Articulation in Prime: Primitive-Based Articulated Object Understanding from a Single Casual Video
Pith reviewed 2026-05-20 11:57 UTC · model grok-4.3
The pith
Geometric primitives recover articulated kinematics from a single casual video by jointly optimizing parts and joints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a category-agnostic optimization framework that treats articulated object understanding as a primitive-fitting problem. Geometric primitives serve as a proxy representation that avoids the pitfalls of unstable point tracks; a novel mechanism organizes them into coherent parts constrained by revolute and prismatic joints. Our formulation jointly optimizes part segmentation and joint parameters, recovering complex kinematics from a single casually captured video. A visibility-aware procedure handles partial observations and occlusions inherent to real-world data.
What carries the argument
Geometric primitives fitted across video frames and grouped into parts via revolute and prismatic joint constraints; the mechanism performs the work of providing a stable proxy that supports simultaneous optimization of segmentation and kinematics parameters.
If this is right
- Recovers complex 3D kinematics from monocular video without long-term point tracking or wide-baseline matching.
- Operates without category-specific training data or specialized capture rigs.
- Handles severe occlusions and rapid ego-motion through the visibility-aware procedure.
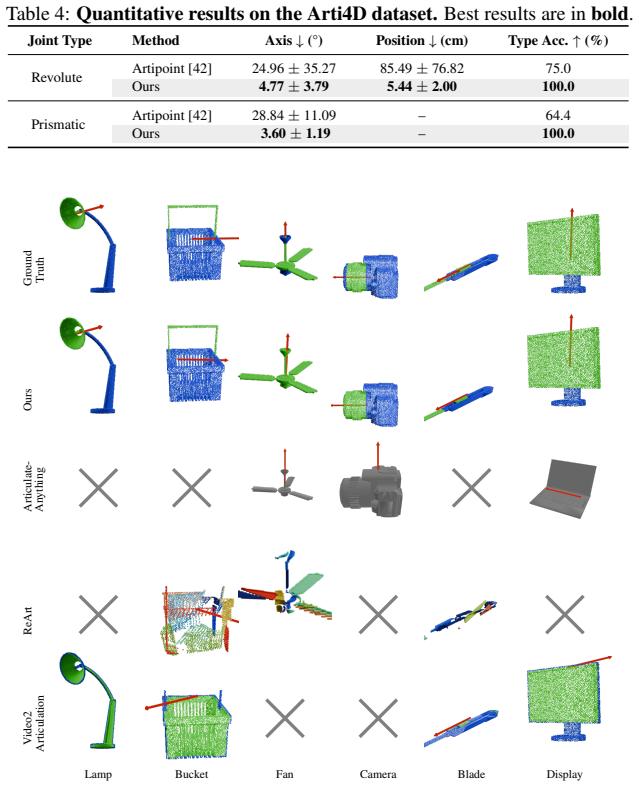
- Outperforms prior methods on the AiP-synth and AiP-real benchmarks that emphasize challenging real-world conditions.
Where Pith is reading between the lines
- The same primitive proxy idea could be tested on videos containing spherical or screw joints to check the limits of the current revolute-prismatic constraint set.
- Combining the optimization with learned priors might improve initialization speed while retaining the stability of explicit fitting.
- The approach could extend to multi-object scenes if the organization mechanism is augmented with inter-object separation terms.
Load-bearing premise
Geometric primitives provide a stable enough representation to segment parts and recover joint parameters accurately even when occlusions, rapid camera motion, and weak features make point tracking unreliable.
What would settle it
If joint parameters recovered on the AiP-real benchmark videos deviate substantially from known ground-truth kinematics under documented heavy occlusions, the claim that primitives serve as a reliable proxy would not hold.
Figures









read the original abstract
Retrieving the 3D kinematics of articulated objects from monocular video is a fundamental challenge in computer vision. Existing methods rely on complex video setups or cues such as long-term point tracking or wide-baseline matching, but are frequently brittle under severe occlusions, rapid camera ego-motion, or weak local features. Learning-based methods, meanwhile, struggle to generalize beyond their training categories. We propose a category-agnostic optimization framework that treats articulated object understanding as a primitive-fitting problem. Geometric primitives serve as a proxy representation that avoids the pitfalls of unstable point tracks; a novel mechanism organizes them into coherent parts constrained by revolute and prismatic joints. Our formulation jointly optimizes part segmentation and joint parameters, recovering complex kinematics from a single casually captured video. A visibility-aware procedure handles partial observations and occlusions inherent to real-world data. We also propose the AiP-synth and AiP-real benchmarks, featuring significant camera motion and heavy occlusions, and outperform existing methods. Project page: https://aartykov.github.io/Articulation-in-Prime/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a category-agnostic optimization framework for recovering 3D kinematics of articulated objects from a single casually captured monocular video. Geometric primitives act as proxy representations for object parts; these are organized into coherent rigid bodies connected by revolute or prismatic joints. A visibility-aware energy jointly optimizes primitive parameters, part segmentation, and joint axes while handling occlusions and ego-motion. New AiP-synth and AiP-real benchmarks are introduced, and the method is reported to outperform prior approaches on them.
Significance. If the optimization is shown to be well-constrained and robust, the primitive-proxy formulation would constitute a useful alternative to point-tracking or learning-based pipelines for articulated-object understanding, especially under severe occlusions and rapid camera motion. The creation of dedicated benchmarks that emphasize these challenging conditions is a concrete contribution that future work can build upon.
major comments (2)
- [§4] §4 (Optimization Framework) and the visibility-aware energy: the central claim that primitives simultaneously yield stable segmentation and kinematics rests on the assumption that the energy supplies enough independent constraints to disentangle per-primitive 3D pose/scale, part assignment, and joint-axis parameters while the camera trajectory remains free. The manuscript should provide an explicit analysis or ablation showing that the formulation avoids degenerate solutions (e.g., axis flips or part swaps) under rapid ego-motion; without such analysis the joint-optimization claim remains under-supported.
- [Experiments] Experiments section, benchmark tables: the reported outperformance on AiP-synth and AiP-real is presented without error bars, multiple random initializations, or sensitivity analysis. Given the skeptic concern about initialization dependence, the absence of these statistics makes it impossible to judge whether the quantitative gains are reliable or merely reflect favorable starting points.
minor comments (2)
- [Abstract] The abstract and method overview use the term “visibility-aware procedure” without a forward reference to the precise equation or subsection that defines the visibility term.
- [§3] Notation for primitive parameters (pose, scale, axis) should be collected in a single table or paragraph early in the method section to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and have revised the manuscript to strengthen the supporting analysis and experimental reporting.
read point-by-point responses
-
Referee: [§4] §4 (Optimization Framework) and the visibility-aware energy: the central claim that primitives simultaneously yield stable segmentation and kinematics rests on the assumption that the energy supplies enough independent constraints to disentangle per-primitive 3D pose/scale, part assignment, and joint-axis parameters while the camera trajectory remains free. The manuscript should provide an explicit analysis or ablation showing that the formulation avoids degenerate solutions (e.g., axis flips or part swaps) under rapid ego-motion; without such analysis the joint-optimization claim remains under-supported.
Authors: We appreciate the referee highlighting the need for explicit validation of non-degeneracy. The visibility-aware energy, combined with primitive geometric constraints and revolute/prismatic joint regularization, supplies cross-frame consistency that discourages axis flips and part swaps even under free camera motion. Our AiP benchmarks already contain sequences with rapid ego-motion and heavy occlusions, and the reported results exhibit stable kinematics without observed degeneracies. To make this explicit, we have added a targeted ablation in the revised Section 4.3 that perturbs camera trajectories and initializations, confirming that the recovered axes and part assignments remain consistent. revision: yes
-
Referee: [Experiments] Experiments section, benchmark tables: the reported outperformance on AiP-synth and AiP-real is presented without error bars, multiple random initializations, or sensitivity analysis. Given the skeptic concern about initialization dependence, the absence of these statistics makes it impossible to judge whether the quantitative gains are reliable or merely reflect favorable starting points.
Authors: We agree that variability statistics are important for assessing optimization-based methods. Our pipeline employs a deterministic initialization from the first-frame primitive fit (Section 3.2), yet we recognize that reporting sensitivity strengthens the claims. In the revised manuscript we have augmented the Experiments section and tables with error bars over five random initializations per sequence as well as a sensitivity study on the visibility threshold and joint regularization weights, showing that the performance margins remain consistent. revision: yes
Circularity Check
No circularity: optimization framework is self-contained
full rationale
The paper describes a category-agnostic optimization procedure that fits geometric primitives to monocular video, then organizes them into parts via revolute/prismatic joint constraints while jointly solving for segmentation and kinematics. No step reduces a claimed result to its own inputs by definition, renames a fitted quantity as a prediction, or relies on a load-bearing self-citation whose content is itself unverified. The visibility-aware energy and benchmark comparisons are presented as external constraints and evaluations, keeping the derivation independent of the target outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Geometric primitives can serve as a proxy representation for articulated parts that enables stable optimization under occlusions and ego-motion
invented entities (2)
-
AiP-synth benchmark
no independent evidence
-
AiP-real benchmark
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a category-agnostic optimization framework that treats articulated object understanding as a primitive-fitting problem. Geometric primitives serve as a proxy representation...
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our formulation jointly optimizes part segmentation and joint parameters...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
In: International Conference for Learning Representations (2026)
Ai, H., Chang, W., Jiao, J., Leonardis, A., Ofek, E.: Articulation in Motion: Prior-free Part Mobility Analysis for Articulated Objects By Dynamic-Static Disentanglement. In: International Conference for Learning Representations (2026)
work page 2026
-
[2]
In: International Conference on Computer Vision Workshops (2025)
Artykov, A., Boittiaux, C., Lepetit, V .: Articulated Object Understanding from a Single Video Sequence. In: International Conference on Computer Vision Workshops (2025)
work page 2025
-
[3]
IEEE Computer graphics and Applications1(1), 11–23 (1981)
Barr, A.H.: Superquadrics and angle-preserving transformations. IEEE Computer graphics and Applications1(1), 11–23 (1981)
work page 1981
-
[4]
In: British Machine Vision Conference (2025)
Chao, J.J., Jiang, Q., Isler, V .: Part Segmentation and Motion Estimation for Articulated Objects with Dynamic 3D Gaussians. In: British Machine Vision Conference (2025)
work page 2025
-
[5]
arXiv preprint arXiv:2603.22102 (2026)
Dai, H., Fan, H., Zhang, H., Wu, D., Zhang, J., Dong, H.: Freeartgs: Articulated gaussian splatting under free-moving scenario. arXiv preprint arXiv:2603.22102 (2026)
-
[6]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Deng, B., Genova, K., Yazdani, S., Bouaziz, S., Hinton, G., Tagliasacchi, A.: Cvxnet: Learnable convex decomposition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 31–44 (2020)
work page 2020
-
[7]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Fedele, E., Sun, B., Guibas, L., Pollefeys, M., Engelmann, F.: Superdec: 3d scene decomposition with superquadrics primitives. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 24625–24635 (2025)
work page 2025
-
[8]
arXiv preprint arXiv:2512.09201 (2025)
Ganeshan, A., Gadelha, M., Groueix, T., Chen, Z., Chaudhuri, S., Kim, V ., Yifan, W., Ritchie, D.: Residual primitive fitting of 3d shapes with superfrusta. arXiv preprint arXiv:2512.09201 (2025)
-
[9]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Groueix, T., Fisher, M., Kim, V .G., Russell, B.C., Aubry, M.: A papier-mâché approach to learning 3d surface generation. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 216–224 (2018)
work page 2018
-
[10]
Huang, J., Zhou, Q., Rabeti, H., Korovko, A., Ling, H., Ren, X., Shen, T., Gao, J., Slepichev, D., Lin, C.H., Ren, J., Xie, K., Biswas, J., Leal-Taixe, L., Fidler, S.: ViPE: Video Pose Engine for 3D Geometric Perception. In: arXiv Preprint (2025)
work page 2025
-
[11]
In: Conference on Computer Vision and Pattern Recognition (2022)
Jiang, Z., Hsu, C.C., Zhu, Y .: Ditto: Building Digital Twins of Articulated Objects from Interaction. In: Conference on Computer Vision and Pattern Recognition (2022)
work page 2022
-
[12]
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3D Gaussian Splatting for Real-Time Radiance Field Rendering. In: ACM SIGGRAPH (2023)
work page 2023
-
[13]
Kerr, J., Kim, C.M., Wu, M., Yi, B., Wang, Q., Goldberg, K., Kanazawa, A.: Robot See Robot Do: Imitating Articulated Object Manipulation with Monocular 4D Reconstruction. In: CORL (2024)
work page 2024
-
[14]
In: International Confer- ence on Machine Learning (2015)
Kingma, D.P., Ba, J.: Adam: A Method for Stochastic Optimization. In: International Confer- ence on Machine Learning (2015)
work page 2015
-
[15]
ACM Transactions on Graphics39(6) (2020)
Laine, S., Hellsten, J., Karras, T., Seol, Y ., Lehtinen, J., Aila, T.: Modular primitives for high-performance differentiable rendering. ACM Transactions on Graphics39(6) (2020)
work page 2020
-
[16]
In: International Conference for Learning Representations (2024) 10
Le, L., Xie, J., Liang, W., Wang, H.J., Yang, Y ., Ma, Y .J., Vedder, K., Krishna, A., Jayaraman, D., Eaton, E.: Articulate-Anything: Automatic Modeling of Articulated Objects via a Vision- Language Foundation Model. In: International Conference for Learning Representations (2024) 10
work page 2024
-
[17]
In: Conference on Computer Vision and Pattern Recognition (2020)
Li, X., Wang, H., Yi, L., Guibas, L.J., Abbott, A.L., Song, S.: Category-Level Articulated Object Pose Estimation. In: Conference on Computer Vision and Pattern Recognition (2020)
work page 2020
-
[18]
In: International Conference on Computer Vision (2023)
Liu, J., Mahdavi-Amiri, A., Savva, M.: Paris: Part-Level Reconstruction and Motion Analysis for Articulated Objects. In: International Conference on Computer Vision (2023)
work page 2023
-
[19]
In: Conference on Computer Vision and Pattern Recognition (2023)
Liu, S., Gupta, S., Wang, S.: Building Rearticulable Models for Arbitrary 3D Objects from 4D Point Clouds. In: Conference on Computer Vision and Pattern Recognition (2023)
work page 2023
-
[20]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, W., Wu, Y ., Ruan, S., Chirikjian, G.S.: Robust and accurate superquadric recovery: A probabilistic approach. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2676–2685 (2022)
work page 2022
-
[21]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liu, W., Wu, Y ., Ruan, S., Chirikjian, G.S.: Marching-primitives: Shape abstraction from signed distance function. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8771–8780 (2023)
work page 2023
-
[22]
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. In: ECCV (2020)
work page 2020
-
[23]
In: Conference on Computer Vision and Pattern Recognition (2019)
Mo, K., Zhu, S., Chang, A.X., Yi, L., Tripathi, S., Guibas, L.J., Su, H.: PartNet: A Large- Scale Benchmark for Fine-Grained and Hierarchical Part-Level 3D Object Understanding. In: Conference on Computer Vision and Pattern Recognition (2019)
work page 2019
-
[24]
Advances in Neural Information Processing Systems36, 5791–5807 (2023)
Monnier, T., Austin, J., Kanazawa, A., Efros, A., Aubry, M.: Differentiable blocks world: Qual- itative 3d decomposition by rendering primitives. Advances in Neural Information Processing Systems36, 5791–5807 (2023)
work page 2023
-
[25]
In: International Conference on Computer Vision (2021)
Mu, J., Qiu, W., Kortylewski, A., Yuille, A., Vasconcelos, N., Wang, X.: A-SDF: Learning Disentangled Signed Distance Functions for Articulated Shape Representation. In: International Conference on Computer Vision (2021)
work page 2021
-
[26]
In: Conference on Computer Vision and Pattern Recognition (2022)
Noguchi, A., Iqbal, U., Tremblay, J., Harada, T., Gallo, O.: Watch It Move: Unsupervised Discovery of 3D Joints for Re-Posing of Articulated Objects. In: Conference on Computer Vision and Pattern Recognition (2022)
work page 2022
-
[27]
In: International Conference on Robotics and Automa- tion (2023)
Ota, K., Tung, H.Y ., Smith, K.A., Cherian, A., Marks, T.K., Sullivan, A., Kanezaki, A., Tenen- baum, J.B.: H-SAUR: Hypothesize, Simulate, Act, Update, and Repeat for Understanding Object Articulations from Interactions. In: International Conference on Robotics and Automa- tion (2023)
work page 2023
-
[28]
In: Conference on Computer Vision and Pattern Recognition (2019)
Park, J.J., Florence, P., Straub, J., Newcombe, R.A., Lovegrove, S.J.: DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation. In: Conference on Computer Vision and Pattern Recognition (2019)
work page 2019
-
[29]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Paschalidou, D., Katharopoulos, A., Geiger, A., Fidler, S.: Neural parts: Learning expressive 3d shape abstractions with invertible neural networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3204–3215 (2021)
work page 2021
-
[30]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Paschalidou, D., Ulusoy, A.O., Geiger, A.: Superquadrics revisited: Learning 3d shape parsing beyond cuboids. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10344–10353 (2019)
work page 2019
-
[31]
In: International Conference on 3D Vision (2026)
Peng, W., Lv, J., Lu, C., Savva, M.: iTACO: Interactable Digital Twins of Articulated Objects from Casually Captured RGBD Videos. In: International Conference on 3D Vision (2026)
work page 2026
-
[32]
Pilu, M., Fisher, R.B.: Equal-distance sampling of superellipse models (1995)
work page 1995
-
[33]
Ravi, N., Gabeur, V ., Hu, Y .T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., Mintun, E., Pan, J., Alwala, K.V ., Carion, N., Wu, C.Y ., Girshick, R., Dollár, P., Feichtenhofer, C.: SAM 2: Segment Anything in Images and Videos. In: arXiv Preprint (2024)
work page 2024
-
[34]
In: American Association for Artificial Intelligence Conference (2022) 11
Shi, Y ., Cao, X., Lu, F., Zhou, B.: P3-Net: Part Mobility Parsing from Point Cloud Sequences via Learning Explicit Point Correspondence. In: American Association for Artificial Intelligence Conference (2022) 11
work page 2022
-
[35]
In: Computer Graphics Forum (2021)
Shi, Y ., Cao, X., Zhou, B.: Self-Supervised Learning of Part Mobility from Point Cloud Sequence. In: Computer Graphics Forum (2021)
work page 2021
-
[36]
In: Conference on Computer Vision and Pattern Recognition (2024)
Song, C., Wei, J., Foo, C.S., Lin, G., Liu, F.: REACTO: Reconstructing Articulated Objects from a Single Video. In: Conference on Computer Vision and Pattern Recognition (2024)
work page 2024
-
[37]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Tulsiani, S., Su, H., Guibas, L.J., Efros, A.A., Malik, J.: Learning shape abstractions by assembling volumetric primitives. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2635–2643 (2017)
work page 2017
-
[38]
IEEE Transactions on Pattern Analysis and Machine Intelligence41(1), 220–233 (2019)
Vaskevicius, N., Birk, A.: Revisiting superquadric fitting: A numerically stable formulation. IEEE Transactions on Pattern Analysis and Machine Intelligence41(1), 220–233 (2019)
work page 2019
-
[39]
In: Conference on Computer Vision and Pattern Recognition (2019)
Wang, H., Sridhar, S., Huang, J., Valentin, J., Song, S., Guibas, L.J.: Normalized Object Coordinate Space for Category-Level 6D Object Pose and Size Estimation. In: Conference on Computer Vision and Pattern Recognition (2019)
work page 2019
-
[40]
In: International Conference on Computer Vision (2021)
Weng, Y ., Wang, H., Zhou, Q., Qin, Y ., Duan, Y ., Fan, Q., Chen, B., Su, H., Guibas, L.J.: CAPTRA: CAtegory-level Pose Tracking for Rigid and Articulated Objects from Point Clouds. In: International Conference on Computer Vision (2021)
work page 2021
-
[41]
In: Conference on Computer Vision and Pattern Recognition (2024)
Weng, Y ., Wen, B., Tremblay, J., Blukis, V ., Fox, D., Guibas, L., Birchfield, S.: Neural Implicit Representation for Building Digital Twins of Unknown Articulated Objects. In: Conference on Computer Vision and Pattern Recognition (2024)
work page 2024
-
[42]
Werby, A., Buechner, M., Roefer, A., Huang, C., Burgard, W., Valada, A.: Articulated Object Estimation in the Wild. In: CoRL (2025)
work page 2025
-
[43]
In: Advances in Neural Information Processing Systems (2025)
Wu, D., Liu, L., Linli, Z., Huang, A., Song, L., Yu, Q., Wu, Q., Lu, C.: Reartgs: Reconstructing and Generating Articulated Objects via 3D Gaussian Splatting with Geometric and Motion Constraints. In: Advances in Neural Information Processing Systems (2025)
work page 2025
-
[44]
In: Conference on Computer Vision and Pattern Recognition (2020)
Xiang, F., Qin, Y ., Mo, K., Xia, Y ., Zhu, H., Liu, F., Liu, M., Jiang, H., Yuan, Y ., Wang, H., Yi, L., Chang, A.X., Guibas, L.J., Su, H.: SAPIEN: A SimulAted Part-Based Interactive ENvironment. In: Conference on Computer Vision and Pattern Recognition (2020)
work page 2020
-
[45]
ACM Transactions On Graphics (TOG)40(4), 1–11 (2021)
Yang, K., Chen, X.: Unsupervised learning for cuboid shape abstraction via joint segmentation from point clouds. ACM Transactions On Graphics (TOG)40(4), 1–11 (2021)
work page 2021
-
[46]
In: Advances in Neural Information Processing Systems (2023)
Zhang, Y ., Edstedt, J., Wandt, B., Forssén, P.E., Magnusson, M., Felsberg, M.: GMSF: Global Matching Scene Flow. In: Advances in Neural Information Processing Systems (2023)
work page 2023
-
[47]
In: Advances in Neural Information Processing Systems (2023)
Zhong, J.X., Cheng, T.Y ., He, Y ., Lu, K., Zhou, K., Markham, A., Trigoni, N.: Multi-Body SE(3) Equivariance for Unsupervised Rigid Segmentation and Motion Estimation. In: Advances in Neural Information Processing Systems (2023)
work page 2023
-
[48]
Zhou, Y ., Barnes, C., Lu, J., Yang, J., Li, H.: On the continuity of rotation representations in neural networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5745–5753 (2019) 12 Appendix Articulation in Prime: Primitive-Based Articulated Object Understanding from a Single Casual Video A Superquadrics Superqu...
work page 2019
-
[49]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.