Recognition: 1 theorem link
· Lean TheoremWhat Will Happen Next: Large Models-Driven Deduction for Emergency Instances
Pith reviewed 2026-05-12 00:49 UTC · model grok-4.3
The pith
Large models can be guided to deduce multiple plausible future paths for emergency events.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
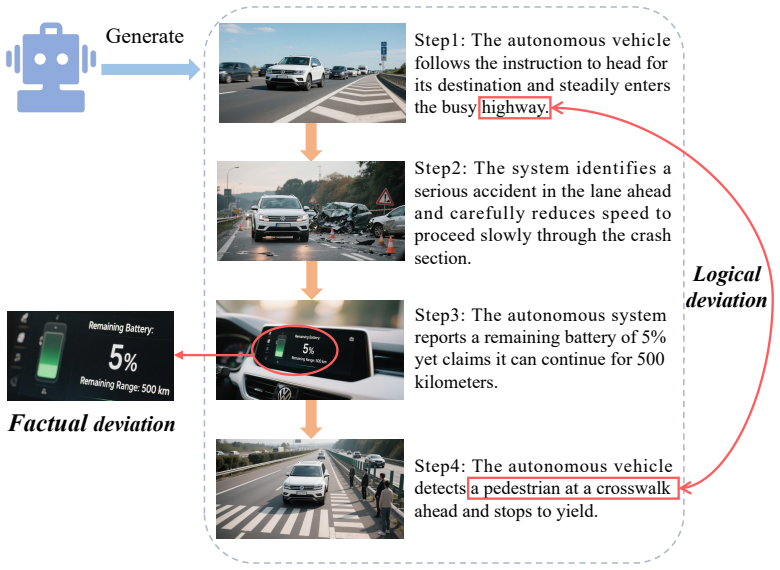
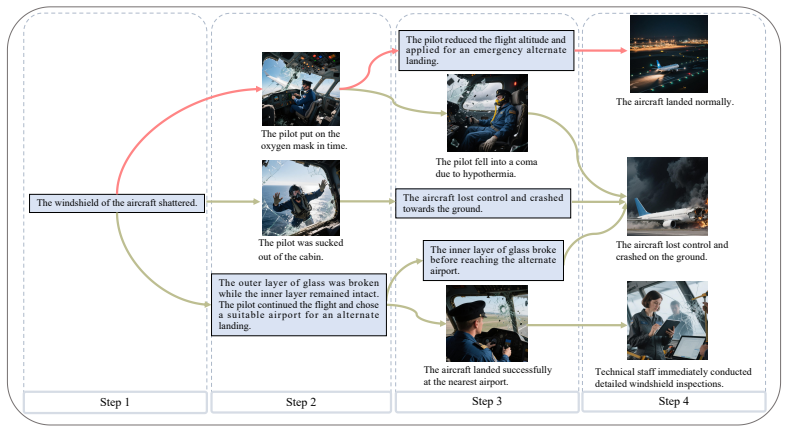
The LMs-driven World Line Divergence System (WLDS) enables diversified visualization and deduction of emergency instances in various domains by using large models to generate multiple development directions, applying factual calibration and logical calibration to maintain accuracy and rigor, incorporating an interactive module for users to select paths and avoid undetected hallucinations, and adding a visualization module that combines text and images for greater interpretability.
What carries the argument
World Line Divergence System (WLDS), which uses large models to diverge emergency paths while applying calibration and interactive checks.
If this is right
- The system can generate additional emergency deduction data beyond the scarce real instances available.
- Users gain support for decision-making in similar future emergencies through exploration of multiple paths.
- High-fidelity text-and-image simulations become available across multiple specific domains.
- The approach extends traditional simulation by adding controllable randomness while preserving factual grounding.
Where Pith is reading between the lines
- Generated deduction data could serve as synthetic training material to improve specialized prediction models in related domains.
- The calibration and interaction pattern might transfer to non-emergency planning tasks such as infrastructure or supply-chain disruptions.
- Real-time sensor inputs could be added to let the system update its deductions dynamically as events unfold.
Load-bearing premise
Large models guided by factual and logical calibration plus user interaction can produce accurate emergency deductions without introducing errors the system fails to catch.
What would settle it
A concrete test case on the EID benchmark where WLDS outputs an emergency development path containing a clear factual or logical inconsistency that neither the calibration steps nor the interactive module flags.
Figures






read the original abstract
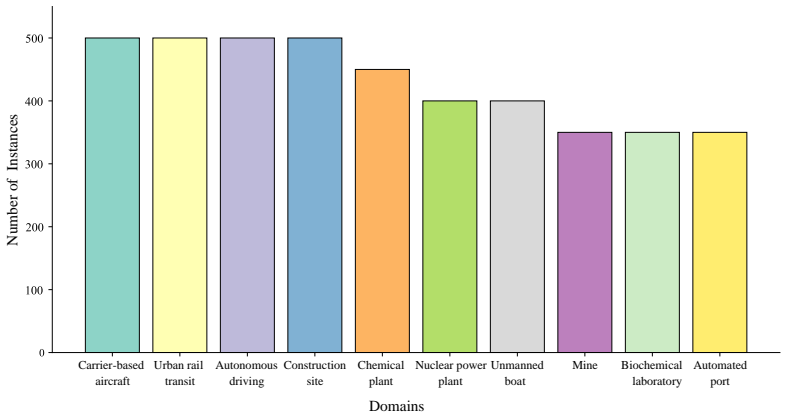
Traditional simulation methods reproduce occurred emergency instances through presetting to assist people in risk assessment and emergency decision-making. However, due to the lack of randomness and diversity, existing simulation systems struggle to fully explore the potential risk as emergency instances are scarce. In contrast, Large Models (LMs) can dynamically adjust generation strategies to introduce controllable randomness, while also possessing extensive prior knowledge and cross-domain knowledge transfer capabilities. Inspired by it, we propose the LMs-driven World Line Divergence System (WLDS), which enables diversified visualization and deduction of emergency instances in different domains. WLDS leverages LMs to deduce emergency instances in various development directions, and introduces the factual calibration and logical calibration mechanism to ensure factual accuracy and logical rigor during the deduction process. The interactive module can independently select deduction directions to avoid potential hallucinations that are difficult for the system to identify. Furthermore, by introducing the visualization module, WLDS forms simulation and deduction that combine text and images, which enhances interpretability. Extensive experiments conducted on the proposed Emergency Instances Deduction (EID) benchmark dataset demonstrate that WLDS achieves high-precision and high-fidelity simulation and deduction of emergency instances in multiple specific domains. Relevant experiments further demonstrate that WLDS can generate more emergency instances deduction data for users and provide support for better decision-making in similar emergency instances in the future.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the LMs-driven World Line Divergence System (WLDS) for diversified visualization and deduction of emergency instances. It uses large models with factual and logical calibration mechanisms, an interactive module to avoid hallucinations, and a visualization module for text-image simulations. The system is tested on the authors' proposed Emergency Instances Deduction (EID) benchmark, claiming high-precision and high-fidelity results in multiple domains.
Significance. If the experimental claims hold with rigorous validation, WLDS could advance emergency simulation by using large models to generate diverse, controllable scenarios that traditional preset methods cannot explore due to limited randomness and data scarcity. This has potential value for risk assessment and decision-making support in data-sparse domains.
major comments (4)
- [Abstract] Abstract: The claim that 'Extensive experiments conducted on the proposed Emergency Instances Deduction (EID) benchmark dataset demonstrate that WLDS achieves high-precision and high-fidelity simulation and deduction' supplies no quantitative metrics, error rates, baseline comparisons, or statistical analysis to substantiate the high-precision assertion.
- [EID Benchmark] EID Benchmark section: The self-proposed EID dataset lacks external validation, independent sourcing, or objective ground truth for open-ended/counterfactual deductions; without blinded expert panels or held-out real-world outcomes, it is unclear whether factual/logical calibration generalizes or fits patterns in the benchmark itself.
- [Interactive Module] Interactive Module description: The assertion that the interactive module 'can independently select deduction directions to avoid potential hallucinations that are difficult for the system to identify' provides no quantitative evidence such as pre/post-intervention error rates or inter-rater reliability on fidelity scores.
- [Experiments] Experiments section: No details are given on the specific domains tested, number of instances evaluated, measurement of 'high-fidelity,' or how calibration prevents hallucinations, leaving the central empirical claim unsupported.
minor comments (1)
- [Abstract] Abstract: The reference to 'Relevant experiments further demonstrate...' is vague and does not specify the experiments or their outcomes.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below and commit to a major revision that strengthens the empirical support, benchmark documentation, and quantitative analysis in the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'Extensive experiments conducted on the proposed Emergency Instances Deduction (EID) benchmark dataset demonstrate that WLDS achieves high-precision and high-fidelity simulation and deduction' supplies no quantitative metrics, error rates, baseline comparisons, or statistical analysis to substantiate the high-precision assertion.
Authors: We agree that the abstract statement is insufficiently specific. In the revised version we will replace the qualitative claim with concrete metrics drawn from the experiments section, including precision and fidelity scores, baseline comparisons, and statistical significance where applicable. revision: yes
-
Referee: [EID Benchmark] EID Benchmark section: The self-proposed EID dataset lacks external validation, independent sourcing, or objective ground truth for open-ended/counterfactual deductions; without blinded expert panels or held-out real-world outcomes, it is unclear whether factual/logical calibration generalizes or fits patterns in the benchmark itself.
Authors: The EID benchmark was created because no suitable public dataset exists for this open-ended deduction task. We will expand the benchmark section to describe the sourcing process (drawing from public emergency reports and scenario templates), the role of factual and logical calibration in reducing overfitting, and any internal consistency checks performed. We acknowledge that fully blinded expert panels or held-out real-world counterfactual outcomes would strengthen the work; we will add an explicit limitations paragraph on this point and note that the calibration mechanisms are intended to improve generalization beyond the benchmark patterns. revision: partial
-
Referee: [Interactive Module] Interactive Module description: The assertion that the interactive module 'can independently select deduction directions to avoid potential hallucinations that are difficult for the system to identify' provides no quantitative evidence such as pre/post-intervention error rates or inter-rater reliability on fidelity scores.
Authors: We will add quantitative ablation results in the revised experiments section, reporting pre- and post-interactive-module hallucination rates (measured via automated fact-checking and human fidelity ratings) together with inter-rater agreement statistics on the fidelity scores. revision: yes
-
Referee: [Experiments] Experiments section: No details are given on the specific domains tested, number of instances evaluated, measurement of 'high-fidelity,' or how calibration prevents hallucinations, leaving the central empirical claim unsupported.
Authors: We will substantially expand the Experiments section to specify the domains evaluated (fire, flood, traffic, and chemical incidents), the exact number of instances per domain, the concrete metrics and protocols used to quantify high-fidelity (expert-rated realism, logical coherence, and factual accuracy), and ablation studies isolating the contribution of factual and logical calibration to hallucination reduction. revision: yes
Circularity Check
No circularity: system proposal with no derivations or self-referential reductions
full rationale
The paper proposes the WLDS system for LM-driven emergency deduction with factual/logical calibration and interactive modules, then reports results on its newly introduced EID benchmark. No equations, parameters, or derivation chains appear in the abstract or described content. No self-citations justify uniqueness theorems or load-bearing premises. The central claim is an empirical performance assertion on author-created data rather than a mathematical result that reduces to its inputs by construction. This matches the default case of a self-contained descriptive system paper with no identifiable circular steps per the enumerated patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Large Models can dynamically adjust generation strategies to introduce controllable randomness while possessing extensive prior knowledge and cross-domain knowledge transfer capabilities.
- domain assumption Factual calibration and logical calibration mechanisms can ensure factual accuracy and logical rigor during the deduction process.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
WLDS leverages LMs to deduce emergency instances... factual calibration and logical calibration mechanism... EID benchmark dataset
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
C. H. dos Santos, J. A. de Queiroz, F. Leal, J. A. B. Montevechi, Use of simulation in the industry 4.0 context: Creation of a digital twin to opti- mise decision making on non-automated process, Journal of Simulation 16 (3) (2022) 284–297. doi:10.1080/17477778.2020.1811172
-
[2]
M. Rissanen, L. Metso, K. Elfvengren, T. Sinkkonen, Serious games for decision-making processes: A systematic literature review, in: J. P. Liyanage, J. Amadi-Echendu, J. Mathew (Eds.), Engineering Assets and Public Infrastructures in the Age of Digitalization, Springer Interna- tional Publishing, Cham, 2020, pp. 330–338
work page 2020
-
[3]
Y. Yu, Y. Wang, Y. Zhang, H. Qu, D. Liu, Inclusiviz : Visual analytics of human mobility data for understanding and mitigating urban seg- regation, IEEE Transactions on Visualization and Computer Graphics 31 (6) (2025) 3836–3849. doi:10.1109/TVCG.2025.3567117
- [4]
-
[5]
H. Liu, L. Zhang, S. K. Sastry Hari, J. Zhao, Safety-critical scenario generation via reinforcement learning based editing, in: 2024 IEEE In- ternational Conference on Robotics and Automation (ICRA), 2024, pp. 14405–14412. doi:10.1109/ICRA57147.2024.10611555
-
[6]
A. Zlocki, A. König, J. Bock, H. Weber, H. Muslim, H. Naka- mura, S. Watanabe, J. Antona-Makoshi, S. Taniguchi, Logi- cal scenarios parameterization for automated vehicle safety as- sessment: Comparison of deceleration and cut-in scenarios from japanese and german highways, IEEE Access 10 (2022) 26817–26829. doi:10.1109/ACCESS.2022.3154415. 24
-
[7]
S. Wang, M. Han, Z. Jiao, Z. Zhang, Y. N. Wu, S.-C. Zhu, H. Liu, Llm3: Large language model-based task and motion planning with mo- tion failure reasoning, in: 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024, pp. 12086–12092. doi:10.1109/IROS58592.2024.10801328
-
[8]
X. Cheng, K. Zhang, T. Wu, Z. Xu, X. Gou, An opinions- updating model for large-scale group decision-making driven by autonomous learning, Information Sciences 662 (2024) 120238. doi:https://doi.org/10.1016/j.ins.2024.120238
-
[9]
N. C. Rajashekar, Y. E. Shin, Y. Pu, S. Chung, K. You, M. Giuf- fre, C. E. Chan, T. Saarinen, A. Hsiao, J. Sekhon, A. H. Wong, L. V. Evans, R. F. Kizilcec, L. Laine, T. Mccall, D. Shung, Human- algorithmic interaction using a large language model-augmented artifi- cial intelligence clinical decision support system, in: Proceedings of the 2024 CHI Conferen...
-
[10]
S. Li, T. Azfar, R. Ke, Chatsumo: Large language model for automating traffic scenario generation in simulation of ur- ban mobility, IEEE Transactions on Intelligent Vehicles (2024) 1– 12doi:10.1109/TIV.2024.3508471
- [11]
-
[12]
J. Yuan, X. Ma, D. Chen, K. Kuang, F. Wu, L. Lin, Domain- specific bias filtering for single labeled domain generalization, In- ternational Journal of Computer Vision 131 (2) (2023) 552–571. doi:https://doi.org/10.1007/s11263-022-01712-7
-
[13]
J. Yuan, X. Ma, D. Chen, F. Wu, L. Lin, K. Kuang, Collaborative se- mantic aggregation and calibration for federated domain generalization, IEEE Transactions on Knowledge and Data Engineering 35 (12) (2023) 12528–12541. doi:10.1109/TKDE.2023.3271851. 25
-
[14]
J. Yuan, X. Ma, D. Chen, K. Kuang, F. Wu, L. Lin, Label-efficient do- main generalization via collaborative exploration and generalization, in: Proceedings of the 30th ACM International Conference on Multimedia, MM ’22, Association for Computing Machinery, New York, NY, USA, 2022, p. 2361–2370. doi:10.1145/3503161.3548059
- [15]
- [16]
-
[17]
D. Chen, Y. Zhuang, S. Zhang, J. Liu, S. Dong, S. Tang, Data shunt: Collaboration of small and large models for lower costs and better per- formance, Proceedings of the AAAI Conference on Artificial Intelligence 38 (10) (2024) 11249–11257. doi:10.1609/aaai.v38i10.29003
- [18]
-
[19]
S.Hawking, G.Ellis, Thelargescalestructureofspacetim-e(cambridge university press, cambridge, england, 1973), B. Carter, Phys. Rev. 2 174
work page 1973
-
[20]
C. Chang, S. Wang, J. Zhang, J. Ge, L. Li, Llmscenario: Large lan- guage model driven scenario generation, IEEE Transactions on Sys- tems, Man, and Cybernetics: Systems 54 (11) (2024) 6581–6594. doi:10.1109/TSMC.2024.3392930
-
[21]
F. Lu, F. Meng, H. Bi, Scenario deduction of explosion ac- cident based on fuzzy dynamic bayesian network, Journal of Loss Prevention in the Process Industries 96 (2025) 105613. doi:https://doi.org/10.1016/j.jlp.2025.105613
-
[22]
X. Zhang, S. Zeinali, G. Schildbach, Interaction-aware traffic prediction and scenario-based model predictive control for autonomous vehicles on 26 highways, IEEE Transactions on Control Systems Technology 33 (4) (2025) 1235–1245. doi:10.1109/TCST.2024.3458817
-
[23]
J. Cai, S. Yang, H. Guang, A review on scenario generation for testing autonomous vehicles, in: 2024 IEEE Intelligent Vehicles Symposium (IV), 2024, pp. 3371–3376. doi:10.1109/IV55156.2024.10588675
-
[24]
T. Niu, K. Zhang, Z. Gan, W. Ding, Planning by sim- ulation: Motion planning with learning-based parallel scenario prediction for autonomous driving (2024). arXiv:2411.09887, doi:https://arxiv.org/abs/2411.09887
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
C. Xu, A. Petiushko, D. Zhao, B. Li, Diffscene: Diffusion-based safety- critical scenario generation for autonomous vehicles, Proceedings of the AAAI Conference on Artificial Intelligence 39 (8) (2025) 8797–8805. doi:10.1609/aaai.v39i8.32951
-
[26]
G. Bagschik, T. Menzel, M. Maurer, Ontology based scene cre- ation for the development of automated vehicles, in: 2018 IEEE Intelligent Vehicles Symposium (IV), 2018, pp. 1813–1820. doi:10.1109/IVS.2018.8500632
-
[27]
A. Li, S. Chen, L. Sun, N. Zheng, M. Tomizuka, W. Zhan, Scegene: Bio-inspired traffic scenario generation for autonomous driving testing, IEEE Transactions on Intelligent Transportation Systems 23 (9) (2022) 14859–14874. doi:10.1109/TITS.2021.3134661
-
[28]
M. Bäumler, F. Linke, G. Prokop, Categorizing data-driven methods for test scenario generation to assess automated driving systems, IEEE Access 12 (2024) 52030–52050. doi:10.1109/ACCESS.2024.3385646
-
[29]
S. Thal, R. Henze, R. Hasegawa, H. Nakamura, H. Imanaga, J. Antona-Makoshi, N. Uchida, Generic detection and search-based test case generation of urban scenarios based on real driving data, in: 2022 IEEE Intelligent Vehicles Symposium (IV), 2022, pp. 694–701. doi:10.1109/IV51971.2022.9827198
-
[30]
doi:10.1109/ACCESS.2023.3340442
M.Bäumler, G.Prokop, Testscenariofusion: Howtofusescenariosfrom accident and traffic observation data, IEEE Access 12 (2024) 16354– 16374. doi:10.1109/ACCESS.2023.3340442. 27
-
[31]
W. de Paula Ferreira, F. Armellini, L. A. De Santa- Eulalia, Simulation in industry 4.0: A state-of-the-art re- view, Computers & Industrial Engineering 149 (2020) 106868. doi:https://doi.org/10.1016/j.cie.2020.106868
-
[32]
D. Mourtzis, Simulation in the design and operation of man- ufacturing systems: state of the art and new trends, Inter- national Journal of Production Research 58 (7) (2020) 1927–
work page 2020
-
[33]
arXiv:https://doi.org/10.1080/00207543.2019.1636321, doi:10.1080/00207543.2019.1636321
-
[34]
G. Baudry, C. Macharis, T. Vallée, Range-based multi-actor multi- criteriaanalysis: Acombinedmethodofmulti-actormulti-criteriaanaly- sis and monte carlo simulation to support participatory decision making under uncertainty, European Journal of Operational Research 264 (1) (2018) 257–269. doi:https://doi.org/10.1016/j.ejor.2017.06.036
-
[35]
R. Chin, S.-P. van Houten, A. Verbraeck, Towards a simulation and vi- sualization portal to support multi-actor decision making in mainports, in: Proceedings of the Winter Simulation Conference, 2005., 2005, pp. 6 pp.–. doi:10.1109/WSC.2005.1574544
-
[36]
A. L. Hananto, A. Tirta, S. G. Herawan, M. Idris, M. E. M. Soudagar, D. W. Djamari, I. Veza, Digital twin and 3d digital twin: Concepts, applications, and challenges in industry 4.0 for digital twin, Computers 13 (4) (2024). doi:10.3390/computers13040100
-
[37]
A. J. G. de Azambuja, T. Giese, K. Schützer, R. Anderl, B. Schle- ich, V. R. Almeida, Digital twins in industry 4.0 – opportuni- ties and challenges related to cyber security, Procedia CIRP 121 (2024) 25–30, 11th CIRP Global Web Conference (CIRPe 2023). doi:https://doi.org/10.1016/j.procir.2023.09.225
-
[38]
X. Liu, I. David, Ai simulation by digital twins: Systematic survey of the state of the art and a reference framework, in: Proceedings of the ACM/IEEE 27th International Conference on Model Driven En- gineering Languages and Systems, MODELS Companion ’24, Associa- tion for Computing Machinery, New York, NY, USA, 2024, p. 401–412. doi:10.1145/3652620.3688253. 28
-
[39]
V. Astarita, G. Guido, S. S. Haghshenas, S. S. Haghshenas, Risk re- duction in transportation systems: The role of digital twins according to a bibliometric-based literature review, Sustainability 16 (8) (2024). doi:10.3390/su16083212
-
[40]
C. Roumeliotis, M. Dasygenis, V. Lazaridis, M. Dossis, Blockchain and digital twins in smart industry 4.0: The use case of supply chain-a re- view of integration techniques and applications, Designs 8 (6) (2024). doi:10.3390/designs8060105
-
[41]
A. Padovano, F. Longo, L. Manca, R. Grugni, Improving safety man- agement in railway stations through a simulation-based digital twin approach, Computers & Industrial Engineering 187 (2024) 109839. doi:https://doi.org/10.1016/j.cie.2023.109839
-
[42]
S. James, Z. Ma, D. R. Arrojo, A. J. Davison, Rlbench: The robot learn- ing benchmark & learning environment, IEEE Robotics and Automation Letters 5 (2) (2020) 3019–3026. doi:10.1109/LRA.2020.2974707
-
[43]
O. Mees, L. Hermann, E. Rosete-Beas, W. Burgard, Calvin: A bench- mark for language-conditioned policy learning for long-horizon robot manipulation tasks, IEEE Robotics and Automation Letters 7 (3) (2022) 7327–7334. doi:10.1109/LRA.2022.3180108
- [44]
-
[45]
W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y. Hou, Y. Min, B. Zhang, J. Zhang, Z. Dong, Y. Du, C. Yang, Y. Chen, Z. Chen, J. Jiang, R. Ren, Y. Li, X. Tang, Z. Liu, P. Liu, J.-Y. Nie, J.-R. Wen, A survey of large language models (2025). arXiv:2303.18223, doi:https://arxiv.org/abs/2303.18223
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [46]
- [47]
- [48]
-
[49]
H. Wang, J. Chen, W. Huang, Q. Ben, T. Wang, B. Mi, T. Huang, S. Zhao, Y. Chen, S. Yang, P. Cao, W. Yu, Z. Ye, J. Li, J. Long, Z. Wang, H. Wang, Y. Zhao, Z. Tu, Y. Qiao, D. Lin, J. Pang, Gru- topia: Dream general robots in a city at scale (2024). arXiv:2407.10943, doi:https://arxiv.org/abs/2407.10943
-
[50]
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots
S. Nasiriany, A. Maddukuri, L. Zhang, A. Parikh, A. Lo, A. Joshi, A. Mandlekar, Y. Zhu, Robocasa: Large-scale simulation of ev- eryday tasks for generalist robots (2024). arXiv:2406.02523, doi:https://arxiv.org/abs/2406.02523. 30
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.