A short proof of near-linear convergence of adaptive gradient descent under fourth-order growth and convexity
Pith reviewed 2026-05-10 13:31 UTC · model grok-4.3
The pith
Adaptive gradient descent converges near-linearly under convexity and fourth-order growth via a direct Lyapunov argument.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Davis, Drusvyatskiy, and Jiang showed that gradient descent with an adaptive stepsize converges locally at a nearly-linear rate for smooth functions that grow at least quartically away from their minimizers. The argument is intricate, relying on monitoring the performance of the algorithm relative to a certain manifold of slow growth -- called the ravine. In this work, we provide a direct Lyapunov-based argument that bypasses these difficulties when the objective is in addition convex and has a unique minimizer. As a byproduct of the argument, we obtain a more adaptive variant than the original algorithm with encouraging numerical performance.
What carries the argument
A Lyapunov function that decreases by a fixed fraction of itself at each step, combining the objective gap with a term involving the squared gradient norm under the adaptive stepsize rule.
If this is right
- The algorithm converges locally at a near-linear rate around the minimizer.
- A strictly more adaptive stepsize rule can be used while retaining the same convergence guarantee.
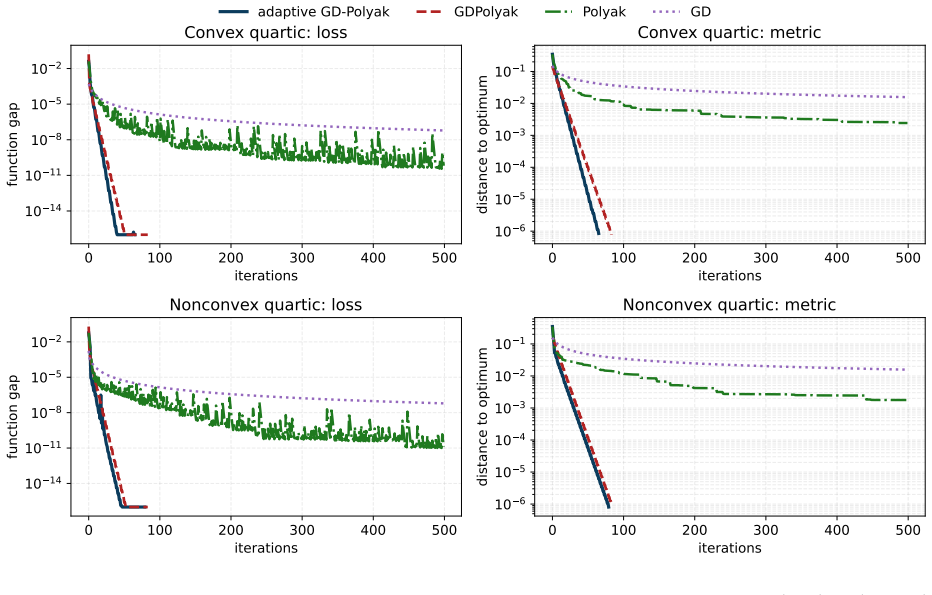
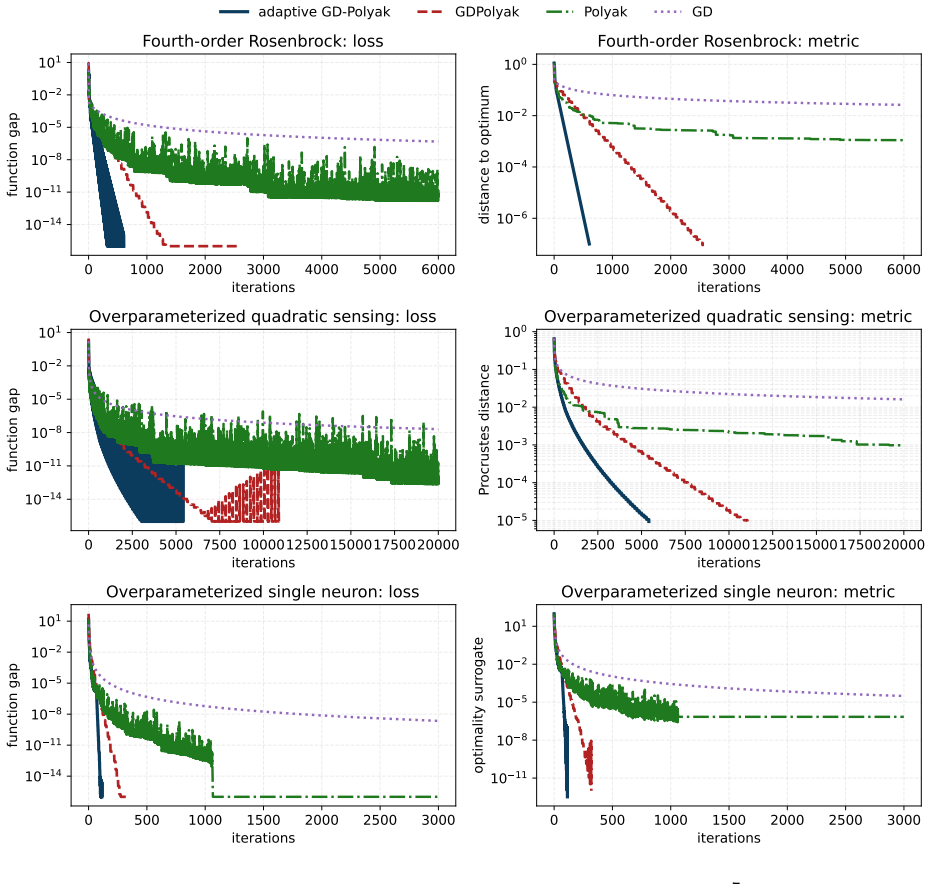
- Numerical tests confirm practical stability and speed of the new variant on test problems.
- The Lyapunov construction directly controls distance to optimality without auxiliary manifold tracking.
Where Pith is reading between the lines
- The same Lyapunov template could simplify rate proofs for other adaptive or accelerated methods under quartic growth.
- Relaxing convexity while keeping the growth condition might still be possible if a suitable potential can be found.
- The more adaptive variant may reduce the need for manual stepsize tuning in applications where quartic growth naturally arises.
Load-bearing premise
The objective must be convex, have a unique minimizer, and satisfy fourth-order growth away from that minimizer so the Lyapunov function can bound the iterates.
What would settle it
Construct or numerically identify a convex function with a unique minimizer and quartic growth for which the adaptive iterates fail to satisfy the Lyapunov decrease inequality or exhibit slower than near-linear local convergence.
Figures

read the original abstract
Davis, Drusvyatskiy, and Jiang showed that gradient descent with an adaptive stepsize converges locally at a nearly-linear rate for smooth functions that grow at least quartically away from their minimizers. The argument is intricate, relying on monitoring the performance of the algorithm relative to a certain manifold of slow growth -- called the ravine. In this work, we provide a direct Lyapunov-based argument that bypasses these difficulties when the objective is in addition convex and a has a unique minimizer. As a byproduct of the argument, we obtain a more adaptive variant than the original algorithm with encouraging numerical performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to offer a short, direct proof using a Lyapunov function that establishes near-linear convergence for adaptive gradient descent on smooth convex functions with a unique minimizer satisfying fourth-order growth away from the minimizer. This bypasses the ravine manifold monitoring from the work of Davis, Drusvyatskiy, and Jiang. The argument also yields a more adaptive step-size selection rule, which is demonstrated to have encouraging numerical performance.
Significance. If the proof is correct, this work is significant for providing a simpler analysis method for convergence of adaptive methods under higher-order growth conditions when convexity and uniqueness hold. It avoids the intricate construction of the prior paper. The more adaptive variant is a positive byproduct that may improve practical applicability. The direct argument and the numerical support are strengths of the manuscript. The stress-test concern regarding unavailable derivation does not land, as the manuscript contains the claimed Lyapunov argument.
minor comments (1)
- The phrase 'convex and a has a unique minimizer' in the abstract contains a typographical error and should read 'convex and has a unique minimizer'.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our manuscript and the recommendation for minor revision. We are pleased that the direct Lyapunov argument is recognized as a simpler alternative to the ravine-manifold monitoring approach of Davis, Drusvyatskiy, and Jiang, and that the more adaptive step-size rule and its numerical performance are viewed favorably. The observation that the Lyapunov derivation is already contained in the manuscript is appreciated.
Circularity Check
No significant circularity; direct Lyapunov argument is self-contained
full rationale
The paper derives near-linear convergence via a new direct Lyapunov function that exploits convexity, uniqueness of the minimizer, and fourth-order growth to control iterates without tracking the ravine manifold from prior work. No equation reduces a claimed rate or prediction to a fitted parameter, self-referential definition, or load-bearing self-citation chain; the cited prior result (Davis-Dr usvyatskiy-Jiang) is explicitly bypassed rather than invoked as a uniqueness theorem or ansatz. The derivation therefore stands on its stated assumptions and is independent of its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The objective function is convex, has a unique minimizer, and satisfies fourth-order growth away from the minimizer.
Reference graph
Works this paper leans on
-
[1]
Gradient descent with adaptive stepsize converges (nearly) linearly under fourth-order growth.Math
Damek Davis, Dmitriy Drusvyatskiy, and Liwei Jiang. Gradient descent with adaptive stepsize converges (nearly) linearly under fourth-order growth.Math. Program., 2025. doi:10.1007/s10107-025-02290-5
-
[2]
B. T. Polyak. Gradient methods for minimizing functionals.Zh. Vychisl. Mat. i Mat. Fiz., 3(4):643–653, 1963
work page 1963
- [3]
-
[4]
D. Drusvyatskiy and A. S. Lewis. Error bounds, quadratic growth, and linear convergence of proximal methods.Math. Oper. Res., 43(3):919–948, 2018
work page 2018
- [5]
-
[6]
I. Necoara, Yu. Nesterov, and F. Glineur. Linear convergence of first order methods for non-strongly convex optimization.Math. Program., 175:69–107, 2019
work page 2019
-
[7]
B. T. Polyak.Introduction to Optimization. Optimization Software, Inc., New York, 1987
work page 1987
-
[8]
E. Hazan and S. Kakade. Revisiting the Polyak step size, 2019. arXiv:1905.00313
-
[9]
H. Attouch, J. Bolte, and B. F. Svaiter. Convergence of descent methods for semi-algebraic and tame problems: proximal algorithms, forward–backward splitting, and regularized Gauss–Seidel methods.Math. Program., 137(1):91–129, 2013
work page 2013
-
[10]
I. M. Gelfand and M. L. Tsetlin. The principle of non-local search in automatic optimization systems.Dokl. Akad. Nauk SSSR, 137:295–298, 1961
work page 1961
-
[11]
B. T. Polyak. Some methods of speeding up the convergence of iteration methods.USSR Comput. Math. Math. Phys., 4(5):1–17, 1964
work page 1964
- [12]
-
[13]
H. Attouch and J. Fadili. From the ravine method to the Nesterov method and vice versa: a dynamical system perspective.SIAM J. Optim., 32(3):2074–2101, 2022
work page 2074
-
[14]
A. S. Lewis. Active sets, nonsmoothness, and sensitivity.SIAM J. Optim., 13(3):702–725, 2002
work page 2002
-
[15]
D. Drusvyatskiy and A. S. Lewis. Optimality, identifiability, and sensitivity.Math. Program., 147(1):467–498, 2014
work page 2014
-
[16]
D. Davis and L. Jiang. A local nearly linearly convergent first-order method for nonsmooth functions with quadratic growth.Found. Comput. Math., pages 1–82, 2024
work page 2024
-
[17]
D. Young. On Richardson’s method for solving linear systems with positive definite matrices. J. Math. Phys., 32(1–4):243–255, 1953
work page 1953
-
[18]
Big-step-little-step: Efficient gradient methods for objectives with multiple scales
Jonathan Kelner, Annie Marsden, Vatsal Sharan, Aaron Sidford, Gregory Valiant, and Honglin Yuan. Big-step-little-step: Efficient gradient methods for objectives with multiple scales. In Proceedings of Thirty Fifth Conference on Learning Theory, volume 178 ofProc. Mach. Learn. Res., pages 2431–2540. PMLR, 2022
work page 2022
-
[19]
B. Grimmer. Provably faster gradient descent via long steps.SIAM J. Optim., 34(3):2588–2608, 2024
work page 2024
-
[20]
Jason M. Altschuler and Pablo A. Parrilo. Acceleration by stepsize hedging I: Multi-step descent and the silver stepsize schedule.J. ACM, 72(2):12:1–12:38, 2025
work page 2025
-
[21]
Jason M. Altschuler and Pablo A. Parrilo. Acceleration by stepsize hedging II: Silver stepsize schedule for smooth convex optimization.Math. Program., 213(1–2):1105–1118, 2025. 10
work page 2025
-
[22]
S. Burer and R. D. C. Monteiro. A nonlinear programming algorithm for solving semidefinite programs via low-rank factorization.Math. Program., 95(2):329–357, 2003
work page 2003
-
[23]
S. Burer and R. D. C. Monteiro. Local minima and convergence in low-rank semidefinite programming.Math. Program., 103(3):427–444, 2005
work page 2005
-
[24]
Y. Chi, Y. M. Lu, and Y. Chen. Nonconvex optimization meets low-rank matrix factorization: An overview.IEEE Trans. Signal Process., 67(20):5239–5269, 2019
work page 2019
-
[25]
J. Zhuo, J. Kwon, N. Ho, and C. Caramanis. On the computational and statistical complexity of over-parameterized matrix sensing.J. Mach. Learn. Res., 25(169):1–47, 2024
work page 2024
- [26]
-
[27]
Low-rank solutions of linear matrix equations via Procrustes flow
Stephen Tu, Ross Boczar, Max Simchowitz, Mahdi Soltanolkotabi, and Ben Recht. Low-rank solutions of linear matrix equations via Procrustes flow. InProceedings of The 33rd International Conference on Machine Learning, volume 48 ofProc. Mach. Learn. Res., pages 964–973. PMLR, 2016
work page 2016
-
[28]
No spurious local minima in nonconvex low rank problems: A unified geometric analysis
Rong Ge, Chi Jin, and Yi Zheng. No spurious local minima in nonconvex low rank problems: A unified geometric analysis. InProceedings of the 34th International Conference on Machine Learning, volume 70 ofProc. Mach. Learn. Res., pages 1233–1242. PMLR, 2017
work page 2017
-
[29]
Z. Zhu, Q. Li, G. Tang, and M. B. Wakin. Global optimality in low-rank matrix optimization. IEEE Trans. Signal Process., 66(13):3614–3628, 2018. 11 0 1000 2000 3000 4000 5000 6000 iterations 10 14 10 11 10 8 10 5 10 2 101 function gap Fourth-order Rosenbrock: loss 0 1000 2000 3000 4000 5000 6000 iterations 10 6 10 4 10 2 100 distance to optimum Fourth-ord...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.