Recognition: 2 theorem links
· Lean TheoremT²PO: Uncertainty-Guided Exploration Control for Stable Multi-Turn Agentic Reinforcement Learning
Pith reviewed 2026-05-08 19:34 UTC · model grok-4.3
The pith
T²PO improves stability and performance in multi-turn agentic RL by using uncertainty dynamics at token and turn levels to guide exploration and avoid wasted rollouts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
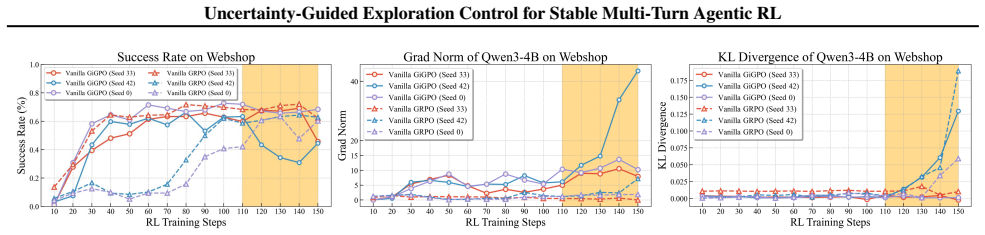
We evaluate T²PO in diverse environments, including WebShop, ALFWorld, and Search QA, demonstrating substantial gains in training stability and performance improvements with better exploration efficiency.
Load-bearing premise
That marginal uncertainty change at the token level and negligible exploration progress at the turn level can be measured reliably enough to trigger interventions without introducing new sources of instability or bias in the policy updates.
Figures






read the original abstract
Recent progress in multi-turn reinforcement learning (RL) has significantly improved reasoning LLMs' performances on complex interactive tasks. Despite advances in stabilization techniques such as fine-grained credit assignment and trajectory filtering, instability remains pervasive and often leads to training collapse. We argue that this instability stems from inefficient exploration in multi-turn settings, where policies continue to generate low-information actions that neither reduce uncertainty nor advance task progress. To address this issue, we propose Token- and Turn-level Policy Optimization (T$^2$PO), an uncertainty-aware framework that explicitly controls exploration at fine-grained levels. At the token level, T$^2$PO monitors uncertainty dynamics and triggers a thinking intervention once the marginal uncertainty change falls below a threshold. At the turn level, T$^2$PO identifies interactions with negligible exploration progress and dynamically resamples such turns to avoid wasted rollouts. We evaluate T$^2$PO in diverse environments, including WebShop, ALFWorld, and Search QA, demonstrating substantial gains in training stability and performance improvements with better exploration efficiency. Code is available at: https://github.com/WillDreamer/T2PO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces T²PO, an uncertainty-aware framework for controlling exploration in multi-turn agentic RL for LLMs. It argues that pervasive training instability arises from inefficient exploration, where policies generate low-information actions that neither reduce uncertainty nor advance task progress. T²PO intervenes at the token level by monitoring uncertainty dynamics and triggering thinking interventions once marginal uncertainty change falls below a threshold; at the turn level, it identifies turns with negligible exploration progress and dynamically resamples them to avoid wasted rollouts. Evaluations on WebShop, ALFWorld, and Search QA are claimed to demonstrate substantial gains in training stability, performance, and exploration efficiency.
Significance. If the reported gains in stability and performance are robust and the interventions do not introduce uncorrected biases, T²PO could provide a practical heuristic for addressing a key source of instability in multi-turn RL for agentic LLMs. The dual token/turn uncertainty control targets a plausible mechanism and could improve exploration efficiency in interactive reasoning tasks, but its significance depends on empirical validation showing that benefits exceed artifacts from altered trajectory distributions.
major comments (2)
- Abstract (turn-level resampling description): The dynamic resampling of turns with negligible exploration progress alters the distribution of trajectories supplied to policy optimization. No importance sampling, adjusted loss terms, or other bias-correction mechanisms are described, which risks biased gradient estimates and could produce apparent stability gains that are artifacts of data rebalancing rather than genuine uncertainty-aware control.
- Abstract (evaluation claim): The abstract asserts 'substantial gains in training stability and performance improvements with better exploration efficiency' across WebShop, ALFWorld, and Search QA, yet supplies no quantitative results, baselines, error bars, ablation studies, or implementation details, rendering the central empirical claim unevaluable from the provided text.
minor comments (2)
- Abstract: The method is presented as a heuristic framework; explicit definitions or equations for uncertainty (e.g., how marginal uncertainty change is computed at the token level) and the threshold are absent, hindering assessment of whether the approach is parameter-free or introduces new free parameters.
- Abstract: No discussion of how token-level interventions interact with credit assignment in the underlying multi-turn RL objective, which could affect the validity of stability claims.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive feedback on our work. We address each major comment below and outline the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: Abstract (turn-level resampling description): The dynamic resampling of turns with negligible exploration progress alters the distribution of trajectories supplied to policy optimization. No importance sampling, adjusted loss terms, or other bias-correction mechanisms are described, which risks biased gradient estimates and could produce apparent stability gains that are artifacts of data rebalancing rather than genuine uncertainty-aware control.
Authors: We acknowledge the validity of this concern. The turn-level resampling is intended to improve exploration efficiency by reallocating rollouts to turns with higher uncertainty reduction potential. In the full manuscript, we describe the resampling process but do not explicitly discuss bias correction. To address this, we will revise the paper to include an analysis of the trajectory distribution shift, provide theoretical justification for why the uncertainty-guided resampling does not introduce harmful bias in this context, and add empirical ablations showing performance with and without resampling. If necessary, we will incorporate importance sampling weights in future iterations. revision: yes
-
Referee: Abstract (evaluation claim): The abstract asserts 'substantial gains in training stability and performance improvements with better exploration efficiency' across WebShop, ALFWorld, and Search QA, yet supplies no quantitative results, baselines, error bars, ablation studies, or implementation details, rendering the central empirical claim unevaluable from the provided text.
Authors: We agree that the abstract is high-level and does not include specific numbers due to length constraints typical for abstracts. The full manuscript contains comprehensive experimental results, including quantitative metrics, comparisons to baselines, error bars from multiple runs, ablation studies on the token- and turn-level components, and implementation details in the appendix. To improve the abstract, we will revise it to briefly mention key quantitative improvements, such as relative gains in success rates and stability metrics on the evaluated benchmarks. revision: yes
Axiom & Free-Parameter Ledger
free parameters (1)
- uncertainty change threshold
axioms (1)
- domain assumption Model uncertainty can be estimated from token probabilities or logits in a way that correlates with exploration value
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
M_t = α(H̃_t) + (1−α)(1−C̃_t), α∈[0,1] ... we vary α from 0.2 to 0.4, 0.6, 0.8, and observe that α=0.4 yields the best performance.
-
IndisputableMonolith/Cost (Jcost = ½(x + x⁻¹) − 1)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Token entropy H_t = −Σ p_i log p_i and confidence C_t = −(1/j)Σ log p_i used as exploration signals.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review arXiv
-
[2]
URL https://www. anthropic.com. Large language model. Cai, H. J., Wang, J., Chen, X., and Dhingra, B. How much backtracking is enough? exploring the interplay of sft and rl in enhancing llm reasoning.arXiv preprint arXiv:2505.24273,
-
[3]
Chen, M., Chen, G., Wang, W., and Yang, Y . Seed-grpo: Semantic entropy enhanced grpo for uncertainty-aware policy optimization.arXiv preprint arXiv:2505.12346,
-
[4]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261,
-
[5]
Agentic entropy-balanced policy optimization.arXiv preprint arXiv:2510.14545,
Dong, G., Bao, L., Wang, Z., Zhao, K., Li, X., Jin, J., Yang, J., Mao, H., Zhang, F., Gai, K., et al. Agentic entropy-balanced policy optimization.arXiv preprint arXiv:2510.14545,
-
[6]
Group-in-Group Policy Optimization for LLM Agent Training
Feng, L., Xue, Z., Liu, T., and An, B. Group-in-group policy optimization for llm agent training.arXiv preprint arXiv:2505.10978,
work page internal anchor Pith review arXiv
-
[7]
Fu, W., Gao, J., Shen, X., Zhu, C., Mei, Z., He, C., Xu, S., Wei, G., Mei, J., Wang, J., Yang, T., Yuan, B., and Wu, Y . Areal: A large-scale asynchronous reinforcement learning system for language reasoning, 2025a. URL https://arxiv.org/abs/2505.24298. Fu, Y ., Wang, X., Tian, Y ., and Zhao, J. Deep think with confidence.arXiv preprint arXiv:2508.15260, ...
-
[8]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Jin, B., Zeng, H., Yue, Z., Yoon, J., Arik, S., Wang, D., Zamani, H., and Han, J. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516,
-
[9]
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
Joshi, M., Choi, E., Weld, D. S., and Zettlemoyer, L. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension.arXiv preprint arXiv:1705.03551,
work page internal anchor Pith review arXiv
-
[10]
Liu, A., Feng, B., Xue, B., Wang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437,
-
[11]
Liu, L., Yao, F., Zhang, D., Dong, C., Shang, J., and Gao, J. Flashrl: 8bit rollouts, full power rl, August 2025a. URL https://fengyao.notion.site/flash-rl. Liu, W., Zhou, R., Deng, Y ., Huang, Y ., Liu, J., Deng, Y ., Zhang, Y ., and He, J. Learn to reason efficiently with adaptive length-based reward shaping.arXiv preprint arXiv:2505.15612, 2025b. 9 Unc...
-
[12]
A., and Lewis, M
Press, O., Zhang, M., Min, S., Schmidt, L., Smith, N. A., and Lewis, M. Measuring and narrowing the composi- tionality gap in language models. InFindings of the As- sociation for Computational Linguistics: EMNLP 2023, pp. 5687–5711,
2023
-
[13]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review arXiv
-
[14]
rstar2-agent: Agentic reasoning technical report, 2025
Shang, N., Liu, Y ., Zhu, Y ., Zhang, L. L., Xu, W., Guan, X., Zhang, B., Dong, B., Zhou, X., Zhang, B., et al. rstar2- agent: Agentic reasoning technical report.arXiv preprint arXiv:2508.20722,
-
[15]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y ., Wu, Y ., et al. Deepseekmath: Push- ing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review arXiv
-
[16]
HybridFlow: A Flexible and Efficient RLHF Framework
Sheng, G., Zhang, C., Ye, Z., Wu, X., Zhang, W., Zhang, R., Peng, Y ., Lin, H., and Wu, C. Hybridflow: A flexi- ble and efficient rlhf framework.arXiv preprint arXiv: 2409.19256,
work page internal anchor Pith review arXiv
-
[17]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Shridhar, M., Yuan, X., C ˆot´e, M.-A., Bisk, Y ., Trischler, A., and Hausknecht, M. Alfworld: Aligning text and embodied environments for interactive learning.arXiv preprint arXiv:2010.03768,
work page internal anchor Pith review arXiv 2010
-
[18]
Zerosearch: Incentivize the search capability of llms without searching, 2025
Sun, H., Qiao, Z., Guo, J., Fan, X., Hou, Y ., Jiang, Y ., Xie, P., Zhang, Y ., Huang, F., and Zhou, J. Zerosearch: In- centivize the search capability of llms without searching. arXiv preprint arXiv:2505.04588,
-
[19]
Team, K., Du, A., Gao, B., Xing, B., Jiang, C., Chen, C., Li, C., Xiao, C., Du, C., Liao, C., et al. Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599,
work page internal anchor Pith review arXiv
-
[20]
URL https: //arxiv.org/abs/2505.09388. Trivedi, H., Balasubramanian, N., Khot, T., and Sab- harwal, A. Musique: Multihop questions via single- hop question composition, 2022.URL https://arxiv. org/abs/2108.00573,
work page internal anchor Pith review arXiv 2022
-
[21]
arXiv preprint arXiv:2509.09265 , year=
Wang, J., Liu, J., Fu, Y ., Li, Y ., Wang, X., Lin, Y ., Yue, Y ., Zhang, L., Wang, Y ., and Wang, K. Harnessing un- certainty: Entropy-modulated policy gradients for long- horizon llm agents, 2025a. URL https://arxiv. org/abs/2509.09265. Wang, X., Zhang, H., Wang, H., Shi, Y ., Li, R., Han, K., Tong, C., Deng, H., Sun, R., Taylor, A., et al. Arlarena: A ...
-
[22]
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning
Wang, Z., Wang, K., Wang, Q., Zhang, P., Li, L., Yang, Z., Yu, K., Nguyen, M. N., Liu, L., Gottlieb, E., Lam, M., Lu, Y ., Cho, K., Wu, J., Fei-Fei, L., Wang, L., Choi, Y ., and Li, M. Ragen: Understanding self-evolution in llm agents via multi-turn reinforcement learning, 2025b. URLhttps://arxiv.org/abs/2504.20073. Wang, Z., Zheng, X., An, K., Ouyang, C....
work page internal anchor Pith review arXiv
-
[23]
Xue, Z., Zheng, L., Liu, Q., Li, Y ., Zheng, X., Ma, Z., and An, B. Simpletir: End-to-end reinforcement learning for multi-turn tool-integrated reasoning.arXiv preprint arXiv:2509.02479,
-
[24]
Yang, Z., Qi, P., Zhang, S., Bengio, Y ., Cohen, W., Salakhut- dinov, R., and Manning, C. D. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 conference on empirical methods in natural language processing, pp. 2369–2380,
2018
-
[25]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
10 Uncertainty-Guided Exploration Control for Stable Multi-Turn Agentic RL Yu, Q., Zhang, Z., Zhu, R., Yuan, Y ., Zuo, X., Yue, Y ., Dai, W., Fan, T., Liu, G., Liu, L., et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
-
[26]
arXiv preprint arXiv:2512.01374 , year=
Zheng, C., Dang, K., Yu, B., Li, M., Jiang, H., Lin, J., Liu, Y ., Yang, A., Zhou, J., and Lin, J. Stabilizing rein- forcement learning with llms: Formulation and practices. arXiv preprint arXiv:2512.01374, 2025a. Zheng, C., Liu, S., Li, M., Chen, X.-H., Yu, B., Gao, C., Dang, K., Liu, Y ., Men, R., Yang, A., et al. Group sequence policy optimization.arXi...
-
[27]
I want a red shirt
11 Uncertainty-Guided Exploration Control for Stable Multi-Turn Agentic RL APPENDIX A. More Task Details A.1. Evaluation Metrics A.1.1. WEBSHOP We adopt six complementary evaluation metrics to comprehensively assess task completion quality. (1)Task Scoreis defined as 10×avg. reward , measuring the average accumulated reward per episode. (2)Success Rateis ...
2020
-
[28]
This is also why parameter-efficient tuning methods, such as Wang et al
suggests that RL in reasoning models does not primarily benefit from memorizing correct solution trajectories, but rather from internalizing structured search behaviors embedded in demonstration traces. This is also why parameter-efficient tuning methods, such as Wang et al. (2023; 2024), can work. In particular, backtracking, where the model explicitly r...
2023
-
[29]
is a stabilization strategy for thinking control designed to improve the robustness of multi-turn policy optimization. In multi-turn reasoning, the accumulation of low-probability tokens and high sampling stochasticity often produces void turns,i.e., responses that contain neither a valid final answer nor a complete executable structure. Typical void turn...
2024
-
[30]
Each reward component evaluates a distinct aspect of task completion, including correct product title identification (Title Score), accurate category matching (reward type), attribute fulfillment (reward attribute), and final option selection (reward option). We observe that prompting-based and instruction-tuned baselines exhibit limited performance on fi...
2039
-
[31]
Codebase Building upon the existing codebase verl (Sheng et al., 2024), our codebase introduces targeted modifications to both the vLLM (Kwon et al.,
and obtain turn-level observation signal: Φk = TkY t=1 M k t 1/Tk 11:ifk >1then 12:Monitor temporal variation across turnsΓ k =|Φ k −Φ k−1| 13:else 14:SetΓ k ←+∞ 15:end if 16:b←b+ 1 17:untilΓ k ≥ηorb≥B max 18:Parse and execute actions in environment: (sk+1, rk)← E.step(a k) 19:Store(s k,a k, rk)intoτ 20:ifIs all done=Truethen 21:break 22:end if 23:end for...
2024
-
[32]
inference engine and the agent interaction loop, enabling seamless integration with verl while preserving its scalability and modularity. Specifically, we redesign the decoding and rollout pipeline to support fine-grained uncertainty-aware control during generation, while maintaining full compatibility with the step-wise multi-turn training paradigm and m...
1982
-
[33]
The next step is to execute this search
That should narrow down the results to the relevant products. The next step is to execute this search. </think> <action>search[heather grey men classic fit 3x large under 30]</action> " ⇑ Falling into repeated failures across multiple interaction turns T2PO Enables Decisive, Non-Redundant Actions. The following figure shows a successful WebShop interactio...
1982
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.