SciResearcher: Scaling Deep Research Agents for Frontier Scientific Reasoning
Pith reviewed 2026-05-09 14:14 UTC · model grok-4.3
The pith
Automated synthesis of conceptual and computational tasks trains an 8B model to set new records on frontier biology and chemistry reasoning benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
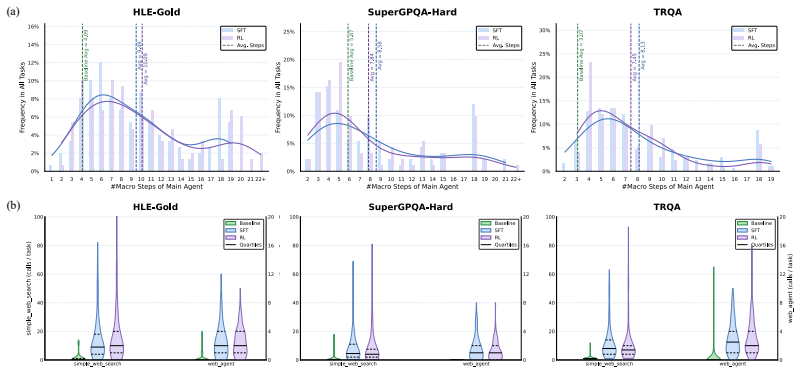
SciResearcher is a fully automated agentic framework for frontier-science data construction that synthesizes diverse conceptual and computational tasks grounded in academic evidence. The framework elicits information acquisition, tool-integrated reasoning, and long-horizon capabilities. Training on the resulting data via supervised fine-tuning and agentic reinforcement learning yields SciResearcher-8B, which scores 19.46 percent on HLE-Bio/Chem-Gold and delivers 13-15 percent absolute improvements on SuperGPQA-Hard-Biology and TRQA-Literature, establishing a new state of the art at the 8B scale and surpassing several larger proprietary agents.
What carries the argument
The SciResearcher agentic framework, which automatically synthesizes grounded conceptual and computational tasks from academic sources to drive supervised fine-tuning and reinforcement learning for scientific agents.
If this is right
- Smaller open models can match or exceed larger closed agents on hard scientific benchmarks when trained on suitably synthesized data.
- The same synthesis loop can be iterated to generate larger and more diverse datasets for continued scaling.
- Agentic reinforcement learning on these tasks strengthens long-horizon planning beyond what factual pre-training alone provides.
- The framework reduces dependence on manual knowledge-graph or browsing pipelines that miss computational depth in sparse academic sources.
Where Pith is reading between the lines
- The method could transfer to other data-scarce fields such as materials discovery or theoretical physics by swapping the source academic corpora.
- Pairing the synthesized tasks with real experimental logs or simulation outputs might close remaining gaps between benchmark performance and practical discovery.
- The performance edge at 8B scale suggests that future gains may come more from data quality than from raw parameter count in scientific agent work.
Load-bearing premise
Tasks synthesized by the agentic framework accurately reflect the computational and reasoning demands of actual frontier scientific problems rather than simplified or proxy versions.
What would settle it
If a model trained on human-curated real frontier problems performs no better than SciResearcher-8B on the same held-out benchmarks, or if SciResearcher-8B fails on a fresh set of unsolved domain problems never seen during data synthesis, the value of the automated construction process would be in question.
Figures





read the original abstract
Frontier scientific reasoning is rapidly emerging as a key foundation for advancing AI agents in automated scientific discovery. Deep research agents offer a promising approach to this challenge. These models develop robust problem-solving capabilities through post-training on information-seeking tasks, which are typically curated via knowledge graph construction or iterative web browsing. However, these strategies face inherent limitations in frontier science, where domain-specific knowledge is scattered across sparse and heterogeneous academic sources, and problem solving requires sophisticated computation and reasoning far beyond factual recall. To bridge this gap, we introduce SciResearcher, a fully automated agentic framework for frontier-science data construction. SciResearcher synthesizes diverse conceptual and computational tasks grounded in academic evidence, while eliciting information acquisition, tool-integrated reasoning, and long-horizon capabilities. Leveraging the curated data for supervised fine-tuning and agentic reinforcement learning, we develop SciResearcher-8B, an agent foundation model that achieves 19.46% on the HLE-Bio/Chem-Gold benchmark, establishing a new state of the art at its parameter scale and surpassing several larger proprietary agents. It further achieves 13-15% absolute gains on SuperGPQA-Hard-Biology and TRQA-Literature benchmarks. Overall, SciResearcher introduces a new paradigm for automated data construction for frontier scientific reasoning and offers a scalable path toward future scientific agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SciResearcher, a fully automated agentic framework for synthesizing diverse conceptual and computational tasks grounded in academic evidence to support information acquisition, tool use, and long-horizon reasoning. The authors apply supervised fine-tuning followed by agentic reinforcement learning on this data to produce SciResearcher-8B, which achieves 19.46% on HLE-Bio/Chem-Gold (new SOTA at 8B scale, surpassing some larger proprietary agents) along with 13-15% absolute gains on SuperGPQA-Hard-Biology and TRQA-Literature.
Significance. If the synthetic tasks are shown to impose reasoning loads comparable to real frontier scientific problems, the framework would provide a scalable, automated alternative to knowledge-graph or web-browsing curation methods, potentially enabling more capable agents for automated discovery in domains with sparse, heterogeneous sources.
major comments (3)
- [§3] §3 (Framework Description): The task-synthesis pipeline is described at a high level but supplies no pseudocode, concrete examples of generated computational tasks, or quantitative metrics (e.g., number of tool calls or reasoning steps required). Without these, it is impossible to verify that the data elicits the claimed long-horizon and tool-integrated reasoning rather than simpler pattern-matching proxies.
- [§5] §5 (Experiments): No ablation studies isolate the contribution of the agentic RL stage versus SFT alone, and no error bars or run-to-run variance are reported for the headline scores (19.46% on HLE-Bio/Chem-Gold, 13-15% gains elsewhere). This leaves open whether the reported improvements are robust or attributable to the framework.
- [§4] §4 (Data Construction): The manuscript provides no human-expert validation, difficulty calibration against real frontier problems, or comparison of source heterogeneity between synthetic tasks and actual academic literature. This directly bears on the central claim that performance gains reflect genuine scaling of scientific reasoning rather than distribution matching on easier proxies.
minor comments (2)
- [Abstract] The abstract states '13-15% absolute gains' without naming the exact baselines or providing the raw scores for each benchmark.
- [§2] Notation for the HLE-Bio/Chem-Gold benchmark is introduced without a reference or brief definition of its construction.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for improving clarity and rigor, and we will revise the manuscript accordingly to address them. Below we respond point by point to the major comments.
read point-by-point responses
-
Referee: [§3] §3 (Framework Description): The task-synthesis pipeline is described at a high level but supplies no pseudocode, concrete examples of generated computational tasks, or quantitative metrics (e.g., number of tool calls or reasoning steps required). Without these, it is impossible to verify that the data elicits the claimed long-horizon and tool-integrated reasoning rather than simpler pattern-matching proxies.
Authors: We agree that additional concrete details are needed to substantiate the long-horizon and tool-use claims. In the revised manuscript we will include full pseudocode for the task-synthesis pipeline as an appendix. We will also provide multiple concrete examples of generated computational tasks (including both conceptual and multi-step computational instances) together with quantitative metrics such as the distribution of tool calls per task and average reasoning steps. These additions will enable readers to directly assess the complexity and structure of the synthesized data. revision: yes
-
Referee: [§5] §5 (Experiments): No ablation studies isolate the contribution of the agentic RL stage versus SFT alone, and no error bars or run-to-run variance are reported for the headline scores (19.46% on HLE-Bio/Chem-Gold, 13-15% gains elsewhere). This leaves open whether the reported improvements are robust or attributable to the framework.
Authors: We acknowledge the value of isolating the RL contribution and reporting statistical robustness. We will add ablation experiments comparing SFT-only training against the full SFT + agentic RL pipeline on the same data. We will also rerun the primary evaluation runs with multiple random seeds and report error bars (standard deviation) for the key metrics on HLE-Bio/Chem-Gold, SuperGPQA-Hard-Biology, and TRQA-Literature. These changes will clarify the source of the observed gains. revision: yes
-
Referee: [§4] §4 (Data Construction): The manuscript provides no human-expert validation, difficulty calibration against real frontier problems, or comparison of source heterogeneity between synthetic tasks and actual academic literature. This directly bears on the central claim that performance gains reflect genuine scaling of scientific reasoning rather than distribution matching on easier proxies.
Authors: We will expand the data construction section to include quantitative comparisons of source heterogeneity (e.g., topic diversity, citation graph statistics, and domain coverage) between the synthetic tasks and samples drawn from the original academic literature. We will also add indirect difficulty calibration by reporting task-complexity statistics (tool-call depth, reasoning-chain length) and relating them to the hardness of the evaluation benchmarks. However, human-expert validation was not performed because the framework is intentionally fully automated; we will explicitly discuss this design choice and its implications as a limitation. revision: partial
- Direct human-expert validation of the synthetic tasks and explicit difficulty calibration against real frontier problems, as these steps would require substantial human annotation effort and contradict the core goal of a fully automated, scalable data-construction pipeline.
Circularity Check
No significant circularity; empirical pipeline on external benchmarks
full rationale
The paper presents an agentic framework that synthesizes tasks from academic sources, applies standard supervised fine-tuning plus agentic RL, and reports accuracy on independent external benchmarks (HLE-Bio/Chem-Gold, SuperGPQA-Hard-Biology, TRQA-Literature). No equations, fitted parameters, or internal derivations are described. Performance claims are grounded in post-training evaluation rather than any self-referential reduction, self-citation chain, or renaming of known results. The central assumption (synthetic tasks match frontier demands) is an empirical validity question, not a circularity in the reported derivation.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.