Recognition: no theorem link
FrameSkip: Learning from Fewer but More Informative Frames in VLA Training
Pith reviewed 2026-05-14 17:55 UTC · model grok-4.3
The pith
FrameSkip improves VLA success rates by training only on high-importance frames from demonstrations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
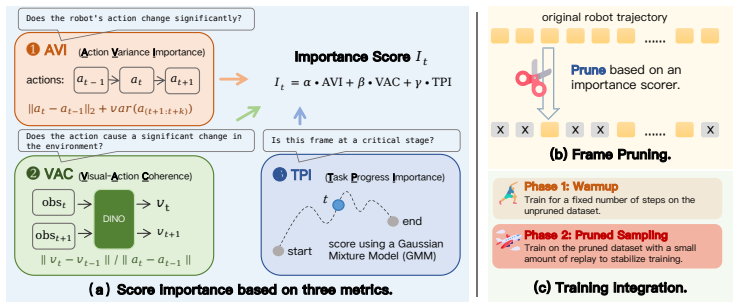
FrameSkip is a dataloader-only frame selection procedure that assigns importance scores to trajectory frames using action variation, visual-action coherence, task-progress priors, and gripper-transition preservation, then remaps the training batch distribution to favor high-scoring frames under a target retention ratio; this yields a macro-average success rate of 76.15 percent across RoboCasa-GR1, SimplerEnv, and LIBERO compared with 66.50 percent when every frame is used.
What carries the argument
FrameSkip scoring function and remapping step that prioritizes frames containing manipulation-critical events such as alignment, contact, grasping, and release.
If this is right
- Training on a compressed set of 20 percent of frames produces higher success rates than full-frame training.
- The approach leaves the VLA model architecture and optimization unchanged.
- FrameSkip outperforms both full-frame baselines and simpler selection heuristics on the tested robot benchmarks.
- Compressed views of trajectories remain sufficient for effective policy learning in manipulation tasks.
Where Pith is reading between the lines
- Reducing frame count per trajectory could shorten training time or allow more trajectories to be processed in the same compute budget.
- Similar importance-based sampling might benefit other sequential decision domains that suffer from long idle periods.
- The scoring signals could be tuned per task if the current fixed combination proves suboptimal on certain manipulation types.
Load-bearing premise
The four scoring signals identify the most important manipulation frames without missing key transitions or introducing bias on new tasks.
What would settle it
Running the same VLA training on a new set of tasks where the FrameSkip-selected frames produce lower success rates than training on all frames would show the selection is not reliably superior.
Figures


read the original abstract
Vision-Language-Action (VLA) policies are commonly trained from dense robot demonstration trajectories, often collected through teleoperation, by sampling every recorded frame as if it provided equally useful supervision. We argue that this convention creates a temporal supervision imbalance: long low-change segments dominate the training stream, while manipulation-critical transitions such as alignment, contact, grasping, and release appear only sparsely. We introduce FrameSkip, a data-layer frame selection framework that scores trajectory frames using action variation, visual-action coherence, task-progress priors, and gripper-transition preservation, then remaps training samples toward high-importance frames under a target retention ratio. Because FrameSkip operates only in the dataloader, it leaves the VLA architecture, action head, training objective, and inference procedure unchanged. Across RoboCasa-GR1, SimplerEnv, and LIBERO, FrameSkip improves the success-retention trade-off over full-frame training and simpler frame selection variants, achieving a macro-average success rate of 76.15% across the three benchmarks compared with 66.50% for full-frame training while using a compressed trajectory view that retains 20% of unique frames in the main setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FrameSkip, a dataloader-only modification for VLA training that scores trajectory frames via four heuristics (action variation, visual-action coherence, task-progress priors, gripper-transition preservation) and remaps samples to retain ~20% of frames focused on high-importance transitions. It reports improved success-retention trade-offs on RoboCasa-GR1, SimplerEnv, and LIBERO, with a macro-average success rate of 76.15% versus 66.50% for full-frame training, while leaving the VLA architecture, loss, and inference unchanged.
Significance. If the gains are robust, the method offers a lightweight, architecture-agnostic way to mitigate temporal supervision imbalance in dense robot demonstrations, potentially lowering data and compute costs for VLA policies. The dataloader-only design is a practical strength.
major comments (4)
- [Abstract and Experiments] Abstract and §4 (Experiments): the macro-average success rates (76.15% vs. 66.50%) are reported without error bars, number of random seeds, or statistical tests, leaving the central empirical claim only partially supported.
- [Method] §3 (Method): no ablation is presented on the four scoring signals, their relative weights, or the choice of the 20% retention ratio; it is therefore unclear whether the reported gains depend on a specific weighting that may not generalize.
- [Method and Experiments] §3.2 and §4: the task-progress priors are described as derived from demonstration statistics, yet no analysis or cross-validation is given to show that the composite score does not systematically under-weight visually subtle or task-novel transitions on the held-out benchmarks.
- [Experiments] §4: the comparison to “simpler frame selection variants” lacks detail on how those baselines were implemented and whether they used the same retention ratio and scoring budget, weakening the claim that FrameSkip’s specific combination is responsible for the improvement.
minor comments (1)
- [Abstract and Method] The abstract and §3 could explicitly state the exact numerical weights used for the four signals and the procedure (if any) for selecting the retention ratio.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps strengthen the empirical rigor and clarity of our work. We address each major comment below and will incorporate revisions in the updated manuscript.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and §4 (Experiments): the macro-average success rates (76.15% vs. 66.50%) are reported without error bars, number of random seeds, or statistical tests, leaving the central empirical claim only partially supported.
Authors: We acknowledge this limitation in the current presentation. In the revised manuscript, we will rerun all experiments using at least three random seeds, report means with standard deviations as error bars, and include statistical tests (e.g., paired t-tests) to support the macro-average improvements. These details will be added to §4 and referenced in the abstract. revision: yes
-
Referee: [Method] §3 (Method): no ablation is presented on the four scoring signals, their relative weights, or the choice of the 20% retention ratio; it is therefore unclear whether the reported gains depend on a specific weighting that may not generalize.
Authors: We agree that systematic ablations are needed to demonstrate robustness. We will add a dedicated ablation subsection in §3 examining the contribution of each individual scoring signal, alternative weightings, and retention ratios ranging from 10% to 50%. This will clarify generalization and show that gains are not tied to one specific configuration. revision: yes
-
Referee: [Method and Experiments] §3.2 and §4: the task-progress priors are described as derived from demonstration statistics, yet no analysis or cross-validation is given to show that the composite score does not systematically under-weight visually subtle or task-novel transitions on the held-out benchmarks.
Authors: This concern about potential bias in the composite score is valid. In the revision, we will expand §3.2 with qualitative frame-selection examples and quantitative analysis on held-out tasks, including metrics for subtle transitions. We will also add cross-validation results across benchmarks to verify that the score does not systematically under-weight such cases. revision: yes
-
Referee: [Experiments] §4: the comparison to “simpler frame selection variants” lacks detail on how those baselines were implemented and whether they used the same retention ratio and scoring budget, weakening the claim that FrameSkip’s specific combination is responsible for the improvement.
Authors: We will revise §4 to provide full implementation details for the simpler baselines, explicitly confirming that all variants use the identical 20% retention ratio and equivalent scoring budget. This will better isolate the contribution of FrameSkip’s combined heuristics. revision: yes
Circularity Check
No circularity: FrameSkip is an independent heuristic dataloader modification evaluated on external benchmarks
full rationale
The paper defines FrameSkip via four explicit scoring signals (action variation, visual-action coherence, task-progress priors, gripper-transition preservation) applied in the dataloader to remap samples under a fixed retention ratio. Performance is measured by direct empirical comparison of success rates on three external benchmarks (RoboCasa-GR1, SimplerEnv, LIBERO) against full-frame baselines and variants. No equations, fitted parameters, or self-citations are shown that reduce the reported macro-average success (76.15% vs 66.50%) to a construction tautology or input-derived quantity. The derivation chain is self-contained and externally falsifiable.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164. Xinyi Chen, Yilun Chen, Yanwei Fu, Ning Gao, Ji- aya Jia, Weiyang Jin, Hao Li, Yao Mu, Jiang- miao Pang, Yu Qiao, Yang Tian, Bin Wang, Bolun Wang, Fangjing Wang, Hanqing Wang, Tai Wang, Ziqin Wang, Xueyuan Wei, Chao Wu, and 10 oth- ers
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
InternVLA-M1: A Spatially Guided Vision-Language-Action Framework for Generalist Robot Policy
Internvla-m1: A spatially guided vision- language-action framework for generalist robot pol- icy.Preprint, arXiv:2510.13778. Cheng Chi, Siyuan Feng, Yilun Du, Zhenjia Xu, Eric Cousineau, Benjamin Burchfiel, and Shuran Song. 8
work page internal anchor Pith review arXiv
-
[3]
Robot data curation with mutual information estimators.arXiv preprint arXiv:2502.08623, 2025
Robot data curation with mutual infor- mation estimators.Preprint, arXiv:2502.08623. Chi-Pin Huang, Yueh-Hua Wu, Min-Hung Chen, Yu-Chiang Frank Wang, and Fu-En Yang
-
[4]
Thinkact: Vision- language-action reasoning via reinforced visual latent planning, 2025
Thinkact: Vision-language-action reasoning via reinforced visual latent planning.Preprint, arXiv:2507.16815. Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Ti...
-
[5]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
π0.5: a vision-language-action model with open-world generalization.Preprint, arXiv:2504.16054. Moo Jin Kim, Chelsea Finn, and Percy Liang
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Fine-tuning vision-language-action models: Optimiz- ing speed and success.Preprint, arXiv:2502.19645. Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, Pannag R Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Openvla: An open-source vision-language-action model. InAnnual Conference on Robot Learning (CoRL). Qixiu Li, Yaobo Liang, Zeyu Wang, Lin Luo, Xi Chen, Mozheng Liao, Fangyun Wei, Yu Deng, Sicheng Xu, Yizhong Zhang, Xiaofan Wang, Bei Liu, Jianlong Fu, Jianmin Bao, Dong Chen, Yuanchun Shi, Jiao- long Yang, and Baining Guo. 2024a. Cogact: A foundational visi...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
LangForce: Bayesian Decomposition of Vision Language Action Models via Latent Action Queries
Langforce: Bayesian decomposition of vision language action models via latent action queries.Preprint, arXiv:2601.15197. Xiaopeng Lin, Shijie Lian, Bin Yu, Ruoqi Yang, Changti Wu, Yuzhuo Miao, Yurun Jin, Yukun Shi, Cong Huang, Bojun Cheng, and Kai Chen
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone
Phys- brain: Human egocentric data as a bridge from vision language models to physical intelligence.Preprint, arXiv:2512.16793. Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone
-
[10]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
Libero: Benchmarking knowledge transfer for lifelong robot learning.arXiv preprint arXiv:2306.03310. Qi Lv, Weijie Kong, Hao Li, Jia Zeng, Zherui Qiu, Delin Qu, Haoming Song, Qizhi Chen, Xiang Deng, and Jiangmiao Pang
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
F1: A vision-language- action model bridging understanding and generation to actions.Preprint, arXiv:2509.06951. Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Man- dlekar, and Yuke Zhu
-
[12]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Robocasa: Large-scale simulation of everyday tasks for generalist robots. In Robotics: Science and Systems. NVIDIA, :, Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi "Jim" Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, and 24...
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Fast: Efficient ac- tion tokenization for vision-language-action models. Preprint, arXiv:2501.09747. 9 Fanqi Pu, Lei Jiang, and Wenming Yang
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Tgm-vla: Task-guided mixup for sampling-efficient and robust robotic manipulation.Preprint, arXiv:2603.00615. Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, and Xuelong Li
-
[15]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Spatialvla: Exploring spatial representations for visual-language- action model.Preprint, arXiv:2501.15830. Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He
work page internal anchor Pith review Pith/arXiv arXiv
- [16]
-
[17]
Vla-jepa: Enhanc- ing vision-language-action model with latent world model.Preprint, arXiv:2602.10098. GEAR Team, Allison Azzolini, Johan Bjorck, Valts Blukis, Fernando Castañeda, Rahul Chand, and 1 oth- ers
-
[18]
Octo: An Open-Source Generalist Robot Policy
Octo: An open-source generalist robot policy.Preprint, arXiv:2405.12213. Yandan Yang, Shuang Zeng, Tong Lin, Xinyuan Chang, Dekang Qi, Junjin Xiao, Haoyun Liu, Ronghan Chen, Yuzhi Chen, Dongjie Huo, Feng Xiong, Xing Wei, Zhiheng Ma, and Mu Xu
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
ABot-M0: VLA Foundation Model for Robotic Manipulation with Action Manifold Learning
Abot-m0: Vla foun- dation model for robotic manipulation with action manifold learning.Preprint, arXiv:2602.11236. Bin Yu, Shijie Lian, Xiaopeng Lin, Yuliang Wei, Zhaolong Shen, Changti Wu, Yuzhuo Miao, Xin- ming Wang, Bailing Wang, Cong Huang, and Kai Chen
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Yu Zhang, Yuqi Xie, Huihan Liu, Rutav Shah, Michael Wan, Linxi Fan, and Yuke Zhu
Twinbrainvla: Unleashing the potential of generalist vlms for embodied tasks via asymmetric mixture-of-transformers.Preprint, arXiv:2601.14133. Yu Zhang, Yuqi Xie, Huihan Liu, Rutav Shah, Michael Wan, Linxi Fan, and Yuke Zhu
-
[21]
CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models, March 2025
Cot-vla: Visual chain-of-thought rea- soning for vision-language-action models.Preprint, arXiv:2503.22020. Zhongyi Zhou, Yichen Zhu, Minjie Zhu, Junjie Wen, Ning Liu, Zhiyuan Xu, Weibin Meng, Ran Cheng, Yaxin Peng, Chaomin Shen, and Feifei Feng
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.