GenAssets: Generating in-the-wild 3D Assets in Latent Space
Pith reviewed 2026-05-08 12:21 UTC · model grok-4.3
The pith
A 3D latent diffusion model generates complete high-quality assets from sparse in-the-wild driving sensor data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a 3D latent diffusion model that learns on in-the-wild LiDAR and camera data captured by a sensor platform and generates high-quality 3D assets with complete geometry and appearance. Key to our method is a reconstruct-then-generate approach that first leverages occlusion-aware neural rendering trained over multiple scenes to build a high-quality latent space for objects, and then trains a diffusion model that operates on the latent space. We show our method outperforms existing reconstruction and generation based methods, unlocking diverse and scalable content creation for simulation.
What carries the argument
The reconstruct-then-generate pipeline: occlusion-aware neural rendering trained across multiple scenes to produce a latent space for partially observed objects, followed by a diffusion model that samples complete assets inside that latent space.
If this is right
- Generated assets render consistently from arbitrary viewpoints rather than only near the original observations.
- The method produces complete geometry and appearance for traffic participants even from single-pass driving captures.
- It scales content creation for multi-sensor simulation without requiring dense multi-view captures or manual modeling.
- Outperforms both pure neural-rendering reconstruction and standard diffusion generation on in-the-wild driving scenes.
Where Pith is reading between the lines
- The same latent-space reconstruction step could be applied to other domains that suffer from sparse, occluded observations such as indoor robotics or aerial mapping.
- Once the latent space exists, the diffusion stage could be conditioned on additional attributes like vehicle type or weather to further increase scenario variety in simulation.
- Integration of these assets into closed-loop simulators would allow testing of perception and planning modules on far more diverse object configurations than real data alone provides.
Load-bearing premise
An occlusion-aware neural rendering model trained over multiple scenes can reliably construct a high-quality latent space for objects observed under sparse viewpoints and partial occlusions in driving data.
What would settle it
If assets generated by the model, when rendered from completely novel viewpoints far from any training observation, fail to match the appearance and geometry statistics of held-out real sensor captures of the same object categories, the claim that the latent space supports faithful completion would not hold.
Figures





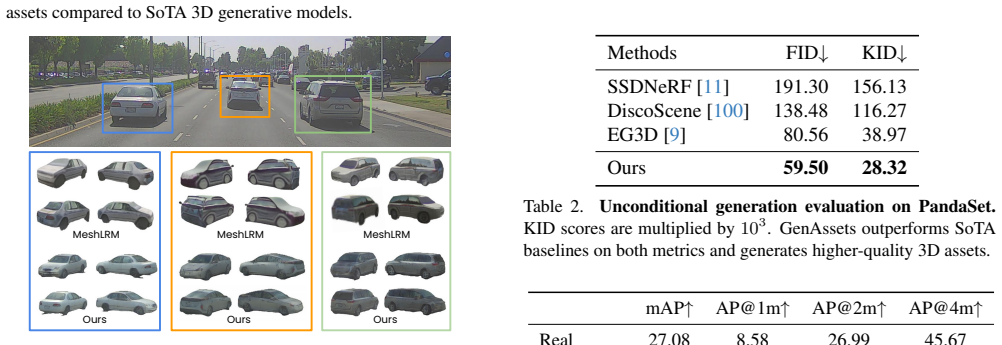
read the original abstract
High-quality 3D assets for traffic participants are critical for multi-sensor simulation, which is essential for the safe end-to-end development of autonomy. Building assets from in-the-wild data is key for diversity and realism, but existing neural-rendering based reconstruction methods are slow and generate assets that render well only from viewpoints close to the original observations, limiting their usefulness in simulation. Recent diffusion-based generative models build complete and diverse assets, but perform poorly on in-the-wild driving scenes, where observed actors are captured under sparse and limited fields of view, and are partially occluded. In this work, we propose a 3D latent diffusion model that learns on in-the-wild LiDAR and camera data captured by a sensor platform and generates high-quality 3D assets with complete geometry and appearance. Key to our method is a "reconstruct-then-generate" approach that first leverages occlusion-aware neural rendering trained over multiple scenes to build a high-quality latent space for objects, and then trains a diffusion model that operates on the latent space. We show our method outperforms existing reconstruction and generation based methods, unlocking diverse and scalable content creation for simulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GenAssets, a 3D latent diffusion model that learns from in-the-wild LiDAR and camera data captured by a sensor platform. It uses a reconstruct-then-generate pipeline: an occlusion-aware neural rendering model is trained jointly over multiple scenes to construct a latent space for objects observed under sparse viewpoints and partial occlusions, after which a diffusion model operates in that latent space to generate 3D assets with complete geometry and appearance. The abstract asserts that this outperforms existing reconstruction and generation baselines for multi-sensor simulation of traffic participants.
Significance. If the central assumption holds, the approach could enable scalable generation of diverse, complete 3D assets from real driving data, addressing the slowness of per-scene neural reconstruction and the failure of standard diffusion models on limited-view, occluded observations. This would support more realistic simulation for autonomy development.
major comments (2)
- [Abstract] Abstract: The claim that the method 'outperforms existing reconstruction and generation based methods' is unsupported by any quantitative metrics, ablation studies, tables, or experimental details. This prevents verification of the central claim.
- [Abstract] Abstract (reconstruct-then-generate description): The pipeline assumes that the occlusion-aware neural renderer, trained jointly over multiple scenes, produces object latents encoding complete unobserved geometry and appearance rather than imputing from dataset priors. No analysis, ablations, or evidence is supplied to show that the latent space recovers missing parts from sparse, occluded driving views (<90° total viewpoint range, frequent partial occlusions) instead of collapsing to averages. This assumption is load-bearing, as every generated asset is decoded from samples in this latent space.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important points about supporting claims in the abstract and providing evidence for the core assumptions in our reconstruct-then-generate pipeline. We address each major comment below and commit to revisions that will strengthen the paper without altering its central contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the method 'outperforms existing reconstruction and generation based methods' is unsupported by any quantitative metrics, ablation studies, tables, or experimental details. This prevents verification of the central claim.
Authors: We agree that the abstract would be strengthened by including specific quantitative support for the performance claim. The full manuscript contains detailed experimental results in Sections 4 and 5, including tables with metrics such as PSNR, IoU for geometry, and FID for appearance, demonstrating consistent improvements over reconstruction and diffusion baselines. To address this directly, we will revise the abstract to incorporate key numerical results (e.g., average gains of X% on primary metrics) while maintaining its concise nature. revision: yes
-
Referee: [Abstract] Abstract (reconstruct-then-generate description): The pipeline assumes that the occlusion-aware neural renderer, trained jointly over multiple scenes, produces object latents encoding complete unobserved geometry and appearance rather than imputing from dataset priors. No analysis, ablations, or evidence is supplied to show that the latent space recovers missing parts from sparse, occluded driving views (<90° total viewpoint range, frequent partial occlusions) instead of collapsing to averages. This assumption is load-bearing, as every generated asset is decoded from samples in this latent space.
Authors: This is a substantive point about the properties of the learned latent space. Our joint multi-scene training is intended to promote completion of unobserved geometry through shared priors across diverse observations, and we provide supporting evidence via qualitative comparisons and quantitative metrics showing that our generated assets are more complete than per-scene baselines. That said, we acknowledge the absence of targeted analysis isolating recovery of missing parts versus dataset averaging. We will add a dedicated ablation subsection (including visualizations of decoded outputs from progressively sparser/occluded inputs against held-out ground truth) to directly demonstrate the latent space behavior. revision: yes
Circularity Check
No circularity: descriptive pipeline with no equations or self-referential reductions
full rationale
The paper describes a reconstruct-then-generate method that first trains an occlusion-aware neural renderer across scenes to produce object latents, then trains a diffusion model on those latents. No equations, derivations, or fitted-parameter predictions appear in the provided text. The central claim is an empirical method statement rather than a mathematical reduction; the neural-rendering step is presented as an enabling component whose validity is external to the diffusion stage. No self-citation chains, ansatzes smuggled via prior work, or renamings of known results are load-bearing for the output. The reader's assessment of score 2.0 is consistent with absence of circular structure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Renderdiffusion: Image diffusion for 3d reconstruction, in- painting and generation
Titas Anciukevi ˇcius, Zexiang Xu, Matthew Fisher, Paul Henderson, Hakan Bilen, Niloy J Mitra, and Paul Guerrero. Renderdiffusion: Image diffusion for 3d reconstruction, in- painting and generation. InCVPR, 2023. 3
work page 2023
-
[2]
Barron, Ben Mildenhall, Dor Verbin, Pratul P
Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul P. Srinivasan, and Peter Hedman. Mip-nerf 360: Unbounded anti-aliased neural radiance fields.CVPR, 2022. 13
work page 2022
-
[3]
Zip-nerf: Anti-aliased grid- based neural radiance fields
Jonathan T Barron, Ben Mildenhall, Dor Verbin, Pratul P Srinivasan, and Peter Hedman. Zip-nerf: Anti-aliased grid- based neural radiance fields. InICCV, 2023. 22
work page 2023
-
[4]
Gaudi: A neural architect for immersive 3d scene generation.NeurIPS, 2022
Miguel Angel Bautista, Pengsheng Guo, Samira Abnar, Walter Talbott, Alexander Toshev, Zhuoyuan Chen, Lau- rent Dinh, Shuangfei Zhai, Hanlin Goh, Daniel Ulbricht, et al. Gaudi: A neural architect for immersive 3d scene generation.NeurIPS, 2022. 5
work page 2022
-
[5]
Demystifying mmd gans.arXiv, 2018
Mikołaj Bi ´nkowski, Danica J Sutherland, Michael Arbel, and Arthur Gretton. Demystifying mmd gans.arXiv, 2018. 7, 16
work page 2018
-
[6]
nuscenes: A multi- modal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multi- modal dataset for autonomous driving. InCVPR, 2020. 8, 18
work page 2020
-
[7]
Lightplane: Highly-scalable components for neu- ral 3d fields.arXiv, 2024
Ang Cao, Justin Johnson, Andrea Vedaldi, and David Novotny. Lightplane: Highly-scalable components for neu- ral 3d fields.arXiv, 2024. 3
work page 2024
-
[8]
pi-gan: Periodic implicit genera- tive adversarial networks for 3d-aware image synthesis
Eric R Chan, Marco Monteiro, Petr Kellnhofer, Jiajun Wu, and Gordon Wetzstein. pi-gan: Periodic implicit genera- tive adversarial networks for 3d-aware image synthesis. In CVPR, 2021. 2
work page 2021
-
[9]
Efficient geometry-aware 3d generative adversarial networks
Eric R Chan, Connor Z Lin, Matthew A Chan, Koki Nagano, Boxiao Pan, Shalini De Mello, Orazio Gallo, Leonidas J Guibas, Jonathan Tremblay, Sameh Khamis, et al. Efficient geometry-aware 3d generative adversarial networks. InCVPR, 2022. 2, 3, 6, 7, 8, 14, 15, 16
work page 2022
-
[10]
pixelsplat: 3d gaussian splats from im- age pairs for scalable generalizable 3d reconstruction
David Charatan, Sizhe Lester Li, Andrea Tagliasacchi, and Vincent Sitzmann. pixelsplat: 3d gaussian splats from im- age pairs for scalable generalizable 3d reconstruction. In CVPR, 2024. 6, 7, 14, 15
work page 2024
-
[11]
Single-stage dif- fusion nerf: A unified approach to 3d generation and recon- struction
Hansheng Chen, Jiatao Gu, Anpei Chen, Wei Tian, Zhuowen Tu, Lingjie Liu, and Hao Su. Single-stage dif- fusion nerf: A unified approach to 3d generation and recon- struction. InICCV, 2023. 2, 3, 5, 6, 7, 8, 15, 16
work page 2023
-
[12]
Geosim: Realistic video simu- lation via geometry-aware composition for self-driving
Yun Chen, Frieda Rong, Shivam Duggal, Shenlong Wang, Xinchen Yan, Sivabalan Manivasagam, Shangjie Xue, Ersin Yumer, and Raquel Urtasun. Geosim: Realistic video simu- lation via geometry-aware composition for self-driving. In CVPR, 2021. 2
work page 2021
-
[13]
G3r: Gradient guided gen- eralizable reconstruction
Yun Chen, Jingkang Wang, Ze Yang, Sivabalan Mani- vasagam, and Raquel Urtasun. G3r: Gradient guided gen- eralizable reconstruction. InECCV, 2025. 2, 6, 7, 14, 15
work page 2025
-
[14]
Omnire: Omni urban scene reconstruction.arXiv, 2024
Ziyu Chen, Jiawei Yang, Jiahui Huang, Riccardo de Lu- tio, Janick Martinez Esturo, Boris Ivanovic, Or Litany, Zan Gojcic, Sanja Fidler, Marco Pavone, et al. Omnire: Omni urban scene reconstruction.arXiv, 2024. 1, 2, 6, 22
work page 2024
-
[15]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. InCVPR, 2023. 2
work page 2023
-
[16]
Diffusion models beat gans on image synthesis.NeurIPS, 2021
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis.NeurIPS, 2021. 5
work page 2021
-
[17]
CARLA: An open urban driving simulator
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Anto- nio Lopez, and Vladlen Koltun. CARLA: An open urban driving simulator. InCoRL, 2017. 1
work page 2017
-
[18]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. InCVPR,
-
[19]
Dynamic 3d gaussian fields for urban areas.arXiv, 2024
Tobias Fischer, Jonas Kulhanek, Samuel Rota Bul `o, Lorenzo Porzi, Marc Pollefeys, and Peter Kontschieder. Dynamic 3d gaussian fields for urban areas.arXiv, 2024. 1
work page 2024
-
[20]
De- tail me more: Improving gan’s photo-realism of complex scenes
Raghudeep Gadde, Qianli Feng, and Aleix M Martinez. De- tail me more: Improving gan’s photo-realism of complex scenes. InICCV, 2021. 5
work page 2021
-
[21]
Get3d: A generative model of high quality 3d tex- tured shapes learned from images.NeurIPS, 2022
Jun Gao, Tianchang Shen, Zian Wang, Wenzheng Chen, Kangxue Yin, Daiqing Li, Or Litany, Zan Gojcic, and Sanja Fidler. Get3d: A generative model of high quality 3d tex- tured shapes learned from images.NeurIPS, 2022. 2, 3
work page 2022
-
[22]
Cat3d: Create anything in 3d with multi-view diffusion models.arXiv, 2024
Ruiqi Gao, Aleksander Holynski, Philipp Henzler, Arthur Brussee, Ricardo Martin-Brualla, Pratul Srinivasan, Jonathan T Barron, and Ben Poole. Cat3d: Create anything in 3d with multi-view diffusion models.arXiv, 2024. 3
work page 2024
-
[23]
Generative adversarial nets.NeurIPS,
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.NeurIPS,
-
[24]
Nerfdiff: Single-image view synthesis with nerf-guided distillation from 3d-aware diffusion
Jiatao Gu, Alex Trevithick, Kai-En Lin, Joshua M Susskind, Christian Theobalt, Lingjie Liu, and Ravi Ra- mamoorthi. Nerfdiff: Single-image view synthesis with nerf-guided distillation from 3d-aware diffusion. InICML,
-
[25]
Gans trained by a two time-scale update rule converge to a local nash equi- librium.NeurIPS, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equi- librium.NeurIPS, 2017. 6, 7, 16
work page 2017
-
[26]
Denoising dif- fusion probabilistic models.NeurIPS, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.NeurIPS, 2020. 3, 5, 13
work page 2020
-
[27]
LRM: Large reconstruction model for single im- age to 3d.arXiv, 2023
Yicong Hong, Kai Zhang, Jiuxiang Gu, Sai Bi, Yang Zhou, Difan Liu, Feng Liu, Kalyan Sunkavalli, Trung Bui, and Hao Tan. LRM: Large reconstruction model for single im- age to 3d.arXiv, 2023. 2
work page 2023
-
[28]
Rangeldm: Fast realistic lidar point cloud generation
Qianjiang Hu, Zhimin Zhang, and Wei Hu. Rangeldm: Fast realistic lidar point cloud generation. InECCV, 2025. 3
work page 2025
-
[29]
VEGS: View extrapolation of ur- ban scenes in 3d gaussian splatting using learned priors
Sungwon Hwang, Min-Jung Kim, Taewoong Kang, Jayeon Kang, and Jaegul Choo. VEGS: View extrapolation of ur- ban scenes in 3d gaussian splatting using learned priors. arXiv, 2024. 2, 3
work page 2024
-
[30]
Image-to-image translation with conditional adver- sarial networks
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. Image-to-image translation with conditional adver- sarial networks. InCVPR, 2017. 4
work page 2017
-
[31]
Codenerf: Disentan- gled neural radiance fields for object categories
Wonbong Jang and Lourdes Agapito. Codenerf: Disentan- gled neural radiance fields for object categories. InICCV,
-
[32]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InCVPR, 2019. 2
work page 2019
-
[33]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 2023. 22
work page 2023
-
[34]
Autosplat: Constrained gaussian splatting for autonomous driving scene reconstruction.arXiv, 2024
Mustafa Khan, Hamidreza Fazlali, Dhruv Sharma, Tong- tong Cao, Dongfeng Bai, Yuan Ren, and Bingbing Liu. Autosplat: Constrained gaussian splatting for autonomous driving scene reconstruction.arXiv, 2024. 1, 2
work page 2024
-
[35]
Auto-encoding variational bayes
Diederik P Kingma. Auto-encoding variational bayes. arXiv, 2013. 3, 5, 13
work page 2013
-
[36]
Adam: A method for stochastic optimization.ICLR, 2015
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.ICLR, 2015. 14
work page 2015
-
[37]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. InICCV, 2023. 6, 15, 16
work page 2023
-
[38]
Instant3d: Fast text-to-3d with sparse-view generation and large reconstruction model
Jiahao Li, Hao Tan, Kai Zhang, Zexiang Xu, Fujun Luan, Yinghao Xu, Yicong Hong, Kalyan Sunkavalli, Greg Shakhnarovich, and Sai Bi. Instant3d: Fast text-to-3d with sparse-view generation and large reconstruction model. arXiv, 2023. 3
work page 2023
-
[39]
Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chong- hao Sima, Tong Lu, Yu Qiao, and Jifeng Dai. Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers. InECCV, 2022. 8
work page 2022
-
[40]
Magic3d: High- resolution text-to-3d content creation
Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. Magic3d: High- resolution text-to-3d content creation. InCVPR, 2023. 2, 3
work page 2023
-
[41]
Neural scene rasterization for large scene rendering in real time
Jeffrey Yunfan Liu, Yun Chen, Ze Yang, Jingkang Wang, Sivabalan Manivasagam, and Raquel Urtasun. Neural scene rasterization for large scene rendering in real time. InICCV,
-
[42]
Minghua Liu, Chao Xu, Haian Jin, Linghao Chen, Mukund Varma T, Zexiang Xu, and Hao Su. One-2-3-45: Any sin- gle image to 3d mesh in 45 seconds without per-shape op- timization.NeurIPS, 2024. 3
work page 2024
-
[43]
Meshformer: High- quality mesh generation with 3d-guided reconstruction model.arXiv, 2024
Minghua Liu, Chong Zeng, Xinyue Wei, Ruoxi Shi, Ling- hao Chen, Chao Xu, Mengqi Zhang, Zhaoning Wang, Xi- aoshuai Zhang, Isabella Liu, et al. Meshformer: High- quality mesh generation with 3d-guided reconstruction model.arXiv, 2024. 20
work page 2024
-
[44]
Zero-1-to-3: Zero-shot one image to 3d object
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tok- makov, Sergey Zakharov, and Carl V ondrick. Zero-1-to-3: Zero-shot one image to 3d object. InICCV, 2023. 3
work page 2023
-
[45]
Meshdif- fusion: Score-based generative 3d mesh modeling.arXiv,
Zhen Liu, Yao Feng, Michael J Black, Derek Nowrouzezahrai, Liam Paull, and Weiyang Liu. Meshdif- fusion: Score-based generative 3d mesh modeling.arXiv,
-
[46]
Wonder3d: Single image to 3d using cross-domain diffusion
Xiaoxiao Long, Yuan-Chen Guo, Cheng Lin, Yuan Liu, Zhiyang Dou, Lingjie Liu, Yuexin Ma, Song-Hai Zhang, Marc Habermann, Christian Theobalt, et al. Wonder3d: Single image to 3d using cross-domain diffusion. InCVPR,
-
[47]
Diffusion probabilistic models for 3d point cloud generation
Shitong Luo and Wei Hu. Diffusion probabilistic models for 3d point cloud generation. InCVPR, 2021. 3
work page 2021
-
[48]
Towards zero domain gap: A comprehensive study of realistic lidar simulation for autonomy testing
Sivabalan Manivasagam, Ioan Andrei B ˆarsan, Jingkang Wang, Ze Yang, and Raquel Urtasun. Towards zero domain gap: A comprehensive study of realistic lidar simulation for autonomy testing. InICCV, 2023. 1
work page 2023
-
[49]
Lt3sd: Latent trees for 3d scene diffusion.arXiv, 2024
Quan Meng, Lei Li, Matthias Nießner, and Angela Dai. Lt3sd: Latent trees for 3d scene diffusion.arXiv, 2024. 3
work page 2024
-
[50]
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view syn- thesis.Communications of the ACM, 2021. 2
work page 2021
-
[51]
Autorf: Learning 3d object radiance fields from single view observations
Norman M ¨uller, Andrea Simonelli, Lorenzo Porzi, Samuel Rota Bul `o, Matthias Nießner, and Peter Kontschieder. Autorf: Learning 3d object radiance fields from single view observations. InCVPR, 2022. 2
work page 2022
-
[52]
Diffrf: Rendering-guided 3d radiance field diffusion
Norman M ¨uller, Yawar Siddiqui, Lorenzo Porzi, Samuel Rota Bulo, Peter Kontschieder, and Matthias Nießner. Diffrf: Rendering-guided 3d radiance field diffusion. InCVPR, 2023. 2, 3, 5, 6
work page 2023
-
[53]
Extracting triangular 3d models, materials, and lighting from images
Jacob Munkberg, Jon Hasselgren, Tianchang Shen, Jun Gao, Wenzheng Chen, Alex Evans, Thomas M ¨uller, and Sanja Fidler. Extracting triangular 3d models, materials, and lighting from images. InCVPR, 2022. 2
work page 2022
-
[54]
Giraffe: Repre- senting scenes as compositional generative neural feature fields
Michael Niemeyer and Andreas Geiger. Giraffe: Repre- senting scenes as compositional generative neural feature fields. InCVPR, 2021. 2
work page 2021
-
[55]
Au- todecoding latent 3d diffusion models.NeurIPS, 2023
Evangelos Ntavelis, Aliaksandr Siarohin, Kyle Olszewski, Chaoyang Wang, Luc V Gool, and Sergey Tulyakov. Au- todecoding latent 3d diffusion models.NeurIPS, 2023. 2, 3
work page 2023
-
[56]
Unisurf: Unifying neural implicit surfaces and radiance fields for multi-view reconstruction
Michael Oechsle, Songyou Peng, and Andreas Geiger. Unisurf: Unifying neural implicit surfaces and radiance fields for multi-view reconstruction. InICCV, 2021. 2
work page 2021
-
[57]
Neural scene graphs for dynamic scenes
Julian Ost, Fahim Mannan, Nils Thuerey, Julian Knodt, and Felix Heide. Neural scene graphs for dynamic scenes. In CVPR, 2021. 2
work page 2021
-
[58]
SDXL: Improving latent diffusion mod- els for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. SDXL: Improving latent diffusion mod- els for high-resolution image synthesis. InICLR, 2024. 3
work page 2024
-
[59]
Dreamfusion: Text-to-3d using 2d diffusion.arXiv,
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Milden- hall. Dreamfusion: Text-to-3d using 2d diffusion.arXiv,
-
[60]
Neural lighting simulation for urban scenes
Ava Pun, Gary Sun, Jingkang Wang, Yun Chen, Ze Yang, Sivabalan Manivasagam, Wei-Chiu Ma, and Raquel Ur- tasun. Neural lighting simulation for urban scenes. In NeurIPS, 2023. 2, 22
work page 2023
-
[61]
Towards realis- tic scene generation with lidar diffusion models
Haoxi Ran, Vitor Guizilini, and Yue Wang. Towards realis- tic scene generation with lidar diffusion models. InCVPR,
-
[62]
Xcube: Large-scale 3d generative modeling using sparse voxel hierarchies
Xuanchi Ren, Jiahui Huang, Xiaohui Zeng, Ken Museth, Sanja Fidler, and Francis Williams. Xcube: Large-scale 3d generative modeling using sparse voxel hierarchies. In CVPR, 2024. 3 10
work page 2024
-
[63]
SCube: Instant large-scale scene reconstruc- tion using voxsplats.arXiv, 2024
Xuanchi Ren, Yifan Lu, Hanxue Liang, Zhangjie Wu, Huan Ling, Mike Chen, Sanja Fidler, Francis Williams, and Ji- ahui Huang. SCube: Instant large-scale scene reconstruc- tion using voxsplats.arXiv, 2024. 2
work page 2024
-
[64]
L3dg: Latent 3d gaussian diffusion
Barbara Roessle, Norman M ¨uller, Lorenzo Porzi, Samuel Rota Bul `o, Peter Kontschieder, Angela Dai, and Matthias Nießner. L3dg: Latent 3d gaussian diffusion. arXiv, 2024. 2, 3
work page 2024
-
[65]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, 2022. 2, 3, 5
work page 2022
-
[66]
Lgsvl simulator: A high fidelity simulator for autonomous driving
Guodong Rong, Byung Hyun Shin, Hadi Tabatabaee, Qiang Lu, Steve Lemke, M ¯artin ¸ˇs Mo ˇzeiko, Eric Boise, Geehoon Uhm, Mark Gerow, and Shalin Mehta. Lgsvl simulator: A high fidelity simulator for autonomous driving. InITSC,
-
[67]
U- net: Convolutional networks for biomedical image segmen- tation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U- net: Convolutional networks for biomedical image segmen- tation. InMICCAI, 2015. 3, 5, 13
work page 2015
-
[68]
Progressive distillation for fast sampling of diffusion models.arXiv, 2022
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models.arXiv, 2022. 13
work page 2022
-
[69]
Adv3d: Gener- ating safety-critical 3d objects through closed-loop simula- tion
Jay Sarva, Jingkang Wang, James Tu, Yuwen Xiong, Siva- balan Manivasagam, and Raquel Urtasun. Adv3d: Gener- ating safety-critical 3d objects through closed-loop simula- tion. InCoRL, 2023. 1
work page 2023
-
[70]
AirSim: High-fidelity visual and physical simula- tion for autonomous vehicles
Shital Shah, Debadeepta Dey, Chris Lovett, and Ashish Kapoor. AirSim: High-fidelity visual and physical simula- tion for autonomous vehicles. InField and service robotics,
-
[71]
Gina-3d: Learning to generate implicit neural assets in the wild
Bokui Shen, Xinchen Yan, Charles R Qi, Mahyar Najibi, Boyang Deng, Leonidas Guibas, Yin Zhou, and Dragomir Anguelov. Gina-3d: Learning to generate implicit neural assets in the wild. InCVPR, 2023. 2
work page 2023
-
[72]
Mvdream: Multi-view diffusion for 3d generation.arXiv, 2023
Yichun Shi, Peng Wang, Jianglong Ye, Mai Long, Kejie Li, and Xiao Yang. Mvdream: Multi-view diffusion for 3d generation.arXiv, 2023. 3
work page 2023
-
[73]
3d neural field genera- tion using triplane diffusion
J Ryan Shue, Eric Ryan Chan, Ryan Po, Zachary Ankner, Jiajun Wu, and Gordon Wetzstein. 3d neural field genera- tion using triplane diffusion. InCVPR, 2023. 3, 5
work page 2023
-
[74]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. InICML, 2015. 5
work page 2015
-
[75]
Denois- ing diffusion implicit models.arXiv, 2020
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denois- ing diffusion implicit models.arXiv, 2020. 3, 5
work page 2020
-
[76]
Score- based generative modeling through stochastic differential equations.arXiv, 2020
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score- based generative modeling through stochastic differential equations.arXiv, 2020. 3, 5
work page 2020
-
[77]
Viewset diffusion:(0-) image-conditioned 3d gen- erative models from 2d data
Stanislaw Szymanowicz, Christian Rupprecht, and Andrea Vedaldi. Viewset diffusion:(0-) image-conditioned 3d gen- erative models from 2d data. InICCV, 2023. 3
work page 2023
-
[78]
Block-nerf: Scalable large scene neural view synthesis
Matthew Tancik, Vincent Casser, Xinchen Yan, Sabeek Pradhan, Ben Mildenhall, Pratul P Srinivasan, Jonathan T Barron, and Henrik Kretzschmar. Block-nerf: Scalable large scene neural view synthesis. InCVPR, 2022. 1
work page 2022
-
[79]
Dreamgaussian: Generative gaussian splatting for efficient 3d content creation.arXiv, 2023
Jiaxiang Tang, Jiawei Ren, Hang Zhou, Ziwei Liu, and Gang Zeng. Dreamgaussian: Generative gaussian splatting for efficient 3d content creation.arXiv, 2023. 3
work page 2023
-
[80]
Lgm: Large multi-view gaussian model for high-resolution 3d content creation
Jiaxiang Tang, Zhaoxi Chen, Xiaokang Chen, Tengfei Wang, Gang Zeng, and Ziwei Liu. Lgm: Large multi-view gaussian model for high-resolution 3d content creation. In ECCV, 2025. 3
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.