Aes3D: Aesthetic Assessment in 3D Gaussian Splatting
Pith reviewed 2026-05-08 16:49 UTC · model grok-4.3
The pith
A lightweight model predicts aesthetic scores for 3D scenes directly from Gaussian splat primitives without rendering images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose Aes3D, the first systematic framework for assessing the aesthetics of 3D neural rendering scenes. Aes3D includes Aesthetic3D, the first dataset dedicated to 3D scene aesthetic assessment, built on our proposed annotation strategy for 3D scene aesthetics. In addition, we present Aes3DGSNet, a lightweight model that directly predicts scene-level aesthetic scores from 3DGS representations. Notably, our model operates solely on 3D Gaussian primitives, eliminating the need for rendering multi-view images and thus reducing computational cost and hardware requirements. Through aesthetics-supervised learning on multi-view 3DGS scene representations, Aes3DGSNet effectively captures high-l
What carries the argument
Aes3DGSNet, a lightweight network that takes 3D Gaussian primitives as input and regresses scene-level aesthetic scores via aesthetics-supervised learning on multi-view representations.
If this is right
- Creators of 3D content can obtain aesthetic feedback without rendering full multi-view images, lowering compute and hardware demands.
- The Aesthetic3D dataset provides a public resource for training and evaluating future 3D aesthetic assessment methods.
- Aes3DGSNet establishes a new performance benchmark for lightweight, direct-from-primitives aesthetic scoring in 3DGS scenes.
- The method supports iterative refinement of visually compelling 3D scenes in immersive media and digital content pipelines.
Where Pith is reading between the lines
- The same primitive-to-score mapping could be adapted to other explicit 3D representations such as point clouds or meshes if the input encoding is adjusted.
- Automated aesthetic optimization loops could be built on top of the scorer to adjust Gaussian parameters toward higher predicted appeal.
- Extending the annotation strategy to dynamic or animated 3DGS scenes would test whether the learned cues generalize beyond static views.
Load-bearing premise
High-level aesthetic attributes such as composition and harmony can be accurately regressed from the raw low-level attributes of 3D Gaussian primitives alone.
What would settle it
Human raters on a held-out set of 3DGS scenes give scores that show no correlation with the model's predictions, or the model matches or underperforms a simple baseline that ignores the 3D structure.
Figures











read the original abstract
As 3D Gaussian Splatting (3DGS) gains attention in immersive media and digital content creation, assessing the aesthetics of 3D scenes becomes important in helping creators build more visually compelling 3D content. However, existing evaluation methods for 3D scenes primarily emphasize reconstruction fidelity and perceptual realism, largely overlooking higher-level aesthetic attributes such as composition, harmony, and visual appeal. This limitation comes from two key challenges: (1) the absence of general 3DGS datasets with aesthetic annotations, and (2) the intrinsic nature of 3DGS as a low-level primitive representation, which makes it difficult to capture high-level aesthetic features. To address these challenges, we propose Aes3D, the first systematic framework for assessing the aesthetics of 3D neural rendering scenes. Aes3D includes Aesthetic3D, the first dataset dedicated to 3D scene aesthetic assessment, built on our proposed annotation strategy for 3D scene aesthetics. In addition, we present Aes3DGSNet, a lightweight model that directly predicts scene-level aesthetic scores from 3DGS representations. Notably, our model operates solely on 3D Gaussian primitives, eliminating the need for rendering multi-view images and thus reducing computational cost and hardware requirements. Through aesthetics-supervised learning on multi-view 3DGS scene representations, Aes3DGSNet effectively captures high-level aesthetic cues and accurately regresses aesthetic scores. Experimental results demonstrate that our approach achieves strong performance while maintaining a lightweight design, establishing a new benchmark for 3D scene aesthetic assessment. Code and datasets will be made available in a future version.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Aes3D as the first systematic framework for assessing aesthetics of 3D neural rendering scenes represented via 3D Gaussian Splatting. It introduces the Aesthetic3D dataset (the first dedicated to 3D scene aesthetic assessment, built via a proposed annotation strategy) and Aes3DGSNet, a lightweight model that directly regresses scene-level aesthetic scores (for attributes such as composition, harmony, and visual appeal) from 3DGS primitives alone, without rendering multi-view images. The model is trained via aesthetics-supervised learning on multi-view 3DGS representations, and the abstract claims that experiments demonstrate strong performance while maintaining a lightweight design, establishing a new benchmark.
Significance. If the central claims hold, the work would be significant for the field of neural rendering and immersive media by shifting evaluation focus from reconstruction fidelity to higher-level aesthetic attributes. The creation of a dedicated dataset and an efficient model that avoids rendering costs could enable practical tools for content creators. The use of multi-view training signals to learn from unordered 3D primitives is a potentially useful direction, though its soundness depends on validation details not supplied in the available text.
major comments (2)
- [Abstract] Abstract (final paragraph): The load-bearing claim that Aes3DGSNet 'directly predicts scene-level aesthetic scores from 3DGS representations' and 'operates solely on 3D Gaussian primitives, eliminating the need for rendering multi-view images' lacks any description of the architecture, aggregation mechanism over the unordered primitive set, or how view-dependent cues (occlusion, framing, lighting) are recovered. This is a correctness risk because aesthetic attributes are defined on 2D projections, and global statistics over primitives may not suffice even with multi-view training supervision.
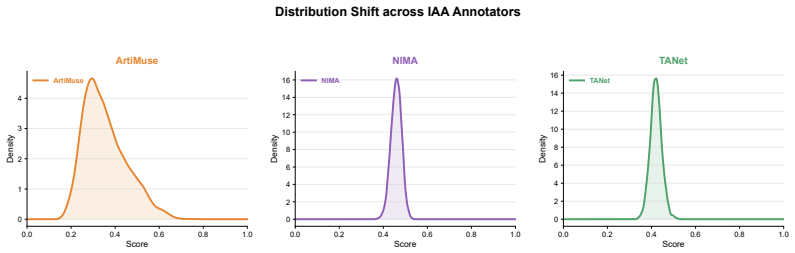
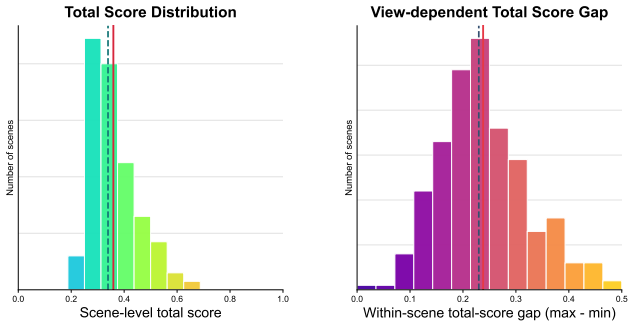
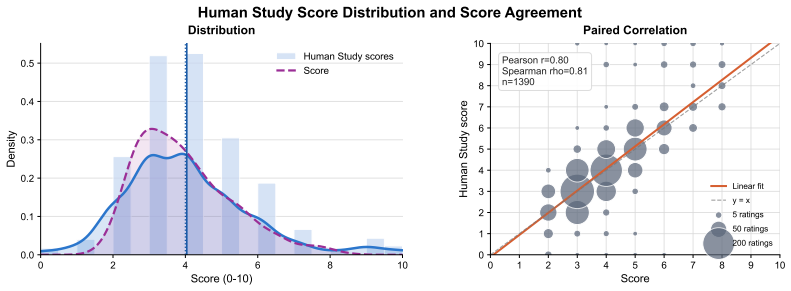
- [Abstract] Abstract (experimental results sentence): No quantitative metrics, dataset statistics (scene count, annotation protocol, inter-annotator agreement), model size, baselines, train/test splits, or error bars are reported, making it impossible to evaluate the 'strong performance' or 'lightweight design' assertions or to determine whether the data supports the new-benchmark claim.
minor comments (1)
- [Abstract] Abstract: The promise that 'Code and datasets will be made available in a future version' is positive, but the manuscript should supply at least high-level dataset statistics and annotation guidelines to allow readers to assess the annotation strategy's reliability.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments on the abstract. We respond to each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract (final paragraph): The load-bearing claim that Aes3DGSNet 'directly predicts scene-level aesthetic scores from 3DGS representations' and 'operates solely on 3D Gaussian primitives, eliminating the need for rendering multi-view images' lacks any description of the architecture, aggregation mechanism over the unordered primitive set, or how view-dependent cues (occlusion, framing, lighting) are recovered. This is a correctness risk because aesthetic attributes are defined on 2D projections, and global statistics over primitives may not suffice even with multi-view training supervision.
Authors: We agree the abstract is highly condensed and omits these details. The full manuscript (Section 3) specifies that Aes3DGSNet uses a lightweight set-based aggregator (permutation-invariant operations over the 3D Gaussian attributes) trained with multi-view aesthetic supervision; view-dependent effects are learned implicitly through the supervision signal rather than explicit rendering at inference. We will revise the abstract to include a short clause describing the aggregation mechanism and the multi-view training strategy. revision: yes
-
Referee: [Abstract] Abstract (experimental results sentence): No quantitative metrics, dataset statistics (scene count, annotation protocol, inter-annotator agreement), model size, baselines, train/test splits, or error bars are reported, making it impossible to evaluate the 'strong performance' or 'lightweight design' assertions or to determine whether the data supports the new-benchmark claim.
Authors: The abstract follows conventional length constraints by summarizing results at a high level. All requested quantitative information (dataset size and annotation protocol, inter-annotator agreement, model parameter count, baseline comparisons, cross-validation splits, and error bars) appears in the Experiments section. We will revise the abstract to incorporate one or two key quantitative highlights (e.g., correlation with human ratings and parameter count) while respecting word limits. revision: yes
Circularity Check
No significant circularity; new dataset and model are independent contributions
full rationale
The paper introduces a new dataset (Aesthetic3D) with a proposed annotation strategy and a new lightweight network (Aes3DGSNet) trained via supervised learning on multi-view 3DGS data to regress scene-level aesthetic scores directly from Gaussian primitives. No mathematical derivation chain, fitted parameters renamed as predictions, or self-citation load-bearing steps are present in the provided text. The central claims rest on empirical construction of the dataset and architecture rather than any reduction of outputs to inputs by definition or prior self-referential results. The approach is self-contained against external benchmarks of dataset creation and model performance.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.