Robust Lightweight Crack Classification for Real-Time UAV Bridge Inspection
Pith reviewed 2026-05-07 05:25 UTC · model grok-4.3
The pith
Lightweight CNN with attention and focal loss detects bridge cracks at 825 FPS for UAV inspections.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
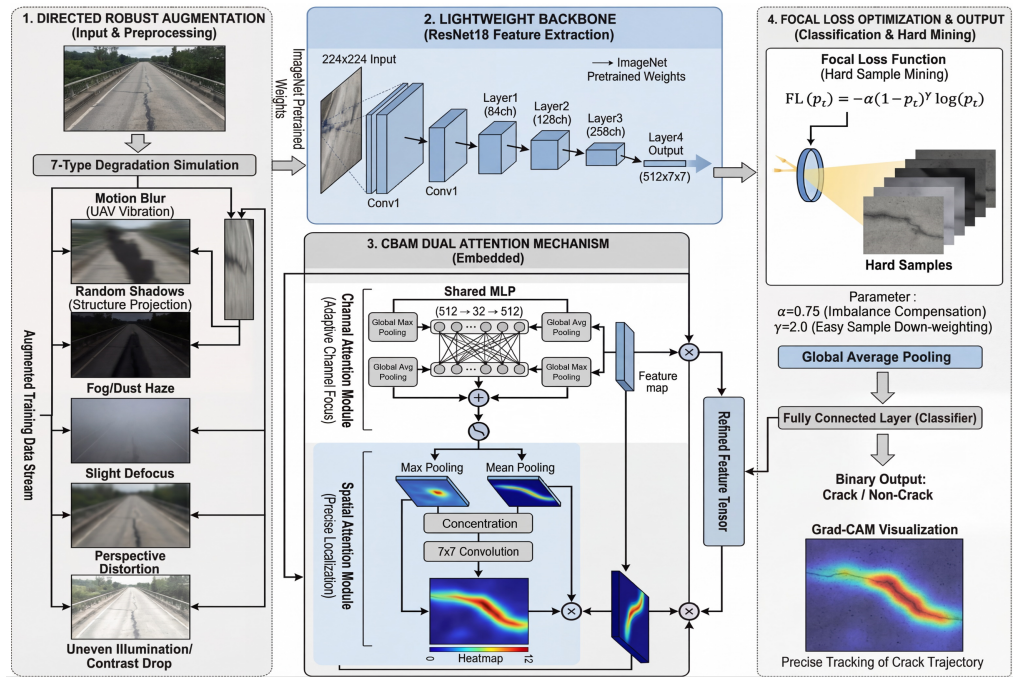
The paper claims that combining a lightweight backbone, Convolutional Block Attention Module (CBAM), directed robust augmentation based on inspection-scene priors, and Focal Loss creates a unified framework that delivers high-speed, accurate crack classification suitable for real-time UAV bridge inspection. Tested on the SDNET2018 bridge deck dataset, the method attains an inference speed of 825 FPS using only 11.21 million parameters and 1.82 gigaflops. It raises the F1-score by 2.51 percent and recall by 3.95 percent relative to the baseline, while Grad-CAM heatmaps show the attention component directs attention along actual crack paths rather than scattered regions.
What carries the argument
The central mechanism is the AttXNet unified lightweight framework that integrates four components—a compact convolutional backbone for efficiency, CBAM to enhance channel and spatial features of weak cracks, a directed augmentation pipeline informed by UAV inspection priors to boost robustness, and focal loss to mitigate class imbalance by focusing training on hard samples.
If this is right
- Supports real-time UAV inspections by processing images at 825 FPS, enabling ground-station assisted workflows without heavy hardware.
- Low parameter count of 11.21M and 1.82G FLOPs allows deployment on resource-constrained UAV systems.
- 3.95% higher recall means more cracks are detected, reducing the risk of overlooking structural issues.
- CBAM integration improves model focus on crack trajectories as confirmed by visualization techniques.
- Provides a practical, balanced solution for accuracy, speed, and robustness in structural health monitoring.
Where Pith is reading between the lines
- If the scene-prior augmentation generalizes, similar techniques could improve defect detection in other UAV applications like power line or pipeline inspection.
- Further tests on datasets with greater variation in lighting and bridge designs would test the claimed robustness.
- The lightweight design opens possibilities for on-drone processing rather than relying solely on ground stations.
- Combining this with multi-view or video analysis from UAV flights could enhance crack tracking over time.
Load-bearing premise
Performance gains from the directed augmentation, CBAM, and focal loss observed on the SDNET2018 dataset will transfer to real-world UAV operations with different lighting, weather, flight conditions, and bridge structures.
What would settle it
Collecting a new test set of UAV bridge images from unseen locations and conditions and measuring whether the reported improvements in F1-score and recall are maintained or significantly reduced.
Figures









read the original abstract
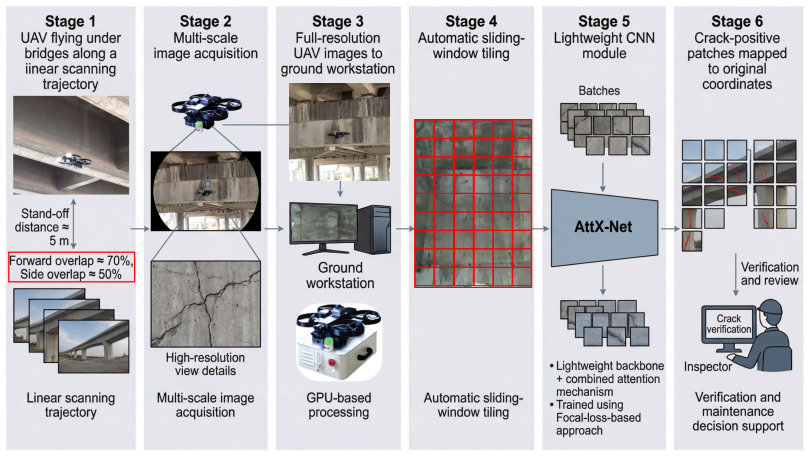
With the widespread application of Unmanned Aerial Vehicles (UAVs) in bridge structural health monitoring, deep learning-based automatic crack detection has become a major research focus. However, practical UAV inspections still face four key challenges: weak crack features, degraded imaging conditions, severe class imbalance, and limited computational resources for practical UAV inspection workflows. To address these issues, this paper proposes a unified lightweight convolutional neural network framework composed of four synergistic components: a lightweight backbone network, a Convolutional Block Attention Module (CBAM) for channel and spatial enhancement, a directed robust augmentation strategy based on inspection-scene priors, and Focal Loss for hard-sample learning under class imbalance. Experiments on the SDNET2018 bridge deck dataset show that the proposed method achieves an inference speed of 825 FPS with only 11.21M parameters and 1.82G FLOPs. Compared with the baseline model, the complete framework improves the F1-score by 2.51% and recall by 3.95%. In addition, Grad-CAM visualizations indicate that the introduced attention module shifts the model's focus from scattered regions to precise tracking along crack trajectories. Overall, this study achieves a strong balance among accuracy, speed, and robustness, providing a practical solution for ground-station assisted real-time deployment in UAV bridge inspections. The source code is available at: https://github.com/skylynf/AttXNet .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a lightweight CNN framework for crack classification in UAV bridge inspections to address weak features, degraded conditions, class imbalance, and limited compute. The framework integrates a lightweight backbone, CBAM attention module, a directed robust augmentation strategy derived from inspection-scene priors, and Focal Loss. On the SDNET2018 bridge deck dataset, it reports 825 FPS inference, 11.21M parameters, 1.82G FLOPs, and gains of +2.51% F1-score and +3.95% recall over a baseline, with Grad-CAM visualizations indicating improved focus on crack trajectories. Source code is provided.
Significance. If the reported metrics on SDNET2018 are reproducible and the components prove effective, the work offers a practical, efficient solution for real-time UAV-assisted bridge inspection, balancing accuracy, speed, and handling of imbalance. The open-source code and concrete FPS/parameter/FLOP numbers strengthen reproducibility and applicability claims. However, the significance for 'robust' real-world deployment is limited by the absence of evidence beyond a single public dataset.
major comments (3)
- [§4 (Experiments)] §4 (Experiments): All quantitative results (825 FPS, 11.21M params, 1.82G FLOPs, +2.51% F1, +3.95% recall) and Grad-CAM visualizations are confined to SDNET2018 splits. No cross-dataset evaluation, no held-out UAV sequences with novel lighting/angles/bridge types, and no test of whether the inspection-scene priors transfer are reported, so the abstract's claim of robustness to 'varied real-world UAV flight conditions' is an unsupported extrapolation.
- [§3.3 (Directed Robust Augmentation)] §3.3 (Directed Robust Augmentation): The augmentation strategy is explicitly 'based on inspection-scene priors' derived from the target dataset. Without an ablation that isolates its contribution from dataset-specific tuning or a transfer experiment on a different bridge dataset, it is impossible to determine whether the reported F1/recall gains are load-bearing or would generalize.
- [§4.1 (Implementation Details)] §4.1 (Implementation Details) and §4.2 (Ablation Studies): The baseline model architecture, training hyperparameters, and exact comparison protocol are not specified with sufficient precision to rule out post-hoc tuning. The incremental benefit of CBAM + augmentation + Focal Loss versus the backbone alone is not broken down with statistical tests or multiple runs, weakening the claim that the complete framework is responsible for the gains.
minor comments (2)
- [§3.1] The backbone network is referred to as 'lightweight' but its exact topology (e.g., number of layers, specific MobileNet/EfficientNet variant) should be stated explicitly in §3.1 for reproducibility.
- [Figure 5] Figure 5 (Grad-CAM) would benefit from side-by-side quantitative metrics (e.g., localization error) in addition to qualitative examples to strengthen the attention-module claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight key areas for strengthening the evidence of generalization and experimental rigor. We agree that additional validation beyond SDNET2018 would better support the robustness claims and will incorporate the suggested revisions, including new experiments and clarifications, in the revised manuscript.
read point-by-point responses
-
Referee: All quantitative results (825 FPS, 11.21M params, 1.82G FLOPs, +2.51% F1, +3.95% recall) and Grad-CAM visualizations are confined to SDNET2018 splits. No cross-dataset evaluation, no held-out UAV sequences with novel lighting/angles/bridge types, and no test of whether the inspection-scene priors transfer are reported, so the abstract's claim of robustness to 'varied real-world UAV flight conditions' is an unsupported extrapolation.
Authors: We acknowledge that the current quantitative results and visualizations are limited to SDNET2018. Although this dataset includes substantial variation in lighting, angles, surface conditions, and crack appearances representative of UAV bridge inspections, we agree that cross-dataset evaluation would provide stronger support for claims of robustness to varied real-world conditions. In the revised manuscript, we will add evaluation on at least one additional public crack detection dataset to demonstrate transferability of the framework and the inspection-scene priors. revision: yes
-
Referee: The augmentation strategy is explicitly 'based on inspection-scene priors' derived from the target dataset. Without an ablation that isolates its contribution from dataset-specific tuning or a transfer experiment on a different bridge dataset, it is impossible to determine whether the reported F1/recall gains are load-bearing or would generalize.
Authors: The directed robust augmentation incorporates priors drawn from typical UAV bridge inspection characteristics (e.g., crack orientations under perspective distortion and common degradation patterns). To address the concern, we will expand the ablation studies to isolate the augmentation's contribution through controlled variants (with and without the directed strategy) and will use the planned cross-dataset experiments to test whether the observed gains transfer beyond SDNET2018-specific tuning. revision: yes
-
Referee: The baseline model architecture, training hyperparameters, and exact comparison protocol are not specified with sufficient precision to rule out post-hoc tuning. The incremental benefit of CBAM + augmentation + Focal Loss versus the backbone alone is not broken down with statistical tests or multiple runs, weakening the claim that the complete framework is responsible for the gains.
Authors: We will revise §4.1 to include complete specifications of the baseline architecture (layer dimensions and connections), all training hyperparameters (optimizer, learning rate schedule, batch size, epochs, and data splits), and the precise comparison protocol. In §4.2, we will report ablation results as means and standard deviations over multiple independent runs (minimum five seeds) and include statistical significance tests (e.g., paired t-tests) to rigorously quantify the incremental contributions of CBAM, the augmentation strategy, and Focal Loss. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper is an empirical CV contribution proposing a lightweight CNN with CBAM attention, a directed augmentation strategy derived from inspection-scene priors, and Focal Loss. All quantitative claims (825 FPS, 11.21M params, +2.51% F1, +3.95% recall) are measured on the external public SDNET2018 benchmark against an explicitly stated baseline. No equations, first-principles derivations, or self-referential normalizations appear in the provided text. The augmentation is a fixed preprocessing step based on domain priors rather than a fitted parameter whose output is later renamed as a prediction. No self-citation chains or uniqueness theorems are invoked to justify core components. The derivation chain is therefore self-contained against external data and does not reduce any result to its own inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- training hyperparameters (learning rate, batch size, augmentation strengths)
axioms (2)
- domain assumption Convolutional neural networks can learn discriminative features from labeled images for binary crack classification.
- domain assumption The SDNET2018 dataset distribution is sufficiently representative of real UAV bridge inspection conditions for generalization claims.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.