WinQ: Accelerating Quantization-Aware Training of Language Models Around Saddle Points
Pith reviewed 2026-05-20 14:49 UTC · model grok-4.3
The pith
Weights in low-bit quantization-aware training settle into flat saddle regions with shrinking Hessian eigenvalues, and periodic interpolation resets plus noise gradients accelerate convergence by up to four times.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
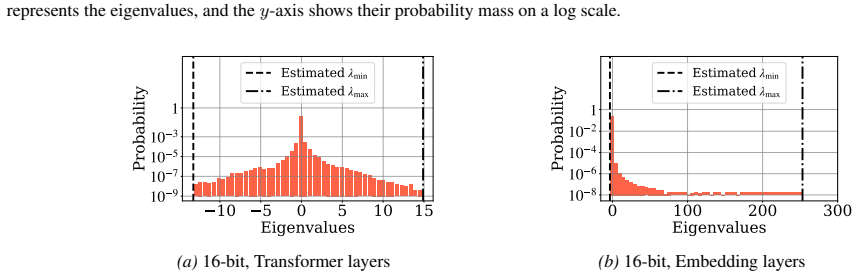
The central claim is that the bottleneck in sub-four-bit QAT arises because weights converge to flat regions around saddle points where the Hessian spectrum shows an increasing fraction of eigenvalues near zero whose magnitudes decrease further at lower bit widths, and that WinQ restores faster progress by periodically resetting weights to their linear interpolation with the quantized versions while computing gradients on noise-injected weights to enlarge those eigenvalues and improve convergence without offsetting instabilities.
What carries the argument
The WinQ procedure of periodic linear-interpolation resets between full-precision and quantized weights combined with noise-injected gradient computation to regularize the Hessian spectrum.
If this is right
- QAT training time can be reduced by a factor of up to four while reaching comparable or better final accuracy.
- Sub-4-bit quantized models achieve up to 8.8 percent higher performance for the same total training cost.
- The acceleration and gains hold consistently across sixteen combinations of language models, quantization methods, and bit widths.
- The method directly targets the observed flattening of the loss landscape that is more pronounced at lower bit widths.
Where Pith is reading between the lines
- The same saddle-point flattening mechanism could appear in other precision-reduction techniques such as knowledge distillation or structured pruning.
- Periodic interpolation resets might serve as a lightweight regularizer in full-precision training when flat regions slow progress.
- Noise injection on gradients may interact with existing low-precision regularizers in ways that further stabilize training at very low bits.
Load-bearing premise
The observed slow convergence and performance plateau below four bits are caused by weights settling into flat saddle-point regions whose Hessian eigenvalues shrink in magnitude, and that the proposed periodic interpolation resets plus noise-injected gradients will reliably enlarge those eigenvalues without introducing offsetting instabilities or overfitting.
What would settle it
Tracking the Hessian eigenvalue distribution throughout standard QAT runs to confirm whether eigenvalues increasingly concentrate near zero with shrinking magnitudes at lower bits, then checking whether WinQ interventions produce measurable increases in those magnitudes that coincide with the reported speed-ups and accuracy gains.
Figures








read the original abstract
Quantization-aware training (QAT) is widely adopted to quantize language models by training full-precision weights using gradients from the quantized model. The main bottleneck is its slow convergence and early performance plateau, particularly below 4-bit-widths. While this problem has been observed in prior work, its precise cause remains unclear. In this paper, we analyze the convergence of QAT by estimating the spectrum of the loss-surface Hessians. We find that the weights converge to flat regions around saddle points, where a large fraction of the Hessian eigenvalues are both positive and negative. During training, an increasing fraction of Hessian eigenvalues concentrates around zero, whose magnitude decreases. At lower bit-widths, the magnitude of eigenvalues in the Hessian spectrum is significantly smaller. To mitigate these issues, we propose an algorithm called WinQ to accelerate QAT, which involves: (1) periodically resetting weights to the linear interpolation of full-precision and quantized weights, reducing the distance to the quantization grid and increasing eigenvalue magnitude, and (2) computing gradients of noise-injected weights to regularize the Hessian. Extensive experiments show that WinQ accelerates QAT by up to 4 times across various quantization methods and models. Under the same training cost, WinQ improves state-of-the-art sub-4-bit quantization by up to 8.8%. These results are consistent across 16 settings with different language models, quantization methods, and bit widths.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that slow convergence and early plateaus in quantization-aware training (QAT) of language models below 4 bits arise because weights settle into flat saddle-point regions of the loss surface, where an increasing fraction of Hessian eigenvalues concentrate near zero and their magnitudes decrease (especially at lower bit widths). To mitigate this, the authors propose WinQ, which periodically resets weights to a linear interpolation between full-precision and quantized values (to increase eigenvalue magnitudes) and computes gradients on noise-injected weights (to regularize the Hessian). Extensive experiments across 16 settings report up to 4x acceleration of QAT and up to 8.8% improvement in sub-4-bit quantization performance under fixed training cost, relative to prior methods.
Significance. If the empirical speedups and accuracy gains hold under broader conditions, WinQ would offer a practical, low-overhead technique for accelerating sub-4-bit QAT of language models, addressing a known bottleneck in efficient deployment. The Hessian-based diagnostic provides an interesting lens on QAT dynamics, and the consistent results across models, quantizers, and bit widths strengthen the practical contribution. However, the significance is tempered by the observational (rather than causal) nature of the Hessian analysis and the absence of controls isolating the proposed mechanism from alternative explanations such as implicit regularization or quantization-error reduction.
major comments (3)
- [§3] §3 (Hessian spectrum analysis): The description of how the Hessian spectrum is estimated (e.g., number of samples, stochastic approximation method, or exact computation on which layers) is insufficiently detailed. This is load-bearing because the central diagnostic claim—that eigenvalues shrink in magnitude and concentrate near zero at lower bit widths—rests on these observations, yet no protocol, variance estimates, or statistical significance tests are provided to support reproducibility or rule out estimation artifacts.
- [§4.2] §4.2 (WinQ algorithm and ablations): The paper does not include an ablation that decouples the effect of the interpolation reset and noise injection on Hessian eigenvalue magnitudes from other possible mechanisms (e.g., periodic averaging reducing quantization error or noise acting as implicit regularization). Without such a controlled experiment, it remains unclear whether the reported speedups are caused by the claimed saddle-point mechanism or by unrelated side effects, weakening the explanatory link between the Hessian observations and the algorithmic interventions.
- [Table 2] Table 2 / experimental results: The reported speedups (up to 4x) and accuracy gains (up to 8.8%) are presented without details on the exact reset period, interpolation coefficient schedule, or noise variance used in each setting, nor on whether these hyperparameters were tuned per model/bit-width or held fixed. This makes it difficult to assess whether the gains are robust or depend on per-experiment tuning that could offset the claimed parameter-light nature of the approach.
minor comments (2)
- [§4.1] The notation for the interpolation coefficient and noise variance should be introduced with explicit symbols and ranges in the main text rather than only in the appendix, to improve readability of the algorithm description.
- [Figure 3] Figure 3 (Hessian eigenvalue histograms): Axis scales and the precise training step at which each snapshot is taken should be stated in the caption for easier comparison across bit widths.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments. We have carefully considered each point and made revisions to the manuscript to address the concerns raised. Our point-by-point responses are provided below.
read point-by-point responses
-
Referee: [§3] §3 (Hessian spectrum analysis): The description of how the Hessian spectrum is estimated (e.g., number of samples, stochastic approximation method, or exact computation on which layers) is insufficiently detailed. This is load-bearing because the central diagnostic claim—that eigenvalues shrink in magnitude and concentrate near zero at lower bit widths—rests on these observations, yet no protocol, variance estimates, or statistical significance tests are provided to support reproducibility or rule out estimation artifacts.
Authors: We agree that the Hessian spectrum estimation protocol requires more detail to ensure reproducibility. In the revised manuscript, we have expanded Section 3 to include the full estimation protocol, specifying the stochastic approximation method, number of samples and iterations, layers analyzed, variance estimates across multiple runs, and statistical significance tests confirming the trends in eigenvalue magnitudes and concentration near zero. These additions directly support the diagnostic claims and address potential estimation artifacts. revision: yes
-
Referee: [§4.2] §4.2 (WinQ algorithm and ablations): The paper does not include an ablation that decouples the effect of the interpolation reset and noise injection on Hessian eigenvalue magnitudes from other possible mechanisms (e.g., periodic averaging reducing quantization error or noise acting as implicit regularization). Without such a controlled experiment, it remains unclear whether the reported speedups are caused by the claimed saddle-point mechanism or by unrelated side effects, weakening the explanatory link between the Hessian observations and the algorithmic interventions.
Authors: We thank the referee for highlighting the need to strengthen the mechanistic link. We have added a controlled ablation study in the revised Section 4.2 that isolates the effects of the interpolation reset and noise injection. The study includes variants with each component disabled individually, as well as controls for periodic averaging and standard regularization, with measurements of resulting changes to Hessian eigenvalue magnitudes and convergence behavior. The results indicate that the combination specifically increases eigenvalue magnitudes around saddle points beyond what alternative mechanisms achieve. revision: yes
-
Referee: [Table 2] Table 2 / experimental results: The reported speedups (up to 4x) and accuracy gains (up to 8.8%) are presented without details on the exact reset period, interpolation coefficient schedule, or noise variance used in each setting, nor on whether these hyperparameters were tuned per model/bit-width or held fixed. This makes it difficult to assess whether the gains are robust or depend on per-experiment tuning that could offset the claimed parameter-light nature of the approach.
Authors: We agree that transparency on hyperparameter choices is essential for evaluating robustness. In the revised manuscript, we have added explicit details on the reset period, interpolation coefficient schedule, and noise variance used for each setting in Table 2. We clarify that these values were held fixed across comparable model and bit-width configurations rather than tuned individually per experiment. We also include a sensitivity analysis showing that the reported gains remain stable under small variations in these hyperparameters. revision: yes
Circularity Check
No circularity: empirical Hessian analysis and interventions are independent of inputs
full rationale
The paper's core contribution is an observational estimate of the Hessian spectrum during QAT, followed by an empirically validated algorithm (periodic interpolation reset plus noise injection) whose speedups are measured directly against external baselines. No derivation chain exists that reduces a claimed result to a fitted parameter or self-referential definition. The interventions are motivated by but not mathematically forced by the spectrum observations; performance claims rest on controlled experiments across 16 settings rather than any self-citation load-bearing step or ansatz smuggled via prior work. This is a standard empirical ML paper with no detectable circularity in its reasoning.
Axiom & Free-Parameter Ledger
free parameters (3)
- reset period
- interpolation coefficient
- noise variance
axioms (1)
- domain assumption The loss surface encountered during QAT contains saddle points whose Hessian spectrum contains both positive and negative eigenvalues whose magnitudes decrease during training and are smaller at lower bit widths.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We analyze the convergence of QAT by estimating the spectrum of the loss-surface Hessians. We find that the weights converge to flat regions around saddle points, where a large fraction of the Hessian eigenvalues are both positive and negative. ... the magnitude of eigenvalues in the Hessian spectrum is significantly smaller.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
periodically resetting weights to the linear interpolation of full-precision and quantized weights, reducing the distance to the quantization grid and increasing eigenvalue magnitude
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
The potential of second-order optimization for llms: A study with full gauss-newton
Abreu, N., Vyas, N., Kakade, S., and Morwani, D. The potential of second-order optimization for llms: A study with full gauss-newton. International Conference on Learning Representations (ICLR), 2026
work page 2026
-
[2]
L., Li, B., Cameron, P., Jaggi, M., Alistarh, D., Hoefler, T., and Hensman, J
Ashkboos, S., Mohtashami, A., Croci, M. L., Li, B., Cameron, P., Jaggi, M., Alistarh, D., Hoefler, T., and Hensman, J. Quarot: Outlier-free 4-bit inference in rotated llms. Advances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[3]
Proxquant: Quantized neural networks via proximal operators
Bai, Y., Wang, Y.-X., and Liberty, E. Proxquant: Quantized neural networks via proximal operators. In International Conference on Learning Representations, 2019
work page 2019
-
[4]
Some large-scale matrix computation problems
Bai, Z., Fahey, G., and Golub, G. Some large-scale matrix computation problems. Journal of Computational and Applied Mathematics, 1996
work page 1996
-
[5]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Bengio, Y., L \'e onard, N., and Courville, A. Estimating or propagating gradients through stochastic neurons for conditional computation. arXiv preprint arXiv:1308.3432, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[6]
Chee, J., Cai, Y., Kuleshov, V., and De Sa, C. M. Quip: 2-bit quantization of large language models with guarantees. Advances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[7]
Analysis of stochastic lanczos quadrature for spectrum approximation
Chen, T., Trogdon, T., and Ubaru, S. Analysis of stochastic lanczos quadrature for spectrum approximation. In International Conference on Machine Learning (ICML). PMLR, 2021
work page 2021
-
[8]
Fast hadamard transform in cuda, with a pytorch interface, 2025
Dao, T., Karampatziakis, N., and Chiang, H. Fast hadamard transform in cuda, with a pytorch interface, 2025
work page 2025
-
[9]
Gq-vae: A gated quantized vae for learning variable length tokens
Datta, T., Huang, K., Kakade, S., and Brandfonbrener, D. Gq-vae: A gated quantized vae for learning variable length tokens. arXiv preprint arXiv:2512.21913, 2025
-
[10]
Dong, Z., Yao, Z., Gholami, A., Mahoney, M. W., and Keutzer, K. Hawq: Hessian aware quantization of neural networks with mixed-precision. In International Conference on Computer Vision (ICCV), 2019
work page 2019
-
[11]
Dong, Z., Yao, Z., Arfeen, D., Gholami, A., Mahoney, M. W., and Keutzer, K. Hawq-v2: Hessian aware trace-weighted quantization of neural networks. Advances in Neural Information Processing Systems (NeurIPS), 2020
work page 2020
-
[12]
Esser, S. K., McKinstry, J. L., Bablani, D., Appuswamy, R., and Modha, D. S. Learned step size quantization. International Conference on Learning Representations (ICLR), 2020
work page 2020
-
[13]
Training with quantization noise for extreme model compression
Fan, A., Stock, P., Graham, B., Grave, E., Gribonval, R., Jegou, H., and Joulin, A. Training with quantization noise for extreme model compression. International Conference on Learning Representations (ICLR), 2021
work page 2021
-
[14]
G., Duan, D., Iyengar, A., Liu, J
Fifty, C., Junkins, R. G., Duan, D., Iyengar, A., Liu, J. W., Amid, E., Thrun, S., and R \'e , C. Restructuring vector quantization with the rotation trick. International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[15]
Frantar, E. and Alistarh, D. Optimal brain compression: A framework for accurate post-training quantization and pruning. Advances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[16]
Gptq: Accurate post-training quantization for generative pre-trained transformers
Frantar, E., Ashkboos, S., Hoefler, T., and Alistarh, D. Gptq: Accurate post-training quantization for generative pre-trained transformers. International Conference on Learning Representations (ICLR), 2023
work page 2023
-
[17]
Gholami, A., Kim, S., Dong, Z., Yao, Z., Mahoney, M. W., and Keutzer, K. A survey of quantization methods for efficient neural network inference. In Low-power computer vision, pp.\ 291--326. 2022
work page 2022
-
[18]
An investigation into neural net optimization via hessian eigenvalue density
Ghorbani, B., Krishnan, S., and Xiao, Y. An investigation into neural net optimization via hessian eigenvalue density. In International Conference on Machine Learning (ICML), 2019
work page 2019
-
[19]
Quantization and training of neural networks for efficient integer-arithmetic-only inference
Jacob, B., Kligys, S., Chen, B., Zhu, M., Tang, M., Howard, A., Adam, H., and Kalenichenko, D. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Computer Vision and Pattern Recognition (CVPR), 2018
work page 2018
-
[20]
Jin, C., Ge, R., Netrapalli, P., Kakade, S. M., and Jordan, M. I. How to escape saddle points efficiently. In International Conference on Machine Learning (ICML). PMLR, 2017
work page 2017
-
[21]
Ju, H., Li, D., and Zhang, H. R. Robust fine-tuning of deep neural networks with hessian-based generalization guarantees. In International Conference on Machine Learning (ICML), 2022
work page 2022
-
[22]
Ju, H., Li, D., Sharma, A., and Zhang, H. R. Generalization in graph neural networks: Improved pac-bayesian bounds on graph diffusion. In International Conference on Artificial Intelligence and Statistics (AISTATS), pp.\ 6314--6341, 2023
work page 2023
-
[23]
F., Bordelon, B., Muennighoff, N., Paul, M., Pehlevan, C., Re, C., and Raghunathan, A
Kumar, T., Ankner, Z., Spector, B. F., Bordelon, B., Muennighoff, N., Paul, M., Pehlevan, C., Re, C., and Raghunathan, A. Scaling laws for precision. In International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[24]
H., Gil, S., Anand, N., and Kakade, S
Kwun, M., Morwani, D., Su, C. H., Gil, S., Anand, N., and Kakade, S. Lotion: Smoothing the optimization landscape for quantized training. arXiv preprint arXiv:2510.08757, 2025
-
[25]
Awq: Activation-aware weight quantization for on-device llm compression and acceleration
Lin, J., Tang, J., Tang, H., Yang, S., Chen, W.-M., Wang, W.-C., Xiao, G., Dang, X., Gan, C., and Han, S. Awq: Activation-aware weight quantization for on-device llm compression and acceleration. Machine Learning and Systems (MLSys), 2024
work page 2024
-
[26]
Bit: Robustly binarized multi-distilled transformer
Liu, Z., Oguz, B., Pappu, A., Xiao, L., Yih, S., Li, M., Krishnamoorthi, R., and Mehdad, Y. Bit: Robustly binarized multi-distilled transformer. Advances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[27]
Spinquant: Llm quantization with learned rotations
Liu, Z., Zhao, C., Fedorov, I., Soran, B., Choudhary, D., Krishnamoorthi, R., Chandra, V., Tian, Y., and Blankevoort, T. Spinquant: Llm quantization with learned rotations. International Conference on Learning Representations (ICLR), 2025 a
work page 2025
-
[28]
Paretoq: Scaling laws in extremely low-bit llm quantization
Liu, Z., Zhao, C., Huang, H., Chen, S., Zhang, J., Zhao, J., Roy, S., Jin, L., Xiong, Y., Shi, Y., Xiao, L., Tian, Y., Soran, B., Krishnamoorthi, R., Blankevoort, T., and Chandra, V. Paretoq: Scaling laws in extremely low-bit llm quantization. Advances in Neural Information Processing Systems (NeurIPS), 2025 b
work page 2025
-
[29]
A., Datta, P., Dean, J., Jain, P., and Kusupati, A
Nair, P. A., Datta, P., Dean, J., Jain, P., and Kusupati, A. Matryoshka quantization. In International Conference on Machine Learning (ICML), 2025
work page 2025
-
[30]
Lectures on convex optimization, volume 137
Nesterov, Y. Lectures on convex optimization, volume 137. Springer, 2018
work page 2018
-
[31]
L., Nikdan, M., and Alistarh, D
Panferov, A., Chen, J., Tabesh, S., Castro, R. L., Nikdan, M., and Alistarh, D. Quest: Stable training of llms with 1-bit weights and activations. International Conference on Machine Learning (ICML), 2025
work page 2025
-
[32]
Cage: Curvature-aware gradient estimation for accurate quantization-aware training
Tabesh, S., Safaryan, M., Panferov, A., Volkova, A., and Alistarh, D. Cage: Curvature-aware gradient estimation for accurate quantization-aware training. arXiv preprint arXiv:2510.18784, 2025
-
[33]
BitNet: Scaling 1-bit Transformers for Large Language Models
Wang, H., Ma, S., Dong, L., Huang, S., Wang, H., Ma, L., Yang, F., Wang, R., Wu, Y., and Wei, F. Bitnet: Scaling 1-bit transformers for large language models. arXiv preprint arXiv:2310.11453, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Wilson, A. G. Deep learning is not so mysterious or different. International Conference on Machine Learning (ICML), 2025
work page 2025
-
[35]
Yao, Z., Gholami, A., Lei, Q., Keutzer, K., and Mahoney, M. W. Hessian-based analysis of large batch training and robustness to adversaries. Advances in Neural Information Processing Systems (NeurIPS), 2018
work page 2018
-
[36]
Yao, Z., Gholami, A., Keutzer, K., and Mahoney, M. W. Pyhessian: Neural networks through the lens of the hessian. In International Conference on Big Data, 2020
work page 2020
-
[37]
Modulora: finetuning 2-bit llms on consumer gpus by integrating with modular quantizers
Yin, J., Dong, J., Wang, Y., De Sa, C., and Kuleshov, V. Modulora: finetuning 2-bit llms on consumer gpus by integrating with modular quantizers. Transactions on machine learning research (TMLR), 2024
work page 2024
-
[38]
Large batch optimization for deep learning: Training bert in 76 minutes
You, Y., Li, J., Reddi, S., Hseu, J., Kumar, S., Bhojanapalli, S., Song, X., Demmel, J., Keutzer, K., and Hsieh, C.-J. Large batch optimization for deep learning: Training bert in 76 minutes. In International Conference on Learning Representations (ICLR), 2020
work page 2020
-
[39]
Zhang, H. R., Li, D., and Ju, H. Noise stability optimization for finding flat minima: A hessian-based regularization approach. Transactions on Machine Learning Research (TMLR), 2024 a
work page 2024
-
[40]
Q-hitter: A better token oracle for efficient llm inference via sparse-quantized kv cache
Zhang, Z., Liu, S., Chen, R., Kailkhura, B., Chen, B., and Wang, Z. Q-hitter: A better token oracle for efficient llm inference via sparse-quantized kv cache. Machine Learning and Systems (MLSys), 2024 b
work page 2024
-
[41]
Zhang, Z., Zhang, Z., Li, D., Wang, L., Dy, J., and Zhang, H. R. Linear-time demonstration selection for in-context learning via gradient estimation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), pp.\ 16470--16488, 2025
work page 2025
-
[42]
Zhang, Z., Duan, M., Ye, Y., and Zhang, H. R. Scalable multi-objective and meta reinforcement learning via gradient estimation. In The AAAI Conference on Artificial Intelligence (AAAI), pp.\ 28609--28617, 2026 a
work page 2026
-
[43]
Zhang, Z., Duan, M., and Zhang, H. R. Efficient estimation of kernel surrogate models for task attribution. International Conference on Learning Representations (ICLR), 2026 b
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.