Med-CAM: Minimal Evidence for Explaining Medical Decision Making
Pith reviewed 2026-05-10 14:04 UTC · model grok-4.3
The pith
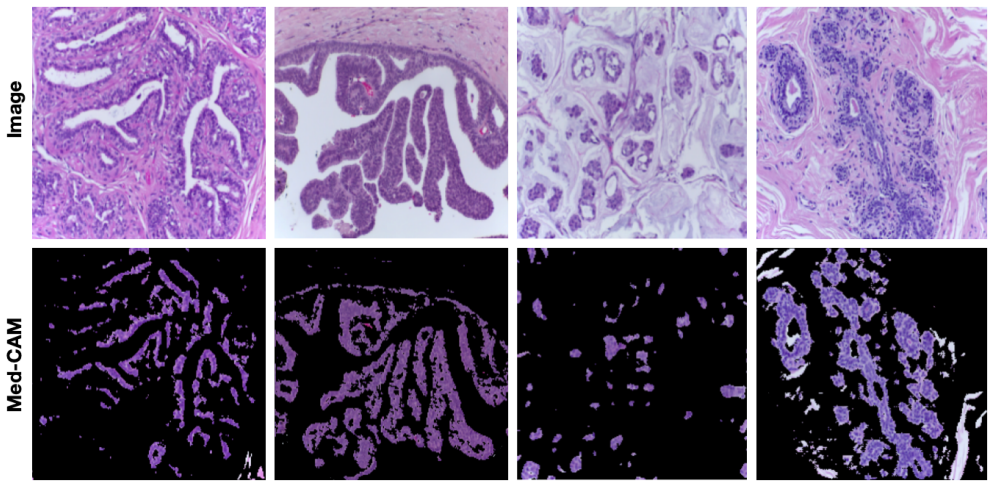
Med-CAM generates minimal sharp evidence masks for medical image decisions by matching classifier activations with a trained segmentation network.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Med-CAM trains a segmentation network from scratch to produce a mask that highlights the minimal evidence critical to the model's decision for any seen or unseen image. This ensures that the explanation is both faithful to the network's behaviour and interpretable to clinicians, delivering conclusive evidence-based explanations unlike prior fuzzy spatial methods.
What carries the argument
Med-CAM framework using Classifier Activation Matching to train a segmentation network that generates minimal diagnostic evidence masks aligned with classifier activations.
If this is right
- Explanations are faithful to the model's prediction and replicate it for any given image.
- Clinicians receive precise information on shapes, textures, and boundaries that influence the diagnosis.
- The method advances transparent AI in high-stakes applications such as pathology and radiology.
- Explanations remain compact and consistent while maintaining diagnostic alignment.
- Works for both seen and unseen images without post-hoc approximations.
Where Pith is reading between the lines
- Similar activation matching could be tested in non-medical classification tasks to see if minimal evidence masks improve interpretability elsewhere.
- If the masks prove robust, they might replace attention-based methods in clinical workflows.
- The approach might generalize to other types of medical data beyond images if activation matching extends accordingly.
Load-bearing premise
That a segmentation network trained from scratch on classifier activations will produce masks that are both minimal and faithful to the original model's decision process without introducing artifacts or bias.
What would settle it
An experiment showing that the produced minimal mask, when used to isolate the evidence in the image, does not cause the original classifier to output the same prediction as the full image.
Figures



read the original abstract
Reliable and interpretable decision-making is essential in medical imaging, where diagnostic outcomes directly influence patient care. Despite advances in deep learning, most medical AI systems operate as opaque black boxes, providing little insight into why a particular diagnosis was reached. In this paper, we introduce Med-CAM, a framework for generating minimal and sharp maps as evidence-based explanations for Medical decision making via Classifier Activation Matching. Med-CAM trains a segmentation network from scratch to produce a mask that highlights the minimal evidence critical to model's decision for any seen or unseen image. This ensures that the explanation is both faithful to the network's behaviour and interpretable to clinicians. Experiments show, unlike prior spatial explanation methods, such as Grad-CAM and attention maps, which yield only fuzzy regions of relative importance, Med-CAM with its superior spatial awareness to shapes, textures, and boundaries, delivers conclusive, evidence-based explanations that faithfully replicate the model's prediction for any given image. By explicitly constraining explanations to be compact, consistent with model activations, and diagnostic alignment, Med-CAM advances transparent AI to foster clinician understanding and trust in high-stakes medical applications such as pathology and radiology.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Med-CAM, a framework that trains a segmentation network from scratch to generate minimal and sharp explanation masks for medical image classifiers via Classifier Activation Matching. It claims these masks provide faithful, evidence-based explanations that replicate the model's predictions, with superior spatial awareness of shapes, textures, and boundaries compared to Grad-CAM and attention maps, advancing transparent AI in high-stakes medical applications.
Significance. If the central claims are substantiated, Med-CAM could meaningfully improve explainable AI for medical imaging by delivering compact, sharp visual explanations aligned with model decisions, potentially fostering greater clinician trust in diagnostic systems for pathology and radiology.
major comments (3)
- [Abstract] Abstract: The assertion that 'experiments show' superiority over Grad-CAM and attention maps, along with 'faithful replication' of the model's prediction, is unsupported because the text supplies no quantitative metrics, experimental setup, baselines, datasets, or results.
- [Method] Method (Classifier Activation Matching): The training of the segmentation network to match classifier activations does not specify the loss function, regularization terms, or constraints (e.g., area penalty or sparsity) used to enforce minimality of the mask. This is load-bearing for the 'minimal evidence' claim and leaves open the risk that the segmenter introduces its own biases or over-segments.
- [Experiments] Experiments: No faithfulness metrics (such as deletion/insertion scores), minimality measures, ablation studies, or direct comparisons with baselines are described, which is required to support the superiority and conclusive replication claims.
minor comments (1)
- [Abstract] Abstract: The sentence 'Med-CAM with its superior spatial awareness to shapes, textures, and boundaries, delivers conclusive...' contains a grammatical issue and awkward phrasing that reduces clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important gaps in the presentation of our claims, methods, and experiments. We address each point below and will incorporate revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that 'experiments show' superiority over Grad-CAM and attention maps, along with 'faithful replication' of the model's prediction, is unsupported because the text supplies no quantitative metrics, experimental setup, baselines, datasets, or results.
Authors: We agree that the abstract references experimental outcomes without providing supporting details. In the revised manuscript, we will expand the abstract to include brief mentions of key quantitative results (e.g., faithfulness and minimality scores) and ensure the main text fully describes the experimental setup, datasets, baselines, and tabulated results to substantiate the claims of superiority and faithful replication. revision: yes
-
Referee: [Method] Method (Classifier Activation Matching): The training of the segmentation network to match classifier activations does not specify the loss function, regularization terms, or constraints (e.g., area penalty or sparsity) used to enforce minimality of the mask. This is load-bearing for the 'minimal evidence' claim and leaves open the risk that the segmenter introduces its own biases or over-segments.
Authors: The referee correctly notes that the loss function and regularization details are not specified in the current draft. We will revise the Method section to explicitly define the Classifier Activation Matching loss, which combines an activation-matching term with an area penalty and sparsity regularization to enforce minimality. We will also add analysis of how these terms mitigate segmenter biases and over-segmentation risks. revision: yes
-
Referee: [Experiments] Experiments: No faithfulness metrics (such as deletion/insertion scores), minimality measures, ablation studies, or direct comparisons with baselines are described, which is required to support the superiority and conclusive replication claims.
Authors: We acknowledge that the current manuscript lacks these quantitative evaluations. The revised version will include a complete Experiments section reporting faithfulness metrics (deletion/insertion scores), minimality measures (e.g., mask area), ablation studies on loss components, and direct comparisons with Grad-CAM and attention maps on medical imaging datasets. These additions will provide the evidence needed to support our claims. revision: yes
Circularity Check
Med-CAM faithfulness reduces to activation-matching training by construction
specific steps
-
fitted input called prediction
[Abstract]
"Med-CAM trains a segmentation network from scratch to produce a mask that highlights the minimal evidence critical to model's decision for any seen or unseen image. This ensures that the explanation is both faithful to the network's behaviour and interpretable to clinicians."
The mask is generated by training explicitly to align with the classifier's activations, so 'faithful replication' of the model's prediction is the direct result of the training objective. The claim of minimality and conclusiveness is asserted as following from this setup without separate enforcement or benchmark, reducing the explanation property to the fitted construction.
full rationale
The paper's core claim is that training a segmentation network from scratch on classifier activations produces masks that are both minimal and faithful to the original model's decisions. This makes the replication of predictions a direct outcome of the fitting process rather than an independent result. The abstract asserts that this training 'ensures' faithfulness and minimality, but without explicit loss terms for sparsity or external validation, the explanation quality is defined by the training setup itself. This qualifies as fitted-input-called-prediction with partial circularity; the method may still be useful but the derivation of 'conclusive, evidence-based' properties does not stand apart from the inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- Segmentation network training hyperparameters
axioms (1)
- domain assumption A segmentation network trained to match classifier activations will produce minimal masks that faithfully represent the model's decision evidence
Reference graph
Works this paper leans on
-
[1]
Sajid Ali, Tamer Abuhmed, Shaker El-Sappagh, Khan Muhammad, Jose M. Alonso-Moral, Roberto Confalonieri, Riccardo Guidotti, Javier Del Ser, Natalia D ´ıaz-Rodr´ıguez, and Francisco Herrera. Explainable artificial intelligence (xai): What we know and what is left to attain trustworthy artificial intelligence.Information Fusion, 99:101805, 2023. 2
work page 2023
-
[2]
Bach: Grand challenge on breast can- cer histology images.Medical Image Analysis, 56:122–139,
Guilherme Aresta, Teresa Ara ´ujo, Scotty Kwok, Sai Saketh Chennamsetty, Mohammed Safwan, Varghese Alex, Bahram Marami, Marcel Prastawa, Monica Chan, Michael Donovan, Gerardo Fernandez, Jack Zeineh, Matthias Kohl, Christoph Walz, Florian Ludwig, Stefan Braunewell, Maximilian Baust, Quoc Dang Vu, Minh Nguyen Nhat To, Eal Kim, Jin Tae Kwak, Sameh Galal, Ver...
-
[3]
B-cos net- works: Alignment is all we need for interpretability, 2022
Moritz B ¨ohle, Mario Fritz, and Bernt Schiele. B-cos net- works: Alignment is all we need for interpretability, 2022. 2
work page 2022
-
[4]
Ahmad Chaddad, Yan Hu, Yihang Wu, Binbin Wen, and Reem Kateb. Generalizable and explainable deep learning for medical image computing: An overview.Current Opin- ion in Biomedical Engineering, 33:100567, 2025. 2
work page 2025
-
[5]
On the reasons behind decisions, 2020
Adnan Darwiche and Auguste Hirth. On the reasons behind decisions, 2020. 2
work page 2020
-
[6]
An image is worth 16x16 words: Transformers for image recognition at scale, 2021
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale, 2021. 5
work page 2021
-
[7]
Amirehsan Ghasemi, Soheil Hashtarkhani, David Schwartz, and Arash Shaban-Nejad. Explainable artificial intelligence in breast cancer detection and risk prediction: A systematic scoping review, 2024. 2
work page 2024
-
[8]
Leilani H. Gilpin, David Bau, Ben Z. Yuan, Ayesha Bajwa, Michael A. Specter, and Lalana Kagal. Explaining explana- tions: An overview of interpretability of machine learning. 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), pages 80–89, 2018. 2
work page 2018
-
[9]
Nicholas Hamilton, Adam Webb, Matt Wilder, Ben Hen- drickson, Matt Blanck, Erin Nelson, Wiley Roemer, and Timothy C. Havens. Enhancing visualization and explain- ability of computer vision models with local interpretable model-agnostic explanations (lime). In2022 IEEE Sym- posium Series on Computational Intelligence (SSCI), pages 604–611, 2022. 2
work page 2022
-
[10]
Deep residual learning for image recognition, 2015
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition, 2015. 5
work page 2015
-
[11]
Weiche Hsieh, Ziqian Bi, Chuanqi Jiang, Junyu Liu, Benji Peng, Sen Zhang, Xuanhe Pan, Jiawei Xu, Jinlang Wang, Keyu Chen, Pohsun Feng, Yizhu Wen, Xinyuan Song, Tianyang Wang, Ming Liu, Junjie Yang, Ming Li, Bowen Jing, Jintao Ren, Junhao Song, Hong-Ming Tseng, Yichao Zhang, Lawrence K. Q. Yan, Qian Niu, Silin Chen, Yunze Wang, and Chia Xin Liang. A compre...
work page 2024
-
[12]
Abduction-based explanations for machine learning models,
Alexey Ignatiev, Nina Narodytska, and Joao Marques-Silva. Abduction-based explanations for machine learning models,
-
[13]
C.A. Jensen, R.D. Reed, R.J. Marks, M.A. El-Sharkawi, Jae-Byung Jung, R.T. Miyamoto, G.M. Anderson, and C.J. Eggen. Inversion of feedforward neural networks: algo- rithms and applications.Proceedings of the IEEE, 87(9): 1536–1549, 1999. 2
work page 1999
-
[14]
Inversion of neural networks by gradient descent.Parallel Computing, 14(3):277–286, 1990
J Kindermann and A Linden. Inversion of neural networks by gradient descent.Parallel Computing, 14(3):277–286, 1990. 2
work page 1990
-
[15]
Jae Hee Lee, Georgii Mikriukov, Gesina Schwalbe, Stefan Wermter, and Diedrich Wolter. Concept-based explanations in computer vision: Where are we and where could we go? InComputer Vision – ECCV 2024 Workshops, pages 266– 287, Cham, 2025. Springer Nature Switzerland. 2
work page 2024
-
[16]
Landscape learning for neural network inversion, 2022
Ruoshi Liu, Chengzhi Mao, Purva Tendulkar, Hao Wang, and Carl V ondrick. Landscape learning for neural network inversion, 2022. 2
work page 2022
-
[17]
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feicht- enhofer, Trevor Darrell, and Saining Xie. A convnet for the 2020s, 2022. 5
work page 2022
-
[18]
A unified approach to inter- preting model predictions, 2017
Scott Lundberg and Su-In Lee. A unified approach to inter- preting model predictions, 2017. 2
work page 2017
-
[19]
Understanding deep image representations by inverting them, 2014
Aravindh Mahendran and Andrea Vedaldi. Understanding deep image representations by inverting them, 2014. 2
work page 2014
-
[20]
Inceptionism: Going deeper into neural networks, 2015
Alexander Mordvintsev, Christopher Olah, and Mike Tyka. Inceptionism: Going deeper into neural networks, 2015
work page 2015
-
[21]
Synthesizing the preferred inputs for neurons in neural networks via deep generator networks, 2016
Anh Nguyen, Alexey Dosovitskiy, Jason Yosinski, Thomas Brox, and Jeff Clune. Synthesizing the preferred inputs for neurons in neural networks via deep generator networks, 2016
work page 2016
-
[22]
Plug & play generative networks: Conditional iterative generation of images in latent space,
Anh Nguyen, Jeff Clune, Yoshua Bengio, Alexey Dosovit- skiy, and Jason Yosinski. Plug & play generative networks: Conditional iterative generation of images in latent space,
-
[23]
Prasanna Porwal, Samiksha Pachade, Ravi Kamble, Manesh Kokare, Girish Deshmukh, Vivek Sahasrabuddhe, and Fab- rice Meriaudeau. Indian diabetic retinopathy image dataset (idrid): A database for diabetic retinopathy screening re- search.Data, 3(3), 2018. 5
work page 2018
-
[24]
Anchors: high-precision model-agnostic explanations
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. Anchors: high-precision model-agnostic explanations. In Proceedings of the Thirty-Second AAAI Conference on Artifi- cial Intelligence and Thirtieth Innovative Applications of Ar- tificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence. AAAI Press, 2018. 2
work page 2018
-
[25]
U-net: Convolutional networks for biomedical image segmentation,
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation,
-
[26]
Emad W. Saad and Donald C. Wunsch. Neural network ex- planation using inversion.Neural Networks, 20(1):78–93,
-
[27]
Mobilenetv2: Inverted residuals and linear bottlenecks, 2019
Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zh- moginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks, 2019. 5
work page 2019
-
[28]
Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Ba- tra
Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Ba- tra. Grad-cam: Visual explanations from deep networks via gradient-based localization.International Journal of Com- puter Vision, 128(2):336–359, 2019. 2
work page 2019
-
[29]
A symbolic approach to explaining bayesian network classifiers
Andy Shih, Arthur Choi, and Adnan Darwiche. A symbolic approach to explaining bayesian network classifiers. InPro- ceedings of the 27th International Joint Conference on Arti- ficial Intelligence, page 5103–5111. AAAI Press, 2018. 2
work page 2018
-
[30]
Learning important features through propagating activation differences, 2019
Avanti Shrikumar, Peyton Greenside, and Anshul Kundaje. Learning important features through propagating activation differences, 2019. 2
work page 2019
-
[31]
Explainable deep learning models in medical image analysis, 2020
Amitojdeep Singh, Sourya Sengupta, and Vasudevan Laksh- minarayanan. Explainable deep learning models in medical image analysis, 2020. 2
work page 2020
-
[32]
What you see is what you classify: Black box attributions, 2022
Steven Stalder, Nathana ¨el Perraudin, Radhakrishna Achanta, Fernando Perez-Cruz, and Michele V olpi. What you see is what you classify: Black box attributions, 2022. 2
work page 2022
-
[33]
Network inversion of binarised neural nets
Pirzada Suhail. Network inversion of binarised neural nets. InThe Second Tiny Papers Track at ICLR 2024, 2024. 2
work page 2024
-
[34]
Network inversion of convo- lutional neural nets
Pirzada Suhail and Amit Sethi. Network inversion of convo- lutional neural nets. InMuslims in ML Workshop co-located with NeurIPS 2024, 2024. 2
work page 2024
-
[35]
Leveraging explanations in interactive machine learning: An overview, 2022
Stefano Teso, ¨Oznur Alkan, Wolfang Stammer, and Eliza- beth Daly. Leveraging explanations in interactive machine learning: An overview, 2022. 2
work page 2022
-
[36]
Philipp Tschandl, Cliff Rosendahl, and Harald Kittler. The ham10000 dataset, a large collection of multi-source der- matoscopic images of common pigmented skin lesions.Sci- entific Data, 5(1), 2018. 5
work page 2018
-
[37]
Bas H.M. van der Velden, Hugo J. Kuijf, Kenneth G.A. Gilhuijs, and Max A. Viergever. Explainable artificial intel- ligence (xai) in deep learning-based medical image analysis. Medical Image Analysis, 79:102470, 2022. 2
work page 2022
-
[38]
Neural network inversion beyond gradient de- scent
Eric Wong. Neural network inversion beyond gradient de- scent. InWOML NIPS, 2017. 2
work page 2017
-
[39]
Understanding neural networks through deep visualization, 2015
Jason Yosinski, Jeff Clune, Anh Nguyen, Thomas Fuchs, and Hod Lipson. Understanding neural networks through deep visualization, 2015. 2
work page 2015
-
[40]
Gandomi, Fang Chen, and Andreas Holzinger
Jianlong Zhou, Amir H. Gandomi, Fang Chen, and Andreas Holzinger. Evaluating the quality of machine learning expla- nations: A survey on methods and metrics.Electronics, 10 (5), 2021. 2
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.