MARQUIS: A Three-Stage Pipeline for Video Retrieval-Augmented Generation
Pith reviewed 2026-05-19 22:34 UTC · model grok-4.3
The pith
MARQUIS is a three-stage pipeline that lifts video retrieval-augmented generation performance on complex queries and long contexts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
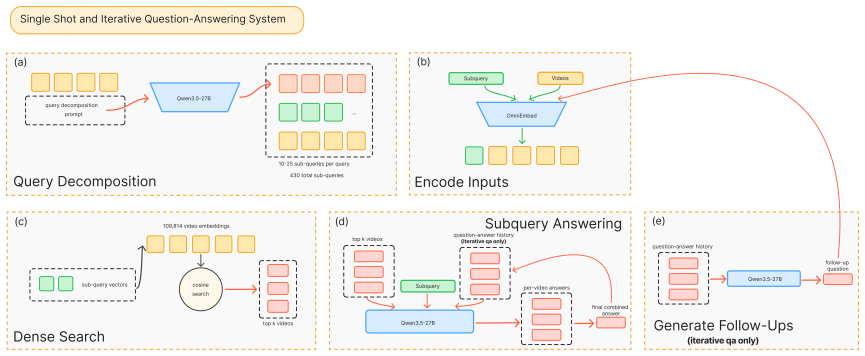
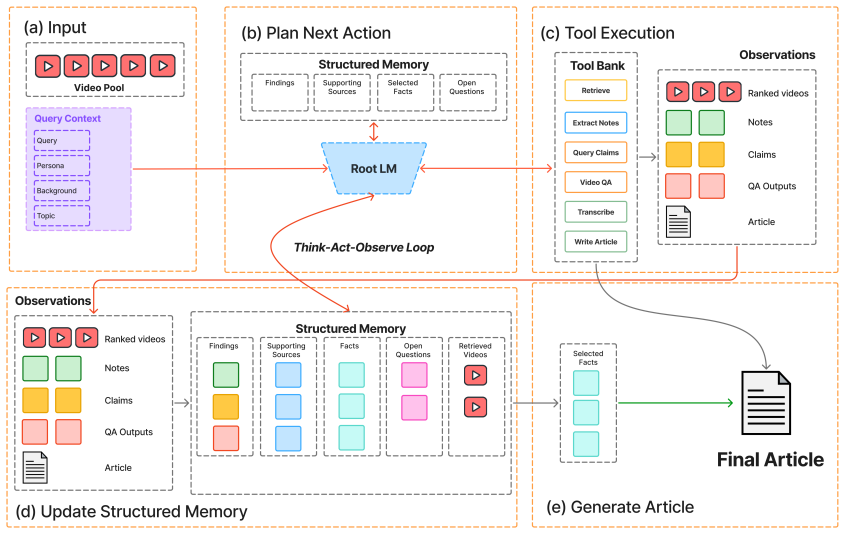
MARQUIS addresses the dual bottlenecks of retrieval-augmented generation from videos by chaining three stages: query expansion, fusion, and reranking; calibrated structured evidence extraction; and article generation from the extracted evidence, optionally controlled by an RLM. On the MAGMaR2026 shared task the system improves retrieval nDCG@10 from 0.195 to 0.759. For generation, ITER-QA-BASE raises average human score from 3.09 to 3.83 over the CAG baseline, while MARQUIS-RLM reaches a human score of 3.30 and the strongest citation recall among non-QA systems.
What carries the argument
The three-stage pipeline of query expansion/fusion/reranking, calibrated structured evidence extraction, and RLM-controlled article generation that processes complex queries and long multi-video contexts without direct embedding of entire videos.
If this is right
- Complex multi-faceted queries become tractable for retrieval when expansion and reranking are applied before evidence extraction.
- Structured evidence extraction reduces memory pressure and improves synthesis quality when generating articles from many videos.
- RLM guidance during generation can increase citation recall even when full QA-style systems are not used.
Where Pith is reading between the lines
- The same staged approach could be tested on audio-only or image-heavy corpora to check whether the gains transfer beyond video.
- If the structured extraction step is the main driver, replacing it with simpler summarizers should produce measurable drops in final article scores.
Load-bearing premise
The large gains come from the three-stage design itself rather than from particular implementation choices, baseline selections, or task-specific tuning details not described in the abstract.
What would settle it
An ablation experiment that removes one of the three stages and measures whether nDCG@10 drops back toward 0.195 or human generation scores drop back toward 3.09 on the same MAGMaR2026 test set.
Figures


read the original abstract
Retrieval-augmented generation from videos requires systems to retrieve relevant audiovisual evidence from large corpora and synthesize it into coherent, attributed text. Current approaches struggle at both ends: retrieval methods fail on complex, multi-faceted queries that cannot be captured by a single embedding, while generation methods lack the high-level reasoning needed to synthesize across multiple videos and face memory constraints over long, multi-video contexts. We present MARQUIS: a three-stage pipeline that addresses these limitations through (1) query expansion, fusion, and reranking, (2) calibrated structured evidence extraction, and (3) article generation from extracted evidence, optionally controlled by an RLM. On the MAGMaR2026 shared task, we improve retrieval performance from 0.195 to 0.759 (nDCG@10). For article generation, ITER-QA-BASE improves average human score from 3.09 to 3.83 over the CAG baseline, while MARQUIS-RLM achieves a human score of 3.30 and the strongest citation recall among non-QA systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MARQUIS, a three-stage pipeline for video retrieval-augmented generation. The stages comprise (1) query expansion, fusion, and reranking to address complex multi-faceted queries, (2) calibrated structured evidence extraction from audiovisual content, and (3) article generation from the extracted evidence, optionally controlled by an RLM. On the MAGMaR2026 shared task, the work reports retrieval nDCG@10 improving from 0.195 to 0.759. For generation, ITER-QA-BASE raises average human score from 3.09 (CAG baseline) to 3.83, while MARQUIS-RLM scores 3.30 and achieves the strongest citation recall among non-QA systems.
Significance. If the reported gains prove robust and attributable to the pipeline architecture, the work would advance video RAG by tackling limitations in handling complex queries and synthesizing across long multi-video contexts. The use of a shared-task benchmark and human evaluation for generation quality are positive for comparability and practical relevance. The manuscript would benefit from explicit credit for any reproducible components or falsifiable predictions, but these are not yet evident from the available description.
major comments (1)
- [§4 (Experiments)] §4 (Experiments) and associated results tables: the central claim attributes the nDCG@10 jump from 0.195 to 0.759 and the human-score gains (3.09 to 3.83) to the three-stage pipeline, yet no ablation studies or matched single-stage controls are described that isolate the incremental contribution of query expansion/fusion/reranking, structured extraction, or RLM control versus underlying model choices, hyperparameter effort, or prompt engineering. This absence directly undermines attribution of the improvements to the proposed architecture.
minor comments (2)
- [Abstract] Abstract: acronyms CAG, ITER-QA-BASE, and RLM are used without definition on first appearance; expand them for immediate readability.
- [Method (§3)] Throughout: ensure all method details (specific retriever/generator models per stage, calibration procedure, RLM integration, and hyperparameter settings) are provided with sufficient precision to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on the MARQUIS manuscript. We address the single major comment below and describe the changes we will make in revision.
read point-by-point responses
-
Referee: [§4 (Experiments)] §4 (Experiments) and associated results tables: the central claim attributes the nDCG@10 jump from 0.195 to 0.759 and the human-score gains (3.09 to 3.83) to the three-stage pipeline, yet no ablation studies or matched single-stage controls are described that isolate the incremental contribution of query expansion/fusion/reranking, structured extraction, or RLM control versus underlying model choices, hyperparameter effort, or prompt engineering. This absence directly undermines attribution of the improvements to the proposed architecture.
Authors: We agree that the current manuscript does not contain explicit ablation studies that would isolate the contribution of each pipeline stage from model choice, hyperparameter tuning, or prompt engineering. The reported numbers reflect end-to-end performance of the full MARQUIS system against the shared-task baselines. To strengthen attribution, we will add ablation experiments in the revised manuscript. These will include (i) a version that disables query expansion/fusion/reranking while retaining the downstream stages, (ii) a version that replaces calibrated structured extraction with direct passage retrieval, and (iii) a version that removes RLM control. All ablations will be run with the same underlying models and prompts used in the main results so that incremental gains can be attributed more directly to the architectural components. revision: yes
Circularity Check
No circularity: empirical results on external shared-task benchmark
full rationale
The paper presents an engineering pipeline (query expansion/fusion/reranking, structured extraction, RLM-controlled generation) and measures its performance on the fixed external MAGMaR2026 benchmark using standard metrics (nDCG@10, human scores). No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the provided text. The reported gains are direct empirical comparisons against external baselines and do not reduce to the pipeline's own inputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MARQUIS: a three-stage pipeline that addresses these limitations through (1) query expansion, fusion, and reranking, (2) calibrated structured evidence extraction, and (3) article generation from extracted evidence, optionally controlled by an RLM.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
On the MAGMaR2026 shared task, we improve retrieval performance from 0.195 to 0.759 (nDCG@10).
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
TVQA: Localized, compositional video ques- tion answering. InProceedings of the 2018 Con- ference on Empirical Methods in Natural Language Processing, pages 1369–1379, Brussels, Belgium. Association for Computational Linguistics. Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Hein- rich Küttler, Mike Lewis, ...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Streamlining evaluation with ir-measures. In Advances in Information Retrieval - 44th European Conference on IR Research, ECIR 2022, Stavanger , Norway, April 10-14, 2022, Proceedings, Part II, volume 13186 ofLecture Notes in Computer Science, pages 305–310. Springer. Alexander Martin, Reno Kriz, William Gantt Walden, Kate Sanders, Hannah Recknor, Eugene ...
-
[3]
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brock- man, Christine Mcleavey, and Ilya Sutskever
Multi-Vector Index Compression in Any Modality.Preprint, arXiv:2602.21202. Alec Radford, Jong Wook Kim, Tao Xu, Greg Brock- man, Christine Mcleavey, and Ilya Sutskever. 2023. Robust speech recognition via large-scale weak su- pervision. InProceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Re...
-
[4]
Look back to reason forward: Revisitable memory for long-context llm agents.Preprint, arXiv:2509.23040. Tyler Skow, Alexander Martin, Benjamin Van Durme, Rama Chellappa, and Reno Kriz. 2026. Rankvideo: Reasoning reranking for text-to-video retrieval. Preprint, arXiv:2602.02444. Qwen Team. 2026. Qwen3.5-omni technical report. Preprint, arXiv:2604.15804. Or...
-
[5]
Do not merge separate information needs into one sub-query
Coverage: Extract every distinct piece of information the user is asking for. Do not merge separate information needs into one sub-query
-
[6]
Prefer atomic queries over compound ones
Granularity: Each sub-query should target ONE specific, retrievable piece of information. Prefer atomic queries over compound ones
-
[7]
Implicit needs: Go beyond what is explicitly stated. Based on the background and persona_title, infer what additional information the user would likely need but did not explicitly ask for. Metric Value Per-Iteration Token Consumption Total tokens 11131 Prompt (context) 10689±6434 (96%) Completion 442±415 (4%) Reasoning 328 Output 114 Context Window Utiliz...
-
[8]
Search-friendly format: Each sub-query should be phrased as a concise search phrase, typically 3–10 words, not a full sentence or question
-
[9]
Context anchoring: Each sub-query should include enough context to be independently searchable without ambiguity
-
[10]
Source-awareness: If the user requests source information, generate sub-queries targeting official sources, methodologies, and data provenance
-
[11]
Dimensional expansion: Consider additional perspectives or breakdowns by time, place, category, cause, mechanism, or comparison only when they add value
-
[12]
No redundancy: Each sub-query must be meaningfully distinct
-
[13]
Language: Always generate sub-queries in English
-
[14]
Generate between 10 and 25 sub-queries
-
[15]
Do not mechanically prepend the full topic title to every sub-query
-
[16]
Focus on the specific information being sought, not on repeating the topic name. Return ONLY a JSON array of strings. No explanation, no markdown, no code blocks. General note extraction prompt.The general- note prompt is query-agnostic but not fully context- free: it includes the source topic and video iden- tifier together with an evidence-first instruc...
-
[17]
Do not merge separate information needs into one question
Coverage: Extract every distinct piece of information the user is asking for. Do not merge separate information needs into one question. If the query asks for multiple related but distinct data points, each one should become its own question
-
[18]
Prefer atomic questions over compound ones
Granularity: Each question should target ONE specific, retrievable piece of information. Prefer atomic questions over compound ones
-
[19]
Implicit needs: Go beyond what is explicitly stated. Based on the background and persona_title, infer what additional information the user would likely need but did not explicitly ask for. Consider what a professional in that role would typically require to produce complete, high-quality work on this topic
-
[20]
Search-friendly format: Each sub-query must be written as a concise, well-formed question that could plausibly be entered into a search engine or research database
-
[21]
Context anchoring: Each question should include enough context (e.g., specific names, dates, locations, technical terms) to be independently searchable without ambiguity
-
[22]
Source-awareness: If the user requests source information or credibility indicators, generate questions specifically targeting official sources, methodologies, and data provenance
-
[23]
Dimensional expansion: For each core information need identified, consider whether the user would benefit from additional perspectives or breakdowns. Ask yourself: can this information be meaningfully decomposed further by time, place, category, cause, mechanism, comparison, or any other axis that is natural and relevant to the topic? Only expand along di...
-
[24]
Do not produce near-duplicates that would return the same search results
No redundancy: Each question must be meaningfully distinct. Do not produce near-duplicates that would return the same search results
-
[25]
Language: Always generate questions in English, regardless of the language field in the input
-
[26]
Focus on quality and relevance over quantity
Quantity: Generate between 10 and 25 questions. Focus on quality and relevance over quantity
-
[27]
Each question should contain only the context necessary for an effective search
Avoid mechanical repetition: Do not mechanically prepend the full topic title to every question. Each question should contain only the context necessary for an effective search
-
[28]
Focus on information needs: Focus on the specific information being sought rather than repeating the topic name unnecessarily. Return ONLY a JSON array of strings. No explanation, no markdown, and no code blocks. For example, given a query about the 2025 Canadian federal election asking for seat counts and vote shares, good questions would be: [ "What was...
work page 2025
-
[29]
Each claim was extracted from a specific video and has a timestamp
Read all the claims below carefully. Each claim was extracted from a specific video and has a timestamp
-
[30]
Group related claims together logically (e.g., by sub-topic or chronological order)
-
[31]
Write a coherent, well-structured report that covers all the key information from the claims
-
[32]
For EVERY piece of information in your report, include an inline citation in the format [video_id, timestamp_start-timestamp_end]
-
[33]
If multiple claims from different videos support the same point, cite all relevant sources
-
[34]
Remove redundant information — if multiple claims say the same thing, mention it once and cite all sources
-
[35]
The report should be fluent and readable, not a list of bullet points
-
[36]
Keep the report concise but comprehensive (aim for 200-400 words). ## Query/Topic: {topic} ## Claims: {claims_text} ## Report: GINGER clustering prompt.The model re- ceives all claims for a query and is instructed to partition them into thematic facet clusters, return- ing a labeled JSON partition of the claim set. You are an information analyst. Given a ...
-
[37]
Read all claims carefully
-
[38]
Group them into clusters based on their sub-topic/facet (e.g., "casualties", "rescue efforts", "damage assessment", "government response", etc.)
-
[39]
Each claim should belong to exactly one cluster
-
[40]
Give each cluster a short, descriptive label
-
[41]
Output your result as a JSON object with the following format: { "clusters": [ { "label": "Short descriptive label for this facet", "claim_ids": ["qc-10-xxx-000", "qc-10-xxx-001"] }, ... ] } Only output the JSON object, no other text. ## Topic: {topic} ## Claims: {claims_text} GINGER ranking prompt.The model receives the labeled clusters and is instructed...
-
[42]
Consider which facets are most important for answering/addressing the query topic
-
[43]
Rank all clusters from most relevant to least relevant
-
[44]
Output a JSON array of cluster labels in order from most to least relevant: { "ranked_labels": ["most relevant label", "second most relevant", ...] } Only output the JSON object, no other text. ## Topic: {topic} ## Clusters: {clusters_text} GINGER summarization prompt.The model receives the claims within a single cluster and is instructed to condense them...
-
[45]
Capture the key information from all claims in this cluster
-
[46]
Include inline citations in the format [video_id, timestamp] for every fact mentioned
-
[47]
Be factual — only include information present in the claims. ## Cluster: {cluster_label} ## Claims in this cluster: {cluster_claims_text} ## One-sentence summary: GINGER fluency prompt.The model receives the concatenated one-sentence cluster summaries and is instructed to rewrite them into a coherent 200–400-word prose report without adding new informatio...
-
[48]
Do NOT add any new information that is not in the summaries below
-
[49]
Do NOT remove any information or citations from the summaries
-
[50]
Keep ALL inline citations in the format [video_id, timestamp]
-
[51]
Improve transitions between sentences for better readability
-
[52]
You may reorder sentences for better logical flow
-
[53]
Keep the report concise (200-400 words). ## Draft report (concatenated summaries): {draft_report} ## Final polished report: MARQUIS-RLM REPL system prompt. You answer queries using an interactive Python REPL, called iteratively until you submit a final answer. THINK-ACT-OBSERVE LOOP: Each iteration: THINK (brief reasoning), ACT (one code block), OBSERVE t...
-
[54]
If a new fact CONTRADICTS an existing finding, say CONFLICT: <existing> vs <new>
NEW_FINDINGS: List any new high-level findings (one sentence each) not already in CURRENT FINDINGS. If a new fact CONTRADICTS an existing finding, say CONFLICT: <existing> vs <new>
-
[55]
One finding per line, prefixed with ‘- ’
UPDATED_FINDINGS: Output the complete updated findings list (old + new, deduplicated). One finding per line, prefixed with ‘- ’
-
[56]
NEXT_STEPS: What should the agent do next? Be specific: which video, which tool, which question. Be concise. MARQUIS-RLM Root LM Judge prompt. TASK: {query_text} FINDINGS (root’s current understanding): {findings_str} FACT TABLE ({n} facts): {fact_lines} You are a strict quality judge. Review ALL facts above for the task
-
[57]
BE CONSERVATIVE — only REMOVE if clearly irrelevant or duplicate
ITEM REVIEW: For each fact (F#0, F#1, ...), give a verdict. BE CONSERVATIVE — only REMOVE if clearly irrelevant or duplicate. When in doubt, KEEP. KEEP — useful, specific, or even mildly relevant (default) REMOVE — clearly irrelevant or duplicate of another listed fact REWRITE — needs more detail or has a missing timestamp (flag, do NOT drop) Format: F#0:...
-
[58]
List their IDs: SELECTED: F#0, F#2, F#7,
SELECTED: Pick the 10-40 BEST facts for a comprehensive report (prefer MORE coverage). List their IDs: SELECTED: F#0, F#2, F#7,
-
[59]
MISSING TIMESTAMPS: List facts that are useful but lack timestamps; suggest video_qa queries to resolve them
-
[60]
GAPS: What information is still missing for a thorough report?
-
[61]
MARQUIS-RLM LLM-as-a judge prompt (behavior-level)
READY: Can we write a good report now? (yes / no / almost) Be specific and concise. MARQUIS-RLM LLM-as-a judge prompt (behavior-level). You are evaluating an AI agent’s performance on iteration {iteration}/{max_iter}. TASK: {query} MEMORY STATE BEFORE: {mem_before} THINK: {think_text} ACT: {code} OBSERVE: {observe} MEMORY STATE AFTER: {mem_after} Rate eac...
-
[62]
Reasoning (1-5): Did THINK show sound reasoning based on memory?
-
[63]
Action (1-5): Was the chosen action relevant and logical?
-
[64]
Granularity (1-5): One focused step, or too much at once?
-
[65]
Eff_Redundancy (1-5) — avoided repeating a tool call? 5b
Progress (1-5): Did this iteration meaningfully advance the task? ## Efficiency breakdown (5 sub-scores): 5a. Eff_Redundancy (1-5) — avoided repeating a tool call? 5b. Eff_Think_Conciseness (1-5) — THINK tight and non-repetitive? 5c. Eff_Code_Minimality (1-5) — minimal code for its purpose? 5d. Eff_Output_Waste (1-5) — avoided producing useless output? 5e...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.