MLCommons Chakra: Advancing Performance Benchmarking and Co-design using Standardized Execution Traces
Pith reviewed 2026-05-20 22:13 UTC · model grok-4.3
The pith
Chakra defines an open graph-based execution trace format to standardize observation and co-design of distributed AI/ML workloads.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
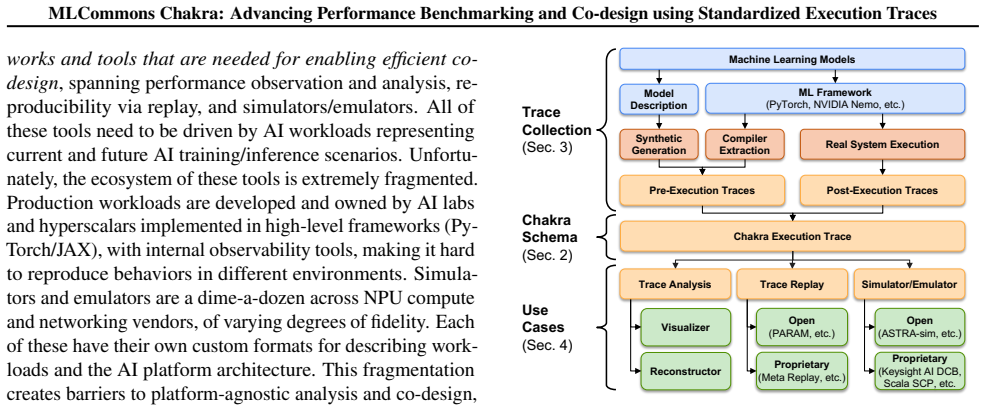
The central contribution is the Chakra execution trace, an open and interoperable graph-based representation of distributed AI/ML workloads that captures key operations such as compute, memory, and communication together with data and control dependencies, timing, and resource constraints, accompanied by tools for trace collection, analysis, generation, and use by simulators, emulators, and replay systems.
What carries the argument
Chakra execution trace (ET), a graph-based representation that encodes operations, dependencies, timing, and constraints to enable analysis and replay across independent tools.
If this is right
- Traces collected on existing AI clusters can be reused to evaluate new hardware designs without re-running the full workload.
- Different research groups can compare optimization results using identical ETs instead of custom trace formats.
- Co-design loops can alternate between trace generation from software changes and simulation on proposed hardware.
- Industry-wide benchmarking becomes more reproducible once tools adopt the common ET format.
Where Pith is reading between the lines
- If ETs become widely adopted, the cost of developing new performance tools could drop because each tool would only need to read one format rather than many proprietary ones.
- The same graph structure might later support automated search for better workload mappings or communication schedules.
- Extending the format to include power or thermal constraints could link performance traces directly to energy-efficiency studies.
Load-bearing premise
A single graph-based execution trace format can sufficiently capture the essential operations, dependencies, timing, and resource constraints of production-scale distributed ML workloads so that many different simulators and emulators can use the same traces effectively.
What would settle it
Run the same production-scale workload trace through several independent simulators and check whether they produce performance predictions that match each other and real hardware measurements within a small error margin.
Figures













read the original abstract
The fast pace of artificial intelligence~(AI) innovation demands an agile methodology for observation, reproduction and optimization of distributed machine learning~(ML) workload behavior in production AI systems and enables efficient software-hardware~(SW-HW) co-design for future systems. We present Chakra, an open and portable ecosystem for performance benchmarking and co-design. The core component of Chakra is an open and interoperable graph-based representation of distributed AI/ML workloads, called Chakra execution trace~(ET). These ETs represent key operations, such as compute, memory, and communication, data and control dependencies, timing, and resource constraints. Additionally, Chakra includes a complementary set of tools and capabilities to enable the collection, analysis, generation, and adoption of Chakra ETs by a broad range of simulators, emulators, and replay tools. We present analysis of Chakra ETs collected on production AI clusters and demonstrate value via real-world case studies. Chakra has been adopted by MLCommons and has active contributions and engagement across the industry, including but not limited to NVIDIA, AMD, Meta, Keysight, HPE, and Scala, to name a few.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Chakra, an open and portable ecosystem for performance benchmarking and co-design of distributed AI/ML workloads. Its core is the Chakra execution trace (ET), a graph-based representation capturing compute, memory, and communication operations along with data/control dependencies, timing, and resource constraints. Complementary tools support collection, analysis, generation, and adoption of ETs by simulators, emulators, and replay tools. The work includes analysis of production AI cluster traces and real-world case studies, and notes adoption by MLCommons with contributions from NVIDIA, AMD, Meta, Keysight, HPE, and Scala.
Significance. A standardized, interoperable ET format with supporting tools could meaningfully advance reproducible benchmarking and SW-HW co-design for large-scale AI systems by enabling portable workload reproduction across independent tools. The open-source nature, MLCommons adoption, and broad industry engagement are concrete strengths that increase the likelihood of impact if the representation proves sufficiently accurate. However, the current lack of quantitative reproduction fidelity metrics and validation against non-deterministic production effects limits the assessed significance.
major comments (2)
- [Abstract] Abstract: the central claim that ETs enable effective analysis, reproduction, and co-design across simulators rests on the representation of timing and resource constraints, yet the text provides no explicit mechanisms (e.g., stochastic timing distributions or feedback loops) for non-deterministic effects such as network jitter or collective algorithm selection. This is load-bearing because a purely static graph risks under-specifying contention at scale, directly affecting the asserted interoperability value.
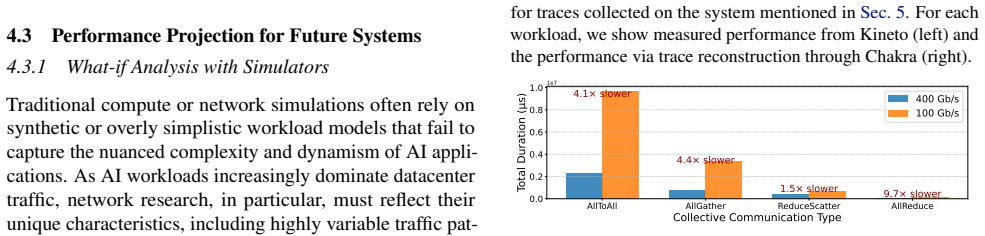
- [Analysis and case studies] The analysis of production traces and real-world case studies section: no quantitative results, error bounds, or fidelity comparisons (e.g., simulated vs. measured runtime or bandwidth utilization) are reported. Without such data the utility claim for co-design remains plausible but unverified, weakening the soundness assessment.
minor comments (1)
- The ET schema and encoding details would benefit from an explicit table or figure early in the manuscript to aid readers in understanding the graph structure and attribute fields.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. The comments on non-deterministic effects and quantitative fidelity metrics identify important opportunities to strengthen the presentation of Chakra's capabilities. We have revised the manuscript accordingly and address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that ETs enable effective analysis, reproduction, and co-design across simulators rests on the representation of timing and resource constraints, yet the text provides no explicit mechanisms (e.g., stochastic timing distributions or feedback loops) for non-deterministic effects such as network jitter or collective algorithm selection. This is load-bearing because a purely static graph risks under-specifying contention at scale, directly affecting the asserted interoperability value.
Authors: The Chakra ET is intentionally a faithful recording of an observed execution, so the included timing values and dependencies already embed the non-deterministic effects (including network jitter) that occurred during trace collection. The static graph structure is deliberate: it guarantees portability and interoperability across independent simulators, emulators, and replay tools. Different simulators are free to overlay stochastic timing distributions, feedback loops, or collective-selection models on top of the provided timings and constraints. We have revised the abstract and added a short clarifying paragraph in the ET specification section to make this extensibility explicit while preserving the core static representation. revision: partial
-
Referee: [Analysis and case studies] The analysis of production traces and real-world case studies section: no quantitative results, error bounds, or fidelity comparisons (e.g., simulated vs. measured runtime or bandwidth utilization) are reported. Without such data the utility claim for co-design remains plausible but unverified, weakening the soundness assessment.
Authors: We agree that quantitative fidelity metrics would strengthen the soundness assessment. The original manuscript prioritized qualitative analysis and evidence of industry adoption. In the revised version we have added a dedicated subsection that reports simulated-versus-measured runtime differences, bandwidth utilization comparisons, and associated error bounds for representative workloads drawn from the production traces. These results were obtained by replaying Chakra ETs through available simulators and contrasting the outputs with direct cluster measurements. revision: yes
Circularity Check
No circularity: proposal of new ET format with no derivation chain
full rationale
The paper presents Chakra as a new open graph-based execution trace representation and supporting ecosystem for ML workload benchmarking and co-design. No equations, fitted parameters, predictions, or first-principles derivations are described that could reduce to self-defined inputs or self-citation chains. The central claims rest on the definition and adoption of the ET format itself, collection from production clusters, and case studies, all of which are independent of any prior author equations or fitted quantities. This is a standardization and tooling contribution rather than a closed mathematical derivation, so no circular steps exist.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Chakra execution trace (ET)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The Chakra schema represents execution as a directed acyclic graph (DAG) where nodes denote operations and edges encode data and control dependencies... Communication is modeled explicitly as a node type alongside computation and memory.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Chakra ETs represent key operations, such as compute, memory, and communication, data and control dependencies, timing, and resource constraints.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
vLLM Github , howpublished =
-
[2]
Ultra Ethernet Consortium , howpublished =
-
[3]
Flint: Compiler Enabled Cluster-Free Design Space Exploration for Distributed ML , author=. 2026 , eprint=
work page 2026
- [5]
-
[6]
Lumos: Efficient Performance Modeling and Estimation for Large-scale LLM Training , author=. 2025 , eprint=
work page 2025
-
[7]
Jia, Zhihao and Zaharia, Matei and Aiken, Alex , booktitle=
-
[8]
Rajbhandari, Samyam and Rasley, Jeff and Ruwase, Olatunji and He, Yuxiong , booktitle=. 2020 , organization=
work page 2020
-
[9]
Ranganathan, Parthasarathy and Lee Victor , url =
-
[10]
Manpreet Singh Minhas , url =
-
[11]
Chakra: Advancing Performance Benchmarking and Co-design using Standardized Execution Traces , author=. 2023 , eprint=
work page 2023
-
[12]
Rashidi, Saeed and Sridharan, Srinivas and Srinivasan, Sudarshan and Krishna, Tushar , booktitle=. 2020 , organization=
work page 2020
-
[13]
IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS) , year=
William Won and Taekyung Heo and Saeed Rashidi and Srinivas Sridharan and Sudarshan Srinivasan and Tushar Krishna , title=. IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS) , year=
-
[14]
Rodrigues, Arun F and Hemmert, K Scott and Barrett, Brian W and Kersey, Chad and Oldfield, Ron and Weston, Marlo and Risen, Rolf and Cook, Jeanine and Rosenfeld, Paul and Cooper-Balis, Elliot and others , journal=. 2011 , publisher=
work page 2011
-
[15]
Wang, Fei and Chen, Guoyang and Zhang, Weifeng and Rompf, Tiark , booktitle=. 2019 , organization=
work page 2019
-
[16]
Wang, Xizheng and Li, Qingxu and Xu, Yichi and Lu, Gang and Li, Dan and Chen, Li and Zhou, Heyang and Zheng, Linkang and Zhang, Sen and Zhu, Yikai and Liu, Yang and Zhang, Pengcheng and Qian, Kun and He, Kunling and Gao, Jiaqi and Zhai, Ennan and Cai, Dennis and Fu, Binzhang , title =. Proceedings of the 22nd USENIX Symposium on Networked Systems Design a...
work page 2025
-
[17]
Santhanam, Keshav and Krishna, Siddharth and Tomioka, Ryota and Harris, Tim and Zaharia, Matei , journal=
-
[18]
Schaarschmidt, Michael and Grewe, Dominik and Vytiniotis, Dimitrios and Paszke, Adam and Schmid, Georg Stefan and Norman, Tamara and Molloy, James and Godwin, Jonathan and Rink, Norman Alexander and Nair, Vinod and others , journal=
-
[19]
and Lee, Jaewon and Lundell, John and Kim, Changkyu and Kejariwal, Arun and Owens, John D
Lin, Zhongyi and Feng, Louis and Ardestani, Ehsan K. and Lee, Jaewon and Lundell, John and Kim, Changkyu and Kejariwal, Arun and Owens, John D. , booktitle=. Building a Performance Model for Deep Learning Recommendation Model Training on GPUs , year=
-
[20]
DreamShard: Generalizable Embedding Table Placement for Recommender Systems , url =
Zha, Daochen and Feng, Louis and Tan, Qiaoyu and Liu, Zirui and Lai, Kwei-Herng and Bhushanam, Bhargav and Tian, Yuandong and Kejariwal, Arun and Hu, Xia , booktitle =. DreamShard: Generalizable Embedding Table Placement for Recommender Systems , url =
-
[21]
Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
Autoshard: Automated embedding table sharding for recommender systems , author=. Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[23]
Mingyu Liang and Wenyin Fu and Louis Feng and Zhongyi Lin and Pavani Panakanti and Shengbao Zheng and Srinivas Sridharan and Christina Delimitrou , year=
-
[24]
FacebookResearch , title =
-
[25]
Facebook Research , title =
- [26]
- [27]
-
[28]
Advances in neural information processing systems , volume=
Pytorch: An imperative style, high-performance deep learning library , author=. Advances in neural information processing systems , volume=
-
[29]
Scalable Synthesis of LLM Benchmarks through Symbolic Tensor Graphs , author =. Proceedings of the 53rd IEEE/ACM International Symposium on Computer Architecture (ISCA '26) , year =
-
[30]
Splitwise: Efficient generative LLM inference using phase splitting , author=. 2024 , eprint=
work page 2024
-
[32]
2026 , month = dec, howpublished =
vLLM , title =. 2026 , month = dec, howpublished =
work page 2026
-
[33]
Keysight AI Data Center Builder , year =
-
[34]
Deep Residual Learning for Image Recognition , author=. 2015 , eprint=
work page 2015
-
[35]
Deep Learning Recommendation Model for Personalization and Recommendation Systems , author=. 2019 , eprint=
work page 2019
-
[36]
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models , author=. 2024 , eprint=
work page 2024
- [37]
- [38]
- [39]
-
[40]
DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving , author=. 2024 , eprint=
work page 2024
-
[41]
Chakra Execution Traces: Benchmarking Network Performance Optimization , year =
-
[42]
2023 , month = jul, howpublished =
Chakra: Advancing Benchmarking and Co-design for Future AI Systems , author =. 2023 , month = jul, howpublished =
work page 2023
-
[43]
Understanding and Optimizing Multi-Stage AI Inference Pipelines , author=. 2026 , eprint=
work page 2026
-
[44]
The 13th International Conference on Learning Representations (ICLR) , year=
LayerDAG: A Layerwise Autoregressive Diffusion Model of Directed Acyclic Graphs for System , author=. The 13th International Conference on Learning Representations (ICLR) , year=
- [45]
- [46]
- [47]
- [48]
-
[49]
ASTRA-sim: Scalable System-Level Simulation Framework for Large-Scale Machine Learning Systems , author =
- [50]
-
[52]
Won, William and Rashidi, Saeed and Srinivasan, Sudarshan and Krishna, Tushar , booktitle=. 2024 , pages=
work page 2024
-
[53]
TACOS: Topology-Aware Collective Algorithm Synthesizer for Distributed Machine Learning , year=
Won, William and Elavazhagan, Midhilesh and Srinivasan, Sudarshan and Gupta, Swati and Krishna, Tushar , booktitle=. TACOS: Topology-Aware Collective Algorithm Synthesizer for Distributed Machine Learning , year=
-
[54]
2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA) , pages=
Enabling compute-communication overlap in distributed deep learning training platforms , author=. 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA) , pages=. 2021 , organization=
work page 2021
-
[55]
Proceedings of the 52nd Annual International Symposium on Computer Architecture , pages=
FRED: A Wafer-scale Fabric for 3D Parallel DNN Training , author=. Proceedings of the 52nd Annual International Symposium on Computer Architecture , pages=
-
[56]
The Scala Compute Platform , author =
-
[57]
Georgia Tech AI Makerspace , author =
-
[58]
Astra-sim: Scalable system-level simulation framework for large-scale machine learning systems
ASTRA-sim . Astra-sim: Scalable system-level simulation framework for large-scale machine learning systems. https://astra-sim.github.io/, 2025. Accessed: 2025-10-30
work page 2025
-
[59]
MIST: A Co-Design Framework for Heterogeneous, Multi-Stage LLM Inference
Bambhaniya, A. R., Wu, H., Subramanian, S., Srinivasan, S., Kundu, S., Yazdanbakhsh, A., Elavazhagan, M., Kumar, M., and Krishna, T. Understanding and optimizing multi-stage ai inference pipelines, 2026. URL https://arxiv.org/abs/2504.09775
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[60]
Bergeron, M. and Kumar, A. Accelerating AI Hardware NPI - Clusterless Validation of GPUs and Networking . https://youtu.be/-PRs1eVF3nY?si=sYl3P0tSsmEAJOL2, 2025. OCP Global Summit
work page 2025
-
[61]
Methodology and Observation of Congestion Control Impact on MoE Training Job Completion Time
Bortok, A. Methodology and Observation of Congestion Control Impact on MoE Training Job Completion Time . https://youtu.be/nLSDrgvu-qw?si=EJnOJ__zB35delA1, 2025. OCP Global Summit
work page 2025
-
[62]
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, ...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[63]
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
Dai, D., Deng, C., Zhao, C., Xu, R. X., Gao, H., Chen, D., Li, J., Zeng, W., Yu, X., Wu, Y., Xie, Z., Li, Y. K., Huang, P., Luo, F., Ruan, C., Sui, Z., and Liang, W. Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models, 2024. URL https://arxiv.org/abs/2401.06066
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[64]
FacebookResearch. Holistic trace analysis. https://github.com/facebookresearch/HolisticTraceAnalysis. Accessed: 2025-09-28
work page 2025
-
[65]
[PyTorch] Integrate Execution Graph Observer into PyTorch Profiler
Feng, L. [PyTorch] Integrate Execution Graph Observer into PyTorch Profiler . URL https://github.com/pytorch/pytorch/pull/75358
-
[66]
Georgia Institute of Technology . Georgia tech ai makerspace. https://coe.gatech.edu/academics/ai-for-engineering/ai-makerspace, 2026. Accessed: 2026-04-06
work page 2026
-
[67]
Characterizing the efficiency of distributed training: A power, performance, and thermal perspective
Go, S., Park, J., More, S., Wu, H., Wang, I., Jezghani, A., Krishna, T., and Mahajan, D. Characterizing the efficiency of distributed training: A power, performance, and thermal perspective. In Proceedings of the 58th IEEE/ACM International Symposium on Microarchitecture, MICRO '25, pp.\ 626–642, New York, NY, USA, 2025. Association for Computing Machiner...
-
[68]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., Yang, A., Fan, A., Goyal, A., Hartshorn, A., Yang, A., Mitra, A., Sravankumar, A., Korenev, A., Hinsvark, A., Rao, A., Zhang, A., Rodriguez, A., Gregerson, A., Spataru, A., Roziere, B., Biron, B., Tang, B., Chern, B., Caucheteux...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[69]
Deep Residual Learning for Image Recognition
He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition, 2015. URL https://arxiv.org/abs/1512.03385
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[70]
Jiang, A. Q., Sablayrolles, A., Roux, A., Mensch, A., Savary, B., Bamford, C., Chaplot, D. S., de las Casas, D., Hanna, E. B., Bressand, F., Lengyel, G., Bour, G., Lample, G., Lavaud, L. R., Saulnier, L., Lachaux, M.-A., Stock, P., Subramanian, S., Yang, S., Antoniak, S., Scao, T. L., Gervet, T., Lavril, T., Wang, T., Lacroix, T., and Sayed, W. E. Mixtral...
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [71]
-
[72]
Keysight ai data center builder
Keysight Technologies . Keysight ai data center builder. https://github.com/Keysight/kai-dc-builder/releases/download/v1.0.2/Keysight.AI.Data.Center.Builder.Solution.Brief.pdf, 2025. Solution brief. Accessed: 2026-03-31
work page 2025
-
[73]
Layerdag: A layerwise autoregressive diffusion model of directed acyclic graphs for system
Li, M., Shitole, V., Chien, E., Man, C., Wang, Z., Zhang, Y., Krishna, T., Li, P., et al. Layerdag: A layerwise autoregressive diffusion model of directed acyclic graphs for system. In The 13th International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[74]
Mystique: Enabling Accurate and Scalable Generation of Production AI Benchmarks
Liang, M., Fu, W., Feng, L., Lin, Z., Panakanti, P., Zheng, S., Sridharan, S., and Delimitrou, C. Mystique: Enabling Accurate and Scalable Generation of Production AI Benchmarks . In Proceedings of the 50th Annual International Symposium on Computer Architecture (ISCA), 2023
work page 2023
-
[75]
Lumos: Efficient performance modeling and estimation for large-scale llm training, 2025
Liang, M., Kassa, H. T., Fu, W., Coutinho, B., Feng, L., and Delimitrou, C. Lumos: Efficient performance modeling and estimation for large-scale llm training, 2025. URL https://arxiv.org/abs/2504.09307
-
[76]
symbolic\_tensor\_graph: A symbolic tensor graph generator for astra-sim
Man, C. symbolic\_tensor\_graph: A symbolic tensor graph generator for astra-sim. https://github.com/astra-sim/symbolic_tensor_graph, 2024. Accessed: 2025-10-29
work page 2024
-
[77]
Scalable synthesis of llm benchmarks through symbolic tensor graphs
Man, C., Park, J., Wu, H., Xu, H., Sridharan, S., and Krishna, T. Scalable synthesis of llm benchmarks through symbolic tensor graphs. In Proceedings of the 53rd IEEE/ACM International Symposium on Computer Architecture (ISCA '26), 2026
work page 2026
-
[78]
Chakra execution traces: Benchmarking network performance optimization
Meta . Chakra execution traces: Benchmarking network performance optimization. https://engineering.fb.com/2023/09/07/networking-traffic/chakra-execution-traces-benchmarking-network-performance-optimization/, September 2023. Accessed: 2026-03-31
work page 2023
-
[79]
Minhas, M. S. Computational Graphs in PyTorch and TensorFlow . URL https://towardsdatascience.com/computational-graphs-in-pytorch-and-tensorflow-c25cc40bdcd1. Accessed: 2025-10-01
work page 2025
-
[80]
Chakra: Advancing benchmarking and co-design for future ai systems
MLCommons . Chakra: Advancing benchmarking and co-design for future ai systems. https://mlcommons.org/2023/07/chakra-advancing-benchmarking-and-co-design-for-future-ai-systems/, July 2023. Accessed: 2026-03-31
work page 2023
-
[81]
MLPerf. MLPerf Storage Benchmark . URL https://mlcommons.org/benchmarks/storage/
-
[82]
Deep Learning Recommendation Model for Personalization and Recommendation Systems
Naumov, M., Mudigere, D., Shi, H.-J. M., Huang, J., Sundaraman, N., Park, J., Wang, X., Gupta, U., Wu, C.-J., Azzolini, A. G., Dzhulgakov, D., Mallevich, A., Cherniavskii, I., Lu, Y., Krishnamoorthi, R., Yu, A., Kondratenko, V., Pereira, S., Chen, X., Chen, W., Rao, V., Jia, B., Xiong, L., and Smelyanskiy, M. Deep learning recommendation model for persona...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[83]
NeMo . NVIDIA NeMo . https://www.nvidia.com/en-us/ai-data-science/products/nemo/. Accessed: 2025-10-01
work page 2025
-
[84]
Splitwise: Efficient generative llm inference using phase splitting, 2024
Patel, P., Choukse, E., Zhang, C., Shah, A., Íñigo Goiri, Maleki, S., and Bianchini, R. Splitwise: Efficient generative llm inference using phase splitting, 2024. URL https://arxiv.org/abs/2311.18677
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.