RaV-IDP: A Reconstruction-as-Validation Framework for Faithful Intelligent Document Processing
Pith reviewed 2026-05-08 06:34 UTC · model grok-4.3
The pith
Document extraction can be validated by reconstructing each entity and scoring its fidelity against the unmodified original region.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
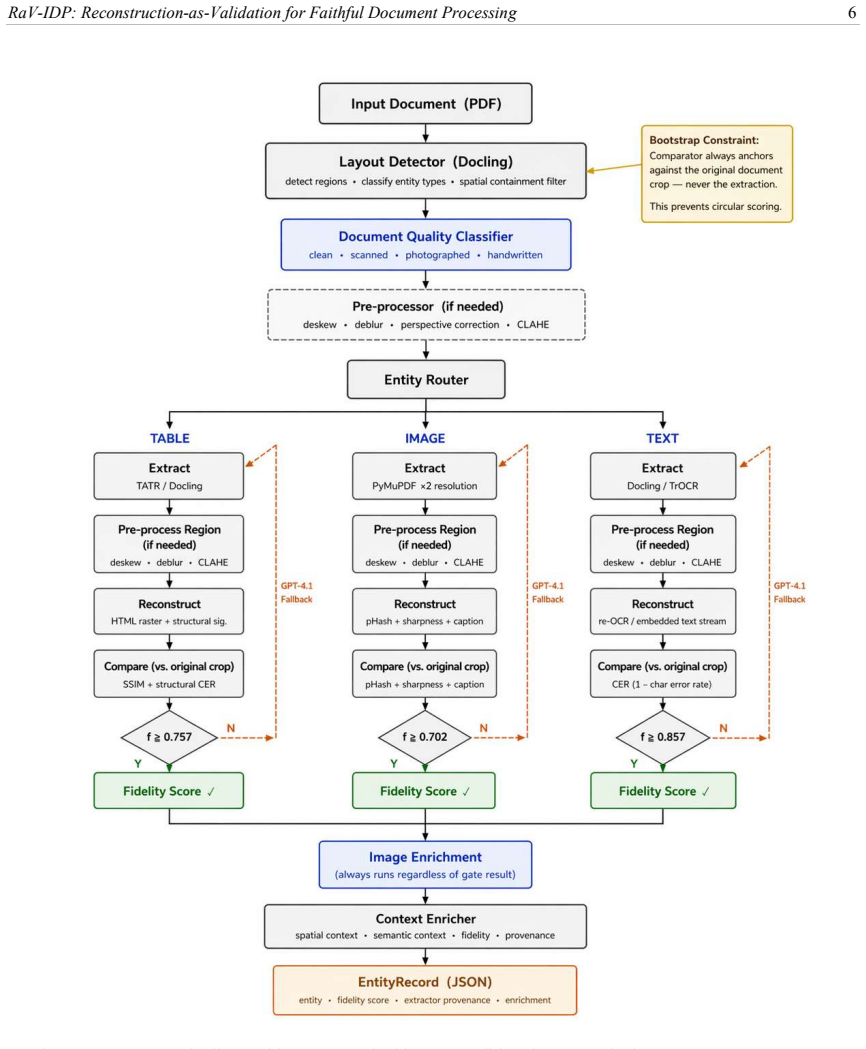
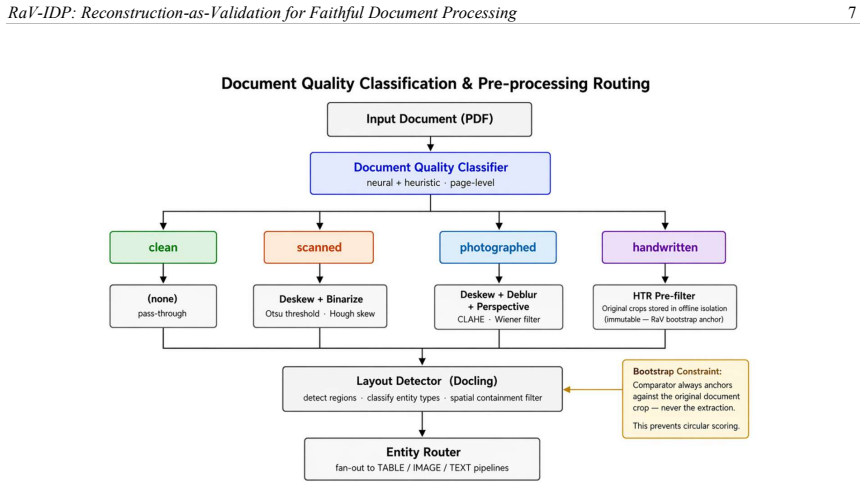
After each entity is extracted, a dedicated reconstructor renders the extracted representation back into a form comparable to the original document region. A comparator then scores fidelity between this reconstruction and the unmodified source crop. The resulting fidelity score functions as a grounded, label-free quality signal. When the score falls below a per-entity-type threshold, a structured GPT-4.1 vision fallback is triggered and the validation loop repeats. The comparator is required to anchor exclusively against the original document region, never against the extraction, to prevent circularity.
What carries the argument
The reconstruction-as-validation loop: a reconstructor renders the extracted entity back into a comparable visual form, a comparator computes fidelity against the original document crop, and low scores trigger iterative GPT-4.1 vision correction under a bootstrap constraint that anchors comparisons to the source.
If this is right
- Extractions with low fidelity are intercepted before reaching knowledge bases, RAG systems, or analytics.
- The validation loop can iterate using vision fallbacks until an acceptable fidelity threshold is reached.
- Per-entity-type thresholds allow different validation standards for tables, images, and text.
- Each pipeline stage can be evaluated with benchmarks matched to its specific function.
Where Pith is reading between the lines
- The method offers a route to reduce silent error propagation in large-scale automated document analysis.
- Similar reconstruction-based checks could be tested on other multimodal extraction tasks such as chart or diagram parsing.
- Repeated fallback loops may surface patterns that allow the extraction models themselves to improve over time.
Load-bearing premise
A dedicated reconstructor can render an extracted entity in a form that lets the comparator produce a fidelity score reflecting true extraction faithfulness rather than reconstructor artifacts.
What would settle it
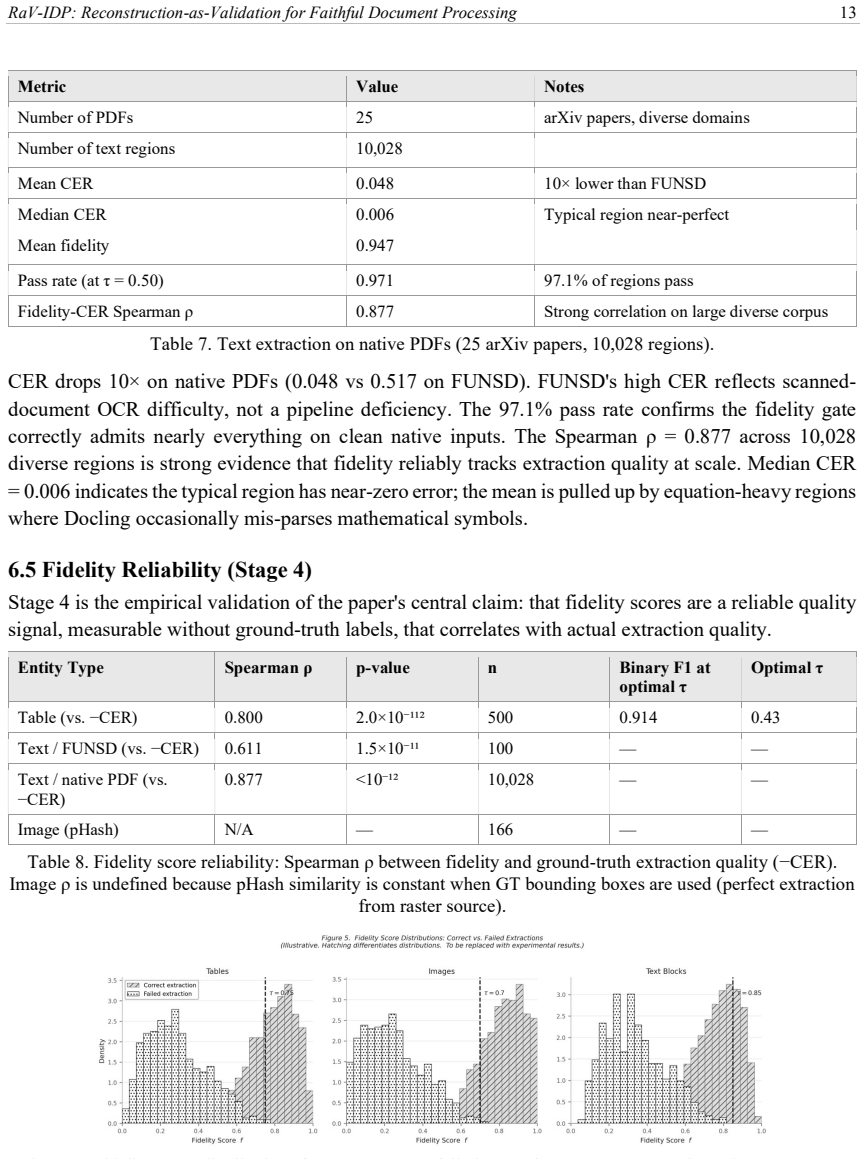
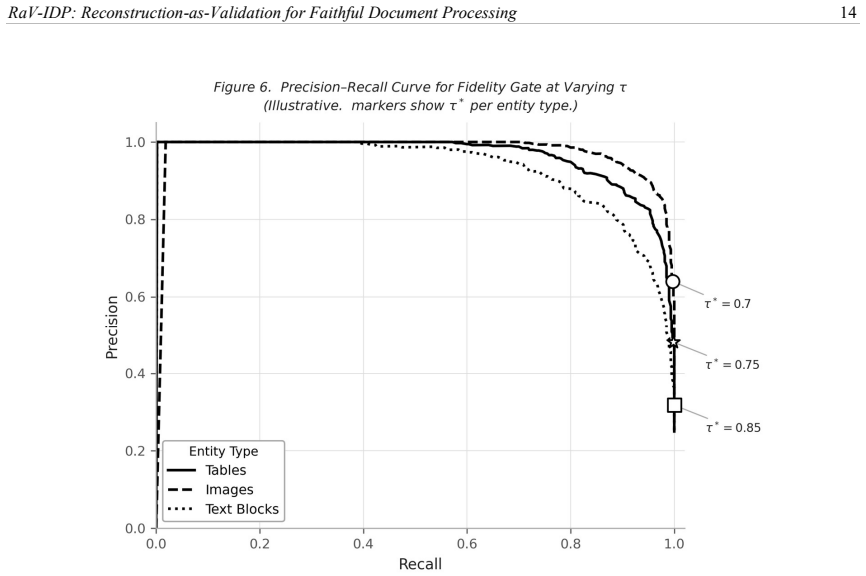
Finding many cases where reconstructions match the source well even though the original extractions contain clear errors, or where fidelity scores show poor agreement with human judgments of faithfulness.
Figures



read the original abstract
Intelligent document processing pipelines extract structured entities (tables, images, and text) from documents for use in downstream systems such as knowledge bases, retrieval-augmented generation, and analytics. A persistent limitation of existing pipelines is that extraction output is produced without any intrinsic mechanism to verify whether it faithfully represents the source. Model-internal confidence scores measure inference certainty, not correspondence to the document, and extraction errors pass silently into downstream consumers. We present Reconstruction as Validation (RaV-IDP), a document processing pipeline that introduces reconstruction as a first-class architectural component. After each entity is extracted, a dedicated reconstructor renders the extracted representation back into a form comparable to the original document region, and a comparator scores fidelity between the reconstruction and the unmodified source crop. This fidelity score is a grounded, label-free quality signal. When fidelity falls below a per-entity-type threshold, a structured GPT-4.1 vision fallback is triggered and the validation loop repeats. We enforce a bootstrap constraint: the comparator always anchors against the original document region, never against the extraction, preventing the validation from becoming circular. We further propose a per-stage evaluation framework pairing each pipeline component with an appropriate benchmark. The code pipeline is publicly available at https://github.com/pritesh-2711/RaV-IDP for experimentation and use.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RaV-IDP, a reconstruction-as-validation framework for intelligent document processing pipelines. After extracting structured entities (tables, images, text), a dedicated reconstructor renders the extraction back into a visual form comparable to the original document crop; a comparator then computes a fidelity score between this reconstruction and the unmodified source region. Low fidelity triggers a structured GPT-4.1 vision fallback, with the loop repeating until the score is acceptable. A bootstrap constraint ensures the comparator always anchors to the original crop (never the extraction) to avoid circularity. The authors also outline a per-stage evaluation framework pairing pipeline components with benchmarks and release the implementation at https://github.com/pritesh-2711/RaV-IDP.
Significance. If the fidelity score can be shown to reflect extraction faithfulness rather than reconstructor artifacts, the framework would supply a practical, label-free mechanism for detecting and correcting silent errors in IDP systems before they reach downstream tasks such as RAG or knowledge-base population. The explicit bootstrap constraint directly addresses the most obvious circularity risk, and the public code release enables immediate experimentation and extension by the community.
major comments (2)
- [Abstract] Abstract and framework description: the central claim that the fidelity score constitutes a 'grounded, label-free quality signal' is unsupported by any empirical results, ablation studies, or quantitative correlation analysis showing that low fidelity corresponds to actual extraction errors rather than reconstructor imperfections. For complex entities (tables with layout, fine-detail images), reconstructor artifacts could dominate the score even when the extraction is correct, rendering the per-entity threshold and GPT-4.1 fallback unreliable.
- [Proposed per-stage evaluation framework] Proposed per-stage evaluation framework: although the manuscript outlines pairing each pipeline stage with an appropriate benchmark, no application of this framework, no benchmark results, and no demonstration that the fidelity score improves end-to-end extraction accuracy are provided. This leaves the load-bearing assumption that reconstruction-based validation improves faithfulness untested.
minor comments (2)
- The implementation details of the dedicated reconstructor (architecture, training objective, handling of layout-preserving entities) are not specified, which would be required for reproducibility even with the released code.
- [Abstract] Clarify how the per-entity-type threshold is chosen or adapted; the current description leaves open whether it is a fixed hyperparameter or learned, affecting claims of being largely parameter-free.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments correctly identify that the current manuscript is primarily a framework proposal without supporting experiments. We will perform a major revision that adds the requested empirical analyses, ablations, and benchmark applications to substantiate the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract and framework description: the central claim that the fidelity score constitutes a 'grounded, label-free quality signal' is unsupported by any empirical results, ablation studies, or quantitative correlation analysis showing that low fidelity corresponds to actual extraction errors rather than reconstructor imperfections. For complex entities (tables with layout, fine-detail images), reconstructor artifacts could dominate the score even when the extraction is correct, rendering the per-entity threshold and GPT-4.1 fallback unreliable.
Authors: We agree that the manuscript does not yet contain empirical evidence or ablations demonstrating that the fidelity score tracks extraction errors rather than reconstructor artifacts, especially for complex entities. This is a substantive gap. In the revision we will add a dedicated experimental section with quantitative correlation analysis on labeled extraction errors, reconstructor ablations, and per-entity threshold sensitivity tests. We will also revise the abstract and framework description to present the fidelity score as a designed grounded signal whose reliability is now supported by the new results rather than asserted a priori. revision: yes
-
Referee: [Proposed per-stage evaluation framework] Proposed per-stage evaluation framework: although the manuscript outlines pairing each pipeline stage with an appropriate benchmark, no application of this framework, no benchmark results, and no demonstration that the fidelity score improves end-to-end extraction accuracy are provided. This leaves the load-bearing assumption that reconstruction-based validation improves faithfulness untested.
Authors: We accept that the per-stage evaluation framework is described but not executed in the current manuscript, leaving the end-to-end benefit untested. The revision will instantiate the framework by reporting benchmark results for the extractor, reconstructor, and comparator stages, followed by an end-to-end ablation that measures extraction accuracy with and without the RaV-IDP validation loop on standard IDP datasets. These results will directly test whether the reconstruction-based validation improves faithfulness. revision: yes
Circularity Check
No significant circularity detected in the framework derivation
full rationale
The paper presents RaV-IDP as an architectural framework rather than a mathematical derivation with predictions or first-principles results. The central mechanism—reconstruction followed by fidelity comparison—is defined with an explicit bootstrap constraint that anchors the comparator to the unmodified original document region, not the extraction. This directly prevents self-referential validation loops by construction. No equations, fitted parameters renamed as predictions, self-citations as load-bearing premises, or ansatzes smuggled via prior work appear in the text. The method's validity rests on external assumptions about reconstructor quality (addressed as a separate risk), but these do not reduce the claimed validation signal to the inputs by definition. The per-stage evaluation framework is proposed without circular reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- per-entity-type threshold
axioms (2)
- domain assumption Reconstruction of an extracted entity can be rendered into a form directly comparable to the original document crop.
- domain assumption The comparator's fidelity score reflects extraction quality rather than reconstructor limitations.
Reference graph
Works this paper leans on
-
[1]
Das, S., Ma, K., Shu, Z., Natarajan, P., Manmatha, R. (2019). DewarpNet: Single-image document unwarping with stacked 3D and 2D regression networks. ICCV 2019
work page 2019
-
[2]
Feng, H., Wang, Y., Zhou, J., Deng, J., Tian, Q. (2021). DocTr: Document image transformer for geometric unwarping and illumination correction. ACM MM 2021
work page 2021
-
[3]
Guo, C., Pleiss, G., Sun, Y., Weinberger, K.Q. (2017). On calibration of modern neural networks. ICML 2017
work page 2017
-
[4]
Huang, Y., Lv, T., Cui, L., Lu, Y., Wei, F. (2022). LayoutLMv3: Pre-training for document AI with unified text and image masking. ACM MM 2022
work page 2022
-
[5]
IBM Research. (2024). Docling: A document conversion library
work page 2024
-
[6]
Li, J., Xu, Y., Lv, T., Cui, L., Zhang, C., Wei, F. (2022). DiT: Self-supervised pre-training for document image transformer. ACM MM 2022
work page 2022
- [7]
-
[8]
Microsoft. (2024). Azure AI Document Intelligence confidence scores documentation
work page 2024
-
[9]
Nayef, N., Shafait, F., Pal, U., Dengel, A. (2015). SmartDoc-QA: A dataset for quality assessment of smartphone captured document images. ICDAR 2015
work page 2015
-
[10]
Pfitzmann, B., Auer, C., Dolfi, M., Nassar, A.S., Staar, P.W.J. (2022). DocLayNet: A large human-annotated dataset for document-layout segmentation. KDD 2022
work page 2022
-
[11]
Pizer, S.M., et al. (1987). Adaptive histogram equalization and its variations. Computer Vision, Graphics, and Image Processing, 39(3)
work page 1987
-
[12]
Pratikakis, I., et al. (2013-2019). DIBCO: Document Image Binarization Contest (various years). ICDAR
work page 2013
-
[13]
Riedl, A., et al. (2025). Tabular context-aware OCR and reconstruction for historical documents. IJDAR 2025
work page 2025
-
[14]
Smock, B., Pesala, R., Abraham, R. (2022). PubTables-1M: Towards comprehensive table extraction from unstructured documents. CVPR 2022
work page 2022
-
[15]
Wang, X., Xie, L., Dong, C., Shan, Y. (2021). Real-ESRGAN: Training real-world blind super-resolution with pure synthetic data. ICCV Workshops 2021
work page 2021
-
[16]
Xu, Y., Li, M., Cui, L., Huang, S., Wei, F., Zhou, M. (2020). LayoutLM: Pre-training of text and layout for document image understanding. KDD 2020
work page 2020
-
[17]
Xu, Y., Xu, Y., Lv, T., Cui, L., Wei, F., Wang, G., Lu, Y. (2021). LayoutLMv2: Multi-modal pre-training for visually-rich document understanding. ACL-IJCNLP 2021
work page 2021
-
[18]
Xue, W., Yu, B., Wang, W., Tao, D., Li, Q. (2021). TGRNet: A table graph reconstruction network for table structure recognition. ICCV 2021
work page 2021
-
[19]
Zhang, Z., et al. (2022). Split, embed and merge: An accurate table structure recognizer. Pattern Recognition, 126
work page 2022
-
[20]
Zheng, X., et al. (2021). Global table extractor (GTE): A framework for joint table identification and cell structure recognition using visual context. WACV 2021
work page 2021
-
[21]
Llama 1” spanning four rows and “Llama 2
Zhong, X., Tang, J., Jimeno-Yepes, A. (2019). PubLayNet: Largest dataset for document layout analysis. ICDAR 2019. RaV-IDP: Reconstruction-as-Validation for Faithful Document Processing 20 Appendix A: End-to-End Pipeline Walkthrough This appendix presents a complete trace of the RaV-IDP pipeline on a single real document: page 6 of the LLaMA 2 research pa...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.