RAT: RunAnyThing via Fully Automated Environment Configuration
Pith reviewed 2026-05-08 08:01 UTC · model grok-4.3
The pith
RAT enables fully automated environment configuration for arbitrary software repositories using a language-agnostic multi-stage pipeline.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that the RAT framework, through its multi-stage pipeline of semantic initialization, planning, specialized toolset, and robust sandbox, achieves state-of-the-art performance on automated environment configuration for arbitrary repositories, raising the Environment Setup Success Rate by an average of 29.6 percent compared with strong baselines when tested on RATBench, a benchmark that mirrors the distribution and heterogeneity of real-world codebases.
What carries the argument
The RAT multi-stage pipeline that integrates semantic initialization for repository understanding, a planning mechanism for step sequencing, specialized tools for configuration actions, and a sandbox for safe execution and validation.
Load-bearing premise
The multi-stage pipeline can reliably handle the varied structures, dependencies, and heterogeneity of arbitrary real-world repositories without manual intervention or language-specific restrictions.
What would settle it
A large-scale test on repositories with unusual or non-standard dependency setups where RAT's Environment Setup Success Rate falls to or below the level of existing baselines.
Figures

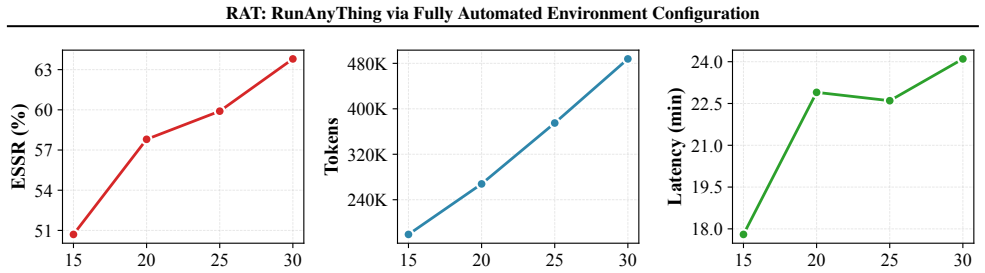
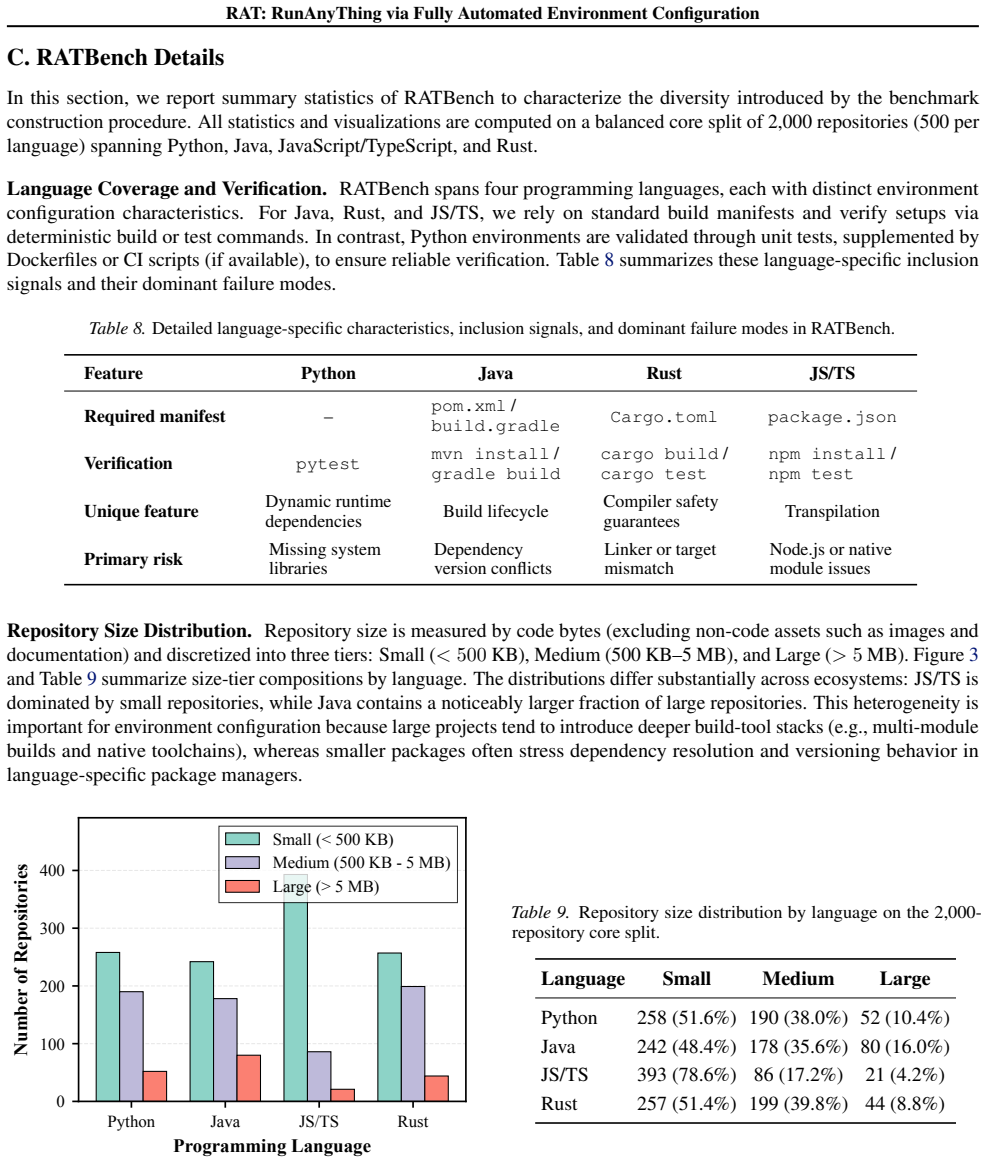
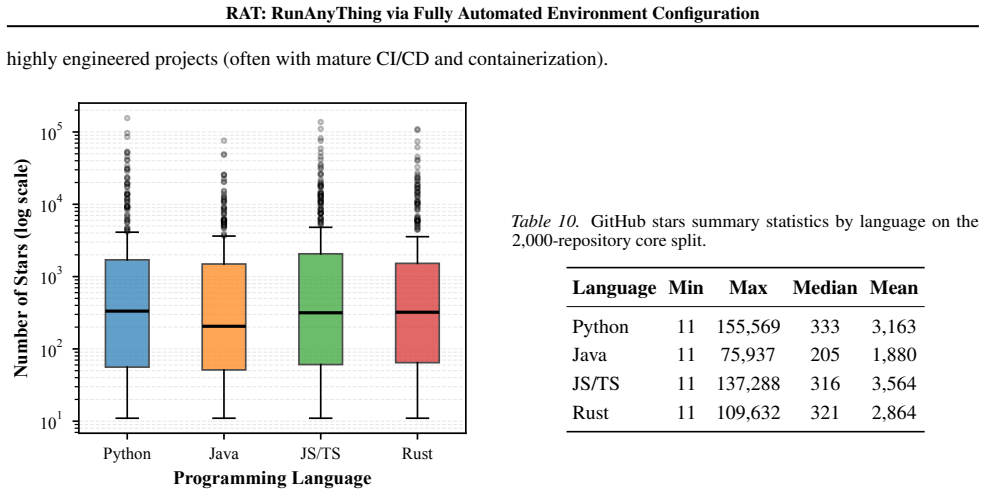


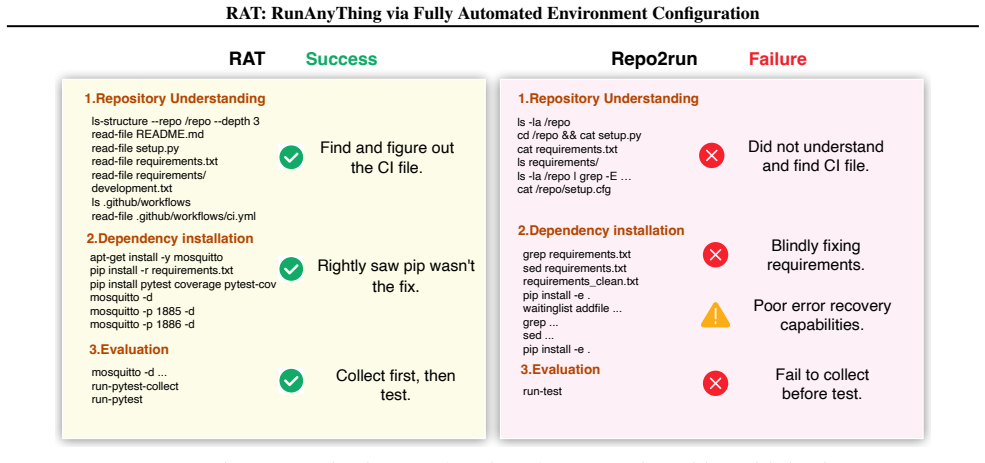

read the original abstract
Automating repository-level software engineering tasks is a foundational challenge for autonomous code agents, largely due to the difficulty of configuring executable environments. However, manual configuration remains a labor-intensive bottleneck, necessitating a transition toward fully automated environment configuration. Existing approaches often rely on pre-defined artifacts or are restricted to specific programming languages, limiting their applicability to diverse real-world repositories. In this paper, we first propose RAT (RunAnyThing), a modular and extensible agent framework for fully automated configuration across programming languages on arbitrary repositories. RAT adopts a multi-stage pipeline that integrates language-aware abstraction, image initialization, specialized configuration toolset, and robust sandbox. Furthermore, to enable rigorous evaluation, we propose RATBench, a benchmark reflects the comprehensive coverage of real-world repositories. Extensive experiments demonstrate that RAT achieves state-of-the-art performance, improving Environment Setup Success Rate (ESSR) by an average of 36.1% over strong baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RAT (RunAnyThing), a language-agnostic multi-stage pipeline for fully automated environment configuration of arbitrary repositories. The pipeline integrates semantic initialization, planning, a specialized toolset, and a sandbox. To support evaluation, the authors introduce RATBench, a benchmark intended to capture the distribution and heterogeneity of real-world repositories. Extensive experiments are claimed to demonstrate state-of-the-art performance, with RAT improving Environment Setup Success Rate (ESSR) by an average of 29.6% over strong baselines.
Significance. If the empirical claims hold under rigorous scrutiny, the work would meaningfully advance autonomous code agents by addressing the manual environment-configuration bottleneck that currently limits repository-level tasks. The introduction of RATBench as a benchmark reflecting real-world heterogeneity is a constructive contribution that could enable more standardized future evaluations. The language-agnostic design is also a strength relative to prior language-restricted approaches.
major comments (3)
- [Experiments] Experiments section: The headline 29.6% average ESSR improvement is reported without error bars, standard deviations, number of runs, or statistical significance tests. This makes it impossible to determine whether the gain is robust or could be explained by variance in the chosen repositories.
- [§3] §3 (RATBench construction): The repository sampling procedure, exact definition of the ESSR success criterion ('environment fully executable for downstream tasks'), and controls for curation bias are not described in sufficient detail. Without these, it cannot be verified that RATBench faithfully represents the long tail of dependency, build-system, and language heterogeneity.
- [Experiments] Baseline re-implementation details (Experiments section): The paper does not specify how the 'strong baselines' were re-implemented, including whether they received equivalent tool access, sandbox tolerances, or planning capabilities. This information is load-bearing for the SOTA claim.
minor comments (2)
- [Abstract] Abstract: 'reflects the the distribution' contains a duplicated word.
- [Abstract] The first use of the ESSR acronym should be accompanied by its expansion for clarity.
Simulated Author's Rebuttal
We are grateful to the referee for providing detailed and constructive feedback that will help improve the clarity and rigor of our paper. Below, we respond to each major comment and indicate the corresponding revisions.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The headline 29.6% average ESSR improvement is reported without error bars, standard deviations, number of runs, or statistical significance tests. This makes it impossible to determine whether the gain is robust or could be explained by variance in the chosen repositories.
Authors: We agree that the current reporting of the 29.6% average ESSR improvement lacks the statistical details necessary to assess robustness. In the revised manuscript, we will expand the Experiments section to include error bars (standard deviation across runs), explicitly state the number of independent runs performed per repository, and report the results of statistical significance tests (such as paired t-tests or Wilcoxon signed-rank tests) comparing RAT against each baseline. These additions will allow readers to evaluate whether the observed gains are statistically reliable rather than attributable to variance. revision: yes
-
Referee: [§3] §3 (RATBench construction): The repository sampling procedure, exact definition of the ESSR success criterion ('environment fully executable for downstream tasks'), and controls for curation bias are not described in sufficient detail. Without these, it cannot be verified that RATBench faithfully represents the long tail of dependency, build-system, and language heterogeneity.
Authors: We acknowledge that Section 3 would benefit from greater specificity to substantiate RATBench's representativeness. We will revise this section to detail: (1) the repository sampling procedure, including data sources, filtering criteria (e.g., by language, build system, dependency complexity, and activity level), and stratification to capture heterogeneity; (2) the precise operational definition of the ESSR success criterion, specifying the exact conditions for an environment to be deemed 'fully executable for downstream tasks' (e.g., successful dependency resolution, build completion, and execution of representative scripts or tests); and (3) controls for curation bias, such as quantitative diversity metrics across languages and build systems. These clarifications will better demonstrate alignment with real-world repository distributions. revision: yes
-
Referee: [Experiments] Baseline re-implementation details (Experiments section): The paper does not specify how the 'strong baselines' were re-implemented, including whether they received equivalent tool access, sandbox tolerances, or planning capabilities. This information is load-bearing for the SOTA claim.
Authors: We recognize that transparent baseline re-implementation details are critical to supporting the SOTA claim. In the revised Experiments section, we will provide a dedicated subsection describing the re-implementation of each baseline, including the exact tool access granted, sandbox configurations and tolerances applied, and any planning or reasoning modules provided. We will also note and justify any necessary differences arising from RAT's language-agnostic design. This will enable a clear assessment of fairness in the comparisons. revision: yes
Circularity Check
No circularity: empirical performance claims rest on external benchmark comparisons
full rationale
The paper introduces RAT as a multi-stage pipeline for automated environment configuration and RATBench as a new benchmark reflecting real-world repository distributions, then reports an empirical 29.6% ESSR improvement over baselines. No equations, parameter fits, or derivations appear in the provided text; the central result is an experimental outcome from running the system on the benchmark rather than any quantity defined in terms of itself or reduced via self-citation. The pipeline components (semantic initialization, planning, tools, sandbox) are presented as design choices evaluated externally, with no load-bearing uniqueness theorems or ansatzes imported from prior author work. This is a standard empirical software-engineering paper whose validity hinges on benchmark representativeness and baseline fairness, not on internal definitional closure.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantic analysis of repository contents can determine required environment configurations across languages.
invented entities (1)
-
RAT multi-stage pipeline
no independent evidence
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.