GEM-4D: Geometry-Enhanced Video World Models for Robot Manipulation
Pith reviewed 2026-05-25 05:32 UTC · model grok-4.3
The pith
Injecting dense 4D correspondence supervision into video world models preserves point-level motion consistency and raises real-world robot manipulation success from 61% to 81%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GEM-4D resolves the limitation of inconsistent point-level motion in video world models by distilling dense 4D correspondences from a pretrained geometry foundation model and injecting them as supervision during training of the video generative backbone. This enables joint capture of appearance and geometric structure while retaining a single-stream architecture with no additional inference cost. An inverse dynamics module converts the correspondence-consistent video rollouts into executable robot trajectories. The resulting model reaches state-of-the-art performance on video prediction and geometric consistency in both simulated and realistic settings and improves real-world manipulation成功率
What carries the argument
Dense 4D correspondence supervision distilled from a pretrained geometry foundation model and injected into the video generative backbone during training.
If this is right
- The model jointly captures appearance and geometric structure from the injected supervision.
- Single-stream design means generated videos incur no extra compute at inference time.
- Inverse dynamics module converts consistent video rollouts into executable trajectories for direct real-world and simulated use.
- Performance reaches state-of-the-art on video prediction and geometric consistency metrics across simulation and realistic scenarios.
- Real-world manipulation success rate increases from 61% to 81%.
Where Pith is reading between the lines
- The same correspondence supervision could be applied to other video-based planning domains such as navigation or object rearrangement where long-term point consistency matters.
- Because the architecture change is confined to training, the approach may transfer to existing video model checkpoints with modest additional training.
- If the geometry foundation model itself improves, GEM-4D performance would improve without any change to the video backbone.
- The method suggests that explicit geometric signals can substitute for architectural complexity when building world models for physical tasks.
Load-bearing premise
The dense 4D correspondences supply accurate, unbiased supervision that directly improves physical consistency for manipulation without introducing new failure modes.
What would settle it
Running GEM-4D and the baseline on the same manipulation tasks and measuring point drift in generated videos or end-to-end success rates; if GEM-4D shows equal or greater drift or lower success than 61%, the claim is falsified.
Figures




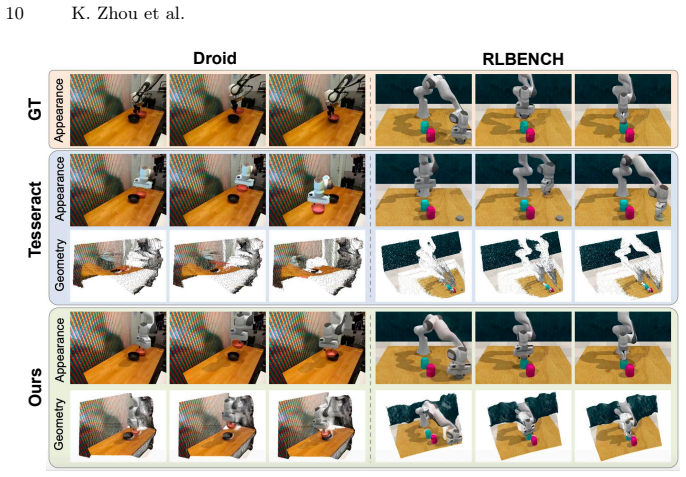
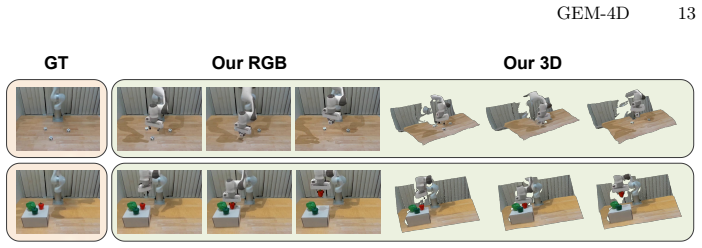
read the original abstract
Video world models can generate realistic futures from a single instruction, but they often fail to track the same physical points consistently across time. As a result, the generated videos appear plausible, yet lack the physical grounding required for reliable action execution, such as robot manipulation. We present GEM-4D, a geometry-grounded video world model that resolves this limitation by injecting dense 4D correspondence supervision distilled from a pretrained geometry foundation model into the video generative backbone during training. This supervision enables the model to jointly capture appearance and geometric structure while retaining a single-stream architecture with no additional inference cost. We further introduce an inverse dynamics module that converts correspondence-consistent video rollouts into executable robot trajectories, enabling direct deployment in both real-world and simulated manipulation. GEM-4D achieves state-of-the-art performance on both video prediction and geometric consistency across both simulation and realistic scenarios and improves real-world manipulation success from 61% to 81%. Additional results are available at https://gem-4d.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GEM-4D, a single-stream video world model that injects dense 4D correspondence supervision distilled from a pretrained geometry foundation model into the generative backbone. This supervision is intended to enforce point-level motion consistency and physical grounding without extra inference cost. An inverse dynamics module then maps the resulting correspondence-consistent video rollouts to executable robot actions. The manuscript reports state-of-the-art results on video prediction and geometric-consistency metrics across simulation and real scenarios, together with an improvement in real-world manipulation success rate from 61% to 81%.
Significance. If the reported gains hold under the experimental protocols detailed in the full manuscript, the work shows that external geometric supervision can measurably improve the downstream utility of video world models for manipulation while preserving architectural simplicity. The inclusion of ablations on the supervision signal and quantitative 3D point-tracking metrics provides concrete evidence that the geometric component contributes to the observed performance lift.
minor comments (2)
- [Abstract] Abstract: the headline performance numbers (61% to 81% success) are presented without any mention of trial count, baseline methods, or statistical tests; a one-sentence summary of the evaluation protocol would improve readability.
- The manuscript should explicitly state the precise form of the 4D correspondence loss (e.g., whether it is an L2 distance on 3D points or a reprojection error) and its weighting relative to the standard video-generation objective.
Simulated Author's Rebuttal
We thank the referee for their positive evaluation of GEM-4D and the recommendation for minor revision. We are encouraged that the role of 4D correspondence supervision in improving geometric consistency and downstream manipulation performance is recognized.
Circularity Check
No significant circularity detected
full rationale
The paper's core contribution injects dense 4D correspondence supervision distilled from an external pretrained geometry foundation model into the video generative backbone. This supervision source is independent of the target model and its outputs. The inverse dynamics module is presented as an additional component that converts the resulting rollouts into trajectories. No equations or claims reduce by construction to fitted parameters, self-definitions, or load-bearing self-citations; empirical ablations and real-world success rates are reported as external validation rather than tautological results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A pretrained geometry foundation model produces dense 4D correspondences that are accurate enough to supervise physical motion in manipulation videos.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.