XDomainBench: Diagnosing Reasoning Collapse in High-Dimensional Scientific Knowledge Composition
Pith reviewed 2026-06-30 20:52 UTC · model grok-4.3
The pith
LLMs exhibit systematic reasoning collapse in interactive scientific knowledge composition as the order of domain mixing increases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
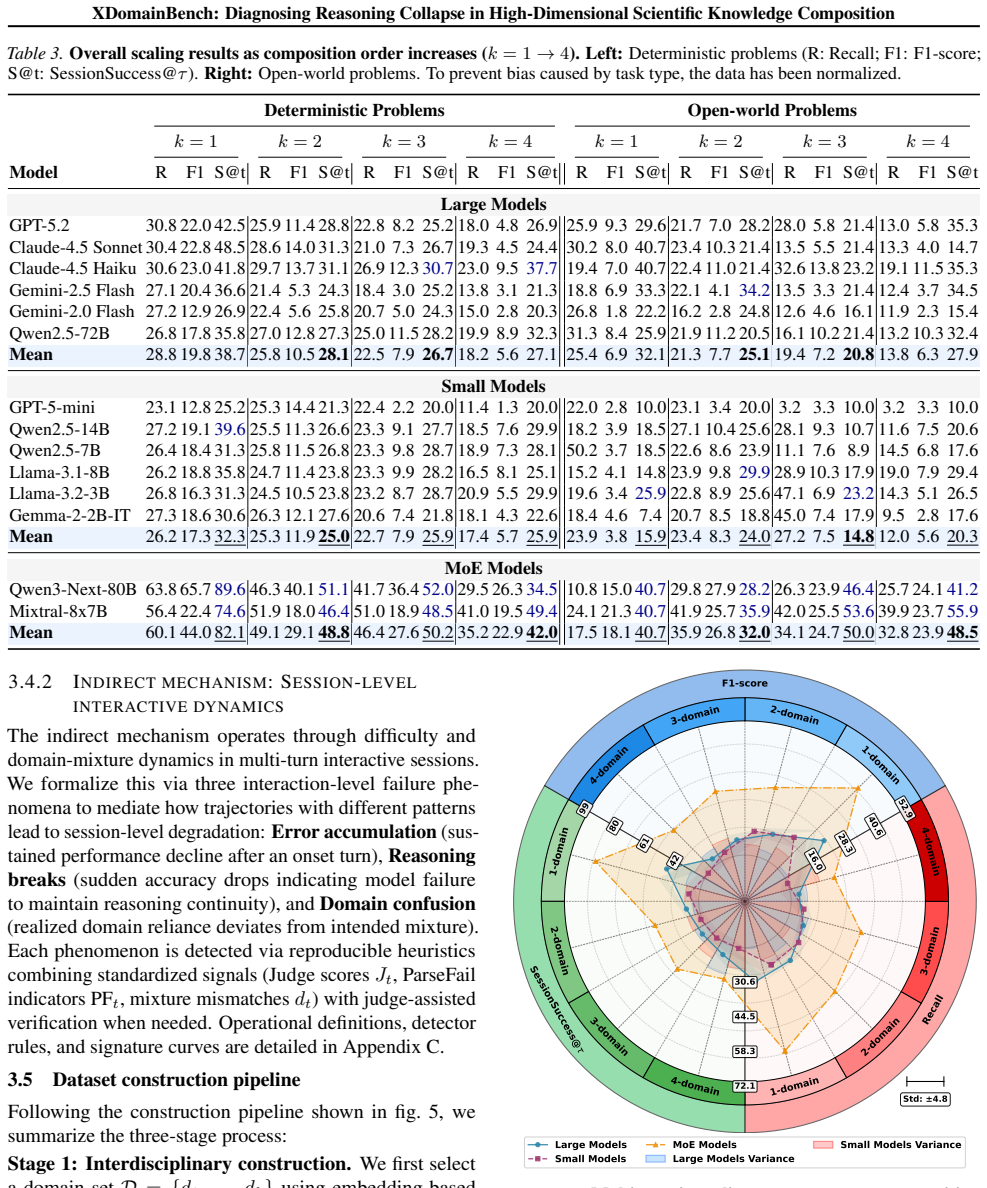
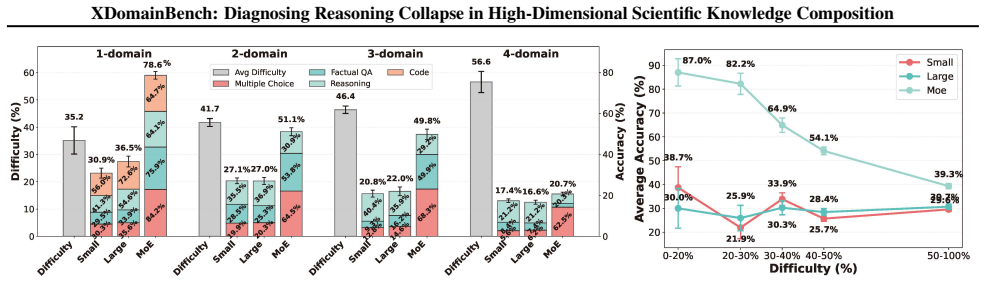
Large-scale evaluation of LLMs reveals a systematic reasoning collapse as composition order increases, stemming from two root causes: (i) direct difficulty increases induced by domain composition, and (ii) indirect interaction-amplified failures where trajectory patterns trigger error accumulation, reasoning breaks, and domain confusion, ultimately leading to session collapse.
What carries the argument
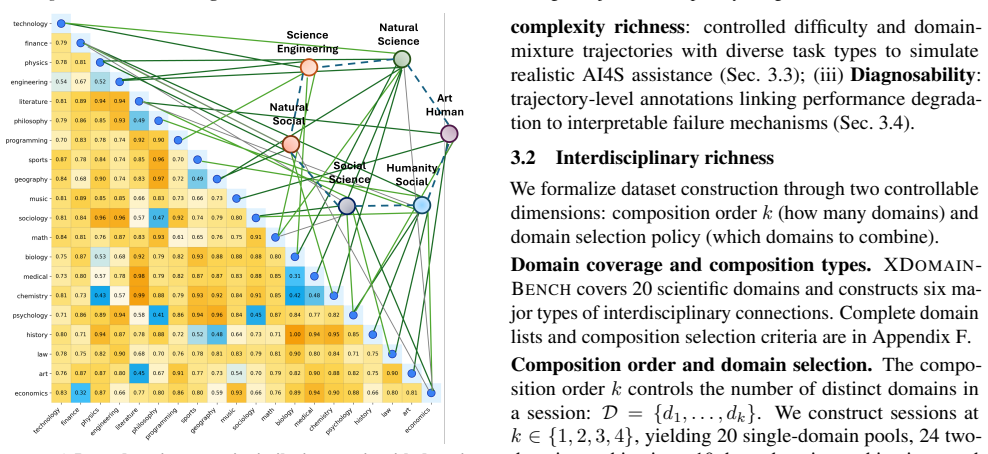
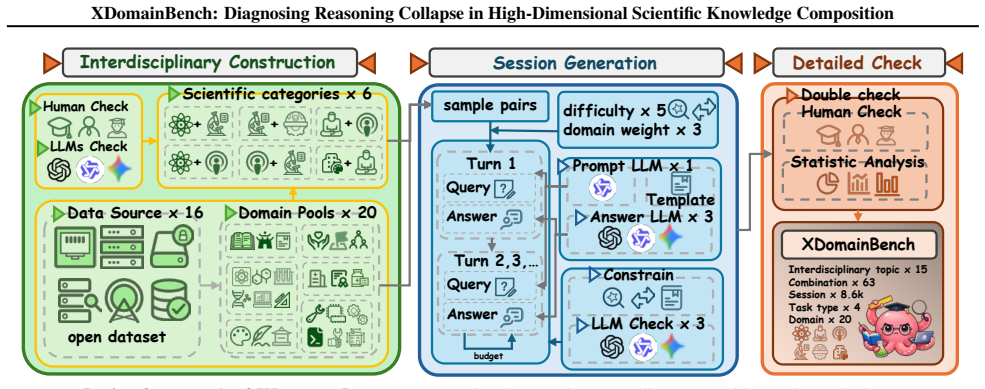
XDomainBench, which formalizes composition order and mixture structure to create 8,598 interactive sessions across 20 domains using 8 realistic trajectory patterns that simulate difficulty and domain-mixture dynamics.
If this is right
- Performance degrades steadily from single-discipline to interdisciplinary tasks as composition order grows.
- Trajectory patterns can trigger error accumulation that leads to reasoning breaks and domain confusion.
- Session collapse becomes the dominant failure mode once multiple domains interact over several turns.
- The benchmark enables controlled stress-testing of models from restricted single-turn scenarios to full interactive workflows.
Where Pith is reading between the lines
- Models may need explicit mechanisms for detecting and recovering from domain confusion during long sessions rather than relying on scale alone.
- Hybrid systems that combine LLMs with external verification tools could reduce the indirect failure mode observed here.
- Extending the benchmark to include live human-AI scientific workflows would test whether the identified collapse generalizes beyond the simulated patterns.
Load-bearing premise
The 8 trajectory patterns and the formalization of composition order and mixture structure are assumed to faithfully simulate real-world interactive scientific workflows.
What would settle it
Running the same LLMs on actual recorded scientific collaboration sessions with high composition order that fall outside the eight defined trajectory patterns and checking whether the same collapse still occurs.
Figures







read the original abstract
Large Language Models (LLMs) are increasingly deployed for knowledge synthesis, yet their capacity for compositional generalization in scientific knowledge remains under-characterized. Existing benchmarks primarily focus on single-turn restricted scenarios, failing to capture the capability boundaries exposed by real-world interactive scientific workflows. To address this, we introduce XDomainBench, a diagnostic benchmark for interactive interdisciplinary scientific reasoning. We formalize the composition order and mixture structure to enable systematic stress-testing from single-discipline to inter-disciplinary, comprising 8,598 interactive sessions across 20 domains and 4 task categories, with 8 realistic trajectory patterns covering difficulty and domain-mixture dynamics, simulating real AI4S scenarios. Large-scale evaluation of LLMs reveals a systematic reasoning collapse as composition order increases, stemming from two root causes: (i) direct difficulty increases induced by domain composition, and (ii) indirect interaction-amplified failures where trajectory patterns trigger error accumulation, reasoning breaks, and domain confusion, ultimately leading to session collapse.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces XDomainBench, a diagnostic benchmark for interactive interdisciplinary scientific reasoning comprising 8,598 sessions across 20 domains and 4 task categories, formalized via composition order, mixture structure, and 8 realistic trajectory patterns. Large-scale LLM evaluation is reported to reveal systematic reasoning collapse with increasing composition order, attributed to (i) direct difficulty increases from domain composition and (ii) indirect interaction-amplified failures causing error accumulation, reasoning breaks, domain confusion, and session collapse.
Significance. If the benchmark and trajectory patterns accurately capture real AI4S workflows, the work would usefully diagnose LLM limitations in high-dimensional compositional scientific reasoning and provide a scalable testbed for future models. The scale (8,598 sessions) and explicit separation of direct vs. indirect failure modes are strengths that could inform targeted improvements in interactive settings.
major comments (3)
- [Abstract and §3 (Benchmark Construction)] The generalization that observed collapse reflects intrinsic LLM limitations in real-world interactive scientific workflows rests entirely on the untested premise that the 8 trajectory patterns, composition order, and mixture structure faithfully reproduce actual session dynamics, error accumulation, and domain confusion; no external validation (expert ratings, real query logs, or comparison to published AI4S traces) is described.
- [Abstract] The abstract asserts the existence of collapse and two root causes but supplies no quantitative metrics, controls, or statistical tests; without these, the causal attribution to direct difficulty vs. interaction-amplified failures cannot be evaluated for robustness.
- [§4 (Evaluation Results)] Table or figure reporting per-trajectory collapse rates (if present) must be checked against the claim of systematic increase with composition order; any lack of ablation isolating the 8 patterns from other factors would undermine the indirect-failure mechanism.
minor comments (2)
- [§2] Clarify the exact definition and operationalization of 'composition order' and 'mixture structure' with a small worked example early in the methods.
- [§3] Ensure all 20 domains and 4 task categories are listed with brief descriptions to allow reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point-by-point below, providing clarifications drawn directly from the manuscript and indicating revisions where they improve rigor or transparency.
read point-by-point responses
-
Referee: [Abstract and §3 (Benchmark Construction)] The generalization that observed collapse reflects intrinsic LLM limitations in real-world interactive scientific workflows rests entirely on the untested premise that the 8 trajectory patterns, composition order, and mixture structure faithfully reproduce actual session dynamics, error accumulation, and domain confusion; no external validation (expert ratings, real query logs, or comparison to published AI4S traces) is described.
Authors: We agree that the manuscript does not report external validation such as expert ratings, real query logs, or direct comparisons to published AI4S traces. The 8 trajectory patterns were constructed from a synthesis of documented AI4S interaction motifs in the literature to span realistic difficulty gradients and domain-mixture structures, with composition order and mixture structure formalized to enable controlled stress-testing. To address the concern, we will revise §3 to expand the rationale for pattern selection with explicit citations to supporting AI4S workflow studies and add a dedicated limitations paragraph acknowledging the absence of direct empirical validation against live traces. This will better bound the scope of the generalization claims. revision: yes
-
Referee: [Abstract] The abstract asserts the existence of collapse and two root causes but supplies no quantitative metrics, controls, or statistical tests; without these, the causal attribution to direct difficulty vs. interaction-amplified failures cannot be evaluated for robustness.
Authors: The abstract is intentionally concise and does not contain the quantitative details, which are instead reported in full in §4 (including per-order collapse rates, error accumulation curves, and statistical comparisons separating direct difficulty from interaction-amplified effects). We will revise the abstract to incorporate a small number of key quantitative indicators (e.g., overall collapse rate increase and significance of the two failure modes) while preserving its brevity, thereby making the causal attribution more immediately evaluable from the abstract alone. revision: yes
-
Referee: [§4 (Evaluation Results)] Table or figure reporting per-trajectory collapse rates (if present) must be checked against the claim of systematic increase with composition order; any lack of ablation isolating the 8 patterns from other factors would undermine the indirect-failure mechanism.
Authors: §4 already includes per-trajectory breakdowns (Figure 4 and Table 3) that show collapse rates increasing systematically with composition order for each of the 8 patterns. The experimental design uses controlled variation of trajectory patterns while holding other factors fixed, thereby isolating their contribution to indirect failures. Should the specific tables or figures not meet the referee's expectations for clarity, we will add an explicit ablation subsection in the revision that further disentangles pattern-specific effects from domain count and task category alone. revision: partial
Circularity Check
No circularity: benchmark design and empirical results remain independent
full rationale
The paper constructs XDomainBench by defining composition order, mixture structure, and 8 trajectory patterns, then performs LLM evaluations that report observed collapse; these steps do not reduce to each other by definition, fitting, or self-citation. No equations, parameter estimation, or load-bearing self-references appear in the provided text, so the reported outcomes are not forced by the benchmark inputs themselves.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Accessed 2026-01-04. Bai, J., Bai, S., Chu, Y ., Cui, Z., Dang, K., Deng, X., Fan, Y ., Ge, W., Han, Y ., Huang, F., Hui, B., Ji, L., Li, M., Lin, J., Lin, R., Liu, D., Liu, G., Lu, C., Lu, K., Ma, J., Men, R., Ren, X., Ren, X., Tan, C., Tan, S., Tu, J., Wang, P., Wang, S., Wang, W., Wu, S., Xu, B., Xu, J., Yang, A., Yang, H., Yang, J., Yang, S., Yao, Y ....
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.acl-long.172 2026
-
[2]
Training Verifiers to Solve Math Word Problems
doi: 10.48550/arXiv.2110.14168. Deng, C., Zhao, Y ., Tang, X., Gerstein, M., and Co- han, A. Investigating data contamination in modern benchmarks for large language models. InProceed- ings of the 2024 Conference of the North American Chapter of the Association for Computational Linguis- tics: Human Language Technologies (Volume 1: Long Papers), pp. 8706–...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2110.14168 2024
-
[3]
doi: 10.18653/v1/2024.naacl-long.482
Association for Computational Linguistics. doi: 10.18653/v1/2024.naacl-long.482. Gao, L., Tow, J., Abbasi, B., Biderman, S., Black, S., DiPofi, A., Foster, C., Golding, L., Hsu, J., Le Noac’h, A., Li, H., McDonell, K., Muennighoff, N., Ociepa, C., Phang, J., Reynolds, L., Schoelkopf, H., Skowron, A., Sutawika, L., Tang, E., Thite, A., Wang, B., Wang, K., ...
-
[4]
URLhttps://zenodo.org/records/10256836. Gemma Team. Gemma 2: Improving open language models at a practical size, 2024. Gong, Z., Hou, Y ., Wu, F., Wang, C., Zhang, F., Wu, T., Hao, Y ., Zhang, J., Duan, Y ., Wang, T., Huang, F., Yuen, C., and Lim, W. Y . B. Subspacepath pruner: Inference- time pruning via probe-based representation–parameter coupling. InF...
-
[5]
RACE : Large-scale R e A ding Comprehension Dataset From Examinations
Association for Computational Linguistics, 2017. doi: 10.18653/v1/D17-1082. Lake, B. and Baroni, M. Generalization without systematic- ity: On the compositional skills of sequence-to-sequence recurrent networks. InProceedings of the 35th Inter- national Conference on Machine Learning (ICML), pp. 4487–4499, 2018. Laskar, M. T. R., Alqahtani, S., Bari, M. S...
-
[6]
Holistic Evaluation of Language Models
Association for Computational Linguistics. doi: 10.18653/v1/2024.emnlp-main.764. Liang, P., Bommasani, R., Lee, T., Tsipras, D., Soylu, D., Yasunaga, M., Zhang, Y ., Narayanan, D., Wu, Y ., Kumar, A., et al. Holistic evaluation of language models.arXiv preprint arXiv:2211.09110, 2022. Lin, J. Divergence measures based on the shannon entropy. IEEE Transact...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.emnlp-main.764 2024
-
[7]
doi: 10.1162/tacl\_a\_00638. Liu, X., Yu, H., Zhang, H., Xu, Y ., Lei, X., Lai, H., Gu, Y ., Ding, H., Men, K., Yang, K., Zhang, S., Deng, X., Zeng, A., Du, Z., Zhang, C., Shen, S., Zhang, T., Su, Y ., Sun, H., Huang, M., Dong, Y ., and Tang, J. Agentbench: Evaluat- ing LLMs as agents.arXiv preprint arXiv:2308.03688,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1162/tacl
-
[8]
AgentBench: Evaluating LLMs as Agents
doi: 10.48550/ARXIV .2308.03688. Lu, P., Mishra, S., Xia, T., Qiu, L., Chang, K.-W., Zhu, S.-C., Tafjord, O., Clark, P., and Kalyan, A. Learn to explain: Multimodal reasoning via thought chains for science question answering.Advances in Neural Infor- mation Processing Systems, 35:2507–2521, 2022. Meta AI. Introducing llama 3.1: Our most capable models to ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2022
-
[9]
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Accessed 2026-01-04. Reimers, N. and Gurevych, I. Sentence-bert: Sentence em- beddings using siamese bert-networks. InProceedings of the 2019 Conference on Empirical Methods in Natu- ral Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP- IJCNLP), pp. 3982–3992. Association for Computational Linguistics, 2...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/d19-1410 2026
-
[10]
Instruction-Following Evaluation for Large Language Models
Association for Computational Linguistics. doi: 10.18653/v1/2024.emnlp-main.498. Zheng, L., Chiang, W.-L., Sheng, Y ., Zhuang, S., Wu, Z., Zhuang, Y ., Lin, Z., Li, Z., Li, D., Xing, E., et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Ad- vances in neural information processing systems, 36: 46595–46623, 2023. Zheng, T., Deng, Z., Tsang, H. T...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.emnlp-main.498 2024
-
[11]
, T , generate (xt, yt) conditioned on prior turns, the desired task type τt, and the target difficulty control for turnt
Turn expansion.For t= 2, . . . , T , generate (xt, yt) conditioned on prior turns, the desired task type τt, and the target difficulty control for turnt
-
[12]
Only accepted turns are appended to the history
Step-wise QC.After each generated turn, apply theformat gate,topic-coherence gate(Section D.5), anddifficulty- consistency gate. Only accepted turns are appended to the history. This strict step-wise gating prevents error accumulation during construction and ensures that the resulting session remains evaluable and coherent before advancing to later turns....
-
[13]
Re-judge (same rubric, stricter schema).Re-run the same judging rubric but enforce a shorter, schema-only output (no free-form rationale), to reduce parsing/verbosity variance
-
[14]
Regenerate (preferred).If the case is near acceptance boundaries or exhibits semantic misalignment, regenerate the turn/session and re-apply the standard validators (Algorithm 2)
-
[15]
scenario_id
Manual audit escalation (rare).Escalate only when repeated regeneration fails and the slice is still quota-critical, or when a systematic issue is suspected (see below). E.5 Audit sampling Human audit procedure.We conducted a comprehensive human audit of the dataset to ensure quality and identify systematic issues. Six PhD students from diverse academic b...
2070
-
[16]
**Correctness**: Is the answer correct? Is it consistent with or semantically equivalent to the expected answer?
-
[17]
**Completeness**: Is the answer complete? Does it answer all parts of the question?
-
[18]
**Reasonableness**: Is the answer reasonable? Does it conform to common sense and domain knowledge? Please provide a score between 0.0 and 1.0, where: - 1.0: Answer is completely correct, complete, and reasonable - 0.7-0.9: Answer is mostly correct but may have minor incompleteness or inaccuracy - 0.4-0.6: Answer is partially correct but has obvious error...
-
[19]
You must return ONLY JSON format, no other text, explanations, or comments
-
[20]
Do NOT use markdown code block markers (do NOT use```json or```)
-
[21]
Return the JSON object directly, starting with { and ending with }
-
[22]
score": 0.0,
Scores must be floating-point numbers between 0.0 and 1.0 **Output format (MUST STRICTLY FOLLOW)**: { "score": 0.0, "correctness": 0.0, "completeness": 0.0, "reasonableness": 0.0 } Remember: Return ONLY JSON, no other content! 32 XDomainBench: Diagnosing Reasoning Collapse in High-Dimensional Scientific Knowledge Composition Ensemble aggregation.We run th...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.