Representations Before Pixels: Semantics-Guided Hierarchical Video Prediction
Pith reviewed 2026-05-10 16:26 UTC · model grok-4.3
The pith
Predicting scene semantics in feature space before generating pixels improves video forecast consistency and efficiency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Re2Pix decomposes forecasting into semantic representation prediction followed by representation-guided visual synthesis. A frozen foundation model supplies the semantic features that are autoregressively forecasted in feature space; a latent diffusion model then renders frames conditioned on those predictions. Nested dropout and mixed supervision are introduced to make the diffusion stage robust to imperfect autoregressive inputs at test time.
What carries the argument
The two-stage hierarchical pipeline that forecasts semantic features from a frozen vision model before conditioning latent diffusion synthesis on them, using nested dropout and mixed supervision to handle train-test mismatch.
If this is right
- The semantics-first design yields higher temporal semantic consistency than direct diffusion baselines on driving data.
- Perceptual quality of generated frames increases while training becomes more efficient.
- The method is effective for complex dynamic scenes such as those encountered in autonomous driving.
- Conditioning strategies allow the diffusion stage to tolerate errors in the upstream semantic predictions.
Where Pith is reading between the lines
- The decomposition implies that pre-trained semantic models can offload structural reasoning from pixel-level generators in other video tasks.
- Similar staging could be tested in non-driving domains where scene consistency matters more than immediate visual detail.
- If foundation-model features prove stable across domains, the need for end-to-end retraining on every new video dataset may decrease.
Load-bearing premise
The frozen vision foundation model yields sufficiently rich and stable semantic representations, and the nested dropout plus mixed supervision strategies close the train-test gap without creating new artifacts.
What would settle it
On a standard driving benchmark, replace the semantic prediction stage with direct pixel diffusion and measure whether temporal semantic consistency and perceptual quality drop below the reported Re2Pix numbers.
Figures


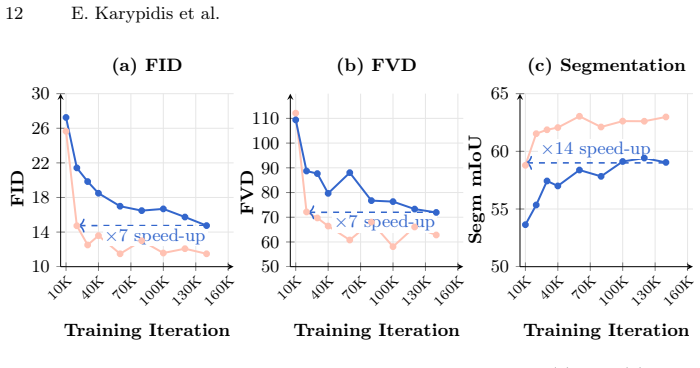
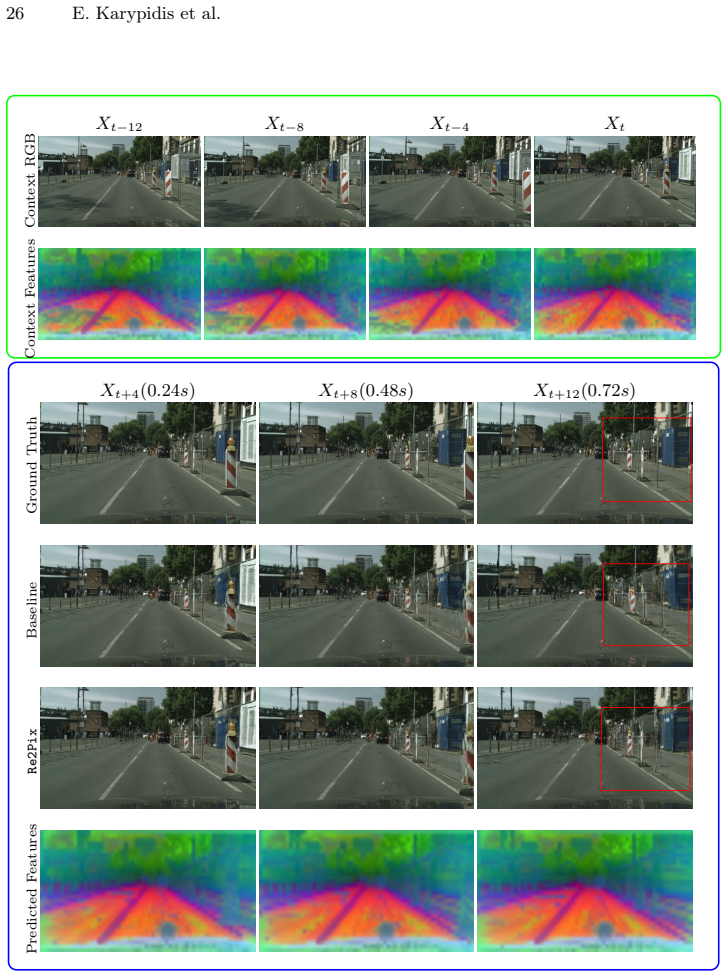



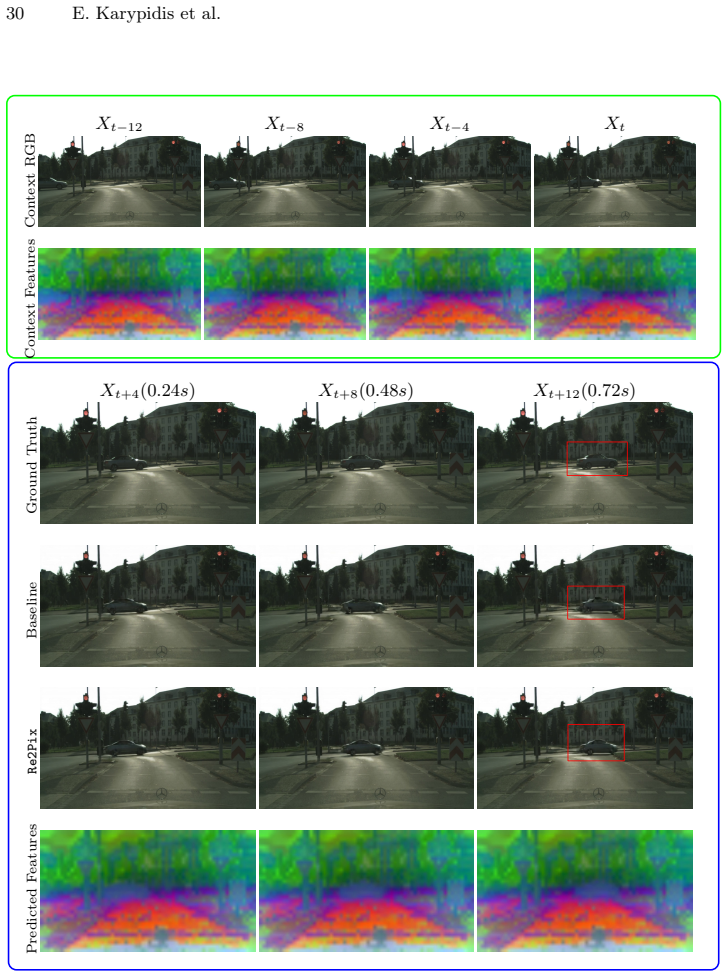
read the original abstract
Accurate future video prediction requires both high visual fidelity and consistent scene semantics, particularly in complex dynamic environments such as autonomous driving. We present Re2Pix, a hierarchical video prediction framework that decomposes forecasting into two stages: semantic representation prediction and representation-guided visual synthesis. Instead of directly predicting future RGB frames, our approach first forecasts future scene structure in the feature space of a frozen vision foundation model, and then conditions a latent diffusion model on these predicted representations to render photorealistic frames. This decomposition enables the model to focus first on scene dynamics and then on appearance generation. A key challenge arises from the train-test mismatch between ground-truth representations available during training and predicted ones used at inference. To address this, we introduce two conditioning strategies, nested dropout and mixed supervision, that improve robustness to imperfect autoregressive predictions. Experiments on challenging driving benchmarks demonstrate that the proposed semantics-first design significantly improves temporal semantic consistency, perceptual quality, and training efficiency compared to strong diffusion baselines. We provide the implementation code at https://github.com/Sta8is/Re2Pix
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Re2Pix, a hierarchical video prediction framework that first autoregressively forecasts future scene semantics in the feature space of a frozen vision foundation model, then conditions a latent diffusion model on these predicted representations to synthesize photorealistic frames. Nested dropout and mixed supervision are introduced to mitigate the train-test mismatch between ground-truth and predicted semantics. Experiments on driving benchmarks report gains in temporal semantic consistency, perceptual quality, and training efficiency relative to strong diffusion baselines, with code released.
Significance. If the empirical gains are robust, the semantics-first decomposition offers a structured alternative to direct pixel or latent prediction, with potential benefits for consistency in dynamic scenes. The use of a frozen foundation model and the two conditioning strategies are practical contributions. Open-sourced code is a clear strength for reproducibility. Significance is tempered by the need to verify that gains hold under compounding autoregressive errors beyond short horizons.
major comments (2)
- [§3.3] §3.3 (Nested Dropout and Mixed Supervision): The strategies are motivated by the train-inference semantic shift, but the section provides no ablation or metric (e.g., feature drift measured by cosine similarity or object trajectory consistency) quantifying their effect on error accumulation over multi-step horizons (>8 frames). Without this, it is unclear whether the reported temporal consistency improvements generalize or remain limited to the short-horizon regime tested.
- [§4 and Table 1] §4 (Experiments) and Table 1: The central claim of significantly improved semantic consistency rests on comparisons to diffusion baselines, yet no results or analysis address long-horizon compounding (e.g., 16+ frame predictions) or include variance across multiple random seeds. This leaves open whether the semantics-first advantage persists when predicted representations deviate further from ground truth.
minor comments (3)
- [§1] The abstract and §1 could more explicitly contrast the approach against prior hierarchical or semantic-conditioned video models to clarify the incremental contribution.
- [Figure 4] Figure 4 (qualitative results) would benefit from side-by-side semantic feature visualizations at multiple timesteps to illustrate consistency.
- [Eq. (3)] Notation for the conditioning input to the diffusion model in Eq. (3) or (4) should be defined more clearly with respect to the autoregressive semantic predictor output.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important aspects of evaluating robustness to error accumulation and long-horizon performance, which we address point-by-point below. We plan to incorporate additional analyses in the revised manuscript.
read point-by-point responses
-
Referee: [§3.3] §3.3 (Nested Dropout and Mixed Supervision): The strategies are motivated by the train-inference semantic shift, but the section provides no ablation or metric (e.g., feature drift measured by cosine similarity or object trajectory consistency) quantifying their effect on error accumulation over multi-step horizons (>8 frames). Without this, it is unclear whether the reported temporal consistency improvements generalize or remain limited to the short-horizon regime tested.
Authors: We agree that quantifying the contribution of nested dropout and mixed supervision to reducing error accumulation is valuable for clarifying their role beyond the short-horizon regime. In the revised manuscript, we will add an ablation that reports feature drift (cosine similarity between predicted and ground-truth semantic features) and object trajectory consistency metrics over horizons exceeding 8 frames. This will directly measure how these strategies mitigate the train-test mismatch during autoregressive rollout. revision: yes
-
Referee: [§4 and Table 1] §4 (Experiments) and Table 1: The central claim of significantly improved semantic consistency rests on comparisons to diffusion baselines, yet no results or analysis address long-horizon compounding (e.g., 16+ frame predictions) or include variance across multiple random seeds. This leaves open whether the semantics-first advantage persists when predicted representations deviate further from ground truth.
Authors: We recognize that assessing performance under greater compounding errors at longer horizons (16+ frames) and reporting variance across seeds would more robustly support the semantic consistency claims. While current experiments adhere to standard benchmark protocols with horizons up to 8 frames, the revised version will include extended 16+ frame predictions along with standard deviations over multiple random seeds to evaluate whether the semantics-first decomposition maintains its advantages as predicted representations diverge from ground truth. revision: yes
Circularity Check
No circularity: empirical claims rest on external benchmarks and frozen external models
full rationale
The paper's core contribution is a two-stage architecture (semantic feature prediction followed by conditioned latent diffusion) whose performance gains are demonstrated via direct comparisons to external diffusion baselines on driving datasets. No equations, fitted parameters, or self-citations are shown to reduce the reported improvements in temporal consistency or perceptual quality to quantities defined by the authors' own inputs. The nested dropout and mixed supervision are presented as regularization techniques whose effectiveness is measured empirically rather than derived by construction from the training data itself. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A frozen vision foundation model encodes scene semantics that remain useful when predicted autoregressively.
- domain assumption Latent diffusion models can synthesize photorealistic frames when conditioned on predicted semantic features.
Reference graph
Works this paper leans on
-
[1]
Cosmos World Foundation Model Platform for Physical AI
Agarwal, N., Ali, A., Bala, M., Balaji, Y., Barker, E., Cai, T., Chattopadhyay, P., Chen, Y., Cui, Y., Ding, Y., et al.: Cosmos world foundation model platform for physical ai. arXiv preprint arXiv:2501.03575 (2025) 4, 7, 10, 23
work page internal anchor Pith review arXiv 2025
-
[2]
arXiv preprint arXiv:2503.14492 (2025)
Alhaija, H.A., Alvarez, J., Bala, M., Cai, T., Cao, T., Cha, L., Chen, J., Chen, M., Ferroni, F., Fidler, S., et al.: Cosmos-transfer1: Conditional world generation with adaptive multimodal control. arXiv preprint arXiv:2503.14492 (2025) 4
-
[3]
World Simulation with Video Foundation Models for Physical AI
Ali, A., Bai, J., Bala, M., Balaji, Y., Blakeman, A., Cai, T., Cao, J., Cao, T., Cha, E., Chao, Y.W., et al.: World simulation with video foundation models for physical ai. arXiv preprint arXiv:2511.00062 (2025) 4, 7
work page internal anchor Pith review arXiv 2025
-
[4]
In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vi- sion (WACV)
Arai, H., Miwa, K., Sasaki, K., Watanabe, K., Yamaguchi, Y., Aoki, S., Ya- mamoto, I.: Covla: Comprehensive vision-language-action dataset for autonomous driving. In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vi- sion (WACV). pp. 1933–1943. IEEE (2025) 9, 23
work page 2025
-
[5]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Assran, M., Bardes, A., Fan, D., Garrido, Q., Howes, R., Muckley, M., Rizvi, A., Roberts, C., Sinha, K., Zholus, A., et al.: V-jepa 2: Self-supervised video models enable understanding, prediction and planning. arXiv preprint arXiv:2506.09985 (2025) 4
work page internal anchor Pith review arXiv 2025
-
[6]
Back to the features: Dino as a foundation for video world models, 2025
Baldassarre, F., Szafraniec, M., Terver, B., Khalidov, V., Massa, F., LeCun, Y., Labatut, P., Seitzer, M., Bojanowski, P.: Back to the features: Dino as a foundation for video world models. arXiv preprint arXiv:2507.19468 (2025) 4
-
[7]
Transactions on Machine Learning Research (2024) 4
Bardes, A., Garrido, Q., Ponce, J., Chen, X., Rabbat, M., LeCun, Y., Assran, M., Ballas, N.: Revisiting feature prediction for learning visual representations from video. Transactions on Machine Learning Research (2024) 4
work page 2024
-
[8]
Vavim and vavam: Autonomous driving through video generative modeling
Bartoccioni, F., Ramzi, E., Besnier, V., Venkataramanan, S., Vu, T.H., Xu, Y., Chambon, L., Gidaris, S., Odabas, S., Hurych, D., et al.: Vavim and vavam: Autonomous driving through video generative modeling. arXiv preprint arXiv:2502.15672 (2025) 4
-
[9]
A pytorch reproduction of masked generative image transformer.arXiv preprint arXiv:2310.14400, 2023
Besnier, V., Chen, M.: A pytorch reproduction of masked generative image trans- former. arXiv preprint arXiv:2310.14400 (2023) 24 16 E. Karypidis et al
-
[10]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., et al.: Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127 (2023) 4
work page internal anchor Pith review arXiv 2023
-
[11]
Caesar, H., Bankiti, V., Lang, A.H., Vora, S., Liong, V.E., Xu, Q., Krishnan, A., Pan, Y., Baldan, G., Beijbom, O.: nuscenes: A multimodal dataset for autonomous driving. In: CVPR (2020) 9, 22
work page 2020
-
[12]
Chen, H., Han, Y., Chen, F., Li, X., Wang, Y., Wang, J., Wang, Z., Liu, Z., Zou, D., Raj, B.: Masked autoencoders are effective tokenizers for diffusion models. In: ICML (2025) 5
work page 2025
-
[13]
Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., Schiele, B.: The cityscapes dataset for semantic urban scene understanding. In: CVPR (June 2016) 9, 22
work page 2016
-
[14]
In: International conference on machine learning
Dehghani, M., Djolonga, J., Mustafa, B., Padlewski, P., Heek, J., Gilmer, J., Steiner, A.P., Caron, M., Geirhos, R., Alabdulmohsin, I., et al.: Scaling vision transformers to 22 billion parameters. In: International conference on machine learning. PMLR (2023) 7
work page 2023
-
[15]
Denton, R., Fergus, R.: Stochastic video generation with a learned prior. In: ICML (2018) 4
work page 2018
-
[16]
In: Interna- tional Conference on Learning Representations (2022) 1
Dosovitskiy, A., Koltun, V.: Learning to act by predicting the future. In: Interna- tional Conference on Learning Representations (2022) 1
work page 2022
-
[17]
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: ICML (2024) 7
work page 2024
-
[18]
A survey of world models for autonomous driving,
Feng, T., Wang, W., Yang, Y.: A survey of world models for autonomous driving. arXiv preprint arXiv:2501.11260 (2025) 1
-
[19]
Gao, S., Yang, J., Chen, L., Chitta, K., Qiu, Y., Geiger, A., Zhang, J., Li, H.: Vista: A generalizable driving world model with high fidelity and versatile controllabil- ity. In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024),https://openreview.net/forum?id=Tw9nfNyOMy1, 4, 12
work page 2024
-
[20]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Gao, Z., Tan, C., Wu, L., Li, S.Z.: Simvp: Simpler yet better video prediction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 3170–3180 (June 2022) 4
work page 2022
-
[21]
The international journal of robotics research (2013) 9, 23
Geiger, A., Lenz, P., Stiller, C., Urtasun, R.: Vision meets robotics: The kitti dataset. The international journal of robotics research (2013) 9, 23
work page 2013
-
[22]
IEEE Transactions on Intelligent Vehicles (2024) 1
Guan, Y., Liao, H., Li, Z., Hu, J., Yuan, R., Zhang, G., Xu, C.: World models for autonomous driving: An initial survey. IEEE Transactions on Intelligent Vehicles (2024) 1
work page 2024
-
[23]
In: ICLR (2023),https:/ / openreview.net/forum?id=QAV2CcLEDh4
Gupta, A., Tian, S., Zhang, Y., Wu, J., Martín-Martín, R., Fei-Fei, L.: Maskvit: Masked visual pre-training for video prediction. In: ICLR (2023),https:/ / openreview.net/forum?id=QAV2CcLEDh4
work page 2023
-
[24]
He, K., Gkioxari, G., Dollár, P., Girshick, R.: Mask r-cnn. In: ICCV (2017) 4
work page 2017
-
[25]
He, Y., et al.: Latent video diffusion models for high-fidelity long video generation. arXiv preprint (2022) 4
work page 2022
-
[26]
5: Improved baselines for agglomerative vision foundation models
Heinrich, G., Ranzinger, M., Yin, H., Lu, Y., Kautz, J., Tao, A., Catanzaro, B., Molchanov, P.: Radiov2. 5: Improved baselines for agglomerative vision foundation models. In: CVPR (2025) 24
work page 2025
-
[27]
Heusel,M.,Ramsauer,H.,Unterthiner,T.,Nessler,B.,Hochreiter,S.:Ganstrained by a two time-scale update rule converge to a local nash equilibrium. In: Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, Re2Pix 17 R. (eds.) Advances in Neural Information Processing Systems. vol. 30. Curran Associates, Inc. (2017),https://...
work page 2017
-
[28]
Imagen Video: High Definition Video Generation with Diffusion Models
Ho, J., Chan, W., Saharia, C., Whang, J., Gao, R., Gritsenko, A., Kingma, D.P., Poole, B., Norouzi, M., Fleet, D.J., et al.: Imagen video: High definition video generation with diffusion models. arXiv preprint arXiv:2210.02303 (2022) 1
work page internal anchor Pith review arXiv 2022
-
[29]
Classifier-Free Diffusion Guidance
Ho, J., Salimans, T.: Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598 (2022) 21
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
Ho, J., Salimans, T., Gritsenko, A., Chan, W., Norouzi, M., Fleet, D.J.: Video diffusion models. In: NeurIPS (2022), arXiv:2204.03458 4
work page internal anchor Pith review arXiv 2022
-
[31]
GAIA-1: A Generative World Model for Autonomous Driving
Hu, A., Russell, L., Yeo, H., Murez, Z., Fedoseev, G., Kendall, A., Shotton, J., Corrado, G.: Gaia-1: A generative world model for autonomous driving. arXiv preprint arXiv:2309.17080 (2023) 5
work page internal anchor Pith review arXiv 2023
-
[32]
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. ICLR (2022) 7
work page 2022
-
[33]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2021) 4
Hu, J.F., Sun, J., Lin, Z., Lai, J.H., Zeng, W., Zheng, W.S.: Apanet: Auto-path aggregation for future instance segmentation prediction. IEEE Transactions on Pattern Analysis and Machine Intelligence (2021) 4
work page 2021
-
[34]
arXiv preprint arXiv:2506.09229 (2025) 2, 4, 7, 8
Hwang, S., Jang, H., Kim, K., Park, M., Choo, J.: Cross-frame representation alignment for fine-tuning video diffusion models. arXiv preprint arXiv:2506.09229 (2025) 5
-
[35]
Jin, X., Li, X., Xiao, H., Shen, X., Lin, Z., Yang, J., Chen, Y., Dong, J., Liu, L., Jie, Z., et al.: Video scene parsing with predictive feature learning. In: ICCV (2017) 4
work page 2017
-
[36]
Advances in neural information processing systems35, 26565–26577 (2022) 10, 23
Karras,T.,Aittala,M.,Aila,T.,Laine,S.:Elucidatingthedesignspaceofdiffusion- based generative models. Advances in neural information processing systems35, 26565–26577 (2022) 10, 23
work page 2022
-
[37]
Karras, T., Aittala, M., Kynkäänniemi, T., Lehtinen, J., Aila, T., Laine, S.: Guid- ing a diffusion model with a bad version of itself. NeurIPs (2024) 21
work page 2024
-
[38]
arXiv preprint arXiv:2412.11673 (2024)
Karypidis, E., Kakogeorgiou, I., Gidaris, S., Komodakis, N.: Dino-foresight: Look- ing into the future with dino. arXiv preprint arXiv:2412.11673 (2024) 4, 6, 24
-
[39]
arXiv preprint arXiv:2501.08303 (2025) 4
Karypidis, E., Kakogeorgiou, I., Gidaris, S., Komodakis, N.: Advancing semantic future prediction through multimodal visual sequence transformers. arXiv preprint arXiv:2501.08303 (2025) 4
-
[40]
Kingma, D., Ba, J.: Adam: A method for stochastic optimization. In: ICLR (2015) 10, 24
work page 2015
-
[41]
Kouzelis, T., Kakogeorgiou, I., Gidaris, S., Komodakis, N.: Eq-vae: Equivariance regularized latent space for improved generative image modeling. arXiv preprint arXiv:2502.09509 (2025) 4
-
[42]
Kouzelis, T., Karypidis, E., Kakogeorgiou, I., Gidaris, S., Komodakis, N.: Boosting generative image modeling via joint image-feature synthesis. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025),https:// openreview.net/forum?id=i4qAfV04rZ5
work page 2025
-
[43]
Kusupati, A., Bhatt, G., Rege, A., Wallingford, M., Sinha, A., Ramanujan, V., Howard-Snyder, W., Chen, K., Kakade, S., Jain, P., et al.: Matryoshka represen- tation learning. NeurIPs (2022) 9
work page 2022
-
[44]
Lee, A.X., Zhang, R., Namee, B., et al.: Stochastic adversarial video prediction. In: arXiv preprint (2018) 4
work page 2018
-
[45]
Leng, X., Singh, J., Hou, Y., Xing, Z., Xie, S., Zheng, L.: Repa-e: Unlock- ing vae for end-to-end tuning with latent diffusion transformers. arXiv preprint arXiv:2504.10483 (2025) 5, 11 18 E. Karypidis et al
-
[46]
Li, T., Katabi, D., He, K.: Return of unconditional generation: A self-supervised representation generation method. NeurIPs (2024) 5
work page 2024
-
[47]
Li, X., Qiu, K., Chen, H., Kuen, J., Gu, J., Raj, B., Lin, Z.: Imagefolder: Au- toregressive image generation with folded tokens. arXiv preprint arXiv:2410.01756 (2024) 5
-
[48]
Lin,Z.,Sun,J.,Hu,J.F.,Yu,Q.,Lai,J.H.,Zheng,W.S.:Predictivefeaturelearning for future segmentation prediction. In: CVPR (2021) 4
work page 2021
-
[49]
arXiv preprint arXiv:2007.08509 (2020) 4
Mallya, A., Wang, T.C., Sapra, K., Liu, M.Y.: World-consistent video-to-video synthesis. arXiv preprint arXiv:2007.08509 (2020) 4
-
[50]
Mathieu, M., Couprie, C., LeCun, Y.: Deep multi-scale video prediction beyond mean square error. arXiv preprint (2016) 4
work page 2016
-
[51]
Nabavi, S.S., Rochan, M., Wang, Y.: Future semantic segmentation with convolu- tional lstm. In: BMVC (2018) 4
work page 2018
-
[52]
com / nvidia - cosmos / cosmos - predict2(2025), accessed: 2026-03-05 4, 12
NVIDIA: Cosmos-predict2.https : / / github . com / nvidia - cosmos / cosmos - predict2(2025), accessed: 2026-03-05 4, 12
work page 2025
-
[53]
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez, P., HAZIZA, D., Massa, F., El-Nouby, A., Assran, M., Ballas, N., Galuba, W., Howes, R., Huang, P.Y., Li, S.W., Misra, I., Rabbat, M., Sharma, V., Synnaeve, G., Xu, H., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: DINOv2: Learning robust visual feat...
work page 2024
-
[54]
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: ICCV (2023) 1, 3, 7
work page 2023
-
[55]
Pernias, P., Rampas, D., Richter, M.L., Pal, C.J., Aubreville, M.: Würstchen: An efficient architecture for large-scale text-to-image diffusion models. In: ICLR (2024) 5
work page 2024
-
[56]
Movie Gen: A Cast of Media Foundation Models
Polyak, A., Zohar, A., Brown, A., Tjandra, A., Sinha, A., Lee, A., Vyas, A., Shi, B., Ma, C.Y., Chuang, C.Y., et al.: Movie gen: A cast of media foundation models. arXiv preprint arXiv:2410.13720 (2024) 4
work page internal anchor Pith review arXiv 2024
-
[57]
Ranftl, R., Bochkovskiy, A., Koltun, V.: Vision transformers for dense prediction. In: CVPR (2021) 10, 24
work page 2021
-
[58]
Rippel, O., Gelbart, M., Adams, R.: Learning ordered representations with nested dropout. In: ICML (2014) 9
work page 2014
-
[59]
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: CVPR (2022) 4
work page 2022
-
[60]
GAIA-2: A Controllable Multi-View Generative World Model for Autonomous Driving
Russell, L., Hu, A., Bertoni, L., Fedoseev, G., Shotton, J., Arani, E., Corrado, G.: Gaia-2: A controllable multi-view generative world model for autonomous driving. arXiv preprint arXiv:2503.20523 (2025) 5
work page internal anchor Pith review arXiv 2025
-
[61]
Saric, J., Orsic, M., Antunovic, T., Vrazic, S., Segvic, S.: Warp to the future: Joint forecasting of features and feature motion. In: CVPR (2020) 4
work page 2020
-
[62]
Sarıyıldız, M.B., Weinzaepfel, P., Lucas, T., de Jorge, P., Larlus, D., Kalantidis, Y.: Dune: Distilling a universal encoder from heterogeneous 2d and 3d teachers. In: CVPR (2025) 24
work page 2025
-
[63]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khali- dov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025) 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Strudel, R., Garcia, R., Laptev, I., Schmid, C.: Segmenter: Transformer for seman- tic segmentation. In: CVPR (2021) 4
work page 2021
-
[65]
Neurocomputing (2024) 7 Re2Pix 19
Su, J., Ahmed, M., Lu, Y., Pan, S., Bo, W., Liu, Y.: Roformer: Enhanced trans- former with rotary position embedding. Neurocomputing (2024) 7 Re2Pix 19
work page 2024
-
[66]
In: Proceedings of the 27th ACM International Conference on Multimedia (2019) 4
Sun, J., Xie, J., Hu, J.F., Lin, Z., Lai, J., Zeng, W., Zheng, W.S.: Predicting future instance segmentation with contextual pyramid convlstms. In: Proceedings of the 27th ACM International Conference on Multimedia (2019) 4
work page 2019
-
[67]
Tschannen, M., Gritsenko, A., Wang, X., Naeem, M.F., Alabdulmohsin, I., Parthasarathy, N., Evans, T., Beyer, L., Xia, Y., Mustafa, B., et al.: Siglip 2: Multilingual vision-language encoders with improved semantic understanding, lo- calization, and dense features. arXiv preprint arXiv:2502.14786 (2025) 4, 14
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[68]
The role of world mod- els in shaping autonomous driving: A comprehensive survey
Tu, S., Zhou, X., Liang, D., Jiang, X., Zhang, Y., Li, X., Bai, X.: The role of world models in shaping autonomous driving: A comprehensive survey. arXiv preprint arXiv:2502.10498 (2025) 1
-
[69]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Unterthiner, T., Van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., Gelly, S.: Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:1812.01717 (2018) 10
work page internal anchor Pith review arXiv 2018
-
[70]
Franca: Nested Matryoshka Clustering for Scalable Visual Representation Learning
Venkataramanan, S., Pariza, V., Salehi, M., Knobel, L., Gidaris, S., Ramzi, E., Bursuc, A., Asano, Y.M.: Franca: Nested matryoshka clustering for scalable visual representation learning. arXiv preprint arXiv:2507.14137 (2025) 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[71]
Villegas, R., Yang, J., Hong, S., Lin, X., Lee, H.: Decomposing motion and content for natural video sequence prediction. In: ICLR (2017) 4
work page 2017
-
[72]
Vondrick, C., Pirsiavash, H., Torralba, A.: Anticipating visual representations from unlabeled video. In: CVPR (2016) 4
work page 2016
-
[73]
Frozen Forecasting: A Unified Evaluation
Walker, J.C., Vélez, P., Cabrera, L.P., Zhou, G., Kabra, R., Doersch, C., Ovs- janikov, M., Carreira, J., Ginosar, S.: Generalist forecasting with frozen video models via latent diffusion. arXiv preprint arXiv:2507.13942 (2025) 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[74]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025) 3, 4, 7, 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[75]
Advances in Neural Information Processing Systems31 (2018) 4
Wang, T.C., Liu, M.Y., Zhu, J.Y., Liu, G., Tao, A., Kautz, J., Catanzaro, B.: Video-to-video synthesis. Advances in Neural Information Processing Systems31 (2018) 4
work page 2018
-
[76]
Emu3: Next-Token Prediction is All You Need
Wang, X., Zhang, X., Luo, Z., Sun, Q., Cui, Y., Wang, J., Zhang, F., Wang, Y., Li, Z., Yu, Q., et al.: Emu3: Next-token prediction is all you need. arXiv preprint arXiv:2409.18869 (2024) 4
work page internal anchor Pith review arXiv 2024
-
[77]
Wang, Y., Jiang, L., Yang, M.H., Li, L.J., Long, M., Fei-Fei, L.: Eidetic 3d LSTM: A model for video prediction and beyond. In: International Conference on Learning Representations (2019),https://openreview.net/forum?id=B1lKS2AqtX4
work page 2019
-
[78]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Wang, Y., He, J., Fan, L., Li, H., Chen, Y., Zhang, Z.: Driving into the future: Mul- tiview visual forecasting and planning with world model for autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 14749–14759 (June 2024) 1
work page 2024
-
[79]
Wortsman, M., Liu, P.J., Xiao, L., Everett, K., Alemi, A., Adlam, B., Co-Reyes, J.D., Gur, I., Kumar, A., Novak, R., et al.: Small-scale proxies for large-scale transformer training instabilities. arXiv preprint arXiv:2309.14322 (2023) 7
- [80]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.