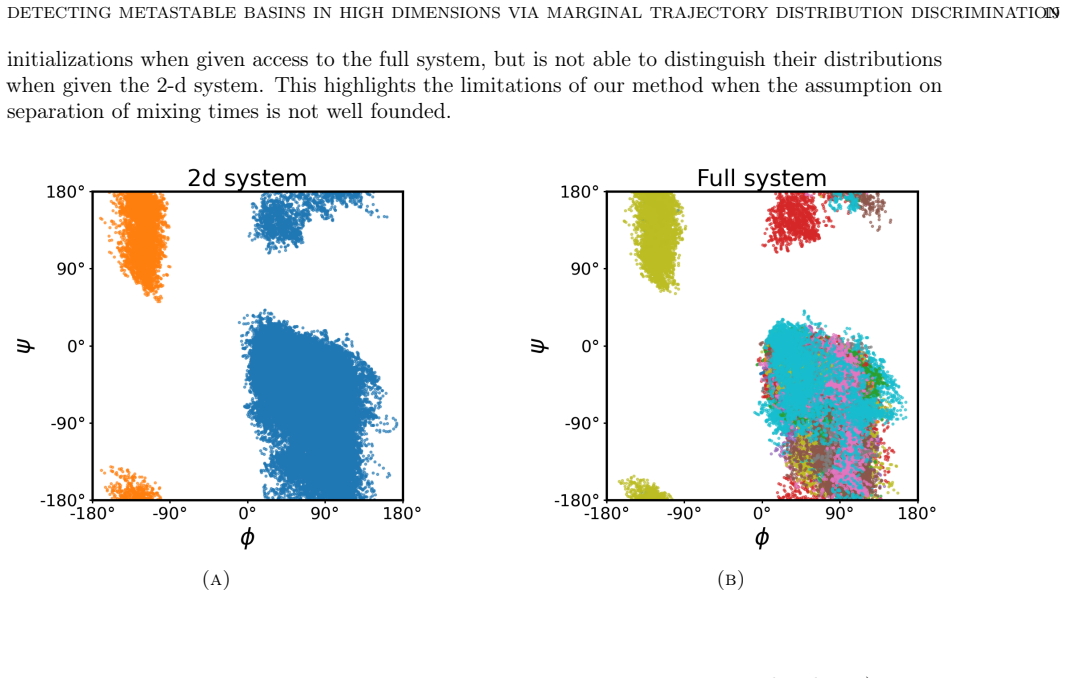
Detecting Metastable Basins in High Dimensions via Marginal Trajectory Distribution Discrimination
Pith reviewed 2026-06-30 14:56 UTC · model grok-4.3
The pith
Basin membership reduces to whether a Bayes classifier on marginal trajectory distributions achieves risk near 1/2 or near zero.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is a risk-separation result: for a time-homogeneous Markov process, if two initial states lie in the same basin then the Bayes risk of the optimal classifier between their marginal trajectory distributions approaches 1/2, whereas if the states lie in distinct basins the risk approaches zero. Basin detection is thereby reduced to estimating these risks with a neural network that approximates the Bayes classifier and iteratively merging candidate representatives whose estimated risk is near 1/2.
What carries the argument
The risk-separation theorem on marginal trajectory distributions, which converts basin detection into a sequence of two-sample classification problems solved by neural approximation of the Bayes classifier.
If this is right
- Spectral and spatial-discretization methods become unnecessary once trajectory discrimination is available.
- The procedure works on reducible processes where inter-basin transitions are arbitrarily rare on the sampling timescale.
- High-dimensional ambient noise does not destroy recoverability provided the low-dimensional basin dynamics remain embedded in the marginal distributions.
- Only a modest number of short trajectories per candidate representative is required once the neural classifier is trained.
Where Pith is reading between the lines
- Trajectory sampling alone may suffice for basin recovery without ever constructing an explicit transition operator.
- The same risk-separation idea could be tested on non-Markovian processes whose finite-time marginals still separate by basin.
- The number of trajectories needed for stable risk estimation may grow with ambient dimension in a manner independent of the intrinsic basin geometry.
Load-bearing premise
The neural network approximates the Bayes-optimal classifier closely enough that its estimated risk reliably signals whether two states belong to the same basin.
What would settle it
Apply the iterative merging procedure to a known metastable system with documented basins and observe whether points from different basins are merged or points from the same basin remain separate when the neural risk estimates deviate from the predicted separation.
Figures

read the original abstract
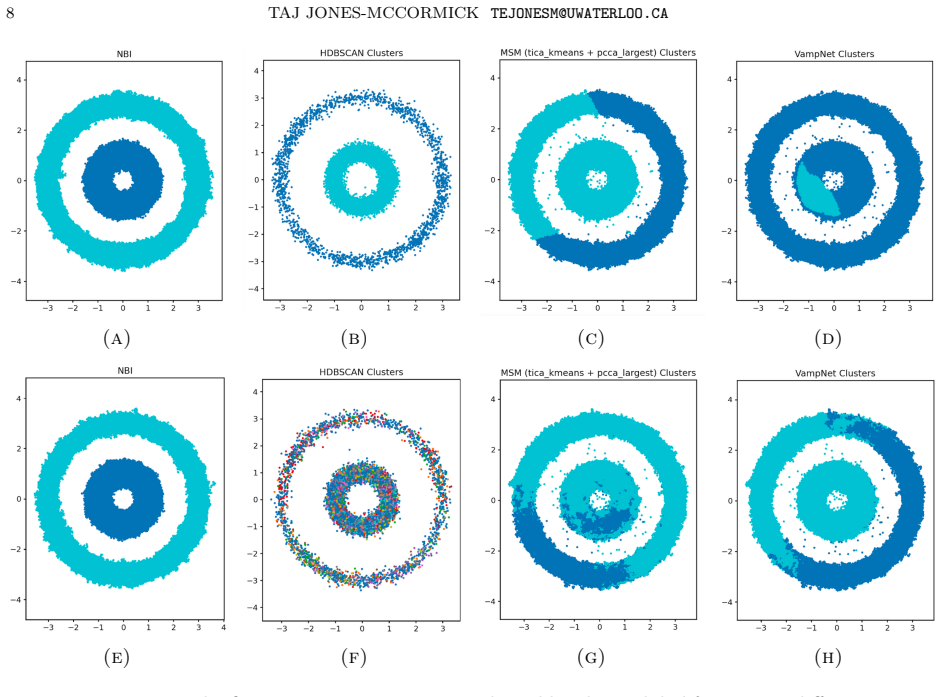
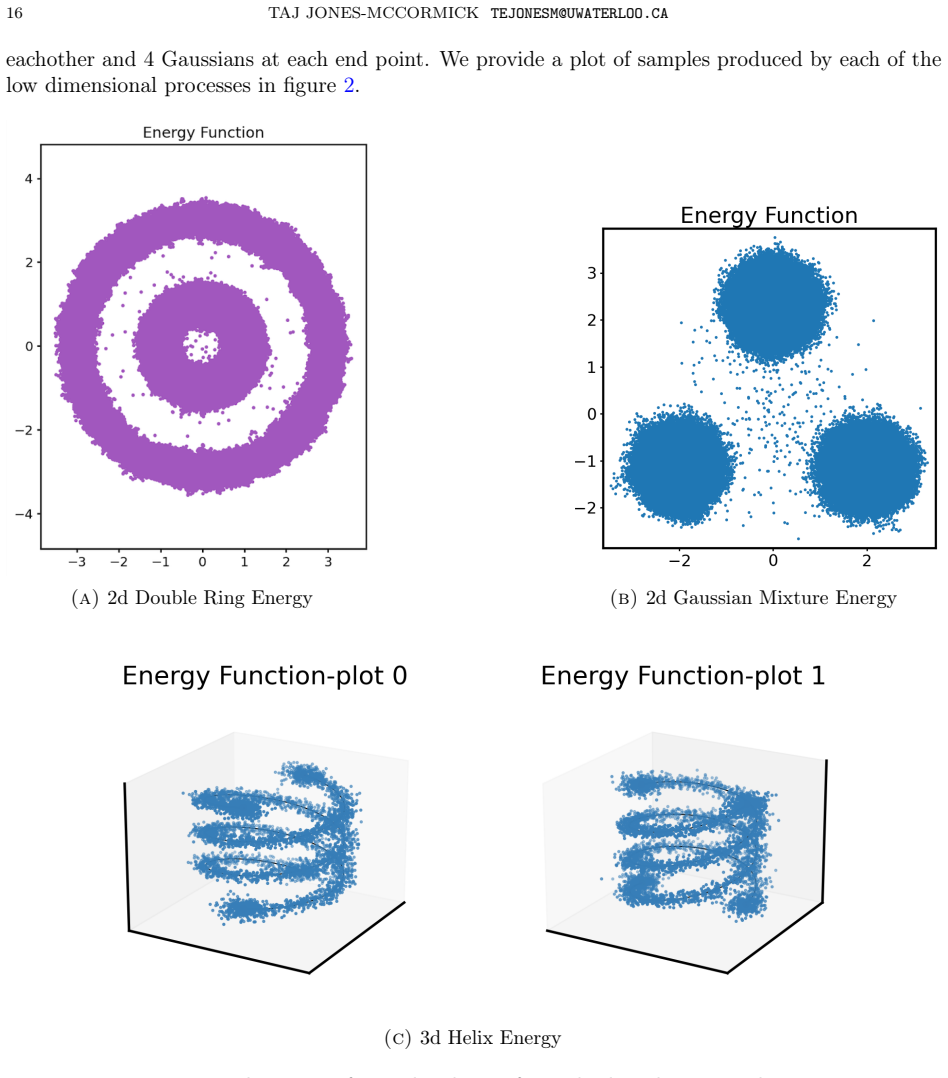
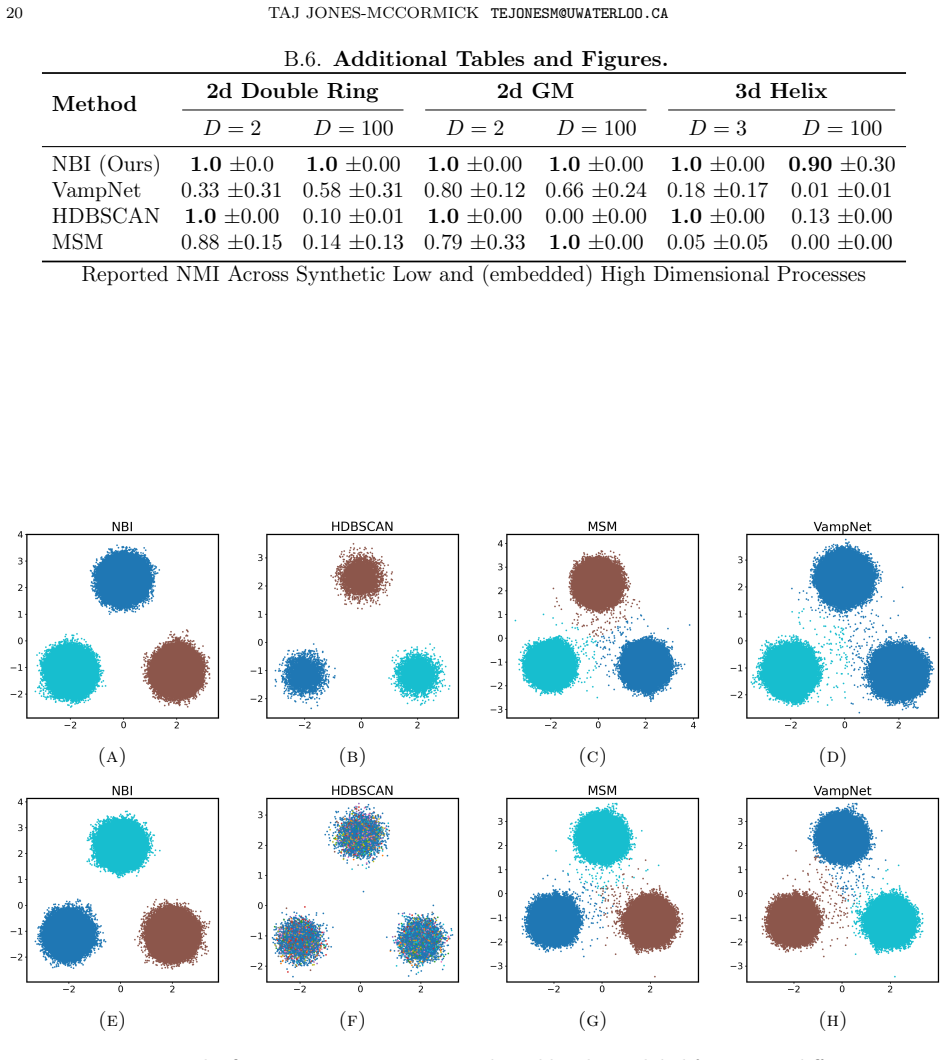
We study the problem of identifying dynamically distinct basins of attraction in high dimensional time-homogeneous Markov processes using only trajectory sampling. This problem is fundamental in the analysis of metastable dynamical systems, where the process rapidly mixes within basins while transitions between basins occur rarely on the timescale of interest, or even when the state space is reducible. Existing approaches typically rely on spatial discretization or spectral analysis of estimated transition operators, which can become unreliable in high dimensional settings or when the underlying basin geometry is highly nonlinear. We propose a discriminative approach to basin identification based on marginal trajectory distribution comparison. We prove a simple risk separation result: if two initial states belong to the same basin, the Bayes-optimal classifier distinguishing their marginal trajectory distributions achieves risk close to 1/2, whereas if they lie in distinct basins, the optimal risk is close to zero. This observation reduces basin detection to a two-sample discrimination problem between marginal trajectory distributions. Motivated by this principle, we develop a neural algorithm that receives a set of candidate basin representatives and iteratively merges them by estimating classification risk with a neural network that approximates the Bayes classifier. We evaluate the method on various metastable systems. These include synthetic systems constructed by embedding low-dimensional dynamics into high dimensional noisy ambient spaces. In these settings, standard spectral and clustering-based methods often fail, while our approach accurately recovers the underlying basin structure. These results display a shortcoming of existing methods and highlight trajectory discrimination as an effective tool for identifying dynamical basins in high dimensional stochastic systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that metastable basins in high-dimensional time-homogeneous Markov processes can be identified from trajectory samples alone by proving a risk-separation result: the Bayes-optimal classifier on marginal trajectory distributions from same-basin initial states has risk near 1/2, while distinct-basin states yield risk near 0. This reduces basin detection to iterative two-sample discrimination, implemented via a neural network that approximates the Bayes classifier to estimate risk and merge candidate representatives. The approach is shown to recover basin structure on synthetic embeddings of low-dimensional dynamics into high-dimensional noisy spaces, where spectral and clustering baselines fail.
Significance. If the separation theorem holds and the neural estimator reliably tracks the true Bayes risk, the work supplies a mathematically grounded alternative to discretization or spectral methods that degrade in high dimensions or with nonlinear basin geometry. Credit is due for the clean risk-separation statement and for the reproducible synthetic experiments that isolate the failure modes of existing techniques. The significance is limited by the absence of approximation-error controls, which directly affects whether the empirical success generalizes beyond the tested synthetics.
major comments (2)
- [§3] §3 (Risk separation theorem and algorithm): The central reduction to two-sample discrimination is load-bearing, yet the manuscript provides no quantitative bound on the neural-network approximation error to the Bayes classifier. In high ambient dimension this gap can be large even when the true marginals are separable, rendering the estimated risk unreliable for the iterative merge decisions; the synthetic experiments do not isolate or bound this gap.
- [§4] §4 (Experimental evaluation): The reported recovery of basin structure on embedded low-dimensional systems is encouraging, but the controls do not include ablations that vary network capacity or training schedule while holding the true marginal separation fixed; without such controls it is impossible to attribute success to the risk-separation principle rather than to favorable approximation behavior on the chosen synthetics.
minor comments (2)
- [§2] Notation for marginal trajectory distributions is introduced without an explicit equation reference; adding a displayed definition would improve traceability to the risk-separation claim.
- [§4] Figure captions for the synthetic embeddings should state the ambient dimension and noise level explicitly rather than referring only to 'high-dimensional' settings.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the value of the risk-separation result. We address each major comment below and outline planned revisions.
read point-by-point responses
-
Referee: [§3] §3 (Risk separation theorem and algorithm): The central reduction to two-sample discrimination is load-bearing, yet the manuscript provides no quantitative bound on the neural-network approximation error to the Bayes classifier. In high ambient dimension this gap can be large even when the true marginals are separable, rendering the estimated risk unreliable for the iterative merge decisions; the synthetic experiments do not isolate or bound this gap.
Authors: We agree that the manuscript provides no quantitative bounds on the approximation error between the neural network and the Bayes classifier. The risk-separation theorem applies to the true Bayes risk (near 1/2 for same-basin states and near 0 for distinct basins), while the algorithm relies on a neural approximation whose error is uncontrolled in the current text. This is a genuine limitation for claiming reliability of the iterative merge procedure in arbitrary high-dimensional settings. In the revised manuscript we will add an explicit discussion of this gap, including a statement that the empirical success on the tested synthetics does not yet guarantee performance when the approximation error is large, and we will include a brief analysis of how the estimated risk behaves under increasing network capacity on the same embedded systems. revision: yes
-
Referee: [§4] §4 (Experimental evaluation): The reported recovery of basin structure on embedded low-dimensional systems is encouraging, but the controls do not include ablations that vary network capacity or training schedule while holding the true marginal separation fixed; without such controls it is impossible to attribute success to the risk-separation principle rather than to favorable approximation behavior on the chosen synthetics.
Authors: We concur that the current experiments lack ablations that vary network capacity or training schedule while keeping the underlying marginal separation fixed. Such controls are necessary to separate the contribution of the theoretical risk-separation principle from favorable approximation properties on the specific synthetics. In the revision we will add these ablations: for each embedded system we will train networks of varying width and depth (and with different training schedules) on the same trajectory data, report the resulting estimated risks and final merge decisions, and compare against the known ground-truth basin structure. This will provide direct evidence on the sensitivity of the procedure to approximation quality. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper's core step is a mathematical risk-separation claim derived from the definitions of basins and marginal trajectory distributions under time-homogeneous Markov dynamics; this is a direct probabilistic argument (same-basin states yield overlapping marginals, distinct basins yield separable ones) that does not reduce to any fitted parameter, self-citation, or ansatz imported from prior work by the same author. The subsequent neural approximation is explicitly described as an estimator of the Bayes risk rather than part of the theorem itself, and no equation or claim equates the output to its inputs by construction. The method is therefore not circular.
Axiom & Free-Parameter Ledger
free parameters (1)
- Neural network architecture, optimizer, and training schedule
axioms (2)
- domain assumption The underlying process is a time-homogeneous Markov process
- domain assumption Rapid mixing occurs inside basins while transitions between basins are rare on the observation timescale
Reference graph
Works this paper leans on
-
[1]
Online stochastic gradient descent on non-convex losses from high-dimensional inference.Journal of Machine Learning Research, 22(106):1–51, 2021
Gerard Ben Arous, Reza Gheissari, and Aukosh Jagannath. Online stochastic gradient descent on non-convex losses from high-dimensional inference.Journal of Machine Learning Research, 22(106):1–51, 2021
2021
-
[2]
Springer Science & Business Media, 2013
Gregory R Bowman, Vijay S Pande, and Frank Noé.An introduction to Markov state models and their application to long timescale molecular simulation. Springer Science & Business Media, 2013
2013
-
[3]
siamese
Jane Bromley, Isabelle Guyon, Yann LeCun, Eduard Säckinger, and Roopak Shah. Signature verification using a" siamese" time delay neural network.Advances in neural information processing systems, 6, 1993
1993
-
[4]
CRC press, 2011
Steve Brooks, Andrew Gelman, Galin Jones, and Xiao-Li Meng.Handbook of markov chain monte carlo. CRC press, 2011
2011
-
[5]
Exploration by Random Network Distillation
Yuri Burda, Harrison Edwards, Amos Storkey, and Oleg Klimov. Exploration by random network distillation.arXiv preprint arXiv:1810.12894, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Hierarchical density estimates for data clustering, visualization, and outlier detection.ACM Transactions on Knowledge Discovery from Data (TKDD), 10(1):1–51, 2015
Ricardo JGB Campello, Davoud Moulavi, Arthur Zimek, and Jörg Sander. Hierarchical density estimates for data clustering, visualization, and outlier detection.ACM Transactions on Knowledge Discovery from Data (TKDD), 10(1):1–51, 2015
2015
-
[7]
Diffusion maps.Applied and computational harmonic analysis, 21(1):5–30, 2006
Ronald R Coifman and Stéphane Lafon. Diffusion maps.Applied and computational harmonic analysis, 21(1):5–30, 2006
2006
-
[8]
Identification of almost invariant aggregates in reversible nearly uncoupled markov chains.Linear Algebra and its Applications, 315(1-3):39–59, 2000
Peter Deuflhard, Wilhelm Huisinga, Alexander Fischer, and Ch Schütte. Identification of almost invariant aggregates in reversible nearly uncoupled markov chains.Linear Algebra and its Applications, 315(1-3):39–59, 2000
2000
-
[9]
Robust perron cluster analysis in conformation dynamics
Peter Deuflhard and Marcus Weber. Robust perron cluster analysis in conformation dynamics. Linear algebra and its applications, 398:161–184, 2005
2005
-
[10]
Openmm 8: molecular dynamics simulation with machine learning potentials.The Journal of Physical Chemistry B, 128(1):109–116, 2023
Peter Eastman, Raimondas Galvelis, Raúl P Peláez, Charlles RA Abreu, Stephen E Farr, Emilio Gallicchio, Anton Gorenko, Michael M Henry, Frank Hu, Jing Huang, et al. Openmm 8: molecular dynamics simulation with machine learning potentials.The Journal of Physical Chemistry B, 128(1):109–116, 2023
2023
-
[11]
A density-based algorithm for discovering clusters in large spatial databases with noise
Martin Ester, Hans-Peter Kriegel, Jörg Sander, Xiaowei Xu, et al. A density-based algorithm for discovering clusters in large spatial databases with noise. Inkdd, volume 96, pages 226–231, 1996
1996
-
[12]
Verso Books, 2020
Emmanuel Farjoun and Moshe Machover.Laws of Chaos: A probabilistic approach to political economy. Verso Books, 2020
2020
-
[13]
An analytic framework for identifying finite-time coherent sets in time-dependent dynamical systems.Physica D: Nonlinear Phenomena, 250:1–19, 2013
Gary Froyland. An analytic framework for identifying finite-time coherent sets in time-dependent dynamical systems.Physica D: Nonlinear Phenomena, 250:1–19, 2013
2013
-
[14]
Deep sparse rectifier neural networks
Xavier Glorot, Antoine Bordes, and Yoshua Bengio. Deep sparse rectifier neural networks. In Proceedings of the fourteenth international conference on artificial intelligence and statistics, pages 315–323. JMLR Workshop and Conference Proceedings, 2011
2011
-
[15]
Dimensionality reduction by learning an invariant mapping
Raia Hadsell, Sumit Chopra, and Yann LeCun. Dimensionality reduction by learning an invariant mapping. In2006 IEEE computer society conference on computer vision and pattern recognition (CVPR’06), volume 2, pages 1735–1742. IEEE, 2006
2006
-
[16]
Comparing partitions.Journal of classification, 2(1):193– 218, 1985
Lawrence Hubert and Phipps Arabie. Comparing partitions.Journal of classification, 2(1):193– 218, 1985
1985
-
[17]
On gradient descent algorithm for generalized phase retrieval problem
Li Ji and Zhou Tie. On gradient descent algorithm for generalized phase retrieval problem. In 2016 IEEE 13th International Conference on Signal Processing (ICSP), pages 320–325. IEEE, 2016
2016
-
[18]
Hamiltonian systems and transformation in hilbert space.Proceedings of the National Academy of Sciences, 17(5):315–318, 1931
Bernard O Koopman. Hamiltonian systems and transformation in hilbert space.Proceedings of the National Academy of Sciences, 17(5):315–318, 1931. 12 TAJ JONES-MCCORMICKTEJONESM@UWATERLOO.CA
1931
-
[19]
Vampnets for deep learning of molecular kinetics.Nature communications, 9(1):5, 2018
Andreas Mardt, Luca Pasquali, Hao Wu, and Frank Noé. Vampnets for deep learning of molecular kinetics.Nature communications, 9(1):5, 2018
2018
-
[20]
Some methods of classification and analysis of multivariate observations
James B McQueen. Some methods of classification and analysis of multivariate observations. In Proc. of 5th Berkeley Symposium on Math. Stat. and Prob., pages 281–297, 1967
1967
-
[21]
Stochasticity helps to navigate rough landscapes: comparing gradient-descent-based algorithms in the phase retrieval problem
Francesca Mignacco, Pierfrancesco Urbani, and Lenka Zdeborová. Stochasticity helps to navigate rough landscapes: comparing gradient-descent-based algorithms in the phase retrieval problem. Machine Learning: Science and Technology, 2(3):035029, 2021
2021
-
[22]
On spectral clustering: Analysis and an algorithm
Andrew Ng, Michael Jordan, and Yair Weiss. On spectral clustering: Analysis and an algorithm. Advances in neural information processing systems, 14, 2001
2001
-
[23]
Kinetic distance and kinetic maps from molecular dynamics simulation.Journal of chemical theory and computation, 11(10):5002–5011, 2015
Frank Noé and Cecilia Clementi. Kinetic distance and kinetic maps from molecular dynamics simulation.Journal of chemical theory and computation, 11(10):5002–5011, 2015
2015
-
[24]
A variational approach to modeling slow processes in stochastic dynamical systems.Multiscale Modeling & Simulation, 11(2):635–655, 2013
Frank Noé and Feliks Nuske. A variational approach to modeling slow processes in stochastic dynamical systems.Multiscale Modeling & Simulation, 11(2):635–655, 2013
2013
-
[25]
Number 2
James R Norris.Markov chains. Number 2. Cambridge university press, 1998
1998
-
[26]
Characterizing metastable states with the help of machine learning.Journal of Chemical Theory and Computa- tion, 18(9):5195–5202, 2022
Pietro Novelli, Luigi Bonati, Massimiliano Pontil, and Michele Parrinello. Characterizing metastable states with the help of machine learning.Journal of Chemical Theory and Computa- tion, 18(9):5195–5202, 2022
2022
-
[27]
Identification of slow molecular order parameters for markov model construction.The Journal of chemical physics, 139(1), 2013
Guillermo Pérez-Hernández, Fabian Paul, Toni Giorgino, Gianni De Fabritiis, and Frank Noé. Identification of slow molecular order parameters for markov model construction.The Journal of chemical physics, 139(1), 2013
2013
-
[28]
Markov models of molecular kinetics: Generation and validation.The Journal of chemical physics, 134(17), 2011
Jan-Hendrik Prinz, Hao Wu, Marco Sarich, Bettina Keller, Martin Senne, Martin Held, John D Chodera, Christof Schütte, and Frank Noé. Markov models of molecular kinetics: Generation and validation.The Journal of chemical physics, 134(17), 2011
2011
-
[29]
Springer, 2004
Christian P Robert, George Casella, and George Casella.Monte Carlo statistical methods, volume 2. Springer, 2004
2004
-
[30]
Exponential convergence of langevin distributions and their discrete approximations
Gareth O Roberts and Richard L Tweedie. Exponential convergence of langevin distributions and their discrete approximations. 1996
1996
-
[31]
On the approximation quality of markov state models.Multiscale Modeling & Simulation, 8(4):1154–1177, 2010
Marco Sarich, Frank Noé, and Christof Schütte. On the approximation quality of markov state models.Multiscale Modeling & Simulation, 8(4):1154–1177, 2010
2010
-
[32]
Springer Science & Business Media, 2006
Eugene Seneta.Non-negative matrices and Markov chains. Springer Science & Business Media, 2006
2006
-
[33]
World Scientific, 2010
Gabriel Stoltz, Mathias Rousset, et al.Free energy computations: A mathematical perspective. World Scientific, 2010
2010
-
[34]
Cluster ensembles—a knowledge reuse framework for combining multiple partitions.Journal of machine learning research, 3(Dec):583–617, 2002
Alexander Strehl and Joydeep Ghosh. Cluster ensembles—a knowledge reuse framework for combining multiple partitions.Journal of machine learning research, 3(Dec):583–617, 2002
2002
-
[35]
Yan Shuo Tan and Roman Vershynin. Online stochastic gradient descent with arbitrary initialization solves non-smooth, non-convex phase retrieval.arXiv preprint arXiv:1910.12837, 2019
-
[36]
Depth-first search and linear graph algorithms.SIAM journal on computing, 1(2):146–160, 1972
Robert Tarjan. Depth-first search and linear graph algorithms.SIAM journal on computing, 1(2):146–160, 1972
1972
-
[37]
Cambridge Molecular Science
David Wales.Energy Landscapes: Applications to Clusters, Biomolecules and Glasses. Cambridge Molecular Science. Cambridge University Press, 2004
2004
-
[38]
Variational koopman models: Slow collective variables and molecular kinetics from short off-equilibrium simulations.The Journal of chemical physics, 146(15), 2017
Hao Wu, Feliks Nüske, Fabian Paul, Stefan Klus, Péter Koltai, and Frank Noé. Variational koopman models: Slow collective variables and molecular kinetics from short off-equilibrium simulations.The Journal of chemical physics, 146(15), 2017. DETECTING METASTABLE BASINS IN HIGH DIMENSIONS VIA MARGINAL TRAJECTORY DISTRIBUTION DISCRIMINATION 13 AppendixA.Proo...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.