MedSynapse-V: Bridging Visual Perception and Clinical Intuition via Latent Memory Evolution
Pith reviewed 2026-05-21 00:46 UTC · model grok-4.3
The pith
MedSynapse-V improves diagnostic accuracy in medical vision-language models by evolving latent diagnostic memories to capture clinical intuition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that through a process of latent diagnostic memory evolution using meta queries for prior memorization, causal counterfactual refinement with reinforcement learning on masked image regions, and intrinsic memory transition to align student and teacher branches, external diagnostic expertise can be transferred into the model's endogenous parameters, leading to better performance than state-of-the-art methods including chain-of-thought paradigms.
What carries the argument
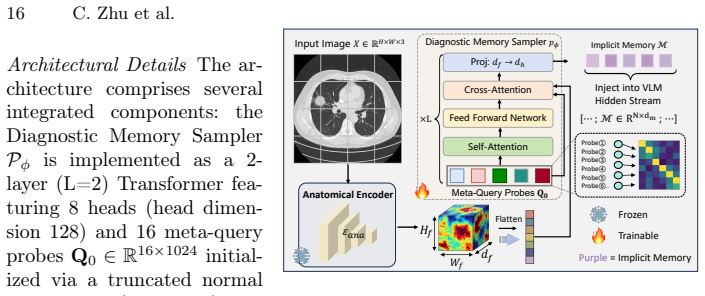
The latent diagnostic memory evolution framework that simulates experiential invocation of clinicians by synthesizing implicit memories in the hidden stream.
If this is right
- Diagnostic accuracy increases across multiple medical imaging datasets.
- Performance exceeds that of chain-of-thought approaches in particular.
- Latent representations become more aligned with actual diagnostic logic through causal pruning of redundant memories.
- Expertise is internalized rather than relying on external sources during inference.
Where Pith is reading between the lines
- This could suggest that similar memory evolution techniques might help in non-medical vision tasks where long-range context is important.
- Future work might test whether the dual-branch transition generalizes to other model architectures.
- If the causal alignment holds, it may reduce hallucinations in medical AI by grounding memories in verifiable image regions.
Load-bearing premise
The assumption that counterfactual rewards derived from region-level feature masking can accurately quantify and align the causal contribution of each latent memory with actual diagnostic logic.
What would settle it
Observing no significant accuracy gains on a new medical dataset when comparing the full model against a version without the causal counterfactual refinement step.
Figures













read the original abstract
High-precision medical diagnosis relies not only on static imaging features but also on the implicit diagnostic memory experts instantly invoke during image interpretation. We pinpoint a fundamental cognitive misalignment in medical VLMs caused by discrete tokenization, leading to quantization loss, long-range information dissipation, and missing case-adaptive expertise. To bridge this gap, we propose ours, a framework for latent diagnostic memory evolution that simulates the experiential invocation of clinicians by dynamically synthesizing implicit diagnostic memories within the model's hidden stream. Specifically, it begins with a Meta Query for Prior Memorization mechanism, where learnable probes retrieve structured priors from an anatomical prior encoder to generate condensed implicit memories. To ensure clinical fidelity, we introduce Causal Counterfactual Refinement (CCR), which leverages reinforcement learning and counterfactual rewards derived from region-level feature masking to quantify the causal contribution of each memory, thereby pruning redundancies and aligning latent representations with diagnostic logic. This evolutionary process culminates in Intrinsic Memory Transition (IMT), a privileged-autonomous dual-branch paradigm that internalizes teacher-branch diagnostic patterns into the student-branch via full-vocabulary divergence alignment. Comprehensive empirical evaluations across multiple datasets demonstrate that ours, by transferring external expertise into endogenous parameters, significantly outperforms existing state-of-the-art methods, particularly chain-of-thought paradigms, in diagnostic accuracy. The code is available at https://github.com/zhcz328/MedSynapse-V.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MedSynapse-V, a framework for evolving latent diagnostic memories in medical vision-language models to address cognitive misalignment from discrete tokenization. It proposes three components: (1) Meta Query for Prior Memorization, which uses learnable probes to retrieve structured priors from an anatomical prior encoder and synthesize condensed implicit memories; (2) Causal Counterfactual Refinement (CCR), which applies reinforcement learning with counterfactual rewards obtained via region-level feature masking to quantify each memory's causal contribution, prune redundancies, and align representations with diagnostic logic; and (3) Intrinsic Memory Transition (IMT), a dual-branch paradigm that internalizes teacher-branch patterns into the student branch through full-vocabulary divergence alignment. The central claim is that transferring external expertise into endogenous parameters yields significant outperformance over state-of-the-art methods, especially chain-of-thought paradigms, in diagnostic accuracy across multiple datasets, with code released at https://github.com/zhcz328/MedSynapse-V.
Significance. If the empirical gains and the causal fidelity of the CCR mechanism are substantiated, the work could advance medical VLMs by moving beyond static feature extraction toward dynamic, case-adaptive memory evolution that more closely mimics expert clinical intuition. The public release of code is a clear strength supporting reproducibility. However, the significance is tempered by the load-bearing dependence on the validity of region-masking counterfactuals for isolating diagnostic causality.
major comments (2)
- [§3.2] §3.2 (Causal Counterfactual Refinement): The manuscript asserts that RL rewards derived from region-level feature masking quantify the causal contribution of each latent memory and enable alignment with diagnostic logic. This step is load-bearing for the headline claim of clinical fidelity and outperformance. Yet the description provides no validation that the resulting counterfactuals isolate true diagnostic evidence rather than spatially correlated artifacts common in medical images; without such checks (e.g., expert agreement studies or controlled interventions), the subsequent pruning and IMT alignment risk misrepresenting clinician reasoning.
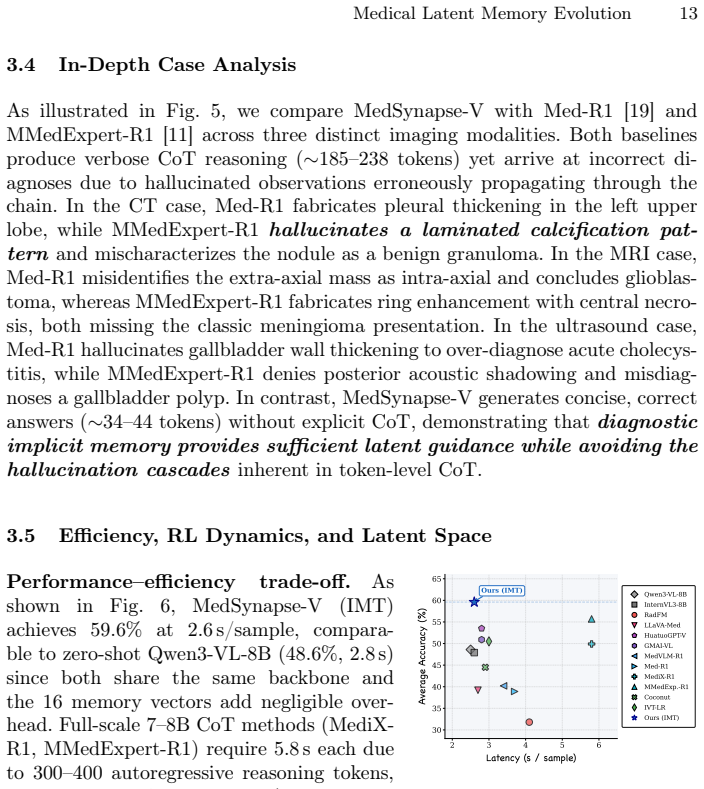
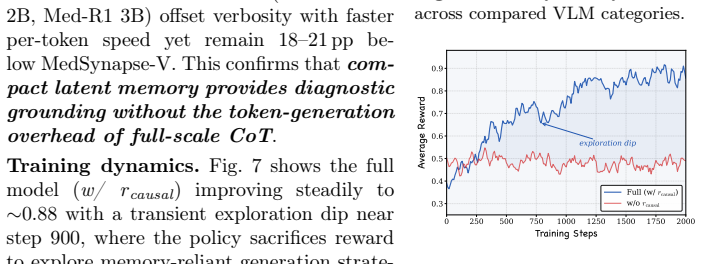
- [§4] §4 (Empirical Evaluations): The claim of significant outperformance over SOTA methods, particularly chain-of-thought, is presented without reported ablations isolating the contribution of CCR versus the prior-memorization or IMT components, nor any error bars, statistical tests, or dataset-specific breakdowns. This makes it impossible to assess whether the gains are robust or attributable to the proposed causal mechanism.
minor comments (2)
- [Abstract] The abstract refers to 'multiple datasets' and 'comprehensive empirical evaluations' but does not name the datasets or primary metrics in the opening summary; these should be stated explicitly in the abstract and introduction for immediate clarity.
- [§3.1 and §3.3] Notation for the Meta Query probes and the full-vocabulary divergence loss in IMT could be formalized with explicit equations to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important aspects of validation and empirical rigor that we will address in the revision. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Causal Counterfactual Refinement): The manuscript asserts that RL rewards derived from region-level feature masking quantify the causal contribution of each latent memory and enable alignment with diagnostic logic. This step is load-bearing for the headline claim of clinical fidelity and outperformance. Yet the description provides no validation that the resulting counterfactuals isolate true diagnostic evidence rather than spatially correlated artifacts common in medical images; without such checks (e.g., expert agreement studies or controlled interventions), the subsequent pruning and IMT alignment risk misrepresenting clinician reasoning.
Authors: We agree that explicit validation of the counterfactual mechanism is necessary to support claims of clinical fidelity. Region-level masking is motivated by the anatomical prior encoder to target spatially localized diagnostic features, but we acknowledge the risk of capturing correlated artifacts. In the revised manuscript we will expand §3.2 with (i) qualitative examples overlaying masked regions on expert-annotated diagnostic findings from a held-out subset and (ii) a controlled sensitivity study measuring accuracy degradation when masking is applied to clinically relevant versus irrelevant areas. Full-scale multi-radiologist agreement studies exceed the scope and resources of the current work and are noted as future work; the added analyses will nevertheless strengthen the causal interpretation. revision: partial
-
Referee: [§4] §4 (Empirical Evaluations): The claim of significant outperformance over SOTA methods, particularly chain-of-thought, is presented without reported ablations isolating the contribution of CCR versus the prior-memorization or IMT components, nor any error bars, statistical tests, or dataset-specific breakdowns. This makes it impossible to assess whether the gains are robust or attributable to the proposed causal mechanism.
Authors: We accept that the empirical presentation would be strengthened by component-wise analysis and statistical reporting. The revised §4 will include: (1) ablation tables removing Meta Query, CCR, and IMT individually while keeping the other modules fixed; (2) mean and standard deviation over five random seeds for all main results; (3) paired statistical significance tests (Wilcoxon signed-rank) against the strongest chain-of-thought baseline; and (4) per-dataset breakdowns of accuracy, sensitivity, and specificity. These additions will make the contribution of the causal refinement mechanism transparent. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The provided abstract and description outline a multi-stage framework (Meta Query for Prior Memorization, CCR via RL on region-masked counterfactuals, and IMT alignment) leading to claimed empirical outperformance on diagnostic accuracy. No equations, self-citations, or fitted-parameter renamings are present that reduce any load-bearing prediction or uniqueness claim to its own inputs by construction. The central performance claim rests on external evaluations across datasets rather than tautological fitting, satisfying the criteria for an independent derivation chain. Potential concerns about reward validity belong to correctness or assumption risk, not circularity.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Causal Counterfactual Refinement (CCR) ... reinforcement learning and counterfactual rewards derived from region-level feature masking to quantify the causal contribution of each memory
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Meta Query for Prior Memorization ... learnable probes retrieve structured priors from an anatomical prior encoder
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Deformba: Vision State Space Model with Adaptive State Fusion
Deformba introduces context-adaptive state fusion to vision SSMs for better spatial augmentation and cross-stream interactions, showing strong results on 2D classification/detection/segmentation and 3D BEV perception ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.