Not All Transitions Matter: Evidence from PPO
Pith reviewed 2026-06-30 15:47 UTC · model grok-4.3
The pith
Randomly dropping a fixed fraction of transitions from PPO rollouts breaks repetitive gradients and stabilizes training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
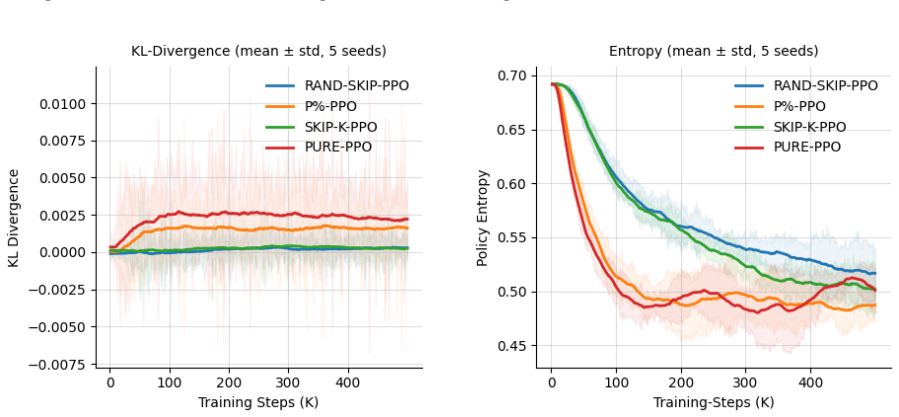
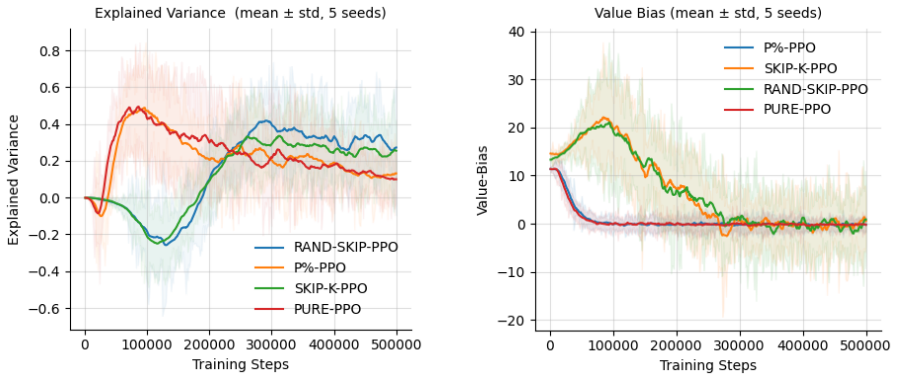
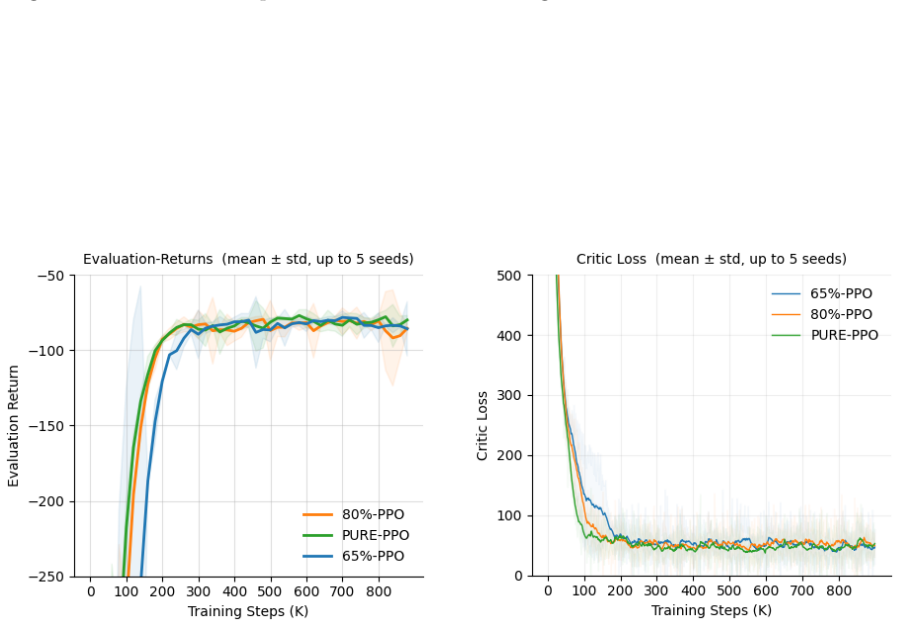
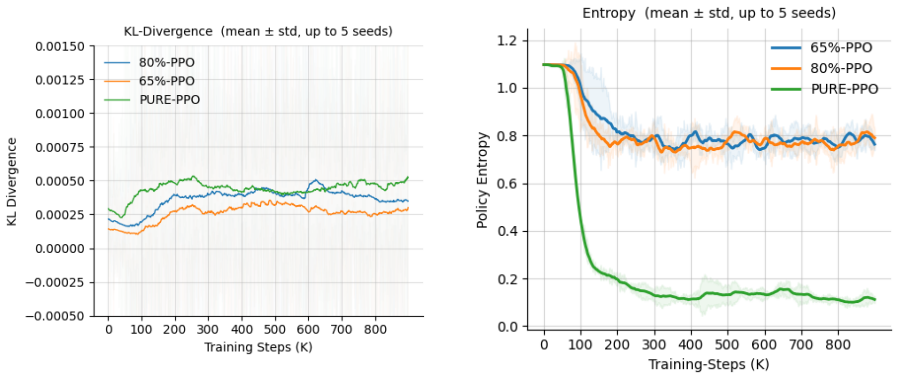
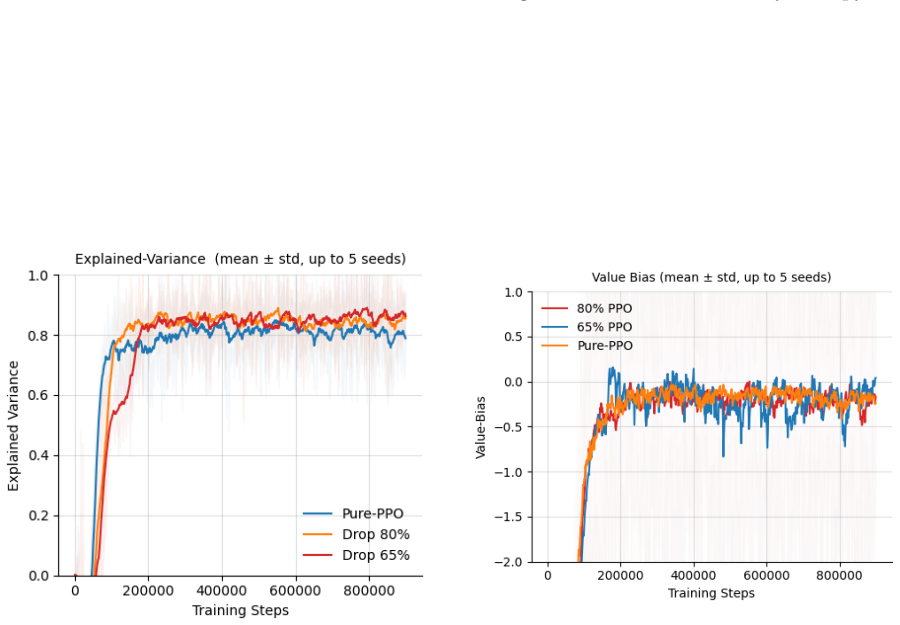
The authors establish that the primary instability in PPO arises from repetitive gradient signals due to consecutive transitions being outputs of prior states via agent actions. Randomly dropping a fixed fraction of transitions from the rollout at the stage that keeps rewards intact disrupts this structure sufficiently to stabilize training dynamics. This minimal modification matches the reward performance of unmodified PPO while yielding more consistent values for KL divergence, policy entropy, and value estimates across the five environments, with 25 percent dropping as the effective rate.
What carries the argument
Random dropping of a fixed fraction of transitions from the rollout buffer, performed to interrupt causal chaining while preserving reward information.
If this is right
- The modified training matches vanilla PPO on final reward across all tested environments.
- Metrics of training consistency improve for KL divergence, policy entropy, and value estimates.
- A 25 percent drop rate disrupts redundancy without thinning the batch too far.
- The change requires no new components and works inside any existing PPO implementation.
- The benefit appears in environments that range from simple discrete control to continuous physics tasks.
Where Pith is reading between the lines
- The same random subsampling step could be tested inside other on-policy algorithms that collect fresh rollouts each update.
- Adaptive versions might vary the drop rate with rollout length or observed gradient repetition.
- The result indicates that transitions collected in a single rollout are not equally necessary for stable updates.
- Longer-horizon tasks might show larger stability gains because chaining effects accumulate over more steps.
Load-bearing premise
The assumption that repetitive gradients from causally chained consecutive transitions are the main source of instability, and that random dropping removes redundancy without introducing selection bias or altering effective batch statistics.
What would settle it
A side-by-side experiment in which the variance of KL divergence or value loss across multiple runs stays the same when transitions are randomly dropped versus when the full chained rollout is used.
Figures










read the original abstract
Training a reinforcement learning agent on-policy means collecting fresh experience at every update, and that experience comes with a hidden problem. Each state in a rollout is the direct output of the previous one, causally chained together by the agent's own actions. Because of this, consecutive transitions are never truly independent. They carry overlapping information, and the gradient signal the network receives ends up far more repetitive than the batch size suggests. The same directions get reinforced over and over, the value network struggles to keep up as the policy shifts, and training becomes quietly unstable in ways that reward curves alone rarely reveal. This paper asks whether that redundancy can simply be removed. We show that randomly dropping a fixed fraction of transitions from the rollout, at the right stage so the reward signal stays intact, is enough to break the repetitive gradient structure and stabilize training. The change is minimal: one sampling step, no new components, no modification to the core algorithm, and it works with any PPO implementation. Across five environments of increasing difficulty, CartPole-v1, Acrobot-v1, LunarLander-v2, HalfCheetah-v5, and Hopper-v5, the method matches vanilla PPO on reward while producing more consistent training dynamics across KL divergence, policy entropy, and value estimates. Dropping 25% of transitions turns out to be the sweet spot: enough to disrupt the redundancy, not enough to thin the batch.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that randomly dropping a fixed fraction (25%) of transitions from on-policy PPO rollouts, performed at a stage that preserves the reward signal, reduces repetitive gradient signals arising from causally chained consecutive states. This minimal change is reported to stabilize training dynamics (more consistent KL divergence, policy entropy, and value estimates) while matching the reward performance of vanilla PPO across five environments of increasing difficulty (CartPole-v1, Acrobot-v1, LunarLander-v2, HalfCheetah-v5, Hopper-v5).
Significance. If substantiated with direct evidence for the proposed mechanism, the intervention would constitute a simple, algorithm-agnostic regularization step that could improve training consistency in on-policy methods without added components or hyperparameter tuning. The work correctly identifies a potential source of redundancy in rollouts and demonstrates that reward curves alone are insufficient to diagnose stability; however, the current results do not yet distinguish the claimed gradient-repetition effect from plausible alternatives such as implicit batch-size regularization.
major comments (3)
- [Abstract/Results] Abstract and Results sections: the claims of 'more consistent training dynamics' across KL, entropy, and value estimates are presented without statistical tests, standard errors, or the number of independent seeds/runs, so it is not possible to assess whether the observed consistency exceeds what would be expected from reduced effective batch size alone.
- [Method/Experiments] Method and Experiments: no direct measurements (gradient cosine similarity between consecutive transitions, advantage correlation, or pre/post-drop batch statistics) are reported to test the central mechanistic claim that random dropping specifically breaks repetitive gradient structure rather than acting through selection bias, changed GAE variance, or surrogate-objective regularization.
- [Experiments] Experiments: the exact timing and implementation of the dropout step ('at the right stage so the reward signal stays intact') is described only at a high level; without pseudocode or precise specification of whether dropout occurs before or after advantage estimation, it is difficult to reproduce or rule out stage-dependent bias in the reported consistency gains.
minor comments (2)
- The environments are given with specific versions; the manuscript should explicitly state the Gym/Gymnasium version and confirm that all runs use identical environment seeds for fair comparison.
- Figure captions or legends should clarify whether the plotted traces are single runs or aggregated, and whether the 'sweet spot' of 25% was determined via a grid search whose results are shown.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below, agreeing where revisions are warranted to improve statistical rigor and reproducibility while noting limitations on direct mechanistic evidence.
read point-by-point responses
-
Referee: [Abstract/Results] Abstract and Results sections: the claims of 'more consistent training dynamics' across KL, entropy, and value estimates are presented without statistical tests, standard errors, or the number of independent seeds/runs, so it is not possible to assess whether the observed consistency exceeds what would be expected from reduced effective batch size alone.
Authors: We agree that statistical support is required to substantiate claims of improved consistency. The experiments used 5 independent random seeds per environment. In the revised manuscript we will report this explicitly, add standard error shading to all relevant plots (KL, entropy, value loss), and include statistical tests (e.g., Levene's test for variance equality and paired t-tests on per-seed consistency metrics) to show that gains exceed those expected from batch-size reduction alone. revision: yes
-
Referee: [Method/Experiments] Method and Experiments: no direct measurements (gradient cosine similarity between consecutive transitions, advantage correlation, or pre/post-drop batch statistics) are reported to test the central mechanistic claim that random dropping specifically breaks repetitive gradient structure rather than acting through selection bias, changed GAE variance, or surrogate-objective regularization.
Authors: We acknowledge that the absence of direct measurements (gradient cosine similarity, advantage correlations) leaves the mechanistic claim open to alternative interpretations such as implicit batch-size effects. The current evidence is indirect via stability metrics. We will expand the discussion section to state this limitation explicitly and note that distinguishing the proposed gradient-repetition effect from other regularizing mechanisms would require additional targeted experiments not present in the original study. revision: partial
-
Referee: [Experiments] Experiments: the exact timing and implementation of the dropout step ('at the right stage so the reward signal stays intact') is described only at a high level; without pseudocode or precise specification of whether dropout occurs before or after advantage estimation, it is difficult to reproduce or rule out stage-dependent bias in the reported consistency gains.
Authors: We agree that precise implementation details are essential for reproducibility. Dropout is performed after full rollout collection (including rewards) but before GAE advantage estimation. We will add explicit pseudocode in the Methods section and a short paragraph clarifying the stage to eliminate ambiguity and allow readers to rule out stage-dependent bias. revision: yes
- The lack of direct mechanistic measurements (gradient cosine similarity, advantage correlations) to distinguish the claimed gradient-repetition effect from plausible alternatives such as implicit batch-size regularization.
Circularity Check
No circularity; empirical intervention with no derivation chain
full rationale
The paper advances an empirical intervention—randomly dropping a fixed fraction of rollout transitions—supported by experimental results on five environments showing matched rewards and more consistent KL/entropy/value traces. No equations, predictions, or uniqueness theorems are presented that reduce to fitted inputs, self-citations, or ansatzes by construction. The 25% drop rate is explicitly described as an observed sweet spot rather than a derived quantity, and the mechanistic account is offered as a hypothesis tested via outcomes rather than a self-referential proof. The derivation chain is therefore self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
free parameters (1)
- drop fraction =
0.25
axioms (1)
- domain assumption Consecutive transitions in on-policy rollouts are never truly independent and carry overlapping information that produces repetitive gradients.
Reference graph
Works this paper leans on
-
[1]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., & Klimov, O. (2017).Proximal Policy Optimization Algorithms. arXiv preprint arXiv:1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
S., & Barto, A
Sutton, R. S., & Barto, A. G. (2018).Reinforcement Learning: An Introduction(2nd ed.). MIT Press
2018
-
[3]
(2014).Dropout: A Simple Way to Prevent Neural Networks from Overfitting
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. (2014).Dropout: A Simple Way to Prevent Neural Networks from Overfitting. Journal of Machine Learning Research, 15(1), 1929–1958
2014
-
[4]
Queeney, J., Paschalidis, I. C., & Cassandras, C. G. (2021).Generalized Proximal Policy Optimization with Sample Reuse. arXiv preprint arXiv:2111.00072
-
[5]
(2021).PTR-PPO: Proximal Policy Optimization with Prioritized Trajectory Replay
Liang, X., Ma, Y., Feng, Y., & Liu, Z. (2021).PTR-PPO: Proximal Policy Optimization with Prioritized Trajectory Replay. arXiv preprint arXiv:2112.03798. 10
-
[6]
(2021).Phasic Policy Gradient
Cobbe, K., Hilton, J., Klimov, O., & Schulman, J. (2021).Phasic Policy Gradient. Proceedings of the 38th International Conference on Machine Learning (ICML)
2021
-
[7]
Corrado, N. E., & Hanna, J. P. (2023).On-Policy Policy Gradient Reinforcement Learning Without On-Policy Sampling. arXiv preprint arXiv:2311.08290
-
[8]
(2024).SAPG: Split and Aggregate Policy Gradients
Makoviychuk, V., et al. (2024).SAPG: Split and Aggregate Policy Gradients. arXiv preprint arXiv:2407.20230
-
[9]
(2024).Colored Noise in PPO: Improved Exploration and Performance through Correlated Action Sampling
Hollenstein, J., Martius, G., & Piater, J. (2024).Colored Noise in PPO: Improved Exploration and Performance through Correlated Action Sampling. Proceedings of the AAAI Conference on Artificial Intelligence. arXiv preprint arXiv:2312.11091
-
[10]
(2021).Action Redundancy in Reinforcement Learning
Tavakoli, A., Fatemi, M., & Kormushev, P. (2021).Action Redundancy in Reinforcement Learning. arXiv preprint arXiv:2102.11329. 11 Appendix: Experimental Results and Graphs All figures compare Vanilla PPO, Method 1 (Fixed K-Step), Method 2 (Random Adaptive K-Step), and Method 3 (Random p% Subsampling) across 1400 rollout steps per update. HalfCheetah-v5 an...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.