Counterargument for Critical Thinking as Judged by AI and Humans
Pith reviewed 2026-05-08 16:23 UTC · model grok-4.3
The pith
Students' counterarguments to AI-generated theses contain logic as a key sign of critical thinking, and LLMs can assess such writing with moderate alignment to human judges.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that students' self-written counterarguments to AI-generated content contain logic, among other things, which is a key component of critical thinking, and that GenAI can be successfully used at scale to assess students' written work based on clear rubrics, with assessments generally aligning with human assessments as shown by Gwet's AC2 inter-rater reliability values of 0.33 for all the models except one.
What carries the argument
Six established rubrics (focus, logic, content, style, correctness, reference) applied uniformly to student counterarguments against AI-generated thesis statements, enabling direct quantitative comparison between human and LLM judges on the same 5-point scale.
Load-bearing premise
The six rubrics, especially the logic rubric, validly measure critical thinking and the single-course sample of 35 submissions generalizes beyond this university setting and topic set.
What would settle it
A replication study with a larger multi-institution sample where either the logic rubric scores fail to correlate with an independent validated critical thinking test or where the LLMs show substantially lower agreement with humans than the reported AC2 of 0.33.
Figures


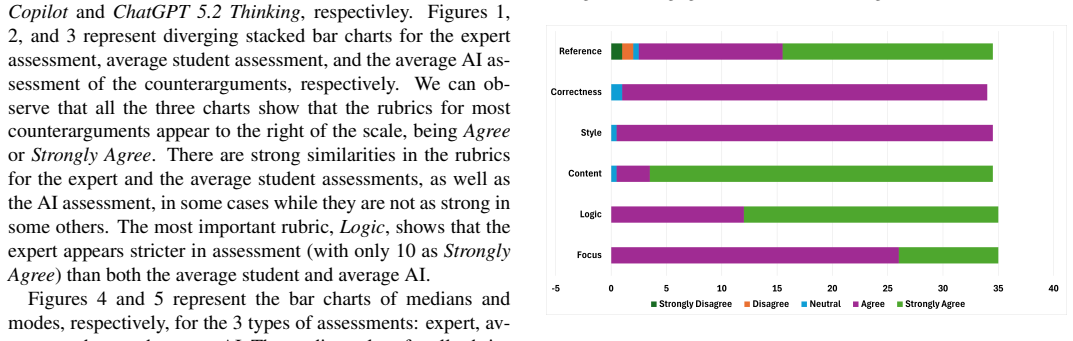




read the original abstract
This intervention study investigates the use of counterarguments in writing for critical thinking by students in the context of Generative AI (GenAI). This is especially as risks of cheating and cognitive offloading exist with the use of GenAI. We presented 36 students in a particular university course with 4 carefully selected thesis statements (from a set of popular debates) to write about anyone of them. We used six established rubrics (focus, logic, content, style, correctness and reference) to conduct three human assessments (two student peer-reviews and one experienced teacher) per writeup on a 5-point Likert scale for all the qualified samples (n) of 35 submissions (after disqualifying one for irregularity). Using the same rubrics and guidelines, we also assessed the submissions using six frontier LLMs as judges. Our mixed-method design included qualitative open-ended feedback per assessment and quantitative methods. The results reveal that (1) the students' self-written counterarguments to AI-generated content contains logic, among other things, which is a key component of critical thinking, and (2) GenAI can be successfully used at scale to assess students' written work, based on clear rubrics, and these assessments generally align with human assessments as shown with Gwets AC2 inter-rater reliability values of 0.33 for all the models except one.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports an intervention study with 35 students writing counterarguments to AI-generated theses on four debate topics. Six rubrics (focus, logic, content, style, correctness, reference) were applied on a 5-point scale by three human raters (two peers, one teacher) and six frontier LLMs per submission. Mixed-methods analysis of quantitative scores and qualitative feedback leads to two claims: (1) student counterarguments demonstrate logic (among other elements) as a key component of critical thinking, and (2) LLMs can assess student writing at scale using clear rubrics, with assessments generally aligning with humans (Gwet's AC2 = 0.33 for five of six models).
Significance. If the central claims hold after addressing sample and validation limitations, the work provides empirical support for using counterargument tasks to promote critical thinking in GenAI contexts and for deploying LLMs as scalable graders when rubrics are explicit. The mixed-methods design with multiple human raters and six LLMs offers direct comparative evidence, and the use of established rubrics plus open-ended feedback is a strength. However, the moderate AC2 value and single-course sample constrain claims about broad applicability in education.
major comments (3)
- [Methods (rubrics and assessment design)] Methods section on rubrics and participant selection: The first central claim rests on the 'logic' rubric scores indicating critical thinking, yet no validation data, citations to established CT instruments (e.g., Watson-Glaser or Delphi Report), or correlation with external CT measures are provided. This is load-bearing because the rubric is treated as directly measuring a 'key component' without supporting evidence.
- [Results (quantitative analysis) and Discussion] Results and Discussion on inter-rater reliability: Gwet's AC2 = 0.33 is presented as evidence of general alignment supporting scalable AI assessment, but the value is moderate, one model is an exception, and no error bars, confidence intervals, or baseline comparisons (e.g., to random or majority-class agreement) are reported. This directly affects the strength of claim (2) on successful use at scale.
- [Methods (participants) and Limitations] Methods and Limitations: The sample is restricted to 35 submissions from one university course on four specific topics. No power analysis, multi-site replication plan, or discussion of how rubric scores or AI-human agreement might vary by discipline, institution, or prompt set is included, limiting support for generalization in the abstract and conclusions.
minor comments (2)
- [Abstract and Methods] The abstract states 'n of 35 submissions (after disqualifying one)' but the introduction mentions 36 students; clarify the exact number of valid submissions and disqualification criteria.
- [Results] Table or figure presenting per-model AC2 values and per-rubric breakdowns would improve clarity; currently the single aggregate 0.33 value is hard to interpret without seeing variation across rubrics or models.
Simulated Author's Rebuttal
We thank the referee for these constructive comments on our manuscript. We address each major point below with clarifications and indicate where revisions will be made to strengthen the paper.
read point-by-point responses
-
Referee: [Methods (rubrics and assessment design)] Methods section on rubrics and participant selection: The first central claim rests on the 'logic' rubric scores indicating critical thinking, yet no validation data, citations to established CT instruments (e.g., Watson-Glaser or Delphi Report), or correlation with external CT measures are provided. This is load-bearing because the rubric is treated as directly measuring a 'key component' without supporting evidence.
Authors: We agree that explicit links to critical thinking frameworks would strengthen the first claim. Logic is a core component in established definitions such as the Delphi Report (Facione, 1990), which we will cite in the revised Introduction and Methods when describing the rubrics. The six rubrics were selected from established writing assessment practices for their applicability to argumentative counterarguments. However, this study did not include external validation against instruments like the Watson-Glaser or correlations with other CT measures, as the design focused on an intervention with rubric-based scoring. We will expand the Methods to justify the rubric choice and more explicitly note this as a limitation while qualifying the claim language. revision: partial
-
Referee: [Results (quantitative analysis) and Discussion] Results and Discussion on inter-rater reliability: Gwet's AC2 = 0.33 is presented as evidence of general alignment supporting scalable AI assessment, but the value is moderate, one model is an exception, and no error bars, confidence intervals, or baseline comparisons (e.g., to random or majority-class agreement) are reported. This directly affects the strength of claim (2) on successful use at scale.
Authors: We will revise the Results and Discussion sections to report confidence intervals for the Gwet's AC2 values and include baseline comparisons to chance-level agreement. We acknowledge that 0.33 indicates moderate agreement, which is typical for subjective writing evaluations but not strong evidence of equivalence; we will temper the language of claim (2) to describe 'moderate alignment' and discuss the exception for one model. These additions will be incorporated in the next version. revision: yes
-
Referee: [Methods (participants) and Limitations] Methods and Limitations: The sample is restricted to 35 submissions from one university course on four specific topics. No power analysis, multi-site replication plan, or discussion of how rubric scores or AI-human agreement might vary by discipline, institution, or prompt set is included, limiting support for generalization in the abstract and conclusions.
Authors: We will expand the Limitations section to address the single-course sample of 35 submissions, note that no a priori power analysis was conducted (as the study was exploratory), and qualify statements in the abstract and conclusions to indicate preliminary findings. We will also add discussion of potential variations by topic based on our existing data and recommend future multi-site studies for broader generalization. The sample cannot be expanded retrospectively. revision: partial
Circularity Check
No significant circularity; empirical study relies on external rubrics and ratings
full rationale
The paper reports an empirical intervention study that applies six established rubrics to 35 student submissions, obtains human ratings (peer and teacher), runs the same rubrics on six LLMs, and computes Gwet's AC2 inter-rater agreement. No equations, fitted parameters, or derived quantities appear in the provided text. The rubrics are described as established rather than defined inside the paper; the central claims (presence of logic in counterarguments and general alignment of LLM assessments) are direct empirical observations, not reductions of one quantity to another by construction. No self-citation chains or uniqueness theorems are invoked as load-bearing premises. The analysis therefore contains no self-definitional, fitted-input, or self-citation circularity steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Established rubrics (focus, logic, content, style, correctness, reference) validly capture components of critical thinking
- standard math Gwet's AC2 is an appropriate measure for inter-rater agreement on ordinal rubric scores
Reference graph
Works this paper leans on
- [1]
-
[2]
author Adewumi, T. , author Alkhaled, L. , author Buck, C. , author Hernandez, S. , author Brilioth, S. , author Kekung, M. , author Ragimov, Y. , author Barney, E. , year 2025 a. title Procot: Stimulating critical thinking and writing of students through engagement with large language models (llms) . journal Journal of Pedagogical Sociology and Psycholog...
-
[3]
author Adewumi, T. , author Alkhaled, L. , author Gurung, N. , author van Boven, G. , author Pagliai, I. , year 2024 . title Fairness and bias in multimodal ai: A survey . journal arXiv preprint arXiv:2406.19097
-
[4]
Ai must not be fully autonomous,
author Adewumi, T. , author Alkhaled, L. , author Imbert, F. , author Han, H. , author Habib, N. , author L \"o wenmark, K. , year 2025 b. title Ai must not be fully autonomous . journal arXiv preprint arXiv:2507.23330
-
[5]
author Adewumi, T. , author Habib, N. , author Alkhaled, L. , author Barney, E. , year 2025 c. title On the limitations of large language models ( LLM s): False attribution , in: editor Angelova, G. , editor Kunilovskaya, M. , editor Escribe, M. , editor Mitkov, R. (Eds.), booktitle Proceedings of the 15th International Conference on Recent Advances in Na...
work page 2025
-
[6]
author Adewumi, T. , author Liwicki, F.S. , author Liwicki, M. , author Gardelli, V. , author Alkhaled, L. , author Mokayed, H. , year 2025 d. title Findings of mega: Math explanation with llms using the socratic method for active learning . journal IEEE Signal Processing Magazine volume 42 , pages 77--94 . :10.1109/MSP.2025.3590807
-
[7]
author Alkharusi, H. , year 2022 . title A descriptive analysis and interpretation of data from likert scales in educational and psychological research . journal Indian Journal of Psychology and Education volume 12 , pages 13--16
work page 2022
-
[8]
author Anderson, L.W. , author Krathwohl, D.R. , year 2001 . title A taxonomy for learning, teaching, and assessing: A revision of Bloom's taxonomy of educational objectives: complete edition . publisher Addison Wesley Longman, Inc
work page 2001
-
[9]
author Bloom, B.S. , author Engelhart, M.D. , author Furst, E.J. , author Hill, W.H. , author Krathwohl, D.R. , et al., year 1956 . title Taxonomy of educational objectives: The classification of educational goals. Handbook 1: Cognitive domain . publisher Longman New York
work page 1956
-
[10]
author Brookhart, S.M. , year 2013 . title How to create and use rubrics for formative assessment and grading . publisher Ascd
work page 2013
-
[11]
author Chi, M.T. , author Wylie, R. , year 2014 . title The icap framework: Linking cognitive engagement to active learning outcomes . journal Educational psychologist volume 49 , pages 219--243
work page 2014
-
[12]
author Duron, R. , author Limbach, B. , author Waugh, W. , year 2006 . title Critical thinking framework for any discipline . journal International Journal of teaching and learning in higher education volume 17 , pages 160--166
work page 2006
-
[13]
author Dwyer, C.P. , author Hogan, M.J. , author Stewart, I. , year 2014 . title An integrated critical thinking framework for the 21st century . journal Thinking skills and Creativity volume 12 , pages 43--52
work page 2014
-
[14]
author Dwyer, C.P. , author Hogan, M.J. , author Stewart, I. , year 2015 . title The promotion of critical thinking skills through argument mapping
work page 2015
-
[15]
author Ennis, R.H. , author Weir, E.E. , year 1985 . title The Ennis-Weir critical thinking essay test: An instrument for teaching and testing . publisher Midwest Publications
work page 1985
-
[16]
author Facione, P.A. , year 1990 . title The delphi report: Committee on pre-college philosophy , in: booktitle American Philosophical Association
work page 1990
-
[17]
author Fulan, L. , author Mengchen, Z. , author Wenyun, L. , year 2025 . title Corpus-assisted counterargumentation instruction: cultivating critical thinking via argumentative writing . journal Thinking Skills and Creativity , pages 102120
work page 2025
-
[18]
author Gerlich, M. , year 2025 a. title Ai tools in society: Impacts on cognitive offloading and the future of critical thinking . journal Societies volume 15 , pages 6
work page 2025
-
[19]
2025, Societies, 15, 6, doi: 10.3390/soc15010006
author Gerlich, M. , year 2025 b. title AI tools in society: Impacts on cognitive offloading and the future of critical thinking . journal Societies volume 15 , pages 6 . :10.3390/soc15010006
-
[20]
author Gonz \'a lez, I. , author Rapanta, C. , author Larrain, A. , year 2026 . title Promoting argumentation skills among university students: A scoping review . journal Higher Education Quarterly volume 80 , pages e70080
work page 2026
-
[21]
author Halpern, R. , year 2006 . title Halpern critical thinking assessment using everyday situations: Background and scoring standards claremont ca: Claremont mckenna college
work page 2006
-
[22]
author Helal, M.Y. , author Elgendy, I.A. , author Albashrawi, M.A. , author Dwivedi, Y.K. , author Al-Ahmadi, M.S. , author Jeon, I. , year 2025 . title The impact of generative ai on critical thinking skills: a systematic review, conceptual framework and future research directions . journal Information Discovery and Delivery
work page 2025
-
[23]
author Howard, R.D. , author McLaughlin, G.W. , author Knight, W.E. , year 2012 . title The handbook of institutional research . publisher John Wiley & Sons
work page 2012
-
[24]
author Jonsson, A. , author Svingby, G. , year 2007 . title The use of scoring rubrics: Reliability, validity and educational consequences . journal Educational research review volume 2 , pages 130--144
work page 2007
-
[25]
author Joshi, A. , author Kale, S. , author Chandel, S. , author Pal, D.K. , year 2015 . title Likert scale: Explored and explained . journal British journal of applied science & technology volume 7 , pages 396
work page 2015
-
[26]
author Kasneci, E. , author Se ler, K. , author K \"u chemann, S. , author Bannert, M. , author Dementieva, D. , author Fischer, F. , author Gasser, U. , author Groh, G. , author G \"u nnemann, S. , author H \"u llermeier, E. , et al., year 2023 . title Chatgpt for good? on opportunities and challenges of large language models for education . journal Lear...
work page 2023
-
[27]
author Kocmi, T. , author Federmann, C. , year 2023 . title Large language models are state-of-the-art evaluators of translation quality , in: booktitle Proceedings of the 24th Annual Conference of the European Association for Machine Translation , pp. pages 193--203
work page 2023
-
[28]
author Kosmyna, N. , author Hauptmann, E. , author Yuan, Y.T. , author Situ, J. , author Liao, X.H. , author Beresnitzky, A.V. , author Braunstein, I. , author Maes, P. , year 2025 a. title Your brain on chatgpt: Accumulation of cognitive debt when using an ai assistant for essay writing task . journal arXiv preprint arXiv:2506.08872 volume 4
work page internal anchor Pith review arXiv 2025
-
[29]
author Kosmyna, N. , author Hauptmann, E. , author Yuan, Y.T. , author Situ, J. , author Liao, X.H. , author Beresnitzky, A.V. , author Braunstein, I. , author Maes, P. , year 2025 b. title Your brain on ChatGPT : Accumulation of cognitive debt when using an AI assistant for essay writing task . :10.48550/ARXIV.2506.08872. note version Number: 2
work page internal anchor Pith review doi:10.48550/arxiv.2506.08872 2025
-
[30]
author Ku, K.Y. , year 2009 . title Assessing students’ critical thinking performance: Urging for measurements using multi-response format . journal Thinking skills and creativity volume 4 , pages 70--76
work page 2009
-
[31]
author Kuhn, D. , year 1991 . title The skills of argument . publisher Cambridge University Press
work page 1991
-
[32]
author Kuhn, D. , year 2018 . title A role for reasoning in a dialogic approach to critical thinking . journal Topoi volume 37 , pages 121--128
work page 2018
-
[33]
author Lai, E.R. , year 2011 . title Critical thinking: A literature review . journal Pearson's research reports volume 6 , pages 40--41
work page 2011
-
[34]
author Li, X. , author Jiang, Q. , author Jiang, L. , author Zhang, S. , author Hu, S. , year 2026 . title The landscape of ai alignment: A comprehensive review of theories and methods . journal International Journal of Pattern Recognition and Artificial Intelligence volume 40 , pages 2539001
work page 2026
-
[35]
author Ling, J.H. , year 2025 . title A review of rubrics in education: Potential and challenges . journal Indonesian Journal of Innovative Teaching and Learning volume 2 , pages 1--14
work page 2025
-
[36]
author Liu, F. , author Stapleton, P. , year 2020 . title Counterargumentation at the primary level: An intervention study investigating the argumentative writing of second language learners . journal System volume 89 , pages 102198
work page 2020
-
[37]
author Liu, J. , year 2025 . title The role of generative AI in the process of autonomous learning of college students . journal Journal of Education, Humanities and Social Sciences volume 53 , pages 38--42 . :10.54097/brzv3w55
-
[38]
author Manurung, M.R. , author Masitoh, S. , author Arianto, F. , year 2022 . title How thinking routines enhance critical thinking of elementary students . journal IJORER: International Journal of Recent Educational Research volume 3 , pages 640--650
work page 2022
-
[39]
author Mulaudzi, L.V. , author Hamilton, J. , year 2025 . title Lecturer’s perspective on the role of ai in personalized learning: Benefits, challenges, and ethical considerations in higher education . journal Journal of Academic Ethics volume 23 , pages 1571--1591
work page 2025
-
[40]
author Nussbaum, E.M. , author Sinatra, G.M. , year 2003 . title Argument and conceptual engagement . journal Contemporary Educational Psychology volume 28 , pages 384--395
work page 2003
-
[41]
author Pinedo, R. , author Garc \' a, N. , author Ca \ n as, M. , year 2018 . title Thinking routines across different subjects and educational levels , in: booktitle INTED2018 Proceedings , organization IATED . pp. pages 5577--5580
work page 2018
-
[42]
Applied Sciences 13(9), 5783 (2023), 10.3390/app13095783
author Rahman, M.M. , author Watanobe, Y. , year 2023 . title ChatGPT for education and research: Opportunities, threats, and strategies . journal Applied Sciences volume 13 , pages 5783 . :10.3390/app13095783
-
[43]
author Ritchhart, R. , author Church, M. , author Morrison, K. , year 2011 . title Making thinking visible: How to promote engagement, understanding, and independence for all learners . publisher John Wiley & Sons
work page 2011
-
[44]
author Romiszowski, A.J. , year 2016 . title Designing instructional systems: Decision making in course planning and curriculum design . publisher Routledge
work page 2016
-
[45]
author Sinfield, S. , author Burns, T. , year 2023 . title Design thinking in education: Adding collaboration, uncertainty, phronesis and fairydust to curriculum design . journal International Journal of Management and Applied Research volume 10 , pages 263--269
work page 2023
-
[46]
author Toulmin, S.E. , year 2003 . title The uses of argument . publisher Cambridge university press
work page 2003
-
[47]
author Tripathi, S. , author Alkhulaifat, D. , author Lyo, S. , author Sukumaran, R. , author Li, B. , author Acharya, V. , author McBeth, R. , author Cook, T.S. , year 2025 . title A hitchhiker's guide to good prompting practices for large language models in radiology . journal Journal of the American College of Radiology volume 22 , pages 841--847
work page 2025
-
[48]
author Watson, G. , year 1980 . title Watson-Glaser critical thinking appraisal . volume volume 3 . publisher Psychological Corporation San Antonio, TX
work page 1980
-
[49]
author Yavuz, F. , author C elik, \"O . , author Yava s C elik, G. , year 2025 . title Utilizing large language models for efl essay grading: An examination of reliability and validity in rubric-based assessments . journal British Journal of Educational Technology volume 56 , pages 150--166
work page 2025
-
[50]
author Zheng, L. , author Chiang, W.L. , author Sheng, Y. , author Zhuang, S. , author Wu, Z. , author Zhuang, Y. , author Lin, Z. , author Li, Z. , author Li, D. , author Xing, E. , et al., year 2023 . title Judging llm-as-a-judge with mt-bench and chatbot arena . journal Advances in neural information processing systems volume 36 , pages 46595--46623
work page 2023
-
[51]
author Zou, D. , author Xie, H. , author Kohnke, L. , year 2025 . title Navigating the future: establishing a framework for educators' pedagogic artificial intelligence competence . journal European Journal of Education volume 60 , pages e70117
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.