Understanding Conversational Patterns in Multi-agent Programming: A Case Study on Fibonacci Game Development
Pith reviewed 2026-06-30 14:54 UTC · model grok-4.3
The pith
Only the DeepSeek-R1 pair converges to the correct solution from the first iteration and sustains it in a two-agent Designer-Programmer setup.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
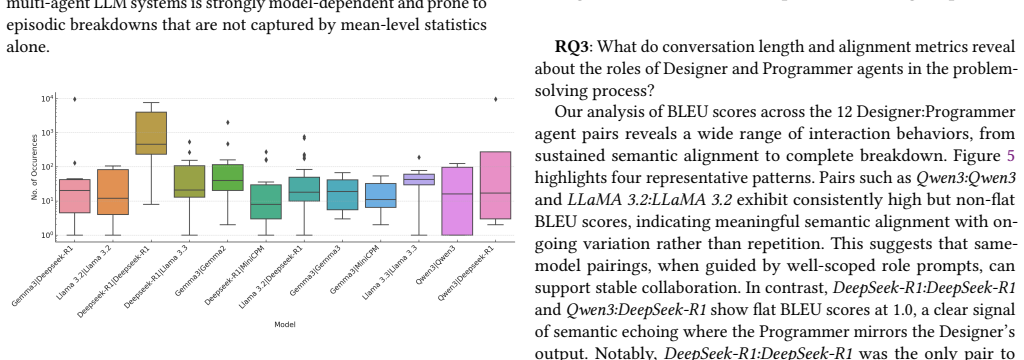
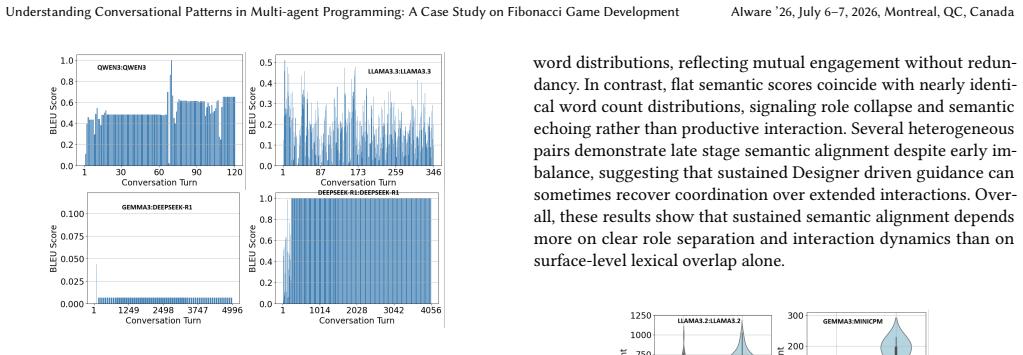
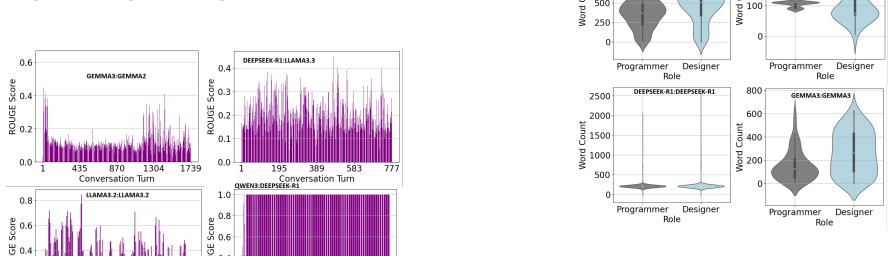
The DeepSeek-R1:DeepSeek-R1 pair was unique in converging to the correct solution from the very first iteration and sustaining it consistently to the final iteration, while LLaMA 3.2:LLaMA 3.2 and Qwen3:Qwen3 demonstrated strong Designer:Programmer role alignment despite diverging from the correct solution. The other pairs deviated from the task, never to converge to a result.
What carries the argument
Three dimensions of multi-agent interaction—efficiency (speed and stability of convergence), consistency (role alignment measured by BLEU and ROUGE), and effectiveness (compilation success and error resolution)—applied to twelve model pairs on the Designer-Programmer Fibonacci task.
If this is right
- Model selection directly affects whether multi-agent teams reach correct code quickly or fail to converge.
- Strong role alignment can occur without producing a correct solution.
- Most tested open-source pairs either diverge or never reach a working result without extra controls.
- Explicit research on convergence detection and stop conditions is required for autonomous agentic software engineering.
Where Pith is reading between the lines
- The observed patterns may shift when agents work on larger or multi-file codebases instead of a single simple game.
- Adding mechanisms to detect early convergence could reduce wasted iterations across all model pairs.
- Hybrid setups that mix models from different families might combine the fast convergence of one pair with the role stability of another.
Load-bearing premise
That the single narrow task of developing a Fibonacci game is representative enough of general multi-agent software engineering work to support broader claims about convergence behavior.
What would settle it
Repeating the exact experiment on a different programming task such as implementing a sorting algorithm and checking whether the same model pairs exhibit the identical convergence and alignment patterns.
Figures




read the original abstract
Large Language Models (LLMs) are increasingly applied to software engineering (SE), yet their potential for autonomous, role-oriented collaboration remains largely underexplored. Understanding how multiple LLM-based agents coordinate, maintain role alignment, and converge on solutions is critical for SE, as naively allowing agents to interact does not reliably lead to correct or stable outcomes. Recent empirical studies show that unstructured or poorly understood interaction dynamics can result in error propagation, premature consensus on incorrect solutions, or prolonged disagreement that prevents convergence, even when correct partial solutions are present early in the interaction. As an initial step towards addressing this underexplored area, we undertake a systematic analysis of conversations between two agents, a Designer and a Programmer across 12 model combinations from 7 open-source LLMs (Gemma 2, Gemma 3, LLaMA 3.2, LLaMA 3.3, DeepSeek-R1, MiniCPM, and Qwen3). Our systematic approach reveals three key dimensions of multi-agent interaction: efficiency (the speed and stability of convergence), consistency (the degree of role alignment visualized by BLEU and ROUGE), and effectiveness (the extent of compilation success and error resolution). Results show that the DeepSeek-R1:DeepSeek-R1 pair was unique in converging to the correct solution from the very first iteration and sustaining it consistently to the final iteration, while LLaMA 3.2:LLaMA 3.2 and Qwen3:Qwen3 demonstrated strong Designer:Programmer role alignment despite of diverging from the correct solution. The other pairs deviated from the task, never to converge to a result. These findings advance understanding of agentic programming and highlight the need for further research on understanding and calibrating convergence and stop conditions essential for future autonomous SE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports an empirical case study of multi-agent LLM interactions, comparing 12 Designer-Programmer pairs drawn from 7 open-source models on the single task of developing a Fibonacci game. It defines three analysis dimensions—efficiency (convergence speed/stability), consistency (role alignment via BLEU/ROUGE), and effectiveness (compilation success/error resolution)—and reports that the DeepSeek-R1:DeepSeek-R1 pair uniquely converged to a correct solution from iteration 1 onward, that LLaMA 3.2:LLaMA 3.2 and Qwen3:Qwen3 exhibited strong role alignment despite incorrect outputs, and that the remaining pairs failed to converge.
Significance. If the observational results prove robust and reproducible, the work supplies concrete data on role-based LLM collaboration in a software-engineering setting and usefully flags the practical importance of convergence and stop-condition mechanisms. The systematic cross-model design and focus on open-source models are strengths for an initial exploration.
major comments (2)
- [Abstract] Abstract: the central claim that the DeepSeek-R1:DeepSeek-R1 pair 'was unique in converging to the correct solution from the very first iteration' rests on a single narrow task whose success criterion is binary and whose output is deterministic; the stress-test concern correctly notes that tasks with ambiguous requirements or longer dependency chains could change observed convergence speed, stability, and role consistency, thereby weakening the load-bearing uniqueness finding for broader multi-agent SE claims.
- [Abstract] Abstract / Methods description: the manuscript states a 'systematic analysis' across 12 pairs but supplies no information on data-collection protocol, exclusion rules, inter-rater reliability for role-alignment scoring, or error analysis; without these details it is impossible to assess whether post-hoc selection or unstated filters affect the reported uniqueness of the DeepSeek pair (reader soundness rating 4.0).
minor comments (1)
- [Abstract] Abstract: 'despite of diverging' is ungrammatical; change to 'despite diverging'.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly to improve clarity and completeness while preserving the scope of this initial case study.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the DeepSeek-R1:DeepSeek-R1 pair 'was unique in converging to the correct solution from the very first iteration' rests on a single narrow task whose success criterion is binary and whose output is deterministic; the stress-test concern correctly notes that tasks with ambiguous requirements or longer dependency chains could change observed convergence speed, stability, and role consistency, thereby weakening the load-bearing uniqueness finding for broader multi-agent SE claims.
Authors: We agree the study examines a single deterministic task (Fibonacci game) with binary success. The manuscript frames the work as an initial case study on one task rather than a general claim across all SE scenarios. The reported uniqueness applies specifically to the 12 pairs on this task. We will revise the abstract and add a limitations paragraph to explicitly state that generalizability to ambiguous or multi-step tasks remains untested and requires future work, thereby avoiding any implication of broad uniqueness. revision: yes
-
Referee: [Abstract] Abstract / Methods description: the manuscript states a 'systematic analysis' across 12 pairs but supplies no information on data-collection protocol, exclusion rules, inter-rater reliability for role-alignment scoring, or error analysis; without these details it is impossible to assess whether post-hoc selection or unstated filters affect the reported uniqueness of the DeepSeek pair (reader soundness rating 4.0).
Authors: We accept that the current Methods section is insufficiently detailed. We will expand it with: (1) the exact data-collection protocol (conversation logging, iteration stopping rule, model temperature/settings), (2) confirmation that all 12 pairs were run without exclusion, (3) clarification that role alignment uses automated BLEU/ROUGE (no manual scoring, hence no inter-rater reliability), and (4) an error-analysis subsection with examples of divergence patterns. These additions will allow readers to evaluate reproducibility. revision: yes
Circularity Check
Empirical observational study with no derivation chain or circular reductions
full rationale
The paper is a case study reporting direct experimental observations of LLM agent conversations on one fixed task (Fibonacci game). No equations, fitted parameters, predictions derived from inputs, or self-citation load-bearing premises appear in the provided text. All reported findings (convergence behavior, role alignment via BLEU/ROUGE, compilation success) are presented as direct measurements from the 12 model-pair runs, with no reduction to prior self-referential definitions or ansatzes. The analysis is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Virginia Braun and Victoria Clarke. 2006. Using thematic analysis in psychology. Qualitative Research in Psychology3, 2 (2006), 77–101
2006
- [3]
-
[4]
Tao Chen. 2024. Challenges and opportunities in integrating LLMs into con- tinuous integration/continuous deployment pipelines. InProceedings of the 5th International Seminar on Artificial Intelligence, Networking and Information Tech- nology (AINIT 2024). IEEE, 364–367
2024
- [5]
- [6]
-
[7]
Jiawei Fang, Yifan Peng, Xiaojie Zhang, Yifan Wang, Xin Yi, Guangyu Zhang, Yuhui Xu, Bin Wu, Shuang Liu, Zhi Li, et al . 2025. A comprehensive survey of self-evolving AI agents: A new paradigm bridging foundation models and lifelong agentic systems.arXiv preprint(2025). arXiv:2508.07407
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [8]
-
[9]
Ahmed E. Hassan, Gaëtan A. Oliva, Dongmei Lin, Boyuan Chen, and Zheng- dong M. Jiang. 2024. Towards AI-native software engineering (SE 3.0): A vision and a challenge roadmap.arXiv preprint(2024). arXiv:2410.06107
-
[10]
Junda He, Christoph Treude, and David Lo. 2025. LLM-based multi-agent systems for software engineering: Literature review, vision, and the road ahead.ACM Transactions on Software Engineering and Methodology34, 5 (2025), 1–30
2025
-
[11]
Soodeh Hosseini and Hossein Seilani. 2025. The role of agentic AI in shaping a smart future: A systematic review.Array, Article 100399 (2025)
2025
-
[12]
Jian Jiang, Fei Wang, Jun Shen, Sunghun Kim, and Sung Kim. 2024. A sur- vey on large language models for code generation.arXiv preprint(2024). arXiv:2406.00515
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. 2024. A survey on large language models for code generation.ACM Transactions on Software Engineering and Methodology(2024)
2024
- [14]
-
[15]
Richard Landis and Gary G
J. Richard Landis and Gary G. Koch. 1977. The measurement of observer agree- ment for categorical data.Biometrics33, 1 (1977), 159–174
1977
-
[16]
Xinyi Li et al. 2024. A survey on LLM-based multi-agent systems: Workflow, infrastructure, and challenges.Vicinagearth1, 1 (2024), 9
2024
-
[17]
Chin-Yew Lin. 2004. ROUGE: A package for automatic evaluation of summaries. InText Summarization Branches Out: Proceedings of the ACL-04 Workshop. ACL, 74–81
2004
-
[18]
Nam Nguyen and Sarah Nadi. 2022. An empirical evaluation of GitHub Copilot’s code suggestions. InProceedings of the 19th International Conference on Mining Software Repositories (MSR ’22). ACM, 1–5
2022
-
[19]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. BLEU: A method for automatic evaluation of machine translation. InProceedings of the 40th Annual Meeting of the Association for Computational Linguistics. ACL, 311–318
2002
-
[20]
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, et al. 2024. ChatDev: Communicative agents for software development. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024). Association for Computational Linguistics, 15174–15186
2024
-
[21]
2020.Action Research in Software Engineering
Miroslaw Staron. 2020.Action Research in Software Engineering. Springer Inter- national Publishing, Berlin, Germany
2020
-
[22]
Simin Sun and Miroslaw Staron. 2025. Literate Programming with LLMs?-A Study on Rosetta Code and CodeNet.IEEE Transactions on Software Engineering (2025)
2025
- [23]
-
[24]
Wikipedia contributors. 2025. Process patterns. https://en.wikipedia.org/wiki/ Process_patterns. Accessed: 2026-02-11
2025
-
[25]
Ohlsson, Björn Regnell, and Anders Wesslén
Claes Wohlin, Per Runeson, Martin Höst, Magnus C. Ohlsson, Björn Regnell, and Anders Wesslén. 2012.Experimentation in Software Engineering. Springer, Berlin, Germany
2012
-
[26]
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, et al. 2024. AutoGen: Enabling next-gen LLM applications via multi- agent conversations. InProceedings of the First Conference on Language Modeling. AIware ’26, July 6–7, 2026, Montreal, QC, Canada Basu et al. Conference on Language Modeling
2024
-
[27]
Chunqiu Steven Xia et al. 2025. Demystifying LLM-based software engineering agents. InProceedings of the ACM on Software Engineering (FSE, Vol. 2). ACM, 801–824
2025
-
[28]
Zhenyu Zheng, Kai Ning, Yufeng Wang, Jian Zhang, Dong Zheng, Min Ye, and Jie Chen. 2023. A survey of large language models for code: Evolution, benchmarking, and future trends.arXiv preprint(2023). arXiv:2311.10372. 8 Acknowledgments This paper has been partially financed by Software Center, www. software-center.se, a collaboration between Chalmers, the U...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.