupled Clip and Dynamic Sampling Policy Optimization (DAPO), achieving 50 points on AIME 2024 with Qwen2.5-32B. ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. HybridFlow: A flexible and efficient RLHF framework.arXiv preprint arXiv:2409.19256, 2024. Proposed veRL/HybridFlow: hybrid single-/multi-controller paradigm for RLHF with 3D-HybridEngine for actor resharding, achieving 1.53x–20.57x throughpu...
work page internal anchor Pith review arXiv 2024
-
[7]
OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework
Jian Hu, Xibin Wu, Wei Shen, Jason Klein Liu, Zilin Zhu, Weixun Wang, Songlin Jiang, Haoran Wang, Hao Chen, Bin Chen, et al. OpenRLHF: An easy-to-use, scalable and high-performance RLHF framework.arXiv preprint arXiv:2405.11143, 2024. Open-source RLHF/RLVR framework built on Ray, vLLM, DeepSpeed, and HuggingFace Transformers, achieving 1.22x–1.68x speedup...
work page internal anchor Pith review arXiv 2024
-
[8]
AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning
Wei Fu, Jiaxuan Gao, Xujie Shen, Chen Zhu, Zhiyu Mei, Chuyi He, Shusheng Xu, Guo Wei, Jun Mei, Jiashu Wang, Tongkai Yang, Binhang Yuan, and Yi Wu. AReaL: A large-scale asynchronous reinforcement learning system for language reasoning.arXiv preprint arXiv:2505.24298, 2025. Fully asynchronous RL system decoupling generation from training with staleness-enha...
work page internal anchor Pith review arXiv 2025
-
[9]
Zhenyu Han, Ansheng You, Haibo Wang, Kui Luo, Guang Yang, Wenqi Shi, Menglong Chen, Sicheng Zhang, Zeshun Lan, Chunshi Deng, Huazhong Ji, Wenjie Liu, Yu Huang, Yixiang Zhang, Chenyi Pan, Jing Wang, Xin Huang, Chunsheng Li, and Jianping Wu. AsyncFlow: An asynchronous streaming RL framework for efficient LLM post-training.arXiv preprint arXiv:2507.01663, 20...
-
[10]
Weixun Wang, Shaopan Xiong, Gengru Chen, Wei Gao, Sheng Guo, Yancheng He, Ju Huang, Jiaheng Liu, Zhendong Li, Xiaoyang Li, Zichen Liu, Haizhou Zhao, et al. Reinforcement learning optimization for large-scale learning: An efficient and user-friendly scaling library.arXiv preprint arXiv:2506.06122, 2025
-
[11]
Hao Zhang, Mingjie Liu, Shaokun Zhang, Songyang Han, Jian Hu, Zhenghui Jin, Yuchi Zhang, Shizhe Diao, Ximing Lu, Binfeng Xu, Zhiding Yu, Jan Kautz, and Yi Dong. ProRL Agent: Rollout-as-a-service for RL training of multi-turn LLM agents.arXiv preprint arXiv:2603.18815, 2026. NVIDIA NeMo Gym: rollout-as-a-service infrastructure for multi-turn agentic RL tra...
-
[12]
slime: An llm post-training framework for rl scaling
Zilin Zhu, Chengxing Xie, Xin Lv, and slime Contributors. slime: An llm post-training framework for rl scaling. https://github.com/THUDM/slime, 2025. GitHub repository
2025
-
[13]
Philipp Moritz, Robert Nishihara, Stephanie Wang, Alexey Tumanov, Richard Liaw, Eric Liang, Melih Elibol, Zongheng Yang, William Paul, Michael I. Jordan, and Ion Stoica. Ray: A distributed framework for emerging AI applications.arXiv preprint arXiv:1712.05889, 2018. Distributed computing framework for AI with task-parallel and actor-based abstractions, wi...
-
[14]
Brown, Miljan Martic, Shane Legg, and Dario Amodei
Paul F. Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences.arXiv preprint arXiv:1706.03741, 2017. Pioneering work on learning reward functions from human preferences to guide RL agents
-
[15]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback....
work page internal anchor Pith review arXiv 2022
-
[16]
Towards Reasoning Era: A Survey of Long Chain-of-Thought for Reasoning Large Language Models
Zhangyue Chen et al. A survey of reasoning with foundation models: Towards complex and long chain-of-thought reasoning.arXiv preprint arXiv:2503.09567, 2025. Comprehensive survey on long and complex chain-of-thought reasoning with foundation models
work page internal anchor Pith review arXiv 2025
-
[17]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-LM: Training multi-billion parameter language models using model parallelism.arXiv preprint arXiv:1909.08053, 2019. Introduced efficient intra-layer tensor model parallelism for training multi-billion parameter transformers, sustaining 15.1 PetaFLO...
work page internal anchor Pith review arXiv 1909
-
[18]
SGLang: Efficient Execution of Structured Language Model Programs
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. SGLang: Efficient execution of structured language model programs.arXiv preprint arXiv:2312.07104, 2023. LLM inference system with RadixAttention for KV cache reuse and compressed F...
work page internal anchor Pith review arXiv 2023
-
[19]
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, Alban Desmaison, Can Balioglu, Pritam Damania, Bernard Nguyen, Geeta Chauhan, Yuchen Hao, Ajit Mathews, and Shen Li. PyTorch FSDP: Experiences on scaling fully sharded data parallel.arXiv preprint arXiv:2304.11277, 2023. Industr...
work page internal anchor Pith review arXiv 2023
-
[20]
Inference-time scaling for generalist reward modeling, 2025
Zijun Liu, Peiyi Wang, Runxin Xu, Shirong Ma, Chong Ruan, Peng Li, Yang Liu, and Yu Wu. Inference-time scaling for generalist reward modeling.arXiv preprint arXiv:2504.02495, 2025. DeepSeek-GRM: Self-Principled Critique Tuning (SPCT) for scalable generalist reward modeling via online RL with inference-time scaling
-
[21]
Zhenghao Xing, Xiaowei Hu, Chi-Wing Fu, Wenhai Wang, Jifeng Dai, and Pheng-Ann Heng. EchoInk-R1: Ex- ploring audio-visual reasoning in multimodal LLMs via reinforcement learning.arXiv preprint arXiv:2505.04623,
-
[22]
Audio-visual reasoning via RL with A VQA-R1-6K dataset; trained Qwen2.5-Omni-7B using GRPO. 14 APREPRINT- APRIL15, 2026 A Discussion A.1 Design Trade-offs The role of colocate mode.Although the fully asynchronous (off-policy) mode delivers the highest throughput in our experiments, colocate mode remains a practical choice when the GPU budget is limited. B...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.