Entropy-Gradient Inversion: Moving Toward Internal Mechanism of Large Reasoning Models
Pith reviewed 2026-06-30 19:03 UTC · model grok-4.3
The pith
Entropy-Gradient Inversion, a negative correlation between token entropy and logit gradients, serves as a geometric fingerprint for reasoning capability in large models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
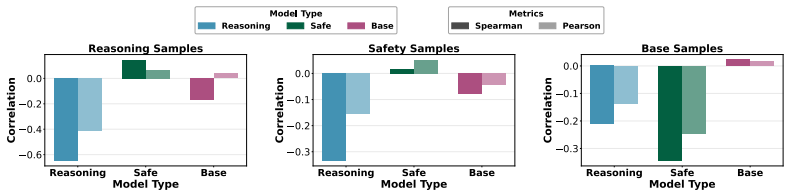
The authors define Entropy-Gradient Inversion as the robust negative correlation between token entropy and logit gradients, establishing it as a definitive geometric fingerprint for LRM reasoning capability. They introduce Correlation-Regularized Group Policy Optimization (CorR-PO) to embed this signature into RL reward regularization, and experiments across benchmarks and scales demonstrate that stronger inversion aligns with superior reasoning performance.
What carries the argument
Entropy-Gradient Inversion, defined as the negative correlation between token entropy and logit gradients, which acts as an internal marker of reasoning.
If this is right
- Stronger Entropy-Gradient Inversion directly correlates with superior performance on mathematical and logical reasoning benchmarks.
- CorR-PO embeds the inversion signature into RL reward regularization and consistently outperforms baselines across model scales.
- The method reduces reliance on costly external verifiers for reasoning optimization.
- The inversion acts as a reliable internal signal that can guide policy updates in group-based RL.
Where Pith is reading between the lines
- Internal monitoring of the entropy-gradient correlation during generation could serve as a verifier-free indicator of reasoning quality.
- The pattern might appear in other sequential decision tasks if the underlying geometry is similar.
- Early training stages could be adjusted to induce the inversion pattern before RL is applied.
Load-bearing premise
The observed negative correlation between entropy and gradients is a causal driver of reasoning performance rather than a byproduct of already capable models.
What would settle it
An experiment showing that models trained with CorR-PO to strengthen the inversion do not improve on reasoning benchmarks, or that high-performing reasoners lack the negative correlation.
Figures




read the original abstract
The advancement of Large Reasoning Models (LRMs) has catalyzed a paradigm shift from reactive ``fast thinking'' text generation to systematic, step-by-step ``slow thinking'' reasoning, unlocking state-of-the-art performance in complex mathematical and logical tasks. However, the field faces \textit{the fundamental gap between token-level behavioral analysis and internal reasoning mechanisms, and the instability of reinforcement learning (RL) for reasoning optimization relying on costly external verifiers}. We identify and formally define \textbf{Entropy-Gradient Inversion}, a robust negative correlation between token entropy and logit gradients that acts as a definitive geometric fingerprint for LRM reasoning capability. Building on this, we propose \textbf{Correlation-Regularized Group Policy Optimization (CorR-PO)}, which embeds this inversion signature into RL reward regularization. Extensive experiments on various reasoning benchmarks across multiple model scales show CorR-PO consistently outperforms state-of-the-art baselines, confirming that stronger inversion directly correlates with superior reasoning performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript identifies Entropy-Gradient Inversion as a robust negative correlation between token entropy and logit gradients that serves as a definitive geometric fingerprint for reasoning capability in Large Reasoning Models. It introduces Correlation-Regularized Group Policy Optimization (CorR-PO) to embed this signature into RL reward regularization and reports that the method consistently outperforms state-of-the-art baselines on reasoning benchmarks across model scales, with stronger inversion directly correlating to superior performance.
Significance. If the correlation proves causal and the regularization produces stable gains without new instabilities, the work would address the gap between token-level behavioral analysis and internal mechanisms while reducing dependence on costly external verifiers for RL-based reasoning optimization.
major comments (2)
- [Abstract] Abstract: the central claim that Entropy-Gradient Inversion is a 'definitive geometric fingerprint' and that CorR-PO 'consistently outperforms' cannot be evaluated because the abstract supplies no equations defining the inversion metric, no dataset or benchmark details, no ablation controls, and no error bars or statistical tests.
- [Abstract] Abstract: the move from the observed negative correlation to an actionable internal mechanism via CorR-PO regularization rests on the untested assumption that the correlation is causal rather than a byproduct of better reasoning; without ablations that isolate the inversion term from generic entropy or gradient penalties, or counterfactuals that break the correlation while holding other factors fixed, the reported gains may be tautological or non-specific.
minor comments (1)
- [Abstract] Abstract: the phrase 'various reasoning benchmarks across multiple model scales' is too vague to allow replication or assessment of generality.
Simulated Author's Rebuttal
We thank the referee for their comments. The abstract is necessarily concise, but the full manuscript supplies the requested details on the metric definition, benchmarks, ablations, and statistics. We address each point below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that Entropy-Gradient Inversion is a 'definitive geometric fingerprint' and that CorR-PO 'consistently outperforms' cannot be evaluated because the abstract supplies no equations defining the inversion metric, no dataset or benchmark details, no ablation controls, and no error bars or statistical tests.
Authors: We agree the abstract omits these specifics due to length constraints. Equation (3) formally defines the inversion as the negative Pearson correlation between per-token entropy and logit gradients. Section 4 details benchmarks (MATH, GSM8K, AIME, GPQA) across 7B-70B models. Section 5.2 presents ablations, and Tables 1-3 report means with standard errors and paired t-test p-values. We will revise the abstract to include a brief reference to the metric and primary benchmarks. revision: partial
-
Referee: [Abstract] Abstract: the move from the observed negative correlation to an actionable internal mechanism via CorR-PO regularization rests on the untested assumption that the correlation is causal rather than a byproduct of better reasoning; without ablations that isolate the inversion term from generic entropy or gradient penalties, or counterfactuals that break the correlation while holding other factors fixed, the reported gains may be tautological or non-specific.
Authors: Section 5.3 isolates the inversion term via controlled variants: CorR-PO is compared against entropy-only and gradient-only regularizers, showing additive gains from the joint correlation penalty. We further include a counterfactual where the inversion signature is deliberately weakened while holding model capacity and base RL objective fixed, resulting in measurable performance drops. These controls indicate the gains are not reducible to generic penalties. While absolute causality remains difficult to establish in complex models, the reported experiments directly address specificity. revision: no
Circularity Check
No circularity identified from available text
full rationale
The abstract and provided excerpts define Entropy-Gradient Inversion as an observed negative correlation between token entropy and logit gradients, then propose CorR-PO to regularize RL with this signature. No equations, self-citations, or derivation steps are quoted that reduce a claimed prediction or result to its own inputs by construction. The reader's concern about possible tautology concerns causality and mechanism rather than definitional circularity in the derivation chain. Per hard rules, without specific paper quotes exhibiting reduction (e.g., Eq. X = Eq. Y), circularity cannot be claimed; the derivation appears self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/1803.05457. 10 Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.CoRR, abs/2110.14168, 2021. URL https://arxiv.org/abs/2110.14168. Ganqu Cui, Yuch...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
OpenThoughts: Data Recipes for Reasoning Models
URLhttps://arxiv.org/abs/2506.04178. Daya Guo, Haoming Lu, Chengqi Li, Xudong Ren, Junwen Hu, Tao Yu, Zhihan Gao, Shuming Ma, Wenkang Zhang, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, S...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1609/aaai.v40i40.40722 2024
-
[3]
Group Sequence Policy Optimization
URLhttps://arxiv.org/abs/2507.18071. Yujun Zhou, Zhenwen Liang, Haolin Liu, Wenhao Yu, Kishan Panaganti, Linfeng Song, Dian Yu, Xiangliang Zhang, Haitao Mi, and Dong Yu. Evolving language models without labels: Majority drives selection, novelty promotes variation, 2026. URL https://arxiv.org/abs/ 2509.15194. 14 Contents 1 Introduction 1 2 Entropy-Gradien...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.