Recognition: 2 theorem links
· Lean TheoremKey Coverage Matters: Semi-Structured Extraction of OCR Clinical Reports
Pith reviewed 2026-05-12 03:31 UTC · model grok-4.3
The pith
Key coverage is the dominant factor for performance in extracting data from OCR clinical reports
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
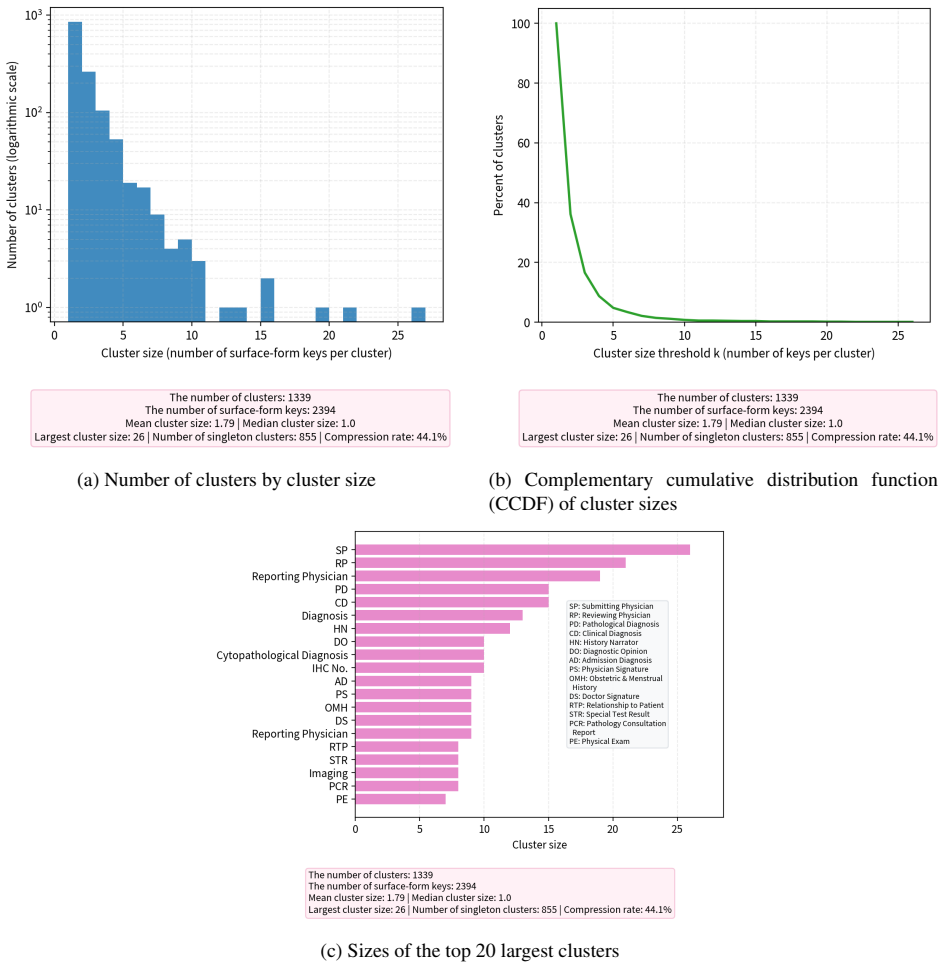
We formulate clinical report extraction as canonical key-conditioned extractive question answering over OCR text. Key coverage, defined as the completeness of the canonical key inventory, is the primary driver of end-to-end performance. Experiments demonstrate monotonic improvement in F1 with increasing coverage, achieving 0.839 exact match F1 and 0.893 boundary-tolerant F1 at Top-90 coverage using a 0.2B BERT model.
What carries the argument
Canonical key-conditioned extractive question answering, where questions are drawn from a dynamically maintained inventory of clinical keys, with key coverage quantifying inventory completeness.
Load-bearing premise
The iterative process of key mining, normalization, clustering, and human verification produces a reliable and complete canonical key inventory that captures the open key space in clinical reports.
What would settle it
Run the extraction model on a fresh collection of reports from additional hospitals while deliberately limiting the key inventory to fewer than 90 top keys and observe whether F1 scores drop below the reported levels despite other optimizations.
Figures




read the original abstract
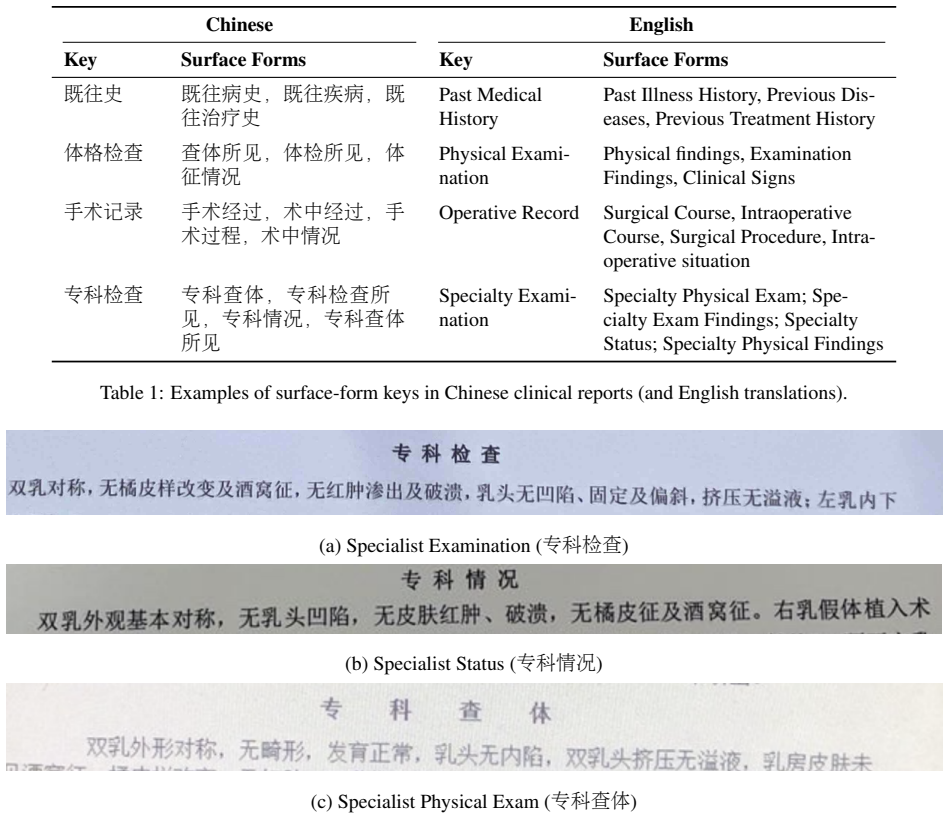
Clinical reports are often fragmented across healthcare institutions because privacy regulations and data silos limit direct information sharing. When patients seek care at a different hospital, they often carry paper or scanned reports from prior visits. This hinders EHR integration and longitudinal review, and downstream applications that depend on more complete patient records, such as patient management, follow-up care, real-world studies, and clinical-trial matching. Although OCR can digitize such reports, reliable extraction remains challenging because clinical documents are heterogeneous, OCR text is noisy, and many healthcare settings require low-cost on-premise deployment. We formulate this problem as canonical key-conditioned extractive question answering over OCR-derived clinical reports. Because the key fields are neither fixed nor known in advance, the key space is open. We maintain a canonical key inventory through iterative key mining, normalization, clustering, and lightweight human verification, and introduce key coverage as a metric to quantify inventory completeness. Using a 0.2B BERT-based model, experiments on real-world reports from more than 20 hospitals show performance improves monotonically with key coverage. The model achieves F1 scores of 0.839 and 0.893 under exact match and boundary-tolerant matching, respectively, once the Top-90 canonical keys are covered. These results show that key coverage is a dominant factor for end-to-end performance. At Top-90 coverage, our model outperforms a fine-tuned Qwen3-0.6B baseline under exact match. Although our annotated corpus is Chinese, the method relies on the language-agnostic key-value organization of semi-structured clinical reports and can be adapted to other settings given an appropriate canonical key inventory and alias mapping.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript formulates OCR-based clinical report extraction as canonical key-conditioned extractive QA over an open key space. It constructs a canonical key inventory via iterative mining, normalization, clustering, and lightweight human verification, defines key coverage as a completeness metric, and reports that a 0.2B BERT model on real-world reports from >20 hospitals exhibits monotonic F1 gains with increasing coverage, reaching 0.839 (exact match) and 0.893 (boundary-tolerant) at Top-90 coverage while outperforming a fine-tuned Qwen3-0.6B baseline under exact match. The approach is claimed to be language-agnostic and suitable for low-cost on-premise deployment.
Significance. If the empirical results can be shown to isolate key coverage from data-volume confounds, the work would offer a practical contribution to semi-structured extraction in noisy, heterogeneous clinical documents. The multi-hospital real-world corpus is a strength, and the focus on inventory completeness provides a concrete, controllable lever for improving end-to-end performance without large models. The current presentation, however, leaves the dominance claim insufficiently supported.
major comments (2)
- The central claim that key coverage is the dominant factor rests on monotonic F1 improvement with coverage (0.839/0.893 at Top-90). However, the experimental design does not hold training-set size, key-frequency distribution, or OCR noise level constant across coverage levels. Because the inventory is built iteratively from the same reports, higher coverage necessarily supplies additional annotated (key, value) pairs; no ablation or reporting of example counts per coverage threshold is described, so the observed trend may be an artifact of data volume rather than coverage per se.
- The outperformance claim versus the fine-tuned Qwen3-0.6B baseline is stated only for exact match at Top-90 coverage. No full baseline results across coverage levels, statistical significance tests, or error analysis are provided, making it impossible to assess whether the 0.2B BERT model is genuinely superior or whether differences arise from the key-conditioning formulation versus other implementation details.
minor comments (3)
- The abstract asserts monotonic improvement but supplies no information on the procedure used to vary or control key coverage (e.g., how the Top-90 subset was selected or whether coverage was measured on held-out data).
- The lightweight human verification step is mentioned without protocol details, number of annotators, or inter-annotator agreement statistics, which are needed to evaluate the reliability of the canonical key inventory.
- Dataset statistics (total reports, total keys, distribution of key frequencies) are absent from the abstract and would help readers interpret the scale of the Top-90 coverage point.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on isolating the effect of key coverage and strengthening the baseline comparisons. The comments highlight important aspects of the experimental design that we will address in revision. Below we respond point by point.
read point-by-point responses
-
Referee: The central claim that key coverage is the dominant factor rests on monotonic F1 improvement with coverage (0.839/0.893 at Top-90). However, the experimental design does not hold training-set size, key-frequency distribution, or OCR noise level constant across coverage levels. Because the inventory is built iteratively from the same reports, higher coverage necessarily supplies additional annotated (key, value) pairs; no ablation or reporting of example counts per coverage threshold is described, so the observed trend may be an artifact of data volume rather than coverage per se.
Authors: We agree that the iterative construction of the canonical inventory from the same reports creates a potential confound, as higher coverage thresholds incorporate additional keys and their corresponding annotated pairs. The manuscript does not report per-threshold example counts or include an ablation that holds training-set size fixed. To address this, we will add a table documenting the number of training examples and (key, value) pairs at each coverage level. We will also include a controlled ablation that subsamples the training data to maintain constant example counts while varying only the set of covered keys, allowing clearer isolation of coverage as the variable. These changes will be incorporated in the revised manuscript. revision: yes
-
Referee: The outperformance claim versus the fine-tuned Qwen3-0.6B baseline is stated only for exact match at Top-90 coverage. No full baseline results across coverage levels, statistical significance tests, or error analysis are provided, making it impossible to assess whether the 0.2B BERT model is genuinely superior or whether differences arise from the key-conditioning formulation versus other implementation details.
Authors: The manuscript reports the outperformance result specifically under exact match at the Top-90 coverage operating point. We acknowledge that expanding this comparison would improve interpretability. In the revision we will report the Qwen3-0.6B baseline F1 scores (both exact and boundary-tolerant) at multiple coverage levels to demonstrate trends. We will add statistical significance testing for the observed differences at Top-90 and include a concise error analysis section comparing representative failure cases between the two models. These additions will clarify the contribution of the key-conditioned formulation. revision: yes
Circularity Check
No circularity: empirical results on external hospital data
full rationale
The paper reports an empirical evaluation on real-world OCR reports from >20 hospitals. Key coverage is defined and measured as an independent metric of inventory completeness via iterative mining + verification, then used to stratify experimental conditions while holding the 0.2B BERT model fixed. Performance (F1) is observed to rise monotonically with coverage level; this is a direct experimental outcome, not a quantity derived by construction from the coverage definition itself, nor from any fitted parameter renamed as prediction, nor from self-citation chains. No equations, uniqueness theorems, or ansatzes appear in the provided text that would collapse the central claim back to its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Clinical reports exhibit semi-structured key-value organization that can be treated as key-conditioned extractive QA over OCR text
invented entities (2)
-
canonical key inventory
no independent evidence
-
key coverage metric
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We maintain a canonical key inventory through iterative key mining, normalization, clustering, and lightweight human verification, and introduce key coverage as a metric to quantify inventory completeness... performance improves monotonically with key coverage.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Using a 0.2B BERT-based model... F1 scores of 0.839 and 0.893... once the Top-90 canonical keys are covered.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A review of secure and privacy-preserving medical data sharing , author=. IEEE access , volume=. 2019 , publisher=
work page 2019
-
[2]
NPJ Digital Medicine , volume =
A scoping review of large language model based approaches for information extraction from radiology reports , author =. NPJ Digital Medicine , volume =. 2024 , doi =
work page 2024
-
[3]
An analysis of entity normalization evaluation biases in specialized domains , author =. BMC Bioinformatics , volume =. 2023 , doi =
work page 2023
-
[4]
Medical concept normalization in clinical trials with drug and disease representation learning , author =. Bioinformatics , volume =
-
[5]
Supervised Open Information Extraction , author =. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) , pages =. 2018 , address =
work page 2018
-
[6]
arXiv preprint arXiv:2105.14313 , year =
Novel Slot Detection: A Benchmark for Discovering Unknown Slot Types in the Task-Oriented Dialogue System , author =. arXiv preprint arXiv:2105.14313 , year =
-
[7]
A review of secure and privacy-preserving medical data sharing , author =. IEEE Access , volume =
-
[8]
Computers in Biology and Medicine , volume =
Natural language processing in electronic health records in relation to healthcare decision-making: a systematic review , author =. Computers in Biology and Medicine , volume =
-
[9]
Journal of Biomedical Informatics , volume =
Clinical concept extraction: a methodology review , author =. Journal of Biomedical Informatics , volume =
-
[10]
FUNSD: A dataset for form understanding in noisy scanned documents , author =. Proceedings of the 2019 International Conference on Document Analysis and Recognition Workshops (ICDARW) , volume =. 2019 , publisher =
work page 2019
-
[11]
Journal of the American Medical Informatics Association , volume =
Deep learning in clinical natural language processing: a methodical review , author =. Journal of the American Medical Informatics Association , volume =
-
[12]
The New England Journal of Medicine , volume =
Engaging patients in the health information exchange , author =. The New England Journal of Medicine , volume =
-
[13]
Journal of the American Medical Informatics Association , volume =
Evaluating the impact of OCR errors on downstream NLP tasks in clinical text , author =. Journal of the American Medical Informatics Association , volume =
-
[14]
JMIR Medical Informatics , volume=
Perspectives on challenges and opportunities for interoperability: Findings from key informant interviews with stakeholders in Ohio , author=. JMIR Medical Informatics , volume=. 2023 , publisher=
work page 2023
-
[15]
van Strien, Daniel and Beelen, Kaspar and Coll Ardanuy, Mariona and Hosseini, Kasra and McGillivray, Barbara and Colavizza, Giovanni , title =. Proceedings of the 12th International Conference on Agents and Artificial Intelligence (ICAART 2020) , editor =. 2020 , pages =
work page 2020
-
[16]
International Journal of Medical Informatics , volume =
Enhancing security in patient medical information exchange: A qualitative study , author =. International Journal of Medical Informatics , volume =. 2025 , month =
work page 2025
-
[17]
Journal of Biomedical Informatics , volume=
Improving tabular data extraction in scanned laboratory reports using deep learning models , author=. Journal of Biomedical Informatics , volume=. 2024 , publisher=
work page 2024
-
[18]
emrQA: A Large Corpus for Question Answering on Electronic Medical Records , author =. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
work page 2018
-
[19]
Information extraction from weakly structured radiological reports with natural language queries , author=. European Radiology , volume=. 2024 , publisher=
work page 2024
-
[20]
BioBERT: a pre-trained biomedical language representation model for biomedical text mining , author =. Bioinformatics , volume =. 2020 , doi =
work page 2020
-
[21]
ACM Transactions on Computing for Healthcare , year =
Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing , author =. ACM Transactions on Computing for Healthcare , year =
-
[22]
Proceedings of the 2nd Clinical Natural Language Processing Workshop (ClinicalNLP) , year =
Publicly Available Clinical BERT Embeddings , author =. Proceedings of the 2nd Clinical Natural Language Processing Workshop (ClinicalNLP) , year =
-
[23]
Self-alignment pretraining for biomedical entity representations , author=. Proceedings of the 2021 conference of the North American chapter of the association for computational linguistics: human language technologies , pages=
work page 2021
-
[24]
Unified Structure Generation for Universal Information Extraction
Lu, Yaojie and Liu, Qing and Dai, Dai and Xiao, Xinyan and Lin, Hongyu and Han, Xianpei and Sun, Le and Wu, Hua. Unified Structure Generation for Universal Information Extraction. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.395
-
[25]
Parallel Instance Query Network for Named Entity Recognition
Shen, Yongliang and Wang, Xiaobin and Tan, Zeqi and Xu, Guangwei and Xie, Pengjun and Huang, Fei and Lu, Weiming and Zhuang, Yueting. Parallel Instance Query Network for Named Entity Recognition. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.67
-
[26]
MedStruct-S: A Benchmark for Key Discovery, Key-Conditioned QA and Semi-Structured Extraction from OCR Clinical Reports , author =. 2026 , note =
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.