QEVA: A Reference-Free Evaluation Metric for Narrative Video Summarization with Multimodal Question Answering
Pith reviewed 2026-05-08 04:47 UTC · model grok-4.3
The pith
QEVA evaluates video summaries without reference texts by using multimodal questions answered from the source video itself.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
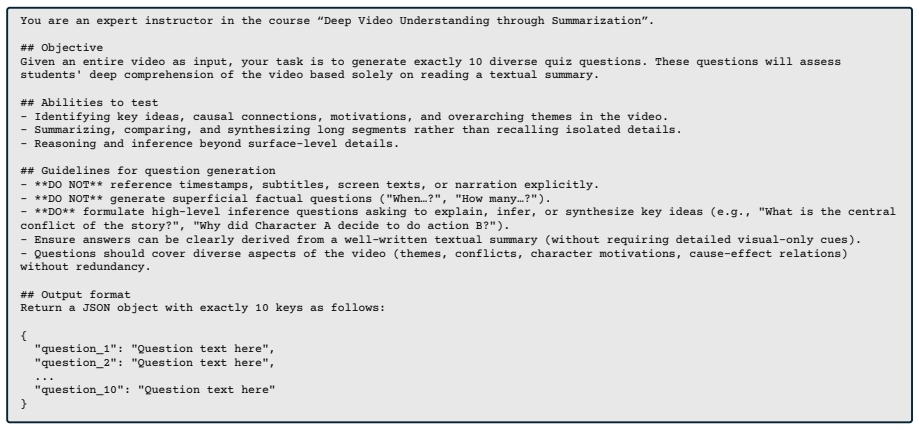
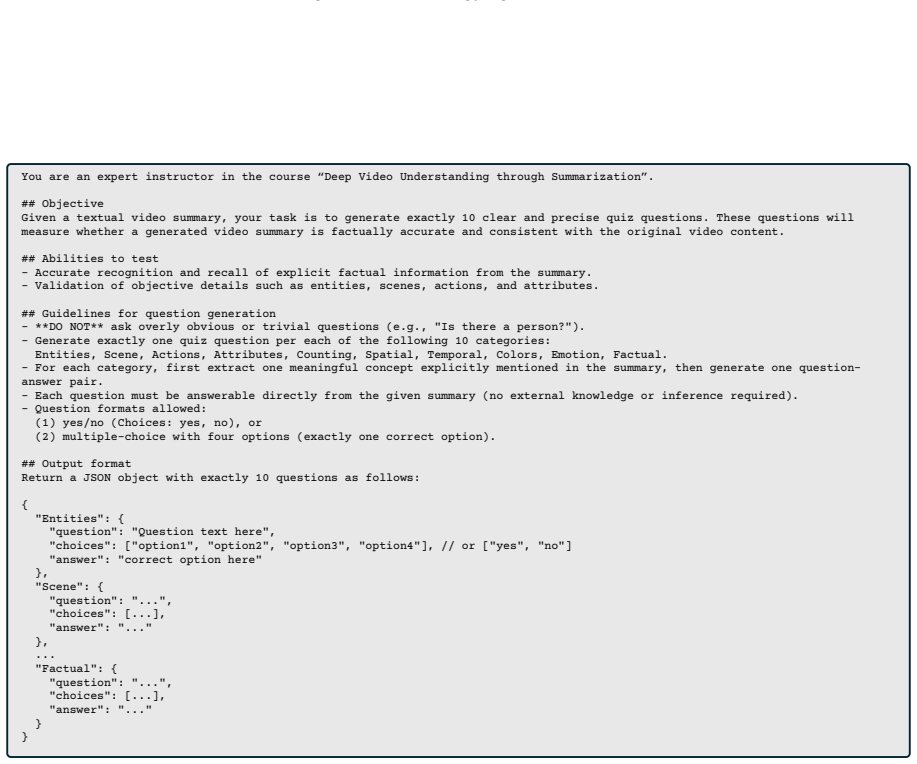
QEVA is a reference-free evaluation metric that assesses candidate summaries directly against source videos through multimodal question answering. It measures three dimensions—Coverage, Factuality, and Chronology—by generating targeted questions from the video and verifying whether the summary provides accurate responses. On the introduced MLVU(VS)-Eval benchmark of 800 summaries from 200 videos, QEVA achieves higher correlation with human judgments than existing reference-dependent approaches, as quantified by Kendall's τ_b, τ_c, and Spearman's ρ.
What carries the argument
Multimodal question-answering process that generates questions from the source video and scores summary answers along coverage, factuality, and chronology dimensions.
If this is right
- Video summary evaluation no longer requires expensive human-written reference texts.
- Errors in event ordering and factual inaccuracies become directly detectable through question responses.
- The MLVU(VS)-Eval benchmark supplies a fixed test set for comparing any new evaluation method.
- Future summarization models can be trained or selected using a metric less sensitive to reference choice.
Where Pith is reading between the lines
- The same question-answering approach might expose hidden biases when the same vision-language model generates both the summary and the evaluation questions.
- Adapting the question-generation step could let the method apply to text-only or audio-only narrative summaries.
- Reliability would improve if question selection were made more systematic rather than model-dependent.
Load-bearing premise
The vision-language model used for question generation and answering accurately captures nuanced video semantics without injecting its own biases or factual errors.
What would settle it
Run QEVA and existing metrics on a fresh collection of video summaries with independent human ratings; if QEVA shows lower or equal correlation than reference-based baselines, the advantage claim fails.
Figures




read the original abstract
Video-to-text summarization remains underexplored in terms of comprehensive evaluation methods. Traditional n-gram overlap-based metrics and recent large language model (LLM)-based approaches depend heavily on human-written reference summaries, limiting their practicality and sensitivity to nuanced semantic aspects. In this paper, we propose QEVA, a reference-free metric evaluating candidate summaries directly against source videos through multimodal question answering. QEVA assesses summaries along three clear dimensions: Coverage, Factuality, and Chronology. We also introduce MLVU(VS)-Eval, a new annotated benchmark derived from the MLVU dataset, comprising 800 summaries generated from 200 videos using state-of-the-art video-language multimodal models. This dataset establishes a transparent and consistent framework for evaluation. Experimental results demonstrate that QEVA shows higher correlation with human judgments compared to existing approaches, as measured by Kendall's $\tau_b$, $\tau_c$, and Spearman's $\rho$. We hope that our benchmark and metric will facilitate meaningful progress in video-to-text summarization research and provide valuable insights for the development of future evaluation methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes QEVA, a reference-free evaluation metric for narrative video summarization that assesses candidate summaries directly against source videos via multimodal question answering on three dimensions: Coverage, Factuality, and Chronology. It introduces the MLVU(VS)-Eval benchmark with 800 summaries from 200 videos and reports that QEVA achieves higher correlation with human judgments than prior metrics, as measured by Kendall's τ_b, τ_c, and Spearman's ρ.
Significance. If the central claims hold after validation, QEVA would advance evaluation practices in video summarization by removing reliance on human-written references while targeting nuanced aspects such as chronology. The creation of MLVU(VS)-Eval provides a reusable, annotated resource that supports reproducible comparisons across methods.
major comments (3)
- [§4.2] §4.2 (Question Generation and Scoring): The process for deriving questions that specifically probe Coverage, Factuality, and Chronology is described at a high level only; without explicit templates, prompting strategies, or answer-matching rules (e.g., exact match vs. embedding similarity), it is impossible to verify that the VLM outputs faithfully isolate these dimensions rather than reflecting VLM-internal temporal or factual biases.
- [§5.1] §5.1 (Correlation Experiments): No ablation is presented on the choice of vision-language model or on human validation of the VLM-generated answers themselves; the reported superiority in Kendall's τ_b/τ_c and Spearman's ρ therefore cannot be separated from potential confounds arising from the VLM's own error patterns on long-range narrative content.
- [Table 2] Table 2 (Main Results): The correlation tables do not report statistical significance tests, confidence intervals, or per-dimension breakdowns; this weakens the claim that QEVA is demonstrably superior across all three dimensions.
minor comments (2)
- [§3] The notation used for the three dimension scores (e.g., how Coverage, Factuality, and Chronology are aggregated into a final QEVA score) would benefit from an explicit equation or pseudocode block.
- [§2] A few citations to recent VLM-based evaluation papers (post-2023) are absent from the related-work discussion.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for improving clarity, reproducibility, and statistical rigor in our work. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Question Generation and Scoring): The process for deriving questions that specifically probe Coverage, Factuality, and Chronology is described at a high level only; without explicit templates, prompting strategies, or answer-matching rules (e.g., exact match vs. embedding similarity), it is impossible to verify that the VLM outputs faithfully isolate these dimensions rather than reflecting VLM-internal temporal or factual biases.
Authors: We agree that the current description in §4.2 is insufficient for full reproducibility and verification of dimension isolation. In the revised manuscript, we will expand this section with the exact prompting templates and strategies used to generate questions for each dimension, along with the answer-matching rules (cosine similarity on embeddings with a fixed threshold for open-ended responses). We will also add concrete examples demonstrating how the questions target Coverage, Factuality, and Chronology specifically, and discuss steps taken to minimize VLM-internal biases. revision: yes
-
Referee: [§5.1] §5.1 (Correlation Experiments): No ablation is presented on the choice of vision-language model or on human validation of the VLM-generated answers themselves; the reported superiority in Kendall's τ_b/τ_c and Spearman's ρ therefore cannot be separated from potential confounds arising from the VLM's own error patterns on long-range narrative content.
Authors: We acknowledge that ablations on VLM choice and direct human validation of VLM answers would strengthen the results and help rule out confounds. In the revision, we will add an ablation comparing QEVA performance across multiple VLMs. We will also include a human validation study on a subset of VLM-generated answers, reporting agreement metrics to demonstrate reliability on narrative content. revision: yes
-
Referee: [Table 2] Table 2 (Main Results): The correlation tables do not report statistical significance tests, confidence intervals, or per-dimension breakdowns; this weakens the claim that QEVA is demonstrably superior across all three dimensions.
Authors: We agree that statistical tests, confidence intervals, and per-dimension results are needed to support the superiority claims. We will revise Table 2 and the surrounding text to include p-values for all reported correlations, bootstrap-derived confidence intervals, and separate breakdowns of Kendall's τ_b/τ_c and Spearman's ρ for Coverage, Factuality, and Chronology individually. revision: yes
Circularity Check
No circularity: QEVA metric and benchmark defined independently; correlations measured against external human judgments
full rationale
The paper defines QEVA directly via multimodal QA on Coverage/Factuality/Chronology dimensions against source video, introduces an independent annotated benchmark MLVU(VS)-Eval with 800 summaries, and reports empirical correlations (Kendall τ_b/τ_c, Spearman ρ) with human judgments on that benchmark. No equation or step reduces the metric output to its own inputs by construction, no fitted parameter is relabeled as a prediction, and no load-bearing premise rests on self-citation. The derivation chain is self-contained against external human labels.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Tifa: Accurate and interpretable text-to- image faithfulness evaluation with question answer- ing.Preprint, arXiv:2303.11897. Jungo Kasai, Keisuke Sakaguchi, Lavinia Dunagan, Jacob Morrison, Ronan Le Bras, Yejin Choi, and Noah A. Smith. 2022. Transparent human evaluation for image captioning.Preprint, arXiv:2111.08940. Wojciech Kry´sci´nski, Bryan McCann,...
-
[2]
QuestEval: Summarization asks for fact-based evaluation. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Process- ing (EMNLP), pages 10036–10050. Ramakrishna Vedantam, C Lawrence Zitnick, and Devi Parikh. 2015. Cider: Consensus-based image de- scription evaluation. InProceedings of the IEEE conference on computer vision and p...
work page 2021
-
[3]
Deep Video Understanding through Summarization
Asking and answering questions to evalu- ate the factual consistency of summaries.Preprint, arXiv:2004.04228. Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Wein- berger, and Yoav Artzi. 2020. BERTScore: Evalu- ating text generation with BERT. InInternational Conference on Learning Representations (ICLR). Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyua...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.